概要
PyTorchの自然言語処理をしていると、EmbeddingBagというやつが出てくるので、これは何?という話。
超初歩的な話なので、詳しい方は見なくて大丈夫です。
時間がない人向け
Embedding: Outputのshape=$(InputLength \times EmbeddingDim)$
$$
Output = x_{one-hot} \cdot W
$$
EmbeddingBag: Outputのshape=$(EmbeddingDim)$
$$
Output = sum_i(x_{one-hot} \cdot W)
$$
解説
まずは何が行われているのかを簡単に解説します。
変数の定義
\begin{align}
& Input \quad x: \quad(InputLength)\\
& Embedding Weight \quad W: \quad(VocabLength \times EmbeddingDim)\\
& Output \quad y
\end{align}
入力
文章をインデックス化した、トークン列。下記例だと[0,3,1,2]を渡せば良い。

内部の演算的には、入力xは下記のような、行:入力単語数x列:Vocabulary数のOne-Hotな行列に変換される。
下記例はVocabulary数が5で、入力長さが[i read a book]の4の場合。
x_{one-hot}=\begin{pmatrix}
1 & 0 & 0 & 0 & 0\\
0 & 0 & 0 & 1 & 0 \\
0 & 1 & 0 & 0 & 0 \\
0 & 0 & 1 & 0 & 0
\end{pmatrix}
Embeddingの計算
ここはシンプルに埋め込み行列との掛け算が行われる。埋め込み行列は行:Vocabolary数x列:EmbeddingDim数の行列である。これと入力xとのいわゆる内積で計算が行われる。例えば上記例のようにVocabolary5、EmbeddingDimが2の場合は、下記のようなWeightMatrixとなる。
W=\begin{pmatrix}
w_{11} & w_{12} \\
w_{21} & w_{22} \\
w_{31} & w_{32} \\
w_{41} & w_{42} \\
w_{51} & w_{52} \\
\end{pmatrix}
この出力yは、行:InputLength入力、列:EmbeddingDimとなり、要素を書けば下記のようになる。
y = x_{one-hot} \cdot W\\
=\begin{pmatrix}
w_{11} & w_{12} \\
w_{41} & w_{42} \\
w_{21} & w_{22} \\
w_{31} & w_{32}
\end{pmatrix}
この出力が通常のEmbedding。
EmbeddingBagの計算
公式のDocumentはこちら。
EmbeddingBagは全く難しいことはなく、この最後に得られたyをもう1段階処理列方向にを行うもの。例えばデフォルトではmode="sum"となっているが、その場合はこうなる。
output=\begin{pmatrix}
w_{11}+w_{41}+w_{21}+w_{31} & w_{12}+w_{42}+w_{22}+w_{32}
\end{pmatrix}
=\Sigma_i(y_{ij})
語順に関係なく、全部足し合わせたものである。
もう想像に難くないが、mode="max"とした場合には、上記の$\Sigma$がmax演算となる。
確認
実際に動かして動作を見てみます。
Embeddingの確認
実際に上の例をやってみることにする。
再現できるように、Weightはseedで固定している。
import torch
from torch import nn
# Embedding
seed = 0
vocab_size = 5
embed_dim = 2
embedding = nn.Embedding(vocab_size, embed_dim)
torch.manual_seed(seed)
embedding.weight.data.uniform_(-1, 1)
init_weight = embedding.weight.data
print(embedding.weight)
Parameter containing:
tensor([[-0.0075, 0.5364],
[-0.8230, -0.7359],
[-0.3852, 0.2682],
[-0.0198, 0.7929],
[-0.0887, 0.2646]], requires_grad=True)
実際に[0,3,1,2]の文章を埋め込んでみる。
上の結果と合わせて見れば、weightの0,3,1,2番目がOne-Hotnによって取得されているのがよくわかる。
text_idx = torch.LongTensor([0, 3, 1, 2])
print(embedding(text_idx))
tensor([[-0.0075, 0.5364],
[-0.0198, 0.7929],
[-0.8230, -0.7359],
[-0.3852, 0.2682]], grad_fn=<EmbeddingBackward0>)
EmbeddingBagの確認
mode="sum"で解説したとおりの確認を行う。
# EmbeddingBag
mode = "sum"
embedding_bag = nn.EmbeddingBag(vocab_size, embed_dim, mode=mode)
embedding_bag.weight.data = init_weight
offset = torch.LongTensor([0])
print("EmbeddingBagの結果")
print(embedding_bag(text_idx, offset))
print("Embedding+加算の結果")
print(embedding(text_idx).sum(axis=0))
まったく同様の結果となることが確認できる。
EmbeddingBagの結果
tensor([[-1.2355, 0.8616]], grad_fn=<EmbeddingBagBackward0>)
Embedding+加算の結果
tensor([-1.2355, 0.8616], grad_fn=<SumBackward1>)
offsetって何?
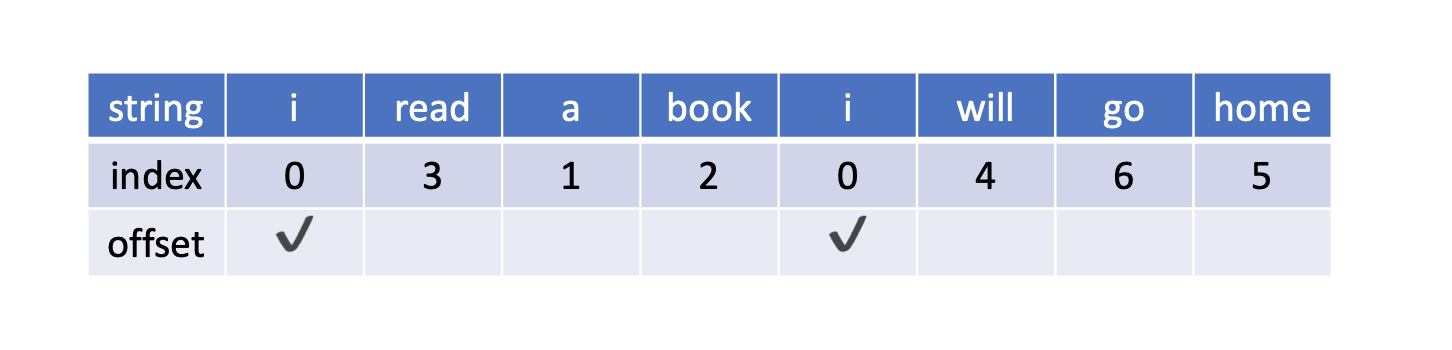
最後にEmbeddingBagのoffsetって何?という話。EmbeddingBagは1次元の入力を、offset位置によって区切ってembedingすることが可能。
2つの例でご紹介。
- 例えば一文字ずつ埋め込みたいなら、長さ分だけの配列を用意してあげる。上の例ならoffset=[0,1,2,3]として叩くだけ。
offset = torch.LongTensor([0,1,2,3])
print(embedding_bag(text_idx, offset))
>tensor([[-0.0075, 0.5364],
[-0.0198, 0.7929],
[-0.8230, -0.7359],
[-0.3852, 0.2682]], grad_fn=<EmbeddingBagBackward0>)
- 例えば複数の文を全部flatに繋いだあとに、文頭をoffsetに指定してあげれば、勝手に切り取って埋め込んでくれる。PyTorchのExampleはこの例かな。イメージはこういう感じ。このときの設定は、offset=[0, 4]となる。(Vocabolaryが増えてるじゃないかというツッコミはなしで。)