2年ほど前にODBCドライバでのOracle接続を投稿しました。
その後erlang向けドライバerlociでの接続に目途が付いてLT用に記事を書いていたのですが、
Ecto対応のOracleドライバの作者であるvstavski氏よりご連絡を頂きました.
(なんと、わざわざそのためにQiitaに会員登録されたようです!)
そのライブラリjamdb_oracleの出来があまりにも衝撃的だったので、ここで紹介します。
**注記:GithubにログオンができないケースのIssueが上がってます。
私も遭遇しましたので、試される方はあくまでテスト環境でお願いします。
Oracle 12cではアカウントロックされてしまいます。
2018/10/13 v0.16でRDS接続問題は解消されました。
jamdb_oracleで出来ること
- OracleにOCIなしで接続できる
- ECTO対応
- OCIが動作しないAlpine Linuxのコンテナから使用可能
- Elixir/phoenixにとって、postgres/mysqlと何ら変わらない接続コスト
OCIって何?
一般的にオープン環境からOracleに接続するには、ドライバであるOCIが必用です。
yumやapt-getではインストールできず、Oracleの公式サイトに登録してのダウンロードが必用です。
適切なパス・環境設定を行い、言語によってはC/C++コンパイラの環境を整える必要もあり、
接続コストが高いデータベースでした。
OCI接続がないのはOracle使用者にとって夢のような環境です。
elixirはOracleに最も簡単につなげる言語
このアダプターの出現で、Elixir/erlangはnodejsやgo,javaを差し置き、最も簡単にOracleに
接続できる処理系になったと言えます。.net coreより簡単かもしれません。
(DelphiやC#は商用でDevart社のツールがあります)
-
2019-07-16追記 F#の
SQLProviderとOracle.ManagedDataAccess.Clientの組み合わせ
のほうが簡単でした。Dotnet CoreのOracle.ManagedDataAccessは、OCIなしでOracleに接続可能です。
導入
今回はEctoアダプターを使用した例を見ていきます。
phoenixのプロジェクト作成
まずはphonixでプロジェクトのひな形を作ります。
postgres向けの設定になるので、そこをOracle向けに修正します。
$ mix phx.new Oapp --no-brunch
$ cd Oapp
mix.exs
postgresexをjamdb_oracleに差し替えるだけです。
defp deps do
[
# ・・・・
{:phoenix, "~> 1.3.0"},
{:phoenix_pubsub, "~> 1.0"},
{:phoenix_ecto, "~> 3.2"},
# {:postgrex, ">= 0.0.0"}, ↓ 置き換え
{:jamdb_oracle, "~> 0.1.1"},
{:phoenix_html, "~> 2.10"},
{:phoenix_live_reload, "~> 1.0", only: :dev},
{:gettext, "~> 0.11"},
{:cowboy, "~> 1.0"}
]
end
パッケージをインストール
$ mix deps.get
DB接続設定
postgres向けの設定を書き換えます。
config :oapp, Oapp.Repo,
adapter: Ecto.Adapters.Jamdb.Oracle,
username: "UID",
password: "PASS",
database: "XE",
hostname: "localhost",
port: 1521,
pool_size: 10,
timeout: 15000
接続確認
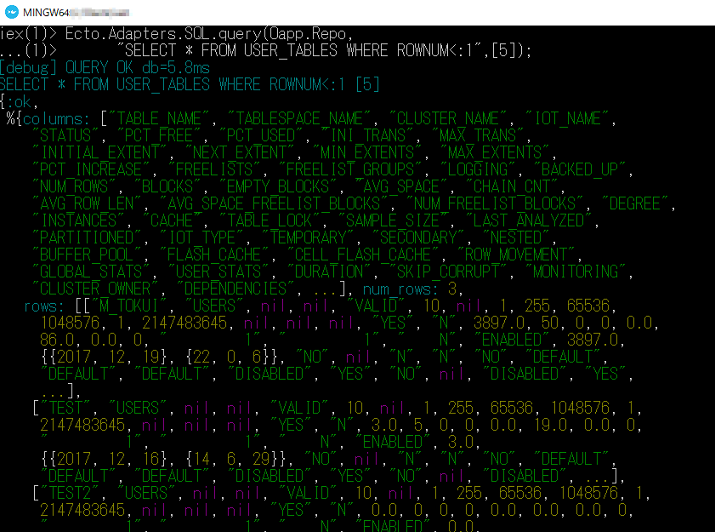
生SQLを発行して、接続が確認できました。
かつてないほど、簡単ですね!
$ iex -S mix
iex > Ecto.Adapters.SQL.query(Oapp.Repo,
"SELECT * FROM USER_TABLES WHERE ROWNUM<:1",[5])
RDB既存テーブルにEctoのModelでアクセスする
生SQLでのアクセスは確認できたので、Ecto.RepoにModel定義して使用してみます。
EctoはDBにテーブルを同時生成するマイグレーションありのサンプルばかりが強調されてますが、既存テーブルにアクセスができます。 ネット検索してもあまり例がないので書いておきます。
以下はOracleに限らず、他のRDBでも使用できるテクニックです。
準備
Oracle側で東京証券取引所から上場企業データをダウンロードして、次のテーブルに叩き込みました。
サンプル用テーブル
CREATE TABLE M_TOKUI (
CODE VARCHAR2(5),
NAME VARCHAR2(60),
PRD_TYPE VARCHAR2(20),
G33_CD NUMBER(4,0),
G33_NAME VARCHAR2(20),
G17_CD NUMBER(4,0),
G17_NAME VARCHAR2(20),
SCALE_CD NUMBER(4,0),
SCALE_NAME VARCHAR2(30),
DAY_UPD DATE DEFAULT SYSDATE,
CONSTRAINT PK_M_TOKUI PRIMARY KEY(CODE)
)
RDB側のテーブル名を使う
mixを使って、スキーマアクセスのためのスクリプトを生成します。
$ mix phx.gen.schema --no-migration \
Sales.Customer customer --table m_tokui \
code:string name:string
-
--tableでOracleのテーブルM_TOKUIを構造体Customerに割り当てています。 -
SalesはElixir上のNamespaceみたいなもので、Oracleのスキーマではありません。 - テーブルのCodeとNameのみを使いたいので、使いたいカラムのみを指定。
次のようなスクリプトが生成されますが、このままでは動作しないので修正を入れます。
defmodule Oapp.Sales.Customer do
use Ecto.Schema
import Ecto.Changeset
alias Oapp.Sales.Customer
schema "m_tokui" do
field :code, :string
field :name, :string
timestamps()
end
def changeset(%Customer{} = customer, attrs) do
モデルのつじつまを合わせる
Oracleで動かすため修正は以下の通り。
- 主キー
codeをschema句の外側に出して、primary_key指定をする
@primary_keyと@deriveの2行を追加します。 -
timestamps()の行は削除
defmodule Oapp.Sales.Customer do
use Ecto.Schema
import Ecto.Changeset
alias Oapp.Sales.Customer
@primary_key{ :code, :string, []} #1.主キーはこの2行へ
@derive {Phoenix.Param, key: :code} #
schema "m_tokui" do
field :name, :string
# timestamps() #2.remove
end
def changeset(%Customer{} = customer, attrs) do
一旦モデルを生成してしまえば、参照項目としてのカラムの追加や削除は自由に編集可能です
後から業種と日付の項目が必用になった場合は以下のように書き足せばOK
defmodule Oapp.Sales.Customer do
use Ecto.Schema
import Ecto.Changeset
alias Oapp.Sales.Customer
@primary_key{ :code, :string, []}
@derive {Phoenix.Param, key: :code}
schema "m_tokui" do
field :name, :string
field :g33_name, :string # 追加
field :day_upd, :naive_datetime # 追加
end
def changeset(%Customer{} = customer, attrs) do
- 実行
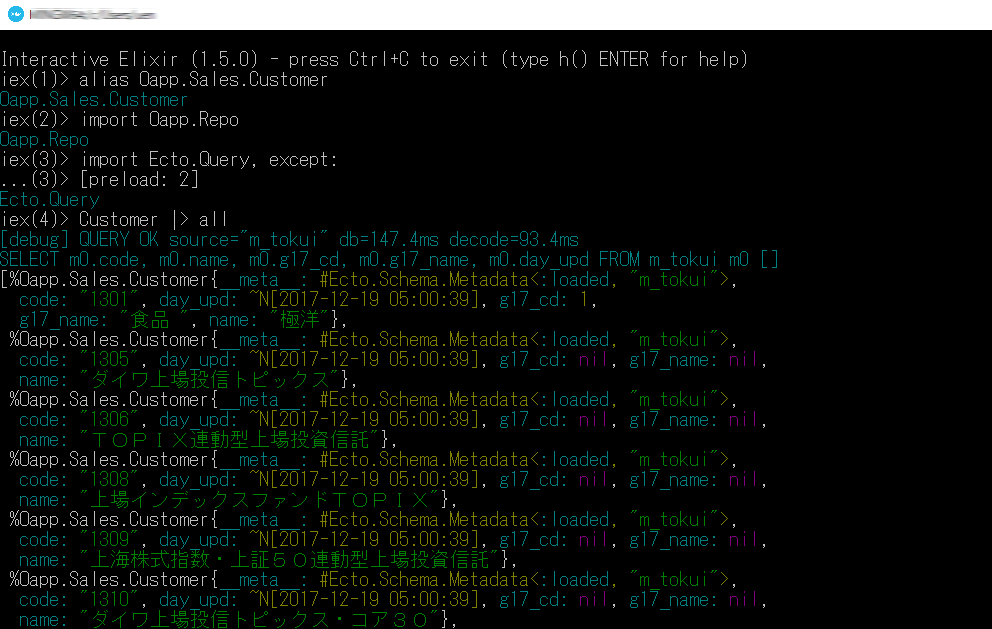
$ iex -S mix
iex> alias Oapp.Sales.Customer
iex> import Oapp.Repo
iex> import Ecto.Query, except: [preload: 2]
iex> Customer |> all
問題なく出力できました。
- キー指定
iex> Customer >| get("1311")
- 後方一致検索
iex> Customer
|> where([rec], like(rec.name, "日本%"))
|> all
- グループ化
iex> from(p in Customer,
group_by: p.g17_name,
select: {p.g17_name, count(p.code)})
|> all
[debug] QUERY OK source="m_tokui" db=46.3ms
SELECT m0.g17_name, count(m0.code) FROM m_tokui m0 GROUP BY m0.g17_name []
[{nil, 313}, {"エネルギー資源 ", 19}, {"機械 ", 228},
{"自動車・輸送機 ", 113}, {"建設・資材 ", 311},
{"電機・精密 ", 308}, {"小売 ", 349}, {"金融(除く銀行) ", 91},
{"電力・ガス ", 24}, {"医薬品 ", 67}, {"銀行 ", 86},
{"素材・化学 ", 287}, {"運輸・物流 ", 117},
{"情報通信・サービスそ", 926}, {"不動産 ", 123}, {"食品 ", 137},
{"商社・卸売 ", 317}, {"鉄鋼・非鉄 ", 81}]
モデルを作成すると、p.codeのようにElixirの構文から直接カラムを指定できるのが魅力です。
今回はデータ参照のみのご紹介でした。