SPSS ModelerでRFM集計を行うノードをPythonで書き換えてみます。
RFM集計ノードは以下の記事で解説されていますが、購買取引データから顧客価値を示すRFMの値を算出するノードとなります。
SPSS Modeler ノードリファレンス 2-13 RFM集計
- Recency : 最新の購入日から経過した日数
- Frequency : 購入回数
- Monetary : 購入金額の合計

SPSS Modelerでは下記の設定でRFMの集計を行います。
- Recencyの基準日を2019/12/31とする
- 2000以下の値を持つレコードを破棄
- 2019/09/01以降のトランザクションデータを用いて集計
- 2、3番目のリーセントトランザクション日付(基準日からの経過日数)を保存

これをPythonで実装します。
データの読み込み
トランザクションデータを読み込みます。その際、SDATEを日付型として読み込みます。
df_tran = pd.read_csv("sampletranDEPT4en2019.csv", parse_dates=['SDATE'])
読み込んだデータの上から5行を覗いてみます。
df_tran.head()

以下のカラムを使用し、集計をしていきます。
-
CUSTID: 顧客ID -
SDATE: 購入日 -
SUBTOTAL: 購入金額
データの前処理
NOWにRecencyの基準日を代入します。
今回は、トランザクションデータ内の最新日時である2019/12/31が基準日となっています。
# トランザクションデータ内の最新日時を取得し、Recencyの基準日(2019/12/31)とする
NOW=df_tran["SDATE"].max()
2019/09/01以降を集計の対象とします。
# 指定日以降のトランザクションデータを集計の対象とする
df_tran=df_tran[df_tran["SDATE"]>="2019-09-01"]
2000以下の値をもつレコードを破棄します。
# 指定の値以下のレコードを破棄
df_tran=df_tran[df_tran["SUBTOTAL"]>2000]
RFM集計
groupby()によってCUSTIDでグループ化し、agg()で集計を行います。
集計内容は下記の通りです。
-
SDATEでは、- 最後の購入日から基準日への経過日数(Recency)を算出します。
-
countを用いて購入回数(Frequency)を算出します。 - 日付をソートし、2番目のリーセントトランザクション日付(R2)を算出します。値を持たない場合は欠損値
pd.NAで埋めます。 - 日付をソートし、3番目のリーセントトランザクション日付(R3)を算出します。値を持たない場合は欠損値
pd.NAで埋めます。
-
SUBTOTALでは、sumを用いて購入金額の合計(Monetary)を算出します。
集計後reset_index()によってDataFrameの行番号を振り直します。
# Recency,Frequency,Monetary,R2,R3を集計する
ID="CUSTID"
df_rfm = (
df_tran.groupby(ID)
.agg(
{
"SDATE": [
lambda date: (NOW - date.max()).days,
"count",
lambda date: (NOW - sorted(date)[-2]).days
if len(date) > 1
else pd.NA,
lambda date: (NOW - sorted(date)[-3]).days
if len(date) > 2
else pd.NA,
],
"SUBTOTAL": "sum",
}
)
.reset_index()
)
最後にカラム名をそれぞれRecency,Frequency,Monetary,R2,R3に変更し、順番を並び替えて完成です。
# カラム名の変更と順番の並び替え
df_rfm.columns=[ID,"Recency","Frequency","R2","R3","Monetary"]
df_rfm=df_rfm.reindex(columns=[ID,"Recency","Frequency","Monetary","R2","R3"])
集計結果を確認
PythonとSPSS Modelerでそれぞれ結果を見て、一致することを確認出来ました。
Pythonの実行結果
df_rfm

SPSS Modelerの実行結果
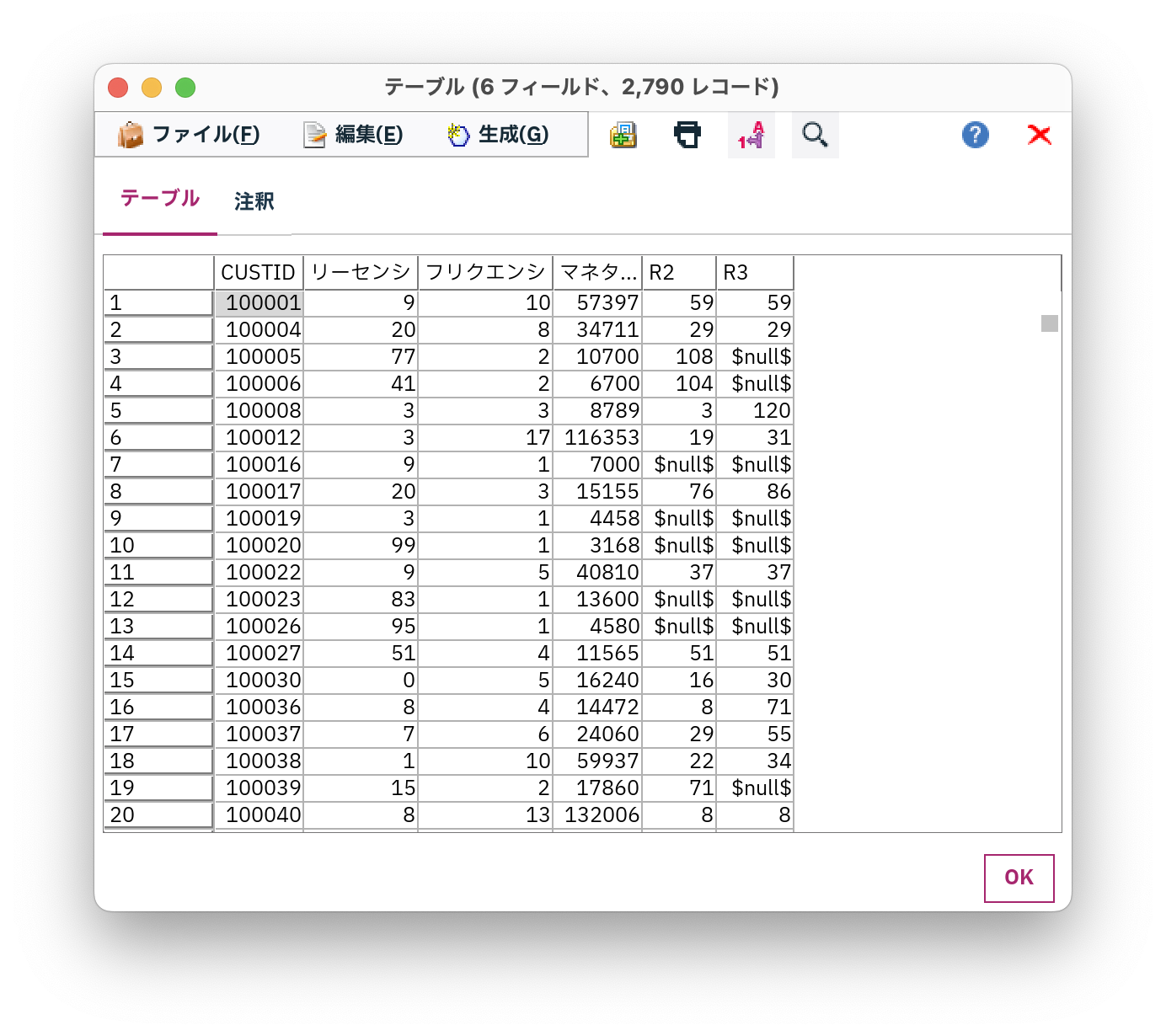
サンプル
サンプルは以下に置きました。
■テスト環境
Modeler 18.4
MacOS Monterey 12.5.1
Python 3.10
pandas 1.4.4