概要
- はじめに
- 評価方法
- 手順
- twitterAPIでテキストデータを集める
- 前処理
- Google Cloud Natural Language API
- ヒストグラム
- 検定
- 標本数は足りているか
- 改善点
- おわりに
- 参考
はじめに
僕は自然言語処理でテキストデータの感情分析をすることにハマっています。それをやっている中で、ネットスラングに対応することは難しいことだと感じました。それで、今回、Google Cloud Natural Language APIにある感情分析サービス(以下 Natural Language API)がネットスラングに対応しているか自分なりに検証してみることにしました。
(注意)自分なりに検証してみただけで、必ずしもNatural Language APIがネットスラングに対応しているかを決定づけるものではないです。
評価方法
文によっては、「笑う」は「草」と置き換えることができると考えたので、それを使って評価を行います。例えば、以下の文は同じ意味になります。
・3分で3rt4いいねは笑う
・3分で3rt4いいねは草
文を複数用意して、Natural Language APIで評価を行った時に、「笑う」と「草」でスコアの平均に差があるか検定します。
手順
手順は以下の通りです。
- twitterAPIでテキストデータを集める
- テキストデータに対して前処理
- Natural Language APIでスコアを出す
- 求めたスコアに対して検定を行う
twitterAPIでテキストデータを集める
twitterAPIを使用するには申請が必要なので、[1]を見ながら申請しました。1日で申請が通りました。
申請が通ったので、テキストデータを取得します。[2]のコードをベースにしています。前処理があるので、取得したテキストデータはテキストファイルに書き込むようにしました。検索キーワードを「笑う」にして検索しています。
import json
from requests_oauthlib import OAuth1Session
# OAuth認証部分
CK = ""
CS = ""
AT = ""
ATS = ""
twitter = OAuth1Session(CK, CS, AT, ATS)
url = 'https://api.twitter.com/1.1/search/tweets.json'
keyword = '笑う'
params ={
'count' : 100, # 取得するtweet数
'q' : keyword, # 検索キーワード
}
f = open('./data/1/backup1.txt','w')
req = twitter.get(url, params = params)
print(req.status_code)
if req.status_code == 200:
res = json.loads(req.text)
for line in res['statuses']:
print(line['text'])
f.write(line['text'] + '\n')
print('*******************************************')
else:
print("Failed: %d" % req.status_code)
検索結果は以下のようになります。
・確かに場外に出すけども相撲は笑う
・笑うとこだから!笑うとこ!!
・なんだそれwwww笑うわwwww
前処理
取得したテキストデータを整えます。
ここでやる作業は以下の4つです。
- 「RT 」「@XXXX」といったいらない文字列の除去
- テキストデータから笑いがある行のみを抽出
- 「草」に置き換えられる「笑う」かの判定
- 「笑う」を「草」に変更した文を作成し、csvにまとめる
1と2は以下のように実装しました。
2はツイートの中に改行がある場合があって、3を行う際に大変に感じたので除去しました。
import re
readF = open('./data/1/backup1.txt','r')
writeF = open('./data/1/preprocessing1.txt','w')
lines = readF.readlines()
for line in lines:
if '笑う' in line:
#「RT 」の除去
line = re.sub('RT ', "", line)
#「@XXXX 」または「@XXXX」の除去
line = re.sub('(@\w*\W* )|(@\w*\W*)', "", line)
writeF.write(line)
readF.close()
writeF.close()
3が一番大変でした。
・「笑う」が文末に来ている
・「笑う」の後が句点
・「笑う」の後が「w」
といった場合は高確率で「草」と置き換えることができるとデータを見ていて思ったのですが、データが偏ってしまうと考えました。結局は人力で判定しました。置き換えることができないと判断したテキストデータは除去しました。
標本数は200になりました。
4は以下のように実装しました。
import csv
import pandas as pd
count = 6
lines = []
for i in range(count):
print(i)
readF = open('./data/'+ str(i+1) + '/preprocessing' + str(i+1) + '.txt')
lines += readF.readlines()
df = pd.DataFrame([],columns=['warau', 'kusa'])
replaceLines = []
for line in lines:
replaceLines.append(line.replace('笑う', '草'))
df["warau"] = lines
df["kusa"] = replaceLines
df.to_csv("./data/preprocessing.csv",index=False)
ここまでの処理の結果は以下の画像のようになります。

Google Cloud Natural Language API
Google Cloud Natural Language APIにある感情分析サービスはテキストが持っている感情スコアを返してくれます。感情スコアは1に近いほどポジティブで−1に近いほどネガティブです[3]。Google Cloud Natural Language APIには感情分析サービス以外にもコンテンツ分類などもあります。
プログラムは[4]を基に実装しました。
「笑う」・「草」の文をそれぞれNatural Language APIに渡し、それぞれ結果をListに格納します。そしてそれを"warauResult"・"kusaResult"をカラム名として、pandasに追加します。最後に、csvファイルを出力します。
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import types
import os
import pandas as pd
credential_path = "/pass/xxx.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path
client = language.LanguageServiceClient()
warauResultList = []
kusaResultList = []
df = pd.read_csv('./data/preprocessing.csv')
count = 9
for index,text in df.iterrows():
#\nの除去
text["warau"] = text["warau"].replace('\n', '')
text["kusa"] = text["kusa"].replace('\n', '')
#warauの解析
document = types.Document(
content=text["warau"],
type=enums.Document.Type.PLAIN_TEXT)
sentiment = client.analyze_sentiment(document=document).document_sentiment
warauResultList.append(sentiment.score)
#kusaの解析
document = types.Document(
content=text["kusa"],
type=enums.Document.Type.PLAIN_TEXT)
sentiment = client.analyze_sentiment(document=document).document_sentiment
kusaResultList.append(sentiment.score)
df["warauResult"] = warauResultList
df["kusaResult"] = kusaResultList
df.to_csv("./data/result.csv",index=False)
ここまでの処理の結果は以下の画像のようになります。

ヒストグラム
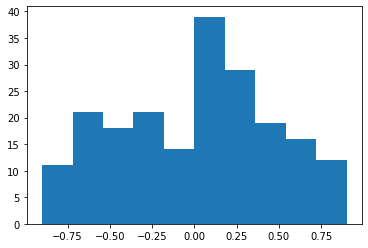
warauResultのヒストグラムは以下の通りです。
kusaResultのヒストグラムは以下の通りです。
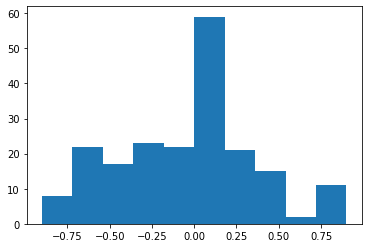
それぞれ正規分布に従っていると仮定します。
検定
warauResultに格納されている値とkusaResultに格納されている値を比較します。
今回は標本間で対応がある場合の平均差の検定を行います。[5]と[6]を参考にしました。
・帰無仮説・・・「笑う」を「草」に変えてもスコアは変わらなかった
・対立仮説・・・「笑う」を「草」に変えたことによってスコアは変わった
プログラムは以下のようになります。
from scipy import stats
import pandas as pd
# 標本間で対応がある場合の平均差の検定
df = pd.read_csv('./data/result.csv')
stats.ttest_rel(df["warauResult"], df["kusaResult"])
結果は以下の通りです。
Ttest_relResult(statistic=3.0558408995373356, pvalue=0.0025520814940409413)
stats.ttest_relのリファレンスは[7]です。
引用:「 If the p-value is smaller than the threshold, e.g. 1%, 5% or 10%, then we reject the null hypothesis of equal averages.」
つまり、今回は, pvalueが約2.5%と小さいので、帰無仮説は棄却されます。よって「笑う」を「草」に変えたことによってスコアは変わったとなります。標本には「草」に置き換えられる「笑う」が入った文しかありません(主観的)。なのに、スコアが変わるということはNatural Language APIがネットスラングに対応できてないと結論づけられます。
標本数は足りているか
warauResult、kusaResultそれぞれ、平均の区間推定を行います。[8]を参考にしました。
\begin{aligned}
\bar{X}-z_{\frac{\alpha}{2}}\sqrt{\frac{s^2}{n}}
< \mu <
\bar{X}+z_{\frac{\alpha}{2}}\sqrt{\frac{s^2}{n}}
\end{aligned}
プログラムは以下のようになります。
from scipy import stats
import math
print("warauResultの標本平均",df['warauResult'].mean())
print("kusaResultの標本平均",df['kusaResult'].mean())
# .var()は不偏分散を求める
print("warauResultの区間推定",stats.norm.interval(alpha=0.95,
loc=df['warauResult'].mean(),
scale=math.sqrt(df['warauResult'].var() / len(df))))
print("kusaResultの区間推定",stats.norm.interval(alpha=0.95,
loc=df['kusaResult'].mean(),
scale=math.sqrt(df['kusaResult'].var() / len(df))))
結果は以下の通りです。
warauResultの標本平均 0.0014999993890523911
kusaResultの標本平均 -0.061000001728534696
warauResultの区間推定 (-0.0630797610044764, 0.06607975978258118)
kusaResultの区間推定 (-0.11646731178466276, -0.005532691672406637)
誤差範囲
・warauResult:約±0.06458
・kusaResult: 約±0.05546
Natural Language APIが返す感情スコアの範囲は1から-1です。この範囲における誤差±0.06は小さいと考えました。
ちなみに[9]のように誤差範囲を基に必要なサンプル数を出すことができます。
・warauResultについて
・信頼係数95%
・誤差範囲±0.06458
この時、標本数は200となります。
import numpy as np
# 母集団の標準偏差はわからないので、不偏分散の平方根で代用
rutoN = (1.96 * np.sqrt(df['warauResult'].var()))/ 0.06458
N = rutoN * rutoN
print(N)
結果は以下の通りです。
200.0058661538003
改善点
・「草」に置き換えられる「笑う」かの判定を一人で行っており、客観的でない
→複数人で評価をする
・今のデータの集め方は多くの標本数を集めることができない
→必要な標本の数が多い場合、パターンを見つけ自動化を検討する
・誤差範囲をどうやって決めるか
→誤差範囲がどれぐらいであればいいかの理由が欲しい
おわりに
来年もAdvent Calendarに参加したいですね。
参考
[1]https://qiita.com/kngsym2018/items/2524d21455aac111cdee
[2]https://qiita.com/tomozo6/items/d7fac0f942f3c4c66daf
[3]https://cloud.google.com/natural-language/docs/basics#interpreting_sentiment_analysis_values
[4]https://cloud.google.com/natural-language/docs/quickstart-client-libraries#client-libraries-install-python
[5]https://bellcurve.jp/statistics/course/9453.html
[6]https://ohke.hateblo.jp/entry/2018/05/19/230000
[7]https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.stats.ttest_rel.html
[8]https://ohke.hateblo.jp/entry/2018/05/12/230000
[9]https://toukeigaku-jouhou.info/2018/01/23/how-to-calculate-samplesize/