はじめに
今回はUnstructuredデータを取り扱ってみます。
内容は以下より。
https://www.cloudera.com/developers/get-started-with-hadoop-tutorial/exercise-2.html
Part-1はこちら
Part-2はこちら
Part-3はこちら
1. データ投入
データはSandboxに準備してありますので、以下のコマンドを実行します。
以下は、HDFSにディレクトリを作成し、ローカルファイルをHDFSにコピーし、最後に投入したデータを確認しています。
sudo -u hdfs hadoop fs -mkdir /user/hive/warehouse/original_access_logs
sudo -u hdfs hadoop fs -copyFromLocal /opt/examples/log_files/access.log.2 /user/hive/warehouse/original_access_logs
hadoop fs -ls /user/hive/warehouse/original_access_logs
以下、結果です。
[cloudera@quickstart ~]$ sudo -u hdfs hadoop fs -mkdir /user/hive/warehouse/original_access_logs
[cloudera@quickstart ~]$ sudo -u hdfs hadoop fs -copyFromLocal /opt/examples/log_files/access.log.2 /user/hive/warehouse/original_access_logs
[cloudera@quickstart ~]$ hadoop fs -ls /user/hive/warehouse/original_access_logs
Found 1 items
-rw-r--r-- 1 hdfs supergroup 39593868 2018-04-01 06:32 /user/hive/warehouse/original_access_logs/access.log.2
2. Hiveクエリエディタでテーブルの作成
Hueにログインし、Hiveクエリエディタにアクセスします。
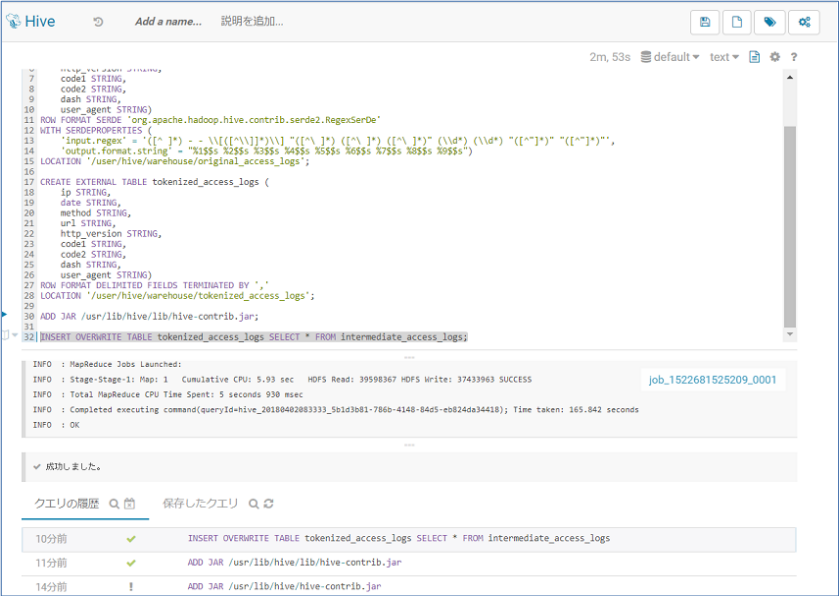
CREATE EXTERNAL TABLE intermediate_access_logs (
ip STRING,
date STRING,
method STRING,
url STRING,
http_version STRING,
code1 STRING,
code2 STRING,
dash STRING,
user_agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex' = '([^ ]*) - - \\[([^\\]]*)\\] "([^\ ]*) ([^\ ]*) ([^\ ]*)" (\\d*) (\\d*) "([^"]*)" "([^"]*)"',
'output.format.string' = "%1$$s %2$$s %3$$s %4$$s %5$$s %6$$s %7$$s %8$$s %9$$s")
LOCATION '/user/hive/warehouse/original_access_logs';
CREATE EXTERNAL TABLE tokenized_access_logs (
ip STRING,
date STRING,
method STRING,
url STRING,
http_version STRING,
code1 STRING,
code2 STRING,
dash STRING,
user_agent STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/hive/warehouse/tokenized_access_logs';
ADD JAR /usr/lib/hive/lib/hive-contrib.jar;
INSERT OVERWRITE TABLE tokenized_access_logs SELECT * FROM intermediate_access_logs;
チュートリアルのページには以下のように記載がありますがエラーになります。
ADD JAR {{lib_dir}}/hive/lib/hive-contrib.jar;
絶対パスに変更し実行します。
ADD JAR /usr/lib/hive/lib/hive-contrib.jar;
以下のようになります。
2. Query
チュートリアルでは
invalidate metadata;
select count(),url from tokenized_access_logs
where url like '%/product/%'
group by url order by count() desc;
のようになっていますが、以下のようなエラーが発生します。
Error while compiling statement: FAILED: SemanticException [Error 10128]: line 3:22 Not yet supported place for UDAF 'count'
以下のように修正してから実行します。
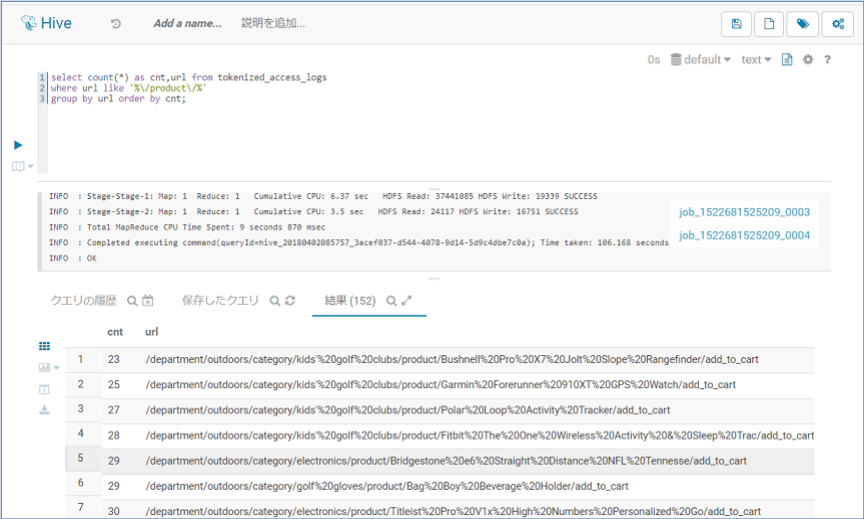
select count(*) as cnt,url from tokenized_access_logs
where url like '%/product/%'
group by url order by cnt;
以下のように表示されれば成功です。
4. 終わりに
Hiveの雰囲気はわかってきましたが、CDHにはいろいろ機能があるので覚えることがたくさんありますね。