概要
BigQueryを利用して、集計をしている際に奇妙な現象に遭遇した。
よくよく調査してみると自分の書いたSQLに問題があるというよりBigQuery自体に問題があるのでは?という結論に至ったので落書き程度に書いておく。
問題となったSQL
WITH table AS (
SELECT
*
FROM
UNNEST (
[
STRUCT(1 AS user, 1 AS group_id, '2018-07-17' AS dat),
(2,1,'2018-07-17'),
(3,1,'2018-07-17'),
(4,1,'2018-07-17'),
(5,1,'2018-07-17'),
(6,1,'2018-07-17'),
(7,1,'2018-07-17'),
(8,2,'2018-07-17'),
(9,2,'2018-07-17'),
(10,2,'2018-07-17'),
(11,2,'2018-07-17'),
(14,3,'2018-07-17'),
(15,3,'2018-07-17'),
(16,3,'2018-07-17'),
(17,3,'2018-07-17'),
(1,1,'2018-07-18'),
(4,1,'2018-07-18'),
(5,1,'2018-07-18'),
(6,1,'2018-07-18'),
(7,1,'2018-07-18'),
(8,2,'2018-07-18'),
(9,2,'2018-07-18'),
(10,2,'2018-07-18'),
(11,2,'2018-07-18'),
(12,2,'2018-07-18'),
(13,2,'2018-07-18'),
(14,3,'2018-07-18'),
(15,3,'2018-07-18'),
(16,3,'2018-07-18'),
(17,3,'2018-07-18'),
(18,3,'2018-07-18')
]
)
)
SELECT
ARRAY_AGG(group_count ORDER BY user_count DESC) AS arr,
dat
FROM (
SELECT
dat,
user_count,
COUNT(*) AS group_count
FROM (
SELECT
dat,
group_id,
COUNT(*) AS user_count
FROM
table
GROUP BY dat, group_id
)
GROUP BY dat, user_count
)
GROUP BY dat
ORDER BY dat ASC
SQLの解説
1つずつ解説。
WITH句 は単純にサンプルデータを作ってるに過ぎないのでスルー推奨。
SELECT
dat,
group_id,
COUNT(*) AS user_count
FROM
table
GROUP BY dat, group_id
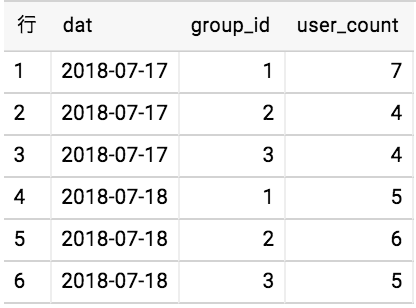
ここはWITH句で作った table に対してdat毎、group_id毎に何人のユーザが居るかを集計している。
結果はこんな感じ。
更に広げて
SELECT
dat,
user_count,
COUNT(*) AS group_count
FROM (
SELECT
dat,
group_id,
COUNT(*) AS user_count
FROM
table
GROUP BY dat, group_id
)
GROUP BY dat, user_count
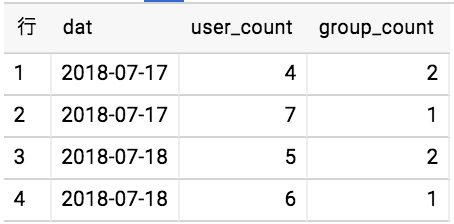
このSQLは先に求めた値に対して更にユーザの数でグルーピングして同じユーザの数のgroup_idの個数を求めている。
結果はこんな感じ。
そして最後に上記の結果を ARRAY_AGG関数 を用いてdat毎にグルーピングして group_count を配列型に格納する。
ARRAY_AGG(group_count ORDER BY user_count DESC) AS arr
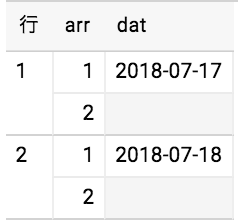
その際の並び順は ORDER BY user_count DESC つまり user_count の降順にしている。
つまり結果は下記のようになるはず。
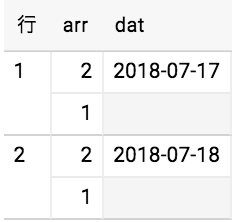
だが実際に実行してみると下記のように ORDER句 が効いていない結果が帰ってくる。
解決方法
結論だけ言うと COUNT(*) を2順に実行してる部分が問題になっている模様。
group_count user_count を取得している箇所で明示的にカラム名を指定することで想定どおりの結果が得られる。(どちらか片方で良い)
例えば下記
SELECT
ARRAY_AGG(group_count ORDER BY user_count DESC) AS arr,
dat
FROM (
SELECT
dat,
user_count,
COUNT(user_count) AS group_count
FROM (
SELECT
dat,
group_id,
COUNT(*) AS user_count
FROM
table
GROUP BY dat, group_id
)
GROUP BY dat, user_count
)
GROUP BY dat
ORDER BY dat ASC
結論
COUNT(*) で無精せずにカラム名を明示的に書けば良い。
だが、別にNULL値を含んでるわけではないので COUNT(カラム名) と COUNT(*) の間に差異があるのは解せない問題である。
書き方に問題があるというよりBigQuery側に問題があると思いたい。
そもそも、こんな特殊なSQLを書く機会はあまりないとは思うが、BigQueryで ARRAY_AGG関数 を利用する場合は注意しましょう。
という落書きでした。
補足
Postgresの場合
少しSQLを改変してPostgresqlに同等のSQLを投げてみると想定どおりの状態になる。
arr | dat
-------+------------
{1,2} | 2018-07-17
{1,2} | 2018-07-18
追伸
なぜこういう挙動を取るかわかる方がいらっしゃいましたら教えて頂ければです。