はじめに
- タイトルのことを軽く試そうとしたが、ハマったので、少しでもノウハウを残そうと思う
- 本当は、テキスト分割をし、その結果をベクトル化するところまでやりたかったが、ハマりすぎてそこまで至らなかったので、今回はできたところまでを記録する
- ベクトル化ができたら、続編を書きたいと思う
やりたいこと
- Azure Blob StorageにファイルをUploadしておく
- Azure AI SearchのIndexerを使って、
- BlobにUploadされたファイルを読み取る
- 読み取ったファイル内のテキストを分割する
- Azure AI Searchに分割されたテキストを格納する
対象のデータ
- テキスト分割は、文章単位(ページ単位ではなく)を使うこととする
- 分割したいテキストファイル(ChatGPTに作らせたサンプル)
失われた時間の旅
昔々、遠い未来の地球で、人々は時間を自在に操ることができる技術を手に入れました。しかし、その技術が悪用され、時空が混乱し始めました。主人公のエミリーは、失われた時間を取り戻すために、未来と過去を旅することになります。
エミリーは、自分の過去を変えることができるのかという疑問を抱えながら、未来の世界から過去へと向かいます。彼女は、時空を支配しようとする悪しき者たちと対峙しながら、失った時間を取り戻すために奮闘します。
彼女の冒険は、時代を超えた友情や愛情といったテーマを掘り下げながら展開されます。そして、最終的にエミリーは、失われた時間を取り戻すためには、過去を変えるのではなく、現在を大切にすることが重要であることに気づくのです。
このような展開を経ながら、エミリーは自分の過去と向き合い、過去を受け入れることで未来を切り拓いていきます。そして、彼女の冒険は、失われた時間の旅から、自己成長へと続いていくのです。
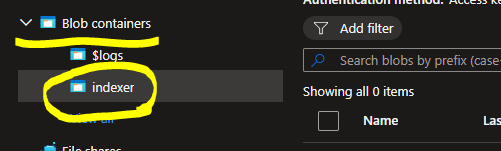
1. Blobを準備する
- Blobコンテナに、任意のフォルダを作成し、そこにファイルを格納することにする
- 今回は、「indexer」というフォルダ名にした
2. Azure AI Searchの準備
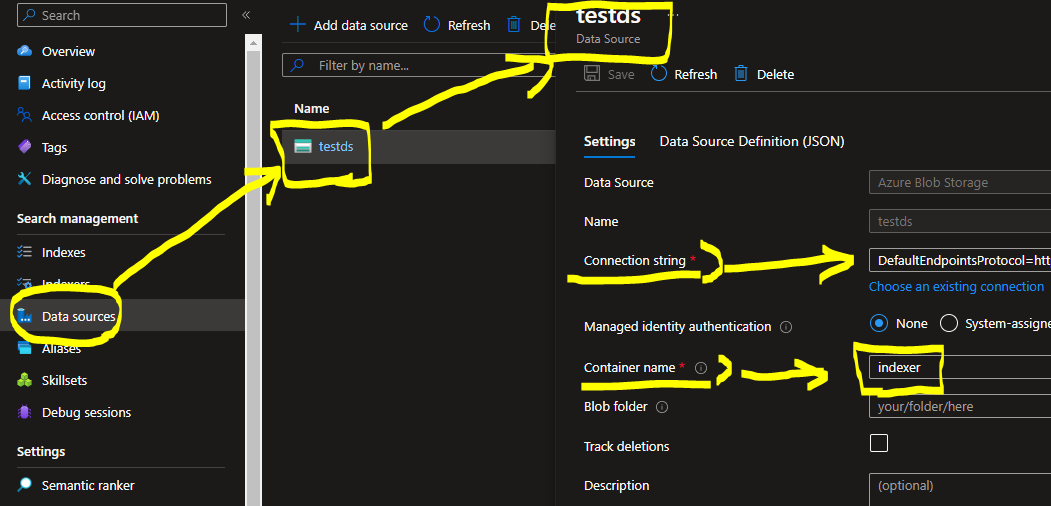
2-1. データソースの準備
- 該当のAzure BlobからConnection Stringをコピーし、今回指定したフォルダ名を記入するのみ
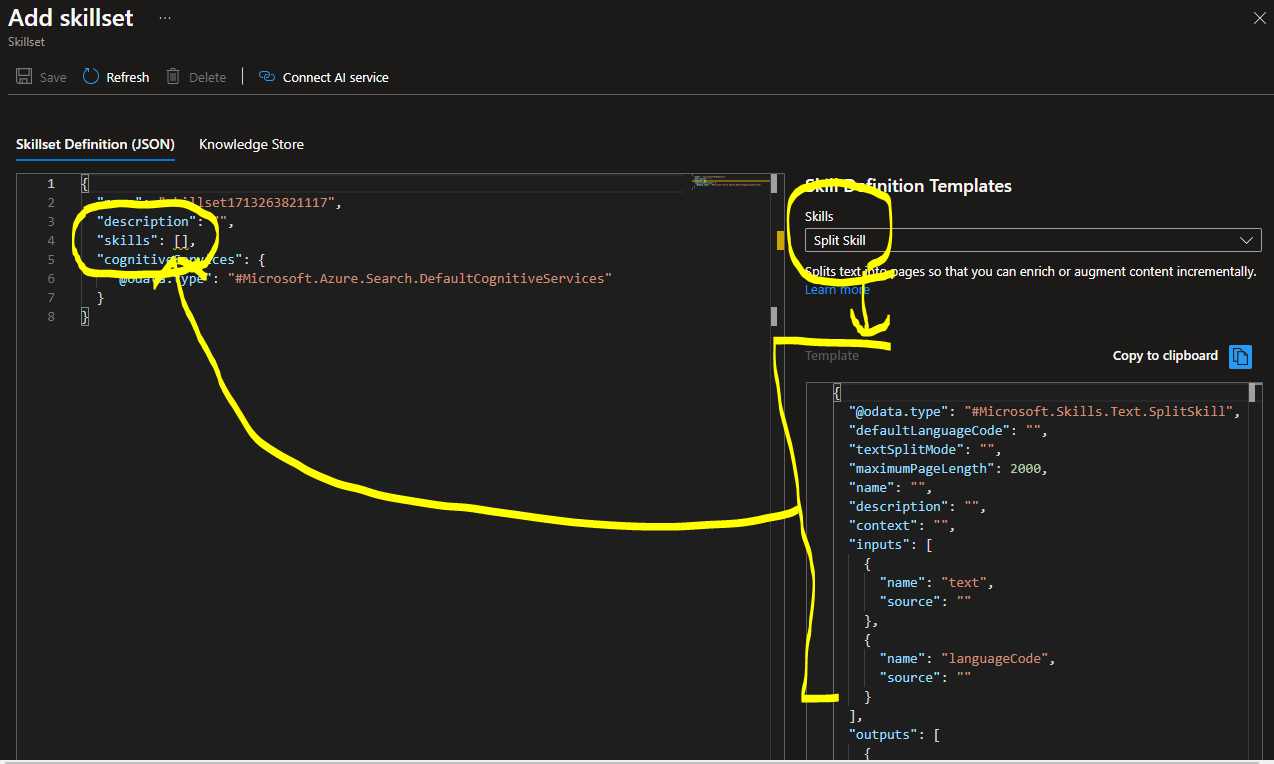
2-2. Skillsetの準備
-
作成しようとすると、いきなりJSONの記述が求められるので、解説を入れたい
-
skillsという配列が、初期状態では空っぽになっているので、そこに、今回は「テキスト分割(split text)」のテンプレートを入れてやる
-
テンプレートの初期値を以下のように変更する
- name:スキルにつける名称と思われる。任意の名称でOK
- context:読み取り元のテキスト領域
- textSplitMode:文章ごとに分割したいため、sentencesを入力
- maximumPageLength:文章分割の場合は関係ないと思うが、省略するとエラーになるので、100を入れておく
- inputs:読み取り対象の領域と読み取りモード(text)を指定する
- outputs:分割後に格納される領域を指定する
-
テンプレートに載っていた、maximumPageLengthやpageOverlapLengthは、ページ分割モード用のパラメータであり、今回不要となるため削除する
-
出来上がった定義を参考に掲載する
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "textSplit01",
"description": "",
"context": "/document/content",
"defaultLanguageCode": "ja",
"textSplitMode": "sentences",
"maximumPageLength": 100,
"inputs": [
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "textItems"
}
]
}
]
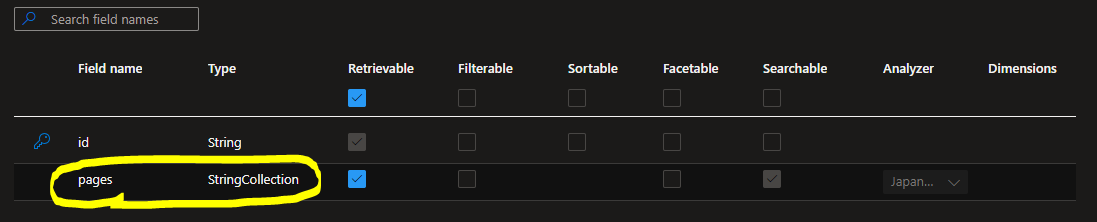
2-3. Indexの準備
- データを格納するインデックスを定義しておく
- 簡単にするため、分割されたテキストを格納するフィールドのみを追加した
- フィールド名は、「pages」とした
- 分割されたテキストは、Stringのコレクションとして出力されるため、StringCollectionタイプ、アナライザはJapanese.Luceneとしておく
2-4. Indexerの準備
-
Settingsでは、2-1から2-3までに作成したものを、それぞれ指定する
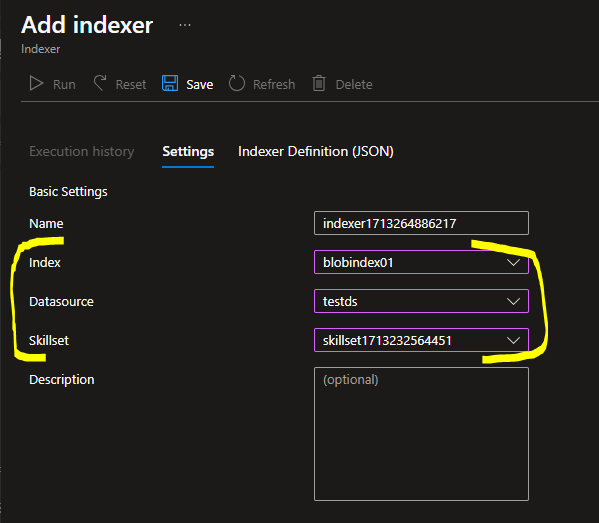
-
次に、Indexer Definition(JSON)の修正を行う
-
分割されたテキストを、指定のフィールドに格納するための設定が必要
-
outputFieldMappingsに、以下を例として定義を記述する
- 分割されたテキストは、「textItems」という領域に格納され、それを今回定義した「pages」というフィールドにマッピングする
- textItemsは、パスでは
/document/content/textItemtとなる
"outputFieldMappings": [
{
"sourceFieldName": "/document/content/textItems",
"targetFieldName": "pages"
}
],
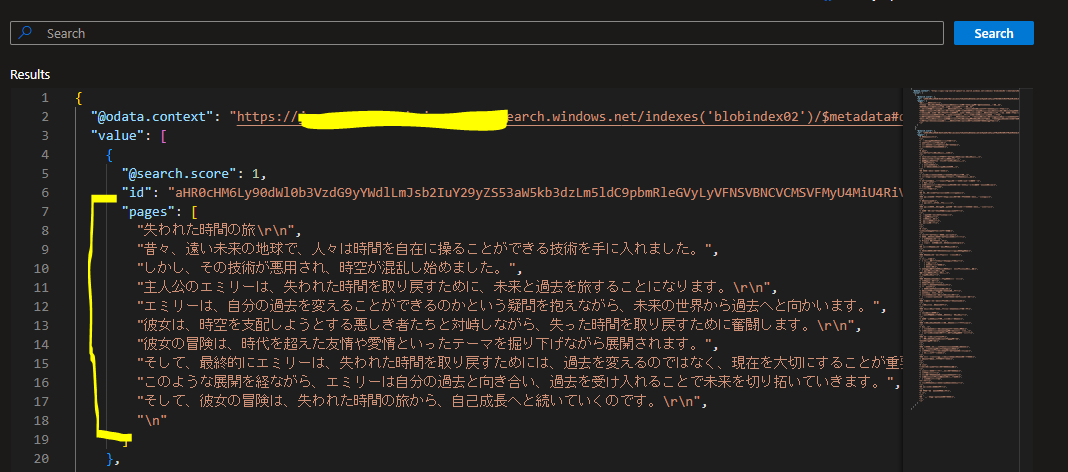
結果
- 改行と句読点を識別し、1文ずつ分割され、「pages」というフィールドに格納された
ハマりポイント
テキストはUTFじゃないとダメ
- WindowsだとSHIFT-JISになりがちなので、要注意!
SkillsetのmaximumPageLengthに注意
- 文章分割モードなので、不要なはずであり、JSON定義時には省略しても保存時にはエラーにならない
- しかし、Indexer実行時には、「maximumPageLengthがnullはダメだよ」とエラーになる
- 省略すると、勝手にnullがアサインされてしまう仕様のようだ
- nullにならないように、100でもいいので数字を入れておく必要がある
Skillsetのinputsとoutputsに注意
- Index上のフィールド定義とSkillset、IndexerのJSON定義を、すべて一致させないと正しく取り込まれないので、注意が必要
- しかし、なぜ入力が、/document/contentなのか、そして出力にtextItemsと指定すると、/document/content/textItemsに出力されるのか、動作仕様がよくわからないので、いろいろ試してみたい
さいごに
- Pythonなどのプログラムを書かずに、テキスト分割などができるIndexerは非常に強力だが、ハードルが非常に高いと感じた。いずれGUIでポチポチと設定できる日が来ますように