はじめに
Part-1では、CDH(Cloudera's Distribution including Apache Hadoop)をVitualBoxに載せてちょっとした動作確認をするところまで実施しました。
今回はTutorialをやってみることにします。
内容は以下より。
https://www.cloudera.com/developers/get-started-with-hadoop-tutorial/exercise-1.html
Part-1はこちら
Part-3はこちら
Part-4はこちら
1. 前提
以下の環境で動作した内容を記述しています。
Windows 10 Home (64bit)
VirtualBox 5.2
CDH 5.12
2. Ingest and query relational data
2.1 MySQLからデータをHiveにIngest
Sandboxを起動するとデフォルトでmysqlが起動しています。そこからテストデータをSqoopクライアントで抽出し、Hiveに取り込みます。プロセスを見ると確かにmysqlが起動しています。
[cloudera@quickstart ~]$ ps -aef | grep sql
root 4907 1 0 09:04 ? 00:00:00 /bin/sh /usr/bin/mysqld_safe --datadir=/var/lib/mysql --socket=/var/lib/mysql/mysql.sock --pid-file=/var/run/mysqld/mysqld.pid --basedir=/usr --user=mysql
mysql 5027 4907 0 09:04 ? 00:00:02 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --user=mysql --log-error=/var/log/mysqld.log --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/lib/mysql/mysql.sock
取り込むコマンドは以下になります。
[cloudera@quickstart ~]$ sqoop import-all-tables \
-m 1 \
--connect jdbc:mysql://quickstart:3306/retail_db \
--username=retail_dba \
--password=cloudera \
--compression-codec=snappy \
--as-parquetfile \
--warehouse-dir=/user/hive/warehouse \
--hive-import
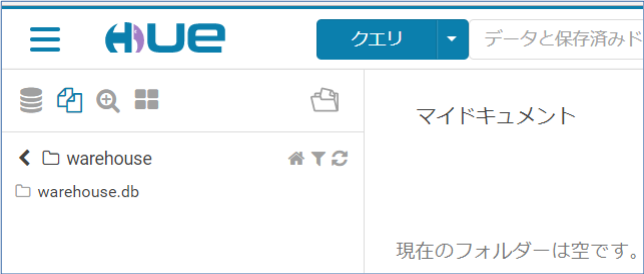
取り込み先をHUEで確認してみます。(何もありません)
実行結果は以下の通りです。Exceptionが発生していますが、Warningなのでとりあえず無視します。
[cloudera@quickstart ~]$ sqoop import-all-tables \
> -m 1 \
> --connect jdbc:mysql://quickstart:3306/retail_db \
> --username=retail_dba \
> --password=cloudera \
> --compression-codec=snappy \
> --as-parquetfile \
> --warehouse-dir=/user/hive/warehouse \
> --hive-import
Warning: /usr/lib/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
18/03/31 09:36:15 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.12.0
18/03/31 09:36:15 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
18/03/31 09:36:15 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
18/03/31 09:36:15 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
18/03/31 09:36:15 WARN tool.BaseSqoopTool: It seems that you're doing hive import directly into default
18/03/31 09:36:15 WARN tool.BaseSqoopTool: hive warehouse directory which is not supported. Sqoop is
18/03/31 09:36:15 WARN tool.BaseSqoopTool: firstly importing data into separate directory and then
18/03/31 09:36:15 WARN tool.BaseSqoopTool: inserting data into hive. Please consider removing
18/03/31 09:36:15 WARN tool.BaseSqoopTool: --target-dir or --warehouse-dir into /user/hive/warehouse in
18/03/31 09:36:15 WARN tool.BaseSqoopTool: case that you will detect any issues.
18/03/31 09:36:16 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
18/03/31 09:36:17 INFO tool.CodeGenTool: Beginning code generation
<<中略>>
18/03/31 09:36:33 INFO hive.metastore: Trying to connect to metastore with URI thrift://127.0.0.1:9083
18/03/31 09:36:33 INFO hive.metastore: Opened a connection to metastore, current connections: 1
18/03/31 09:36:33 INFO hive.metastore: Connected to metastore.
18/03/31 09:36:35 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
18/03/31 09:36:35 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/03/31 09:36:39 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1281)
at java.lang.Thread.join(Thread.java:1355)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:952)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:690)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:879)
18/03/31 09:36:39 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1281)
at java.lang.Thread.join(Thread.java:1355)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:952)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:690)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:879)
<<中略>>
18/03/31 09:40:00 INFO impl.YarnClientImpl: Submitted application application_1522512340502_0001
18/03/31 09:40:01 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1522512340502_0001/
18/03/31 09:40:01 INFO mapreduce.Job: Running job: job_1522512340502_0001
18/03/31 09:41:18 INFO mapreduce.Job: Job job_1522512340502_0001 running in uber mode : false
18/03/31 09:41:18 INFO mapreduce.Job: map 0% reduce 0%
18/03/31 09:42:05 INFO mapreduce.Job: map 100% reduce 0%
18/03/31 09:42:08 INFO mapreduce.Job: Job job_1522512340502_0001 completed successfully
18/03/31 09:42:09 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=225329
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=5685
HDFS: Number of bytes written=3447
HDFS: Number of read operations=48
HDFS: Number of large read operations=0
HDFS: Number of write operations=10
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=33910
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=33910
Total vcore-milliseconds taken by all map tasks=33910
Total megabyte-milliseconds taken by all map tasks=34723840
Map-Reduce Framework
Map input records=58
Map output records=58
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=162
CPU time spent (ms)=4780
Physical memory (bytes) snapshot=315736064
Virtual memory (bytes) snapshot=1592389632
Total committed heap usage (bytes)=251658240
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
18/03/31 09:42:09 INFO mapreduce.ImportJobBase: Transferred 3.3662 KB in 333.9434 seconds (10.3221 bytes/sec)
<<中略>>
18/03/31 06:23:45 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1281)
at java.lang.Thread.join(Thread.java:1355)
at zorg.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:952)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutpu tStream.java:690)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStre am.java:879)
18/03/31 06:23:46 INFO db.DBInputFormat: Using read commited transaction isolation
18/03/31 06:23:47 INFO mapreduce.JobSubmitter: number of splits:1
18/03/31 06:23:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1522501975217_0006
18/03/31 06:23:47 INFO impl.YarnClientImpl: Submitted application application_15 22501975217_0006
18/03/31 06:23:47 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1522501975217_0006/
18/03/31 06:23:47 INFO mapreduce.Job: Running job: job_1522501975217_0006
18/03/31 06:24:04 INFO mapreduce.Job: Job job_1522501975217_0006 running in uber mode : false
18/03/31 06:24:04 INFO mapreduce.Job: map 0% reduce 0%
18/03/31 06:24:21 INFO mapreduce.Job: map 100% reduce 0%
18/03/31 06:24:22 INFO mapreduce.Job: Job job_1522501975217_0006 completed successfully
18/03/31 06:24:22 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=214650
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=9261
HDFS: Number of bytes written=47240
HDFS: Number of read operations=48
HDFS: Number of large read operations=0
HDFS: Number of write operations=10
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=6236672
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=12181
Total vcore-milliseconds taken by all map tasks=12181
Total megabyte-milliseconds taken by all map tasks=6236672
Map-Reduce Framework
Map input records=1345
Map output records=1345
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=217
CPU time spent (ms)=3920
Physical memory (bytes) snapshot=196726784
Virtual memory (bytes) snapshot=757174272
Total committed heap usage (bytes)=49283072
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
18/03/31 06:24:22 INFO mapreduce.ImportJobBase: Transferred 46.1328 KB in 52.184 3 seconds (905.2524 bytes/sec)
18/03/31 06:24:22 INFO mapreduce.ImportJobBase: Retrieved 1345 records.
2.2 取込んだデータの確認
HDFSを確認してみます。
[cloudera@quickstart ~]$ hadoop fs -ls /user/hive/warehouse/
Found 6 items
drwxrwxrwx - cloudera supergroup 0 2018-03-31 09:42 /user/hive/warehouse/categories
drwxrwxrwx - cloudera supergroup 0 2018-03-31 09:48 /user/hive/warehouse/customers
drwxrwxrwx - cloudera supergroup 0 2018-03-31 09:53 /user/hive/warehouse/departments
drwxrwxrwx - cloudera supergroup 0 2018-03-31 09:59 /user/hive/warehouse/order_items
drwxrwxrwx - cloudera supergroup 0 2018-03-31 10:03 /user/hive/warehouse/orders
drwxrwxrwx - cloudera supergroup 0 2018-03-31 10:10 /user/hive/warehouse/products
[cloudera@quickstart ~]$ hadoop fs -ls /user/hive/warehouse/categories/
Found 3 items
drwxr-xr-x - cloudera supergroup 0 2018-03-31 09:36 /user/hive/warehouse/categories/.metadata
drwxr-xr-x - cloudera supergroup 0 2018-03-31 09:42 /user/hive/warehouse/categories/.signals
-rw-r--r-- 1 cloudera supergroup 1957 2018-03-31 09:42 /user/hive/warehouse/categories/fb71c96b-e860-4c6d-8a20-e98ef65d35db.parquet
HUEでも確認してみます。
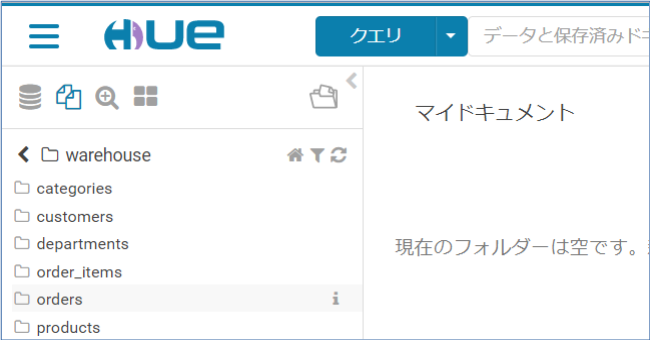
Exceptionが出ていましたが、正常にデータは取り込まれているようです。
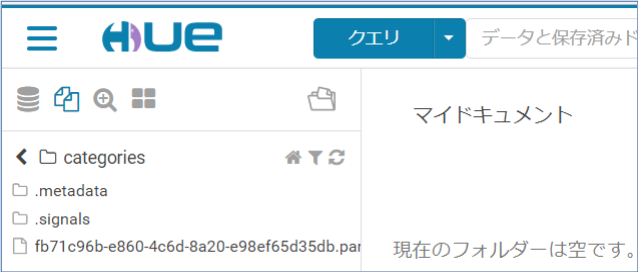
続いてparquetの内部をGUIで覗いてみます。
HUEの左側でファイルを選択します。
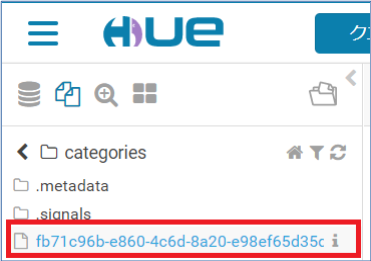
以下のようにファイルが展開されます。
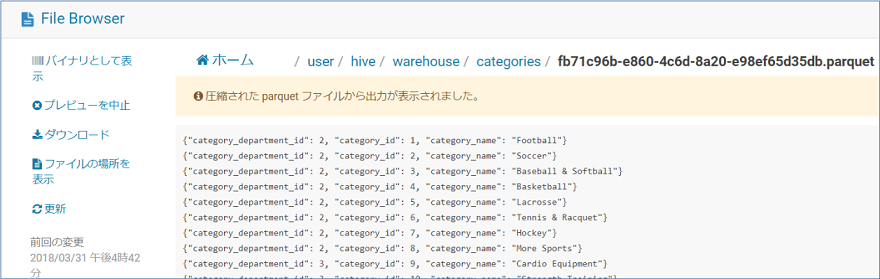
ついでにスキーマ構造も見てみます。
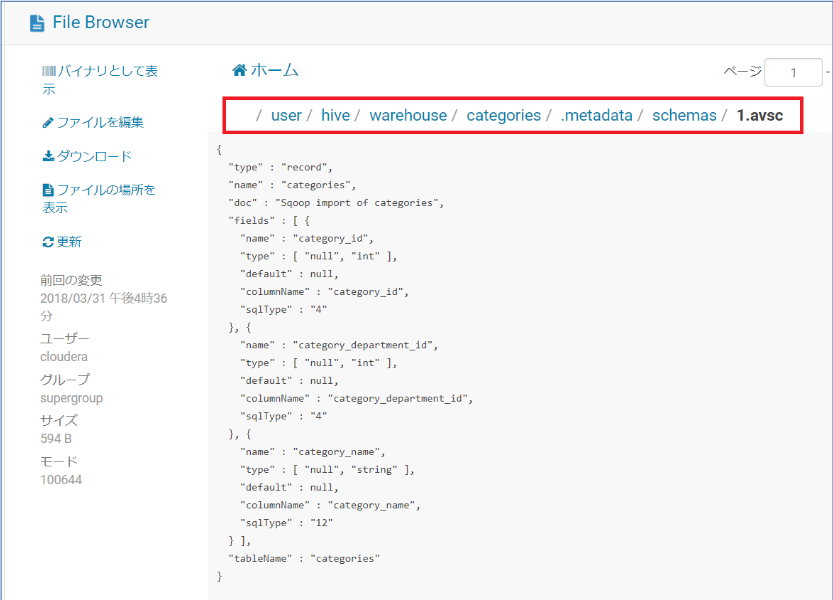
2.3 Queryの実行
次にImpala Query EditorでQueryを実行してみます。
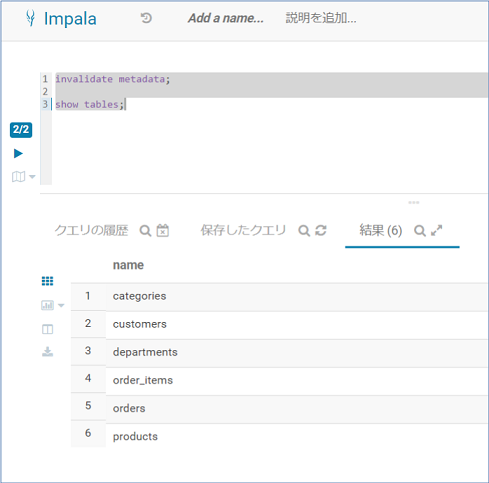
まずは以下の2行でメタデータの更新とテーブル一覧を表示します。
invalidate metadata;
show tables;
カーソルが当たっている行が実行されるので、2行同時に実行するためには両方とも選択状態にしておきます。
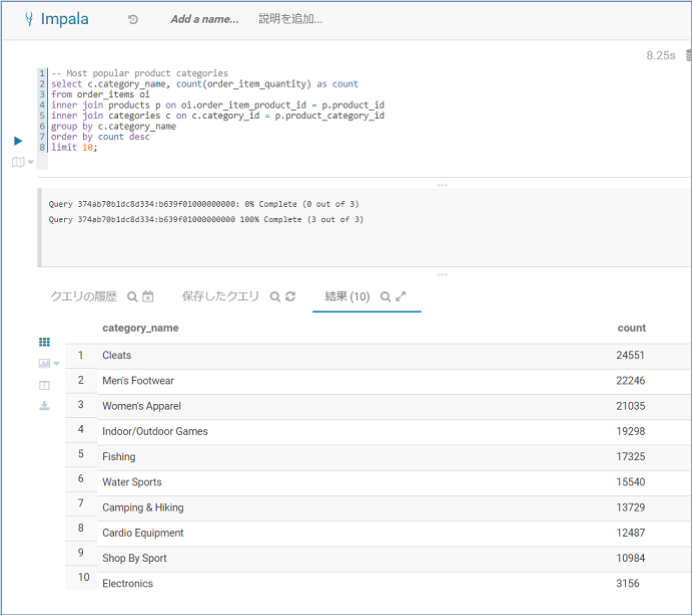
続いて最もポピュラーなプロダクトカテゴリーを検索します。上位10位まで表示します。
-- Most popular product categories
select c.category_name, count(order_item_quantity) as count
from order_items oi
inner join products p on oi.order_item_product_id = p.product_id
inner join categories c on c.category_id = p.product_category_id
group by c.category_name
order by count desc
limit 10;
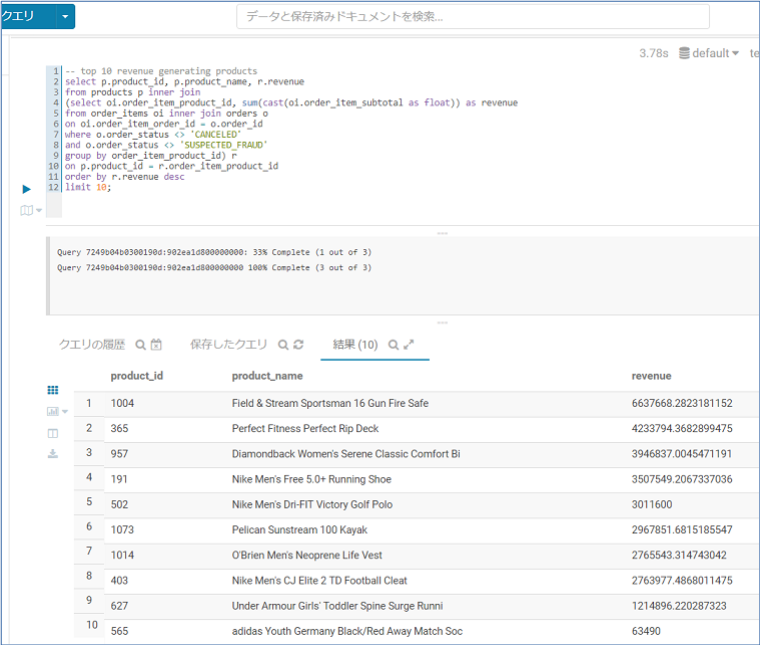
続いて収入が高い順に10位まで表示します。
-- top 10 revenue generating products
select p.product_id, p.product_name, r.revenue
from products p inner join
(select oi.order_item_product_id, sum(cast(oi.order_item_subtotal as float)) as revenue
from order_items oi inner join orders o
on oi.order_item_order_id = o.order_id
where o.order_status <> 'CANCELED'
and o.order_status <> 'SUSPECTED_FRAUD'
group by order_item_product_id) r
on p.product_id = r.order_item_product_id
order by r.revenue desc
limit 10;
3. 終わりに
今回実行した内容はトラディショナルなRDBでも実施できますが、データ量が多い場合はHadoopの方がインフラコストが安くなりますし、スケールアウトすることでさらに大容量のデータも取り扱うことができるようになります。
Part-1はこちら
Part-3はこちら
Part-4はこちら
参考URL