はじめに
この記事はQiita アドベントカレンダー 2022 Linuxの24日目の記事です。
アドベントカレンダーも終わりが近付き、師走が忙しくて、まだ読めていないカレンダー記事が溜まっている方も多いと思います。
そこで、アドベントカレンダーの記事をすべてまとめて一つのEPUBファイルに落としてKindleで後でじっくり読もう、という試みの記事です。
Qiita記事を電子書籍化するの拡張版です。
やっていることは Shellscriptでスクレイピング + pandoc でEPUBに変換 です。
記事の内容の8割はシェルスクリプトスクレイピングで右往左往している様子が見れるだけですので、お急ぎの方は最終的なShellscriptまで読み飛ばしてください。
Webへ公開されているHTMLをスクレイピングするので、Qiita APIは使いません。Qiitaへの登録すら必要ありません。
前準備
QiitaアドベントカレンダーのHTMLを開発ツールを使ってざっくり覗いてみると、table要素内にaタグでリンクが書き込まれているようです。
このtable内のaタグを抜き出せば、リンク一覧を取得できそうです。
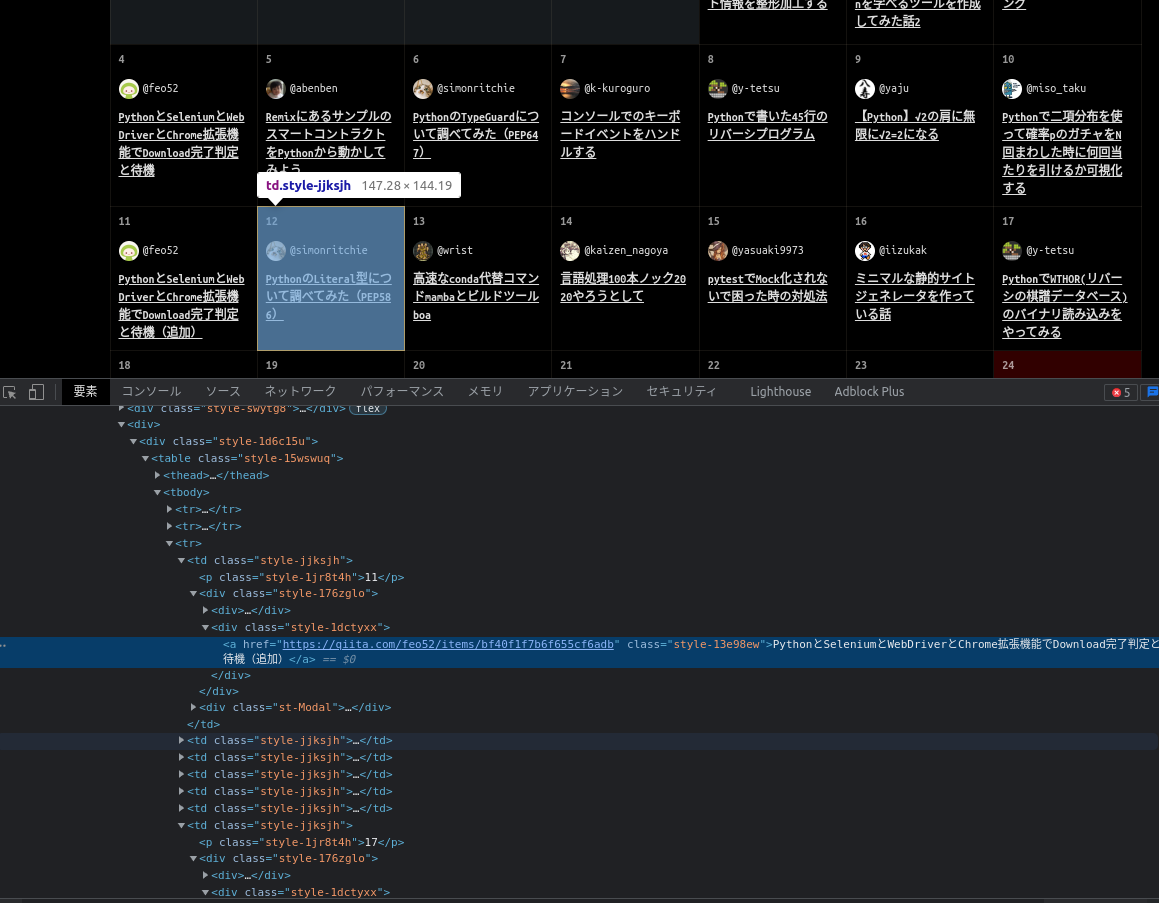
スクレイピング
テーブル取得
# カレンダーを取得して、最初のtable要素のみ取り出す
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>'
テーブルを出力できました。
出力結果略。
grep -oはマッチした箇所だけを抜き出します。
grep -PのPerl正規表現を使うことで最短マッチ.*?を使えます。
$ man grep
-o, --only-matching
マッチする行のマッチした部分だけを (それが空文字列でなければ) 表示します。 マッチした各文字列は、それぞれ別の行に書き出します。
-P, --perl-regexp
パターンを Perl 互換の正規表現 (PCRE) として扱います。 きわめて実験的なものなので、 grep -P を使うと、その機能は実装されていませんという 警告が出るかもしれません。
aタグ取得
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>' |
grep -oP '<a href.*?</a>'
URL="https://qiita.com/advent-calendar/2021/linux"
<a href="/hoglet" class="css-h63oov"><img class="css-15uqmbt" height="20" loading="lazy" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/2217966/profile-images/1635240021" width="20"/>@<!-- -->hoglet</a></div><div class="css-1dctyxx"><a href="https://qiita.com/hoglet/items/edb0cb47b7705570492d" class="css-13e98ew">Linux入門 1-2 各コマンドとviコマンドの基本</a>
<a href='/advent-calendar-terms' target='_blank' style='text-decoration: underline; color: #3683bf;'>the terms of use</a></p></div><div class="css-16y4ddv"><button font-size="14" class="css-w4p0ut e1rb7ucl0">Cancel</button><button font-size="14" class="css-w4p0ut e1rb7ucl0">Join</button></div></div></div></td><td class="css-jjksjh"><p class="css-1emq3dn">2</p><div class="css-176zglo"><div><a href="/kakinaguru_zo" class="css-h63oov"><img class="css-15uqmbt" height="20" loading="lazy" src="https://qiita-image-store.s3.amazonaws.com/0/259309/profile-images/1528523620" width="20"/>@<!-- -->kakinaguru_zo</a></div><div class="css-1dctyxx"><a href="https://qiita.com/kakinaguru_zo/items/08c227291d63e7570821" class="css-13e98ew">hardening のための sysctl と カーネル起動オプションと kconfig</a>
<a href='/advent-calendar-terms' target='_blank' style='text-decoration: underline; color: #3683bf;'>the terms of use</a></p></div><div class="css-16y4ddv"><button font-size="14" class="css-w4p0ut e1rb7ucl0">Cancel</button><button font-size="14" class="css-w4p0ut e1rb7ucl0">Join</button></div></div></div></td><td class="css-jjksjh"><p class="css-1emq3dn">3</p><div class="css-176zglo"><div><a href="/furandon_pig" class="css-h63oov"><img class="css-15uqmbt" height="20" loading="lazy" src="https://qiita-image-store.s3.amazonaws.com/0/61137/profile-images/1473695440" width="20"/>@<!-- -->furandon_pig</a></div><div class="css-1dctyxx"><a href="https://qiita.com/furandon_pig/items/ee393ee89c39232a4cdb" class="css-13e98ew">逆ポーランド計算機カーネルモジュール(仮)を作ってみる</a>
...
300行取得しました。
カレンダー記事は25件なので、余計なタグを取得してそうです。
記事リンクはitemsがURLに含まれるので、itemsを含むhrefだけ取得しましょう。
itemsを含むhrefのaタグだけ取得
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>' |
grep -oP '<a href.*?items.*?</a>'
<a href="/hoglet" class="css-h63oov"><img class="css-15uqmbt" height="20" loading="lazy" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/2217966/profile-images/1635240021" width="20"/>@<!-- -->hoglet</a>
<a href="https://qiita.com/hoglet/items/edb0cb47b7705570492d" class="css-13e98ew">Linux入門 1-2 各コマンドとviコマンドの基本</a>
<a href='/advent-calendar-terms' target='_blank' style='text-decoration: underline; color: #3683bf;'>the terms of use</a>
<a href="/kakinaguru_zo" class="css-h63oov"><img class="css-15uqmbt" height="20" loading="lazy" src="https://qiita-image-store.s3.amazonaws.com/0/259309/profile-images/1528523620" width="20"/>@<!-- -->kakinaguru_zo</a>
<a href="https://qiita.com/kakinaguru_zo/items/08c227291d63e7570821" class="css-13e98ew">hardening のための sysctl と カーネル起動オプションと kconfig</a>
<a href='/advent-calendar-terms' target='_blank' style='text-decoration: underline; color: #3683bf;'>the terms of use</a>
<a href="/furandon_pig" class="css-h63oov"><img class="css-15uqmbt" height="20" loading="lazy" src="https://qiita-image-store.s3.amazonaws.com/0/61137/profile-images/1473695440" width="20"/>@<!-- -->furandon_pig</a>
<a href="https://qiita.com/furandon_pig/items/ee393ee89c39232a4cdb" class="css-13e98ew">逆ポーランド計算機カーネルモジュール(仮)を作ってみる</a>
...
100行取得できました。
まだ4倍多い。
hrefの内容を見てみるとitemsを含まない行まで取得できています。
ちなみにclassでフィルターを書ける方法も考えましたが、使用されているclass名が年度ごと、カレンダーごとに違うようなので、応用が利かないと思い、この案はボツにしました。
href="https://qiita.comを含むaタグだけを取得
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>' |
grep -oP '<a href="https://qiita.com/.*?items.*?</a>'
<a href="https://qiita.com/hoglet/items/edb0cb47b7705570492d" class="css-13e98ew">Linux入門 1-2 各コマンドとviコマンドの基本</a>
<a href="https://qiita.com/kakinaguru_zo/items/08c227291d63e7570821" class="css-13e98ew">hardening のための sysctl と カーネル起動オプションと kconfig</a>
<a href="https://qiita.com/furandon_pig/items/ee393ee89c39232a4cdb" class="css-13e98ew">逆ポーランド計算機カーネルモジュール(仮)を作ってみる</a>
<a href="https://qiita.com/woonotch/items/8f362989269bacdfc183" class="css-13e98ew">KAGOYAサーバーでCentOS8からAlma Linuxへ換装した</a>
<a href="https://qiita.com/Lesmiscore/items/4d03efc9e86bac758f68" class="css-13e98ew">squashfsをsystemdで起動時にマウントする</a>
...
64行取得できました。
25日分の記事取得なのに64行?不可解。
アドベントカレンダーに上がる記事のURLはQiita記事に限らないからですね。
上のスクリプトだと、qiitaドメインのURLだけを取得してきます。
さらに、HTML要素をよく見てみるとカレンダーは一つしかないのに、同じURLの記事が4つあり、tableが4つもありました。
つまり、16件のQiitaドメインの記事が4カレンダー分で16x4=64行取得できたということです。
表示スタイル(PC, タブレット、スマホ)とかによって使い分けているのか?
sedでURLとタイトルだけ抜き出す
重複している部分はとりあえず置いといて、連想配列にすれば重複がなくなるかな、と連想配列にする前準備です。
sedでURLとタイトルだけ抜き出します。
マッチした部分は\1, \2で取り出し、コロンで区切ります。
sed -rで正規表現マッチができます。
$ man sed
-r, --regexp-extended
スクリプトで拡張正規表現を使用する
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>' |
grep -oP '<a href="https://qiita.com/.*?items.*?</a>' |
sed -r 's_<a href="(https://qiita.com.*)" class=.*>(.*)</a>_\1:\2_g'
https://qiita.com/hoglet/items/edb0cb47b7705570492d:Linux入門 1-2 各コマンドとviコマンドの基本
https://qiita.com/kakinaguru_zo/items/08c227291d63e7570821:hardening のための sysctl と カーネル起動オプションと kconfig
https://qiita.com/furandon_pig/items/ee393ee89c39232a4cdb:逆ポーランド計算機カーネルモジュール(仮)を作ってみる
https://qiita.com/woonotch/items/8f362989269bacdfc183:KAGOYAサーバーでCentOS8からAlma Linuxへ換装した
https://qiita.com/Lesmiscore/items/4d03efc9e86bac758f68:squashfsをsystemdで起動時にマウントする
https://qiita.com/angel_p_57/items/07fe5d86970fc84c564a:バックグラウンドのSSH処理がジョブを停止させる問題
...
連想配列を使う(ボツ)
重複するURLを取り除く方法を考えました。
まず考えたのは連想配列や集合を使う方法です。
bashで連想配列にするには ["キー"]="値"のようにしてdeclare -A 変数名に渡すようです。
bash version 4.0以上が必要です。
URL="https://qiita.com/advent-calendar/2021/linux"
items=(
$(curl -fsSL $URL |
grep -oP '<table.*?</table>' |
grep -oP '<a href="https://qiita.com/.*?items.*?</a>' |
sed -r 's_<a href="(https://qiita.com.*)" class=.*>(.*)</a>_\1_g'
)
)
echo ${#items[*]} # 配列の長さ表示
64
headで一行だけ取得(ボツ)
愚直にgrep -oPの結果をheadで最初の一行だけにしました。
これで最初のtable要素だけ取得できます。
# URL="https://qiita.com/advent-calendar/2021/linux"
cat `pwd`/qiita.com_advent-calendar_2021_linux.html |
grep -oP '<table.*?</table>' |
head -1
<table class="css-15wswuq"><thead><tr><th class="css-18put86">Sun</th><th class="css-18put86">Mon</th><th class="css-18put86">Tue</th><th class="css-18put86">Wed</th><th class="css-18put86">Thu</th><th class="css-18put86">Fri</th><th class="css-18put86">Sat</th></tr></thead><tbody><tr><td class="css-16hii6j"><p class="css-1yhp7mb">28</p></td><td class="css-16hii6j"><p class="css-1yhp7mb">29</p></td><td class="css-16hii6j"><p class="css-1yhp7mb">30</p></td><td class="css-jjksjh"><p class="css-1emq3dn">1</p><div class="css-176zglo"><div><a href="/hoglet" class="css-h63oov"><img class="css-15uqmbt" height="20" loading="lazy" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/2217966/profile-images/1635240021" width="20"/>@<!-- -->hoglet</a></div><div class="css-1dctyxx"><a href="https://qiita.com/hoglet/items/edb0cb47b7705570492d" class="css-13e98ew">Linux入門 1-2 各コマンドとviコマンドの基本</a></div></
...
最初のtable内のaタグだけを取得
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>' | head -1 | # 最初のtable要素のみ
grep -oP '<a href="https?:.*?</a>'
25行抜き出せました。
httpsがないとユーザーページなど、サーバー側のローカルパス指定も引っかかってきます。
最初のテーブルの記事がすべて埋まっているので、25日分の外部リンク記事が取得できたということです。
<a href="https://qiita.com/hoglet/items/edb0cb47b7705570492d" class="css-13e98ew">Linux入門 1-2 各コマンドとviコマンドの基本</a>
<a href="https://qiita.com/kakinaguru_zo/items/08c227291d63e7570821" class="css-13e98ew">hardening のための sysctl と カーネル起動オプションと kconfig</a>
<a href="https://qiita.com/furandon_pig/items/ee393ee89c39232a4cdb" class="css-13e98ew">逆ポーランド計算機カーネルモジュール(仮)を作ってみる</a>
<a href="https://qiita.com/woonotch/items/8f362989269bacdfc183" class="css-13e98ew">KAGOYAサーバーでCentOS8からAlma Linuxへ換装した</a>
<a href="https://qiita.com/Lesmiscore/items/4d03efc9e86bac758f68" class="css-13e98ew">squashfsをsystemdで起動時にマウントする</a>
<a href="https://qiita.com/angel_p_57/items/07fe5d86970fc84c564a" class="css-13e98ew">バックグラウンドのSSH処理がジョブを停止させる問題</a>
<a href="https://qiita.com/YutaroHayakawa/items/8cd2fd0a2f0b602f61c4" class="css-13e98ew">ipftrace2で始めるLinuxネットワークスタック探訪</a>
<a href="https://www.kimullaa.com/entry/2021/12/08/063000" class="css-13e98ew">delay accounting を使ってみる</a>
<a href="https://qiita.com/EbiTT/items/98fd5bc7e967ecfba666" class="css-13e98ew">【Linux】cutコマンドのオプション別パフォーマンス対決</a>
<a href="https://tech.buty4649.net/entry/2021/12/05/220929" class="css-13e98ew">業務で使っているPCをLinuxデスクトップにしてから3年半が経った</a>
<a href="https://tech.buty4649.net/entry/2021/12/11/231401" class="css-13e98ew">MAAS3.1の新機能:デプロイ済みのマシンを管理下におく</a>
<a href="https://qiita.com/opuntia/items/ace9dff9bbd66893d2d7" class="css-13e98ew">systemdでマウントする順序をコントロールする方法 </a>
<a href="https://udzura.hatenablog.jp/entry/2021/12/13/203425" class="css-13e98ew">プラグインを書いて学ぶGNU NSS</a>
<a href="https://qiita.com/kaizen_nagoya/items/9f286daa1d093262ed38" class="css-13e98ew">Linux いろいろ</a>
<a href="https://feneshi.co/Rust_In_Linux_Kernel_2/" class="css-13e98ew">Linux kernelに入ってきそうなRustをさらに読む</a>
<a href="https://qiita.com/k8uwall/items/f1afc2349b59f3f1b42a" class="css-13e98ew">実行されないcron設定ファイルを検証してみた</a>
<a href="https://ryuichi1208.hateblo.jp/entry/2021/12/16/152821" class="css-13e98ew">ディスクリプタパッシングについて書きます</a>
<a href="https://kernhack.hatenablog.com/entry/2021/12/18/002124" class="css-13e98ew">stable kernelにコントリビュートする</a>
<a href="https://qiita.com/takutakahashi/items/315626ae479f0a6206ef" class="css-13e98ew">手を動かして学ぶ QEMU とネットワーク</a>
<a href="https://zenn.dev/ozaki_r/articles/b47af93f38b9c1" class="css-13e98ew">AF_XDPの動作モード間の処理の違い</a>
<a href="https://gihyo.jp/admin/serial/01/linux_containers/0048" class="css-13e98ew">LXCで学ぶコンテナ入門 第48回 cgroup v2から使うコントローラとmiscコントローラ</a>
<a href="https://qiita.com/shohey1226/items/8c51593663050d37def2" class="css-13e98ew">Online Linux Terminal - Wazatermを支える技術</a>
<a href="https://qiita.com/cat_servant/items/0b680e02bf60878b76a3" class="css-13e98ew">元Linux向けアプリケーション開発者がおすすめする本「C言語によるスーパーLinuxプログラミング」の紹介</a>
<a href="https://qiita.com/juraruming/items/f89ec5a2a27bbd462c0c" class="css-13e98ew">Yoctoベースの組み込みLinuxがビルドエラーになったときに試したこと</a>
<a href="https://qiita.com/kentaost/items/d8917a14fc9a97d5a28f" class="css-13e98ew">KRSI と fmod_ret 入門編</a>
しかし、後述するアドベントカレンダーの2020年問題でテーブル一つだけを抜き出すとその1, その2,...に分かれているカレンダーが取得できない。汎用性がないのでボツ。
grepでtable要素を一つだけ取り出す(ボツ)
grep -m1でできるはずだが...
$ man grep
-m NUM, --max-count=NUM
マッチした行数が NUM に達したら、ファイルの読み込みを中止します。 入力が通常ファイルから標準入力を介して行わ
れている場合は、マッチした行を NUM 行出力した時点で、 grep は標準入力の読み出し位置を最後にマッチした行の直後
に来るようにしてから、 終了します。続いて表示する文脈行がある場合でも、この動作は変わりません。 このことは、
grep を呼び出すプロセスが、中止したところから検索を 再開することを可能にします。 grep はマッチした行数が NUM
に達してストップしたとき、それに続く文脈行があれば、それを出力します。 -c や --count オプションを同時に使用し
た場合、 grep は NUM よりも大きい数を出力しません。 -v や --invert-match を同時に使用した場合は、マッチしない
行を NUM 行出力したところで、 grep はストップします。
できない。
すべてのtable要素が一行の中に出てくるからでしょうか。
sedでtable要素を一つだけ取り出す
grepの代わりにsed使ったら最初のtableだけ抜き出せました。
-rで正規表現マッチを使います。
.*?で最短マッチで'<table'から'</table>'までを抜き出します。
# URL="https://qiita.com/advent-calendar/2021/linux"
cat `pwd`/qiita.com_advent-calendar_2021_linux.html |
sed -r 's_.*(<table.*?</table>).*_\1_' |
grep -oP '<a href="https:.*?</a>'
<a href="https://help.qiita.com/ja/articles/qiita-adcal-1" target="_blank" class="css-4b06c6">Help</a>
<a href="https://www.twilio.com/ja/" target="_blank" rel="noopener noreferrer" class="css-13o7eu2"><img src="//cdn.qiita.com/assets/public/advent-calendar-sponsors/2021/logo-twilio-3f2007f009fed09470b03118935cfed0.png" alt="Twilio" class="css-1yyankv"/></a>
<a href="https://www.t-dash.io/" target="_blank" rel="noopener noreferrer" class="css-13o7eu2"><img src="//cdn.qiita.com/assets/public/advent-calendar-sponsors/2021/logo-tdash-bb7d6ecb0fa7981ff78599deaa2f2d1d.png" alt="T-DASH" class="css-1yyankv"/></a>
<a href="https://www.freee.co.jp/" target="_blank" rel="noopener noreferrer" class="css-13o7eu2"><img src="//cdn.qiita.com/assets/public/advent-calendar-sponsors/2021/logo-freee-c4a13524fc764db9fd6a40a42fe8fb9d.png" alt="freee" class="css-1yyankv"/></a>
<a href="https://news.microsoft.com/ja-jp/" target="_blank" rel="noopener noreferrer" class="css-13o7eu2"><img src="//cdn.qiita.com/assets/public/advent-calendar-sponsors/2021/logo-microsoft-1082454804b77c07815c46d87d3215a8.png" alt="Microsoft" class="css-1yyankv"/></a>
<a href="https://www.udemy.com/?utm_medium=udemyads&utm_source=bene-placement&utm_type=QiitaZine&utm_campaign=adventcalendar&utm_content=top&utm_term=202112" target="_blank" rel="noopener noreferrer" class="css-13o7eu2"><img src="//cdn.qiita.com/assets/public/advent-calendar-sponsors/2021/logo-udemy-ba4168c69d46653919c87d687d3ffbd8.png" alt="Udemy" class="css-1yyankv"/></a>
<a href="https://snyk.io/" target="_blank" rel="noopener noreferrer" class="css-13o7eu2"><img src="//cdn.qiita.com/assets/public/advent-calendar-sponsors/2021/logo-snyk-418a64f4e19152a6fa02d92861ae28b7.png" alt="Snyk" class="css-1yyankv"/></a>
45行取得できました。
URLのみ抜き出す
各行のパターンマッチにはsed -r s/XXX/\1/を使います。
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>' | head -1 |
grep -oP '<a href="https:.*?</a>' |
sed -r 's_^.*?href="([^"]+)".*$_\1_'
([^"]*)はダブルクォーテーション以外の文字列1個以上を示すので、
ダブルクォーテーション内の最短一致パターンを抜き出します。
hrefがないと最短一致で後ろのclass=""の中だけを取得してきます。
https://qiita.com/hoglet/items/edb0cb47b7705570492d
https://qiita.com/kakinaguru_zo/items/08c227291d63e7570821
https://qiita.com/furandon_pig/items/ee393ee89c39232a4cdb
https://qiita.com/woonotch/items/8f362989269bacdfc183
https://qiita.com/Lesmiscore/items/4d03efc9e86bac758f68
https://qiita.com/angel_p_57/items/07fe5d86970fc84c564a
https://qiita.com/YutaroHayakawa/items/8cd2fd0a2f0b602f61c4
https://www.kimullaa.com/entry/2021/12/08/063000
https://qiita.com/EbiTT/items/98fd5bc7e967ecfba666
https://tech.buty4649.net/entry/2021/12/05/220929
https://tech.buty4649.net/entry/2021/12/11/231401
https://qiita.com/opuntia/items/ace9dff9bbd66893d2d7
https://udzura.hatenablog.jp/entry/2021/12/13/203425
https://qiita.com/kaizen_nagoya/items/9f286daa1d093262ed38
https://feneshi.co/Rust_In_Linux_Kernel_2/
https://qiita.com/k8uwall/items/f1afc2349b59f3f1b42a
https://ryuichi1208.hateblo.jp/entry/2021/12/16/152821
https://kernhack.hatenablog.com/entry/2021/12/18/002124
https://qiita.com/takutakahashi/items/315626ae479f0a6206ef
https://zenn.dev/ozaki_r/articles/b47af93f38b9c1
https://gihyo.jp/admin/serial/01/linux_containers/0048
https://qiita.com/shohey1226/items/8c51593663050d37def2
https://qiita.com/cat_servant/items/0b680e02bf60878b76a3
https://qiita.com/juraruming/items/f89ec5a2a27bbd462c0c
https://qiita.com/kentaost/items/d8917a14fc9a97d5a28f
HTMLを一括ダウンロード
カレンダーのURL一覧を取得できたので、これをすべてcurlして標準出力に渡します。
直列に(非・パラレルに、非・並列に)出力するにはxargsコマンドで-n1を指定すると、引数を一つずつ処理していくので、1日から25日まで順序を守ってHTMLをダウンロードします。
$ man:xargs
-n max-args, --max-args=max-args
1 コマンド行につき最大 max-args 個の引数を使用します。 作成されたコマンドラインが、 コマンドライン長の上限を超過する場合は (-s オプション
参照)、 max-args より少ない引数が使用されることになります。 ただし、 -x オプションが指定されているときは別で、 その場合は xargs が終了しま
す。
URL="https://qiita.com/advent-calendar/2021/linux"
curl -fsSL $URL |
grep -oP '<table.*?</table>' | head -1 | # 最初のtableのみ
grep -oP '<a href="https?:.*?</a>' | # httpが含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' | # URLのみ
xargs -n1 curl -L # アドベントカレンダー上の外部リンクから得られるHTMLの一括ダウンロード
電子書籍化
単一カレンダー
pandocへHTMLを渡してEPUBとして出力します。
これまでやってきたことをpandocにHTMLとして入力しEPUBとして出力するだけです。
他のカレンダーに応用したり、タイトルを考えるのが面倒なので、変数に年号とテーマを入れてURLとする小さな変更も加えています。
YEAR="2021"
THEME="Linux"
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
curl -fsSL $URL |
grep -oP '<table.*?</table>' | head -1 | # 最初のtableのみ
grep -oP '<a href="https?:.*?</a>' | # httpが含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' | # URLのみ
xargs -n1 curl -L | # アドベントカレンダー上の外部リンクから得られるHTMLの一括ダウンロード
pandoc -s -f html -t epub3 --toc --toc-depth=3 -o Qiitaアドベントカレンダー${YEAR}${THEME}.epub
curl: (23) Failure writing output to destination
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 104k 0 104k 0 0 128k 0 --:--:-- --:--:-- --:--:-- 128k
100 104k 0 104k 0 0 128k 0 --:--:-- --:--:-- --:--:-- 128k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 98k 0 98k 0 0 82894 0 --:--:-- 0:00:01 --:--:-- 82920
100 98k 0 98k 0 0 82886 0 --:--:-- 0:00:01 --:--:-- 82920
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 84841 0 84841 0 0 133k 0 --:--:-- --:--:-- --:--:-- 133k
100 141k 0 141k 0 0 226k 0 --:--:-- --:--:-- --:--:-- 225k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 964k 0 964k 0 0 1239k 0 --:--:-- --:--:-- --:--:-- 1241k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 70693 0 70693 0 0 223k 0 --:--:-- --:--:-- --:--:-- 222k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 140k 0 140k 0 0 184k 0 --:--:-- --:--:-- --:--:-- 184k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 98237 0 98237 0 0 135k 0 --:--:-- --:--:-- --:--:-- 135k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 313 100 313 0 0 1691 0 --:--:-- --:--:-- --:--:-- 1701
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 313 100 313 0 0 1387 0 --:--:-- --:--:-- --:--:-- 1387
100 68076 100 68076 0 0 234k 0 --:--:-- --:--:-- --:--:-- 234k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 98k 0 98k 0 0 195k 0 --:--:-- --:--:-- --:--:-- 195k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 58614 0 58614 0 0 269k 0 --:--:-- --:--:-- --:--:-- 270k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 46479 0 46479 0 0 239k 0 --:--:-- --:--:-- --:--:-- 240k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 66002 0 66002 0 0 79150 0 --:--:-- --:--:-- --:--:-- 79139
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 59094 0 59094 0 0 282k 0 --:--:-- --:--:-- --:--:-- 282k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0
100 68799 0 68799 0 0 54173 0 --:--:-- 0:00:01 --:--:-- 54172
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 78333 100 78333 0 0 197k 0 --:--:-- --:--:-- --:--:-- 197k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 101k 0 101k 0 0 133k 0 --:--:-- --:--:-- --:--:-- 133k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 58121 0 58121 0 0 244k 0 --:--:-- --:--:-- --:--:-- 245k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 78725 0 78725 0 0 438k 0 --:--:-- --:--:-- --:--:-- 439k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 98k 0 98k 0 0 276k 0 --:--:-- --:--:-- --:--:-- 275k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 169k 0 169k 0 0 109k 0 --:--:-- 0:00:01 --:--:-- 109k
100 169k 0 169k 0 0 109k 0 --:--:-- 0:00:01 --:--:-- 109k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 64507 0 64507 0 0 152k 0 --:--:-- --:--:-- --:--:-- 151k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 76201 0 76201 0 0 131k 0 --:--:-- --:--:-- --:--:-- 131k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 101k 0 101k 0 0 100k 0 --:--:-- 0:00:01 --:--:-- 100k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 119k 0 119k 0 0 160k 0 --:--:-- --:--:-- --:--:-- 160k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 31587 0 31587 0 0 19972 0 --:--:-- 0:00:01 --:--:-- 19966
100 92398 0 92398 0 0 39517 0 --:--:-- 0:00:02 --:--:-- 39537
[WARNING] Could not fetch resource //b.yjtag.jp/iframe?c=g7Rx6Q9: Could not fetch //b.yjtag.jp/iframe?c=g7Rx6Q9
InvalidUrlException "//b.yjtag.jp/iframe?c=g7Rx6Q9" "Invalid URL"
[WARNING] Duplicate identifier 'title' at input line 8667 column 73
[WARNING] Duplicate identifier 'blog-description' at input line 8669 column 43
[WARNING] Could not fetch resource //b.yjtag.jp/iframe?c=g7Rx6Q9: Could not fetch //b.yjtag.jp/iframe?c=g7Rx6Q9
InvalidUrlException "//b.yjtag.jp/iframe?c=g7Rx6Q9" "Invalid URL"
[WARNING] Duplicate identifier 'title' at input line 9916 column 73
[WARNING] Duplicate identifier 'blog-description' at input line 9918 column 110
[WARNING] Could not fetch resource //b.yjtag.jp/iframe?c=g7Rx6Q9: Could not fetch //b.yjtag.jp/iframe?c=g7Rx6Q9
InvalidUrlException "//b.yjtag.jp/iframe?c=g7Rx6Q9" "Invalid URL"
[WARNING] Duplicate identifier 'title' at input line 12956 column 80
[WARNING] Duplicate identifier 'blog-description' at input line 12958 column 73
[WARNING] Duplicate identifier 'title' at input line 14391 column 94
[WARNING] Duplicate identifier 'blog-description' at input line 14393 column 51
[WARNING] Could not fetch resource /assets/blog/profile.png: PandocIOError "/assets/blog/profile.png" /assets/blog/profile.png: openBinaryFile: does not exist (No such file or directory)
[WARNING] Could not fetch resource /assets/images/author/2014/Y_Kato_manage_blue.png: PandocIOError "/assets/images/author/2014/Y_Kato_manage_blue.png" /assets/images/author/2014/Y_Kato_manage_blue.png: openBinaryFile: does not exist (No such file or directory)
[WARNING] Could not fetch resource /assets/templates/gihyojp2022/images/twitter.svg: PandocIOError "/assets/templates/gihyojp2022/images/twitter.svg" /assets/templates/gihyojp2022/images/twitter.svg: openBinaryFile: does not exist (No such file or directory)
[WARNING] Could not fetch resource /assets/templates/gihyojp2022/images/facebook.svg: PandocIOError "/assets/templates/gihyojp2022/images/facebook.svg" /assets/templates/gihyojp2022/images/facebook.svg: openBinaryFile: does not exist (No such file or directory)
[WARNING] Could not fetch resource /assets/templates/gihyojp2022/images/hatena.svg: PandocIOError "/assets/templates/gihyojp2022/images/hatena.svg" /assets/templates/gihyojp2022/images/hatena.svg: openBinaryFile: does not exist (No such file or directory)
いっぱいwarning出てきましたが、なんとかEPUBとして出力できました。
ダウンロードの表示も邪魔なので外部URLの取得もcurl -fsSLとしたほうが良かったかもしれません。
複数カレンダー対応
次に2021年のPythonアドベントカレンダーを試してみました。
いかん、カレンダーが4つもある...
よく考えればここまで考えてスクリプトを組むべきでした。
アドベントカレンダーの構造が2020年以前と2021年以降で異なるようです。
- 2020年以前: 複数のカレンダーにまたがる場合は、複数のページに分けてリンクを記載。
- 2021年以降: 複数のカレンダーにまたがる場合は、1つのページにすべてのリンクを記載。
複数のカレンダー対応(2021年以降)
ここでは、1つのページにすべての外部リンクが記載された2021年以降のバージョンに対応したスクリプトを書きます。
順序キープしたままの重複削除はややこしいので、もうこの際 アドベントカレンダーの日付順 という縛りは無視して、
簡単な重複削除としてsort | uniqを使います。
YEAR="2021"
THEME="Python"
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
curl -fsSL $URL |
grep -oP '<table.*?</table>' | # tableタグのみ
grep -oP '<a href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' | # URLのみ
sort | uniq # 重複削除
https://blog.tsukumijima.net/article/python-nuitka-usage/
https://blog.utgw.net/entry/2021/12/17/093604
https://chanyou.hatenablog.jp/entry/symmetric-api-testing-python
https://d.nishimotz.com/archives/2405
https://daikikatsuragawa.hatenablog.com/entry/2021/12/18/120000
https://kentapt.hatenablog.com/entry/2022/01/03/141924?_ga=2.246246721.494030156.1641034049-1601353361.1630730568
https://nakagami.blog.ss-blog.jp/2021-12-04
https://nakagami.blog.ss-blog.jp/2021-12-07
https://nakagami.blog.ss-blog.jp/2021-12-11
https://nakagami.blog.ss-blog.jp/2021-12-14
https://nikkie-ftnext.hatenablog.com/entry/how-to-colorize-terminal-output
https://note.com/naoki_fujita/n/n12bb9588eee4
https://qiita.com/8_hisakichi_8/items/778059dceccd08b1630c
https://qiita.com/Altaka4128/items/eb4e9cb0bf46d450b03f
https://qiita.com/Brutus/items/256af9bc203966b18cd7
https://qiita.com/DeepTama/items/4bf9e3139471918eb0fe
https://qiita.com/HGS_Naofumi/items/9cac3f4eb08b79efd072
https://qiita.com/Hagian/items/4de129b6b5d3744515dc
https://qiita.com/Intel0tw5727/items/6988c62ce4aaa681b151
https://qiita.com/NGOhiroshi/items/7a810c12d310154fbc5d
https://qiita.com/NSsystems_DX/items/18a01f195c31f1d1db8c
https://qiita.com/Supu/items/d90175ddd72f0f3e9f11
https://qiita.com/YottyPG/items/ed425fa28ad0e4eb1200
https://qiita.com/ZakkyR/items/b44afb3c19f090632f20
https://qiita.com/abenben/items/fef721c9acbb2fe35f90
https://qiita.com/akihiro_suto/items/81ac26e066791ec60f72
https://qiita.com/bellvine/items/a99a385e58ad2199a5ce
https://qiita.com/c60evaporator/items/f92dff60a46317b7d967
https://qiita.com/cvusk/items/fcda5e77350f248d39e5
https://qiita.com/glyzinieh/items/1ad567c2f2268cd1c185
https://qiita.com/glyzinieh/items/d0343b43a7926b23929a
https://qiita.com/guravity/items/e32046face541ca48d5e
https://qiita.com/higebobo/items/0df815a7b6378854e39d
https://qiita.com/hkwsdgea_ttt2/items/970f34e1aa59059f7c69
https://qiita.com/hoshi_kouki/items/b932710304df3e6cc65a
https://qiita.com/hydrogen_0330/items/59dfa37ceb3bb19b6372
https://qiita.com/hydrogen_0330/items/b32ff007f19258951118
https://qiita.com/ijufumi/items/3609a983cd0673383f69
https://qiita.com/ijufumi/items/52abed9ce4205fd0eff3
https://qiita.com/ijufumi/items/6dfee715b40979017d1d
https://qiita.com/ijufumi/items/d1149f3d4c0034235799
https://qiita.com/kaizen_nagoya/items/1b7281a69eed47805e4a
https://qiita.com/kaizen_nagoya/items/290b10c701724f22be53
https://qiita.com/kanjas20/items/c120c41542460d7056b8
https://qiita.com/kenbu/items/8182cddf2d01da8679cd
https://qiita.com/ku_a_i/items/e3fe06f24741bb7d6db7
https://qiita.com/kuro_take/items/b753ff5daf03aed20682
https://qiita.com/miso_taku/items/8e3d5bd012c23bddc6a6
https://qiita.com/n_slender/items/3e0b3644b708ee1d8a20
https://qiita.com/n_slender/items/863c2899bb08f38e5f15
https://qiita.com/n_slender/items/c08a0611449cfd4e802c
https://qiita.com/n_slender/items/e621666b7ef85f563c86
https://qiita.com/ny7760/items/d9c247781a790210936d
https://qiita.com/okateru/items/1b90eab9483eb4ed38e4
https://qiita.com/okpingu109/items/64267842851ef3d40742
https://qiita.com/phyblas/items/d56003904c83938823f2
https://qiita.com/ponnhide/items/35dcf52ec98a2a39839f
https://qiita.com/ryusuke920/items/4a3bf6cd07d4df39c06e
https://qiita.com/saka212/items/a9a59dca40b34018910a
https://qiita.com/satto_sann/items/4c754595cf9119330c45
https://qiita.com/seigot/items/1e455e5b65284eddc4d0
https://qiita.com/simonritchie/items/045fd2373565f3e49036
https://qiita.com/simonritchie/items/10d3be5e35fff8f3f368
https://qiita.com/simonritchie/items/26f7da93ac85f60b2972
https://qiita.com/simonritchie/items/44242479f0df86fffff5
https://qiita.com/simonritchie/items/4c19b723f623a3b3df8f
https://qiita.com/simonritchie/items/7d8382e821dd1e9bd98b
https://qiita.com/tasuren/items/2999f5c662c846260b36
https://qiita.com/waterada/items/1c03a7c863faf9327595
https://qiita.com/yasudadesu/items/f7f8fc3af984bcc55a55
https://qiita.com/youichi_io/items/861bd760e6b496cf2f4a
https://qiita.com/yutoun/items/2ea452bb4a76e156e6eb
https://qiita.com/yutoun/items/5ba4697550c27dd2b8d1
https://ryuichi1208.hateblo.jp/entry/2021/12/01/234631
https://sandfishfactory.hatenablog.com/entry/2021/12/14/000000
https://shinyorke.hatenablog.com/entry/python2022
https://zenn.dev/bluepost/articles/22327195c09314
https://zenn.dev/hamakou108/articles/5896bfc162ba65
https://zenn.dev/nekoallergy/articles/sklearn-nn-mlpclf01
https://zenn.dev/sikkim/articles/3be1841603a06619fa2c
https://zenn.dev/whitphx/articles/streamlit-realtime-cv-app
https://zenn.dev/yukinarit/articles/3fbba1b5414b69
https://zenn.dev/yukinarit/articles/afb263bf68fff2
83行取得できました。
カレンダーを数えてみても83個の外部リンクがあるので、この方法でうまくいくでしょう。
順序は守られず、アドベントカレンダーの何日目かは、記事の内容に書いてあったりなかったり書き手次第ですが、とりあえずテーマはまとまっていて年号ごとのアドベントカレンダー記事であるという情報はわかります。
sortオプションで重複削除(ボツ)
sort | uniq じゃなくてsort --unique, sort -u
$ man:sort
-u, --unique -c と併せて使用した場合、厳密に順序を確認する。-c を付けずに使用した場合、最初の同一行のみ出力する
YEAR="2021"
THEME="go"
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
curl -fsSL ${URL} |
grep -oP '<table.*?</table>' | # tableタグのみ
grep -oP '<a href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' | # URLのみ
sort -u
https://blog.penguincabinet.com/posts/Fyne-drag-and-drop/
https://blog.potproject.net/2021/12/01/dotenv-goenvgen-oss/
https://blog.yagipy.me/analyze-maintainability-index
https://budougumi0617.github.io/2021/12/20/gomock_verify_in_any_order/
https://deltam.blogspot.com/2021/12/go-recoverable-error.html
https://dev.to/cia_rana/is-golangci-lint-generics-readiness-200n
https://ema-hiro.hatenablog.com/entry/2021/12/07/000040
https://junchang1031.hatenablog.com/entry/2021/12/22/193522
https://k2ss.info/archives/3214/
https://medium.com/@naoto0822/go%E3%81%8B%E3%82%89zetasql%E3%82%92%E4%BD%BF%E3%81%86-b5c904fa76fb
https://medium.com/eureka-engineering/go-bitwise-manipulating-counting-algorithm-4f8bb14893d0
https://morikuni.dev/articles/awgodoc-release
...
83件取得できました。
ただし、順序が辞書順に並び変わってしまいます。
重複なしリスト(連想配列を使う方法)(ボツ)
sh, bashで重複なしarray
YEAR="2021"
THEME="go"
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
arry=(
$(curl -fsSL ${URL} |
grep -oP '<table.*?</table>' | # tableタグのみ
grep -oP '<a href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' # URLのみ
)
)
echo ${#arry[@]} # 重複ありArrayの長さ
declare -A sets
for x in "${arry[@]}"; do
sets[$x]=""
done
echo "${!sets[@]}" # 重複なしArray
echo ${#sets[@]} # 重複なしArrayの長さ
216
https://note.com/homie_inc/n/ncbd6da4f7706 https://zenn.dev/a_ichi1/articles/555c8eed11fdad https://zenn.dev/sivchari/articles/be6cc55d313b12 https://qiita.com/u1and0/items/06b65199a5e11c8d4411 https://zenn.dev/hajimehoshi/articles/72f027db464280 https://qiita.com/masa_ito/items/e3f21dd43e1013732755 https://www.m3tech.blog/entry/go-json-es https://qiita.com/ShintaNakama/ite
...
83
83件取得できましたが、順序がばらばらになりました。
重複なしリスト(awkを使う方法)
awkを使って重複を削除すると、順序を変えずに重複を削除できる1ようです。
$0は行全体を示すので、A、B、Cがそれぞれ行を読み込む度に代入される。
なので、パイプの右側で下記のような計算が実施されてることになる。a[A]++ a[B]++ a[C]++最初にその行が現れたときだけ条件が、インクリメントされる前※なので、配列の値が0となり、条件式 a[$0]++ == 0 と'!a[$0]++' は真(つまり 1)になる。
アクションが記載されていない場合、awkは真のときだけ、行の内容を表示するので、最初にその行が現れたときだけ、その行が表示される。
※変数の後につけた場合、後置といって、次に変数が参照される際に、インクリメントが行われる。
$ echo "c\nb\na\nb"
c
b
a
b
$ echo "c\nb\na\nb" | awk '!a[$0]++'
c
b
a
なるほど!
先程までのURL取得スクリプトの末尾にawk '!a[$0]++'を追記します。
YEAR="2021"
THEME="go"
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
curl -fsSL ${URL} |
grep -oP '<table.*?</table>' | # tableタグのみ
grep -oP '<a href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' | # URLのみ
awk '!a[$0]++'
https://qiita.com/jiro4989/items/2530c4f789916521a47a
https://zenn.dev/ww24/articles/beae98be198c94
https://zenn.dev/sivchari/articles/be6cc55d313b12
https://qiita.com/yyoshiki41/items/5660f22278e96de1e5a4
https://qiita.com/masa_ito/items/e3f21dd43e1013732755
...
83件取得できました。
元リンクのアドベントカレンダー2021 Goのページでも順番かつ重複無しでURLを取得できたことをざっと確認できました。
2021年以降のカレンダーにはこれを使っていきたいと思います。
YEAR="2021"
THEME="Python"
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
curl -fsSL ${URL} |
grep -oP '<table.*?</table>' | # tableタグのみ
grep -oP '<a href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' | # URLのみ
sort | uniq | # 重複削除
xargs -n1 curl -fsSL | # アドベントカレンダー上の外部リンクから得られるHTMLの一括ダウンロード
pandoc -s -f html -t epub3 --toc --toc-depth=3 -o Qiitaアドベントカレンダー${YEAR}${THEME}.epub
上記コマンドを実行してアドベントカレンダー2021のPythonカレンダーを4つまとめようと思いましたが、メモリを5GBも喰うわ、CPU100%状態が続くわ、5時間経っても終わらないわで中断しました。
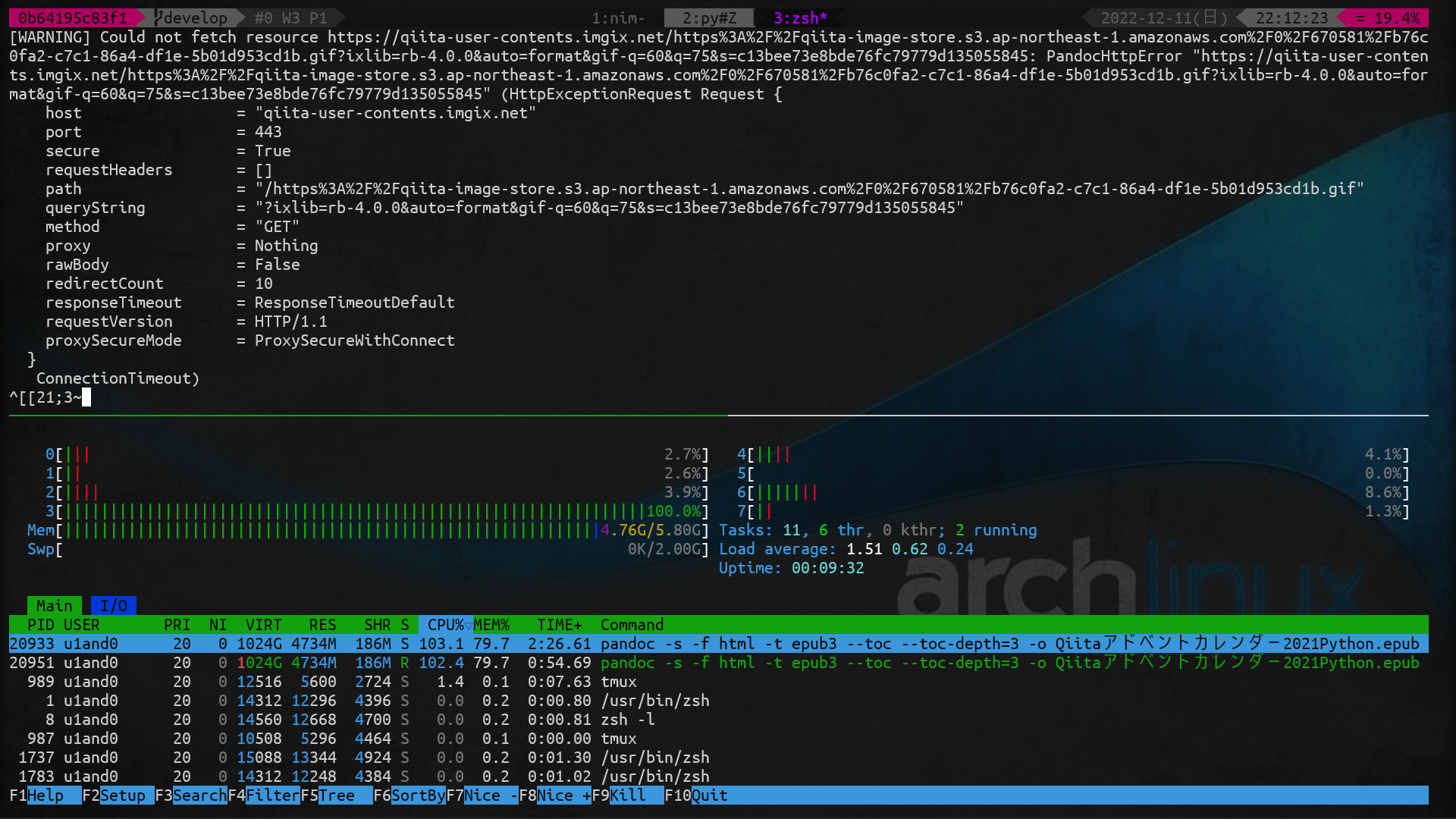
マシンリソース食い過ぎ
自宅の32GBメモリのデスクトップなら1分ほど待つだけで終了しました。
WSL通したのが悪いのか、ノートのスペックが貧弱なのか。
とにかく、URLの数が多い場合はマシンリソースに注意してください。
複数のカレンダー対応(2020年以前)
ここでは、複数のページに外部リンクが記載された2020年以前のバージョンに対応したスクリプトを書きます。
単純にURLを複数並べていく
YEAR="2020"
THEME="Nim"
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
curl -fsSL ${URL}{,-2} | # 複数ページにまたがる場合はここにすべてのカレンダーURLを記載
grep -oP '<table.*?</table>' | # tableタグのみ
grep -oP '<a href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' # URLのみ
${URL}{,-2}でカンマ区切りすると、${URL}と${URL}-2のように展開されます。(ブレース展開とか言う名前がついてたような?)
https://qiita.com/jiro4989/items/499f145da6dda6b725ef
https://qiita.com/fox_0430/items/5385522ac923a10d0103
https://qiita.com/jiro4989/items/448254aa66adbdd0b846
https://qiita.com/jiro4989/items/d9769b4cdb5475509204
https://qiita.com/frodo821/items/a5cb988674a8f8555c8f
https://qiita.com/momeemt/items/000d1f6c384f4f00e103
https://qiita.com/dumblepy/items/be660c17556d73aa3570
https://qiita.com/jiro4989/items/7d6d707fa5ab9a5dd25d
https://qiita.com/nnahito/items/d1fe5b18e02bdab97ba0
https://qiita.com/momeemt/items/c3fc62ee86b0d36a30d5
https://qiita.com/pianopia/items/158cb29c1e4a6b55e6c4
https://qiita.com/6in/items/66c1a3d2d43b3b5cc869
https://qiita.com/6in/items/2067b71e3b1a10880bad
https://qiita.com/dumblepy/items/9417626f33de19fe14ba
...
50行取得できました。
複数ページにまたがる場合は最初のcurlで外部リンクを収集する際にすべてのカレンダーのリンクを記載します。
ここでは 2020/nimカレンダーと 2020/nim-2カレンダーを取得しました。
Vim(エディタの)カレンダーでは2020/vim2となるようで、ハイフンがついたりつかなかったりの規則がカレンダーによって異なるようなので、取得前に実際のページへ行ってURLの規則を確認する必要があります。
sort | uniqしなくてもページの重複がないURL一覧を取得できました。
複数に分かれるカレンダーのURLもスクレイピングから取得できる
元URLとそこからリンクされている https://qiita.com/advent-calendar/2020/nim から始まるURLだけを抜き出しました。
$ URL="https://qiita.com/advent-calendar/2020/nim"
$ curl -fsSL $URL |
grep -oP '<a href="'$URL'.*?>' |
sed -r 's_^.*href="([^"]+)".*$_\1_'
https://qiita.com/advent-calendar/2020/nim
https://qiita.com/advent-calendar/2020/nim-2
これをスクレイプ元のURLに入れてあげればいいわけですね。
しかしながら、カレンダーごとにその年のカレンダーをすべて列挙していたり、現在のカレンダー以外を表示していたりと仕様が異なっています。 汎用ではありませんのでもうひとひねり必要。
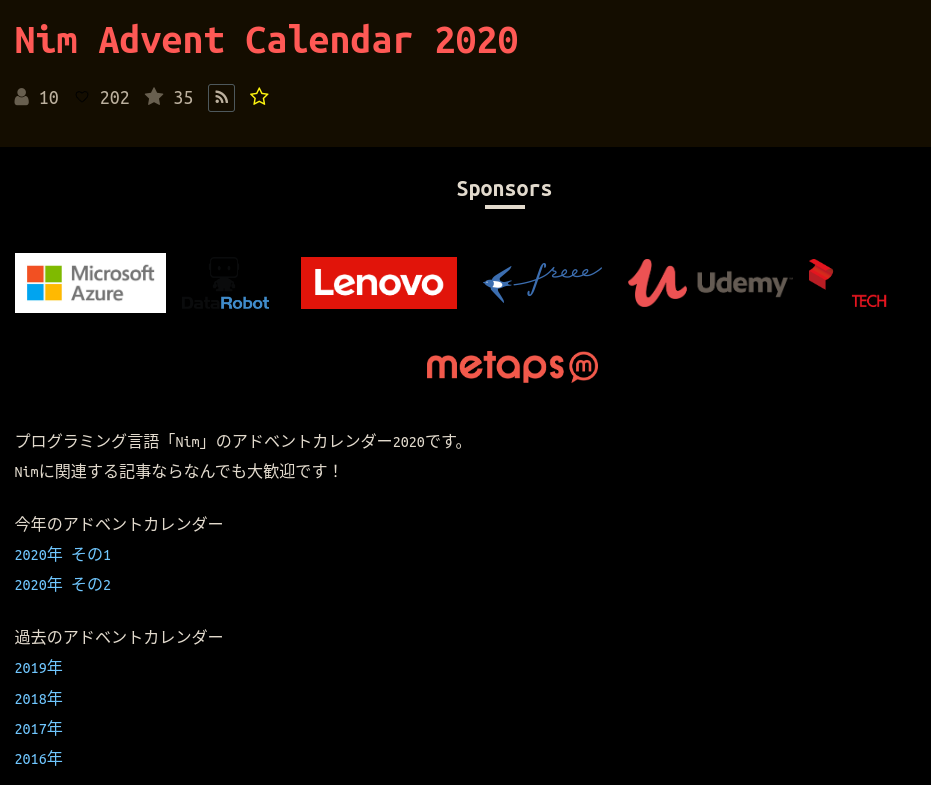
その年のすべてのカレンダーを列挙する2020年Nim2カレンダーの例。

その1のカレンダーにその2のカレンダーのURLだけ記載する2020年Vim2カレンダーの例。
さっきのawkで重複削除する方法を使いましょう。
YEAR=2020
THEME=nim
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
OTHER_CALENDAR=$(curl -fsSL ${URL} |
grep -oP '<a href="'${URL}'.*?>' |
sed -r 's_^.*href="([^"]+)".*$_\1_'
)
echo ${URL} ${OTHER_CALENDAR} | tr ' ' '\n' | awk '!a[$0]++'
リンクされているその2以降のカレンダーをOTHER_CALENDAR変数に入れ、
その次のechoで元URLとその2以降のURLを並べて、awkで順序を守った重複削除をします。
https://qiita.com/advent-calendar/2020/nim
https://qiita.com/advent-calendar/2020/nim-2
2020年NimカレンダーのURLを重複なく、すべて取得できました。
YEAR=2020
THEME=vim
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
OTHER_CALENDAR=$(curl -fsSL ${URL} |
grep -oP '<a href="'${URL}'.*?>' |
sed -r 's_^.*href="([^"]+)".*$_\1_'
)
echo ${URL} ${OTHER_CALENDAR} | tr ' ' '\n' | awk '!a[$0]++'
https://qiita.com/advent-calendar/2020/vim
https://qiita.com/advent-calendar/2020/vim2
2020年VimカレンダーのURLを重複なく、すべて取得できました。
...とここですべての外部リンクが取得できない問題。
2020年のVimカレンダーのQiita以外の記事がaタグの書き方が異なっていました。
target blankで新しいタブを開くようになってる。。。
<a target="_blank" rel="noopener noreferrer" href="https://zenn.dev/raa0121/articles/mingw-gvim-transparency">mingw-gvim-transparency を作った話 <span class="fa fa-external-link"></span></a>
aタグの中身がすぐhrefで始まらなくても取得できるように変更しました。
YEAR=2020
THEME=vim
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
OTHER_CALENDAR=$(curl -fsSL ${URL} |
grep -oP '<a href="'${URL}'.*?>' |
sed -r 's_^.*href="([^"]+)".*$_\1_'
)
CALENDARS=$(echo ${URL} ${OTHER_CALENDAR} | tr ' ' '\n' | awk '!a[$0]++')
curl -fsSL ${CALENDARS} |
grep -oP '<table.*?</table>' | # tableタグのみ
+ grep -oP '<a .*?href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
- grep -oP '<a href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' #| # URLのみ
awk '!a[$0]++' #| 順序変えなし重複削除
https://qiita.com/gorilla0513/items/480d454ca74868eb07bd
https://qiita.com/mira010/items/6278d604eefb926db937
https://daisuzu.hatenablog.com/entry/2020/12/03/003629
https://kaneshin.co/posts/advent-calendar-2020-vim
https://qiita.com/uyo/items/d26a76d7ed7c8d8f9918
https://zenn.dev/uji/articles/112da02adc7ff3
https://imokuri123.com/blog/2020/12/neovim-init-lua/
https://zenn.dev/skanehira/articles/2020-12-25-vim-beatbanana
https://zenn.dev/skanehira/articles/2020-12-05-vim-my-philosophy
...
49件取得できました。
これでその1, その2のようにカレンダー数が多すぎてシリーズが分割されているアドベントカレンダーもすべて取得できるようになりました。
ただし、シリーズのURLが記載されているページのみ対象です。普通は記載されていると思いますが。
Send to Kindleの制約
Kindleのパーソナルドキュメントで開けるファイルは50MBまで
2021年のPythonカレンダーはダウンロードしてみるとすべてのカレンダー合わせてファイルサイズが85.1 MBもあります。
これではKindleへ送れない...。3
この方法では、50MBまでのファイルを送信することができます(※他の方法を含めて、50MB以上を送信する方法はなさそう)。
GmailやYahoo!メールなどからSend-to-Kindleを利用しようにも、添付ファイルのサイズ上限が25MBまであり、ファイルサイズが大きい電子書籍の場合は困ってしまいます。
50MBすら軽く超えてます。困った...
USBをKindleにつなげて直接送るか。4
しかし、そのためにはepubをmodiに変換する必要がありそうです。
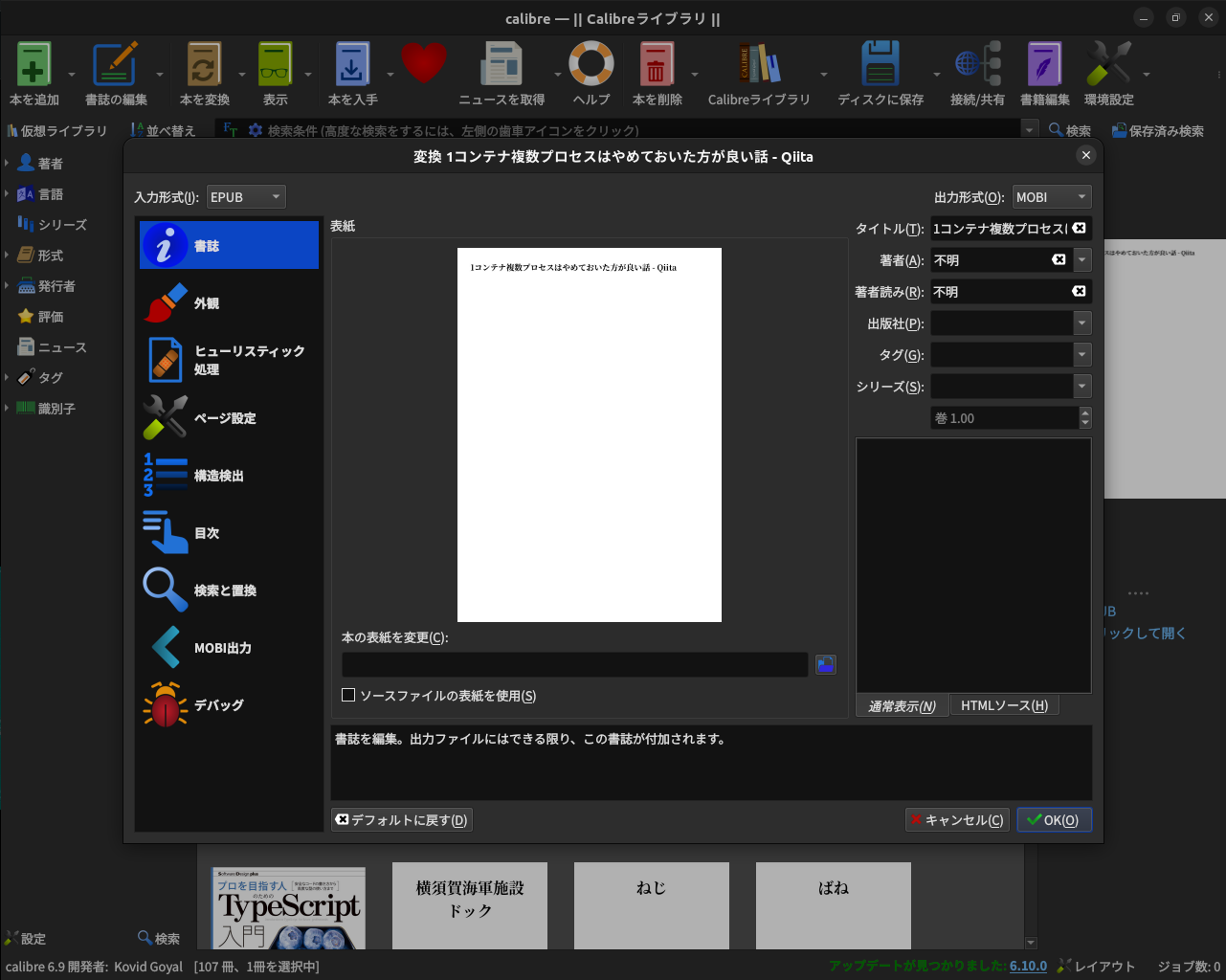
電子書籍管理ツールCaribreを使ってepub -> mobiへの変換。
残念ながらpandocはmobiのIOに対応していない。
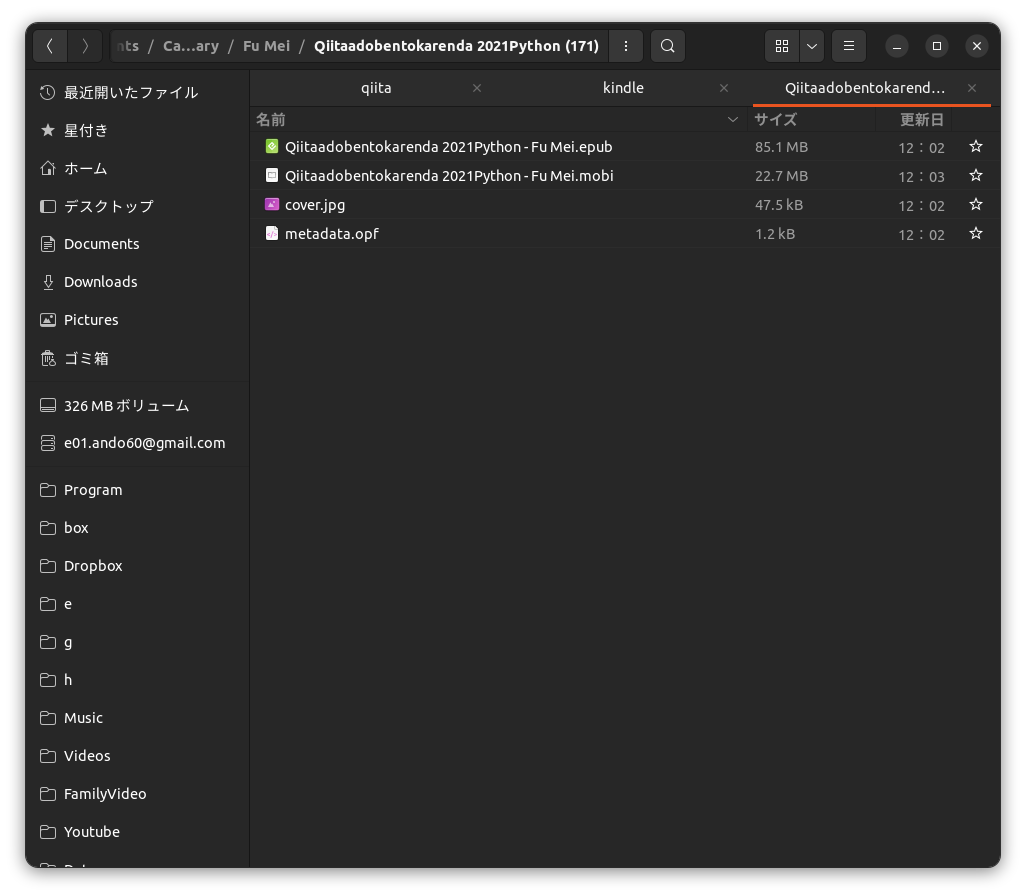
Calibreを使ってmobiに変換すると85.1MB->22.MBまでサイズダウンしました。
gifとかがなくなるからでしょうか?(EPUBだとgifアニメーションが動いていました。
これでSend to Kindleできます。
最終的なShellscript
年次とテーマを外部引数にしてスクリプトを実行できるようにしました。
#!/bin/sh
YEAR=$1
THEME=$2
URL="https://qiita.com/advent-calendar/${YEAR}/${THEME}"
# カレンダー数が多すぎてその1その2のように分割されている場合
# シリーズカレンダーのリンクを取得
OTHER_CALENDAR=$(curl -fsSL ${URL} |
grep -oP '<a href="'${URL}'.*?>' |
sed -r 's_^.*href="([^"]+)".*$_\1_')
# 元カレンダーURLとシリーズカレンダーの重複削除
CALENDARS=$(echo ${URL} ${OTHER_CALENDAR} | tr ' ' '\n' | awk '!a[$0]++')
# 記事のHTMLを取得してepub化
curl -fsSL ${CALENDARS} |
grep -oP '<table.*?</table>' | # tableタグのみ
grep -oP '<a .*?href="https?:.*?</a>' | # http:, https:が含まれるaタグのみ
sed -r 's_^.*?href="([^"]+)".*$_\1_' | # URLのみ
awk '!a[$0]++' | # 順序変えなし重複削除
xargs -n1 curl -fsSL | # アドベントカレンダー上の外部リンクから得られるHTMLの一括ダウンロード
pandoc -s -f html -t epub3 --toc --toc-depth=3 -o Qiitaアドベントカレンダー${YEAR}${THEME}.epub
例として、下記のコマンドで2020年のVimアドベントカレンダーをEPUB化します。
渡す引数は第1引数に年(例: 2020)と第2引数にテーマ(例: Vim)を指定します。
引数に与えた文字列がファイルのタイトルに使われるので、大文字、小文字に注意してください。
Qiita記事には大文字小文字区別なしでアクセスできます。
$ ./scrape-advent-calendar.sh 2020 Vim
上記コマンドで2020年のVimアドベントカレンダーをまとめて、Qiitaアドベントカレンダー2020vim.epubが出力されます。
Qiitaアドベントカレンダーを電子書籍化するDockerイメージ
pandocコマンドが使える環境を用意するのがメンドクサイ?
そんな人にDockerイメージu1and0/qiita-advent-calendar-epubを用意しました5。
ベースイメージにcurlがなかったので追加しました。
grepコマンドはありましたが、buzyboxのビルトインでは-Pオプションが使えなかったので、あえてインストールしました。
tlmgrは知らない名前でしたが、LaTeXのパッケージ管理ツールの名前だそうです。
FROM "pandoc/latex"
RUN apk --update --no-cache add grep curl && \
tlmgr update --self --all && \
tlmgr install collection-langjapanese
COPY scrape-advent-calendar.sh /usr/bin
RUN chmod +x /usr/bin/scrape-advent-calendar.sh
ENTRYPOINT ["/usr/bin/scrape-advent-calendar.sh"]
LABEL maintainer="u1and0 <e01.ando60@gmail.com>"
使い方は本家dockerhub - pandoc/latexにあるような例とほぼ一緒です。
$ docker run --rm \
--volume $(pwd):/data \
--user $(id -u):$(id -g) \
u1and0/qiita-advent-calendar-epub \
2022 Go
まとめ
アドベントカレンダーは年々少しずつページの構造が変わっているので、取得先の情報に合わせて本カレンダーでやっているようにscrape-advent-calendar.shに手を入れる必要性がありますので、汎用的に使えるためには将来的にシェルスクリプトに手を入れてイメージをビルドし直さなければならないかもしれません。
HTMLの生成はある程度自動化されていますが、構造は人間が考えるものなので将来的にページの構造が変わってしまうかもしれません。2020年前後でカレンダーが分割されていたり1ページにまとめられていなかったように、スクレイピングのためのスクリプトは構造に合わせて柔軟に変えていく必要があります。
[おまけ]Shellscript記事を書くにあたって有用だったVimコマンド
本筋とは異なりますが、本記事を書くにあたって有用だったVimコマンドを紹介します。
:r # 代替バッファから読み込み
カレントバッファにQiita記事(.md)、代替バッファにShellscriptファイル(.sh)を開いているとして、代替バッファのShellscriptを現在の行に書き込みます。
Vimのコマンドラインにて、:#が代替バッファという意味です。
:w >> # 代替バッファへ追加書き込み
カレントバッファにShellscriptファイル(.sh)、代替バッファにQiita記事(.md)を開いているとして、Qiita記事(.md)の行末に今のShellscriptを書き込みます。
>が上書き, >>が追加書き込みです。
$r !sh % スクリプトの結果を行末に書き込み
カレントバッファにShellscriptファイル(.sh)を開いているとして、スクリプトの行末に現在のスクリプトの結果を書き込みます。
:$が行末という意味です。
-
Nimはプログラミング言語の名前で、Vimはエディタの名前です。マイナーかつ名前が似ているものを例にしてしまって恐縮です。Nim - Wikipedia / Vim - Wikipedia ↩ ↩2
-
【Send-to-Kindle】メールを使わず25MB以上の電子書籍ファイルをアップロードしてKindleで読む方法(日本で利用可能) ↩