背景
SSD1306というコントローラを使ったOLEDを使う仕事がありました。
実際に使うディスプレイは一般人では買いづらいのですが、秋月電子にSSD1306を使った小さなOLEDが売っていました。
0.96インチ 128×64ドット有機ELディスプレイ(OLED) 白色
ちょうど表示画素数も同じだったので、これを使って事前にドライバの開発などを始めます。
ディスプレイのドット構成はこんな感じ。

このコントローラを使ったOLEDは、縦方向が8ページに分かれています。
データの転送はページ毎に行います。
横書きの文字列を表示するのに適しています。
このコントローラには文字キャラクタが内蔵されていないので、マイコン内のメモリにスクリーンバッファを設けて、その中に文字や絵を描き、コントローラにスクリーンバッファの内容をページ毎に分けて転送します。
横方向は128ドットあり、好きな位置から好きな範囲を転送できます。
特定の位置の表示だけを更新するときに便利です。
このOLEDの一つのページは高さが8ドットなので、HD44780などの液晶コントローラで使われていた5ドットx7ドットのキャラクタを表示するには便利です。
横方向全てを更新するには128バイト転送しなくてはいけません。
全ての画素を更新するには1024バイト転送しなくてはならず、シリアル系ではビットに分解して送りますから、単純計算で8096ビットをシリアルで転送します。
しかし、I2Cなどのシリアル系のインターフェースは割り込みを使って転送することで、他の処理とは並行させて動かせるので、転送時間が気になるようなことはあまりないでしょう。
転送時に意外に時間がかかっている!?
特に動作に問題はなく、文字の表示ができるようになりました。

いつも通りmainループがどのくらいのスピードで回っているかを測定していました。
その際、転送時にmainループが2msec近く遅くなっていることがわかりました。
全画面を更新するわけでなく、一部の文字を表示更新が必要なときに、必要な箇所だけをI2Cで送る作りにしています。
I2C自体は割り込みで転送しているので、mainループに影響を与えません。
調べていくと、スクリーンバッファに文字キャラクタデータを書き込む時に時間がかかっていることがわかりました。
しかし、組み込み機器の開発を長年やっている肌感覚で、「この程度のデータ転送で2msecはかからないのでは?」と感じていました。
しかし、測定すると実際には1.4msecほどかかっています。
スクリーンバッファの構成と文字キャラクタの構成
今回、このような予想以上の時間がかかっているのは8ドットx8ドットの文字ではなく、
- 2倍のサイズの文字
- 3倍のサイズの文字
- 4倍のサイズの文字
で発生していました。
今回は4倍サイズの文字で測定をしてみました。
8x8の1倍サイズの文字は、今までもこのようなディスプレイを扱ったことがあったので、自作のキャラジェネを使ったりしていました。
2〜4倍サイズの文字はデータを持っていないので、GitHubで公開されている方がいたので、それを利用させてもらいました。
LCD-fonts〜GitHub
OLEDのデータの送信方法はページごとに左から右へ送ります。

GitHubで公開されているフォントデータは、上から下、左から右という並びになっています。

このような関係から、フォントデータを順番に送っていく方式を採用する場合は、ページ指定を変えながらスクリーンバッファへデータを埋めていきます。
スクリーンバッファは下記のような構造でメモリ上にあります。
unsigned char screenBuffer[8][128]; //8 page x 128 columns(8bit x 128column) x
I2Cで転送する際、データはページに分かれてた方がいいので、このような構成でメモリ上に配置しています。
必要に応じて、ページに分けずベタで持たせたりしたいときは、キャストするなどして利用します。
4倍サイズの文字を例に、実際にスクリーンバッファへ描画する方法を検討します。
素直にページ毎に転送する
1.4msecの転送時間がかかっていたときは、このようにしていました。
int width = 22; //4倍文字の横幅(dot, 高さは32dot=4ページ)
int row = 0; //表示を開始するページ
int pix = 0; //表示を開始する横の位置
int cg = CHAR_4X; //4倍文字のフォントデータ
for(int i = 0; i < width; i++) {
for(int page = 0; page < 4; page++) { //page
screenBuffer[row + page][pix] = *cg++;
}
pix++;
}
フォントデータは上から下の順にデータが並んでいるので、スクリーンバッファへはページを変えながら転送していきます。
上記のプログラムでは、同じ横方向の位置(pix)でページ(row + page)を4回変えて転送し、1ドット(pix)ずつ右へアドレスをずらしていきます。
フォントデータ(cg)はアドレスをインクリメントし続け、順番に送っていきます。
この方法は見た目にわかりやすいです。
ページ(row + page)を4回変え、終わったら横方向アドレス(pix)を変えていくというのがわかります。
このソースは可読性に優れていますよね。
しかし、個人的にはあまりこのような方法は使っていませんでした。
理由は、この方法だと転送のたびにアドレス計算をしているからです。
ここに、予想以上に時間がかかっていました!!
その測定結果がこちら。
4文字の4倍サイズの文字を送るのに1.41msecかかっています

アドレスの計算をさせない方法
いつもやる通り、アドレス計算をさせず、ポインタを使ってスクリーンバッファへ文字を書いていきます。
int width = 22; //4倍文字の横幅(dot, 高さは32dot=4ページ)
int row = 0; //表示を開始するページ
int pix = 0; //表示を開始する横の位置
int cg = CHAR_4X; //4倍文字のフォントデータ
unsigned char* page0 = &(screenBuffer[row][pix]);
unsigned char* page1 = &(screenBuffer[row + 1][pix]);
unsigned char* page2 = &(screenBuffer[row + 2][pix]);
unsigned char* page3 = &(screenBuffer[row + 3][pix]);
for(int i = 0; i < width; i++) {
*page0++ = *cg++;
*page1++ = *cg++;
*page2++ = *cg++;
*page3++ = *cg++;
}
アドレスは前出の方式の時とは違って、加算処理だけで算出されます。
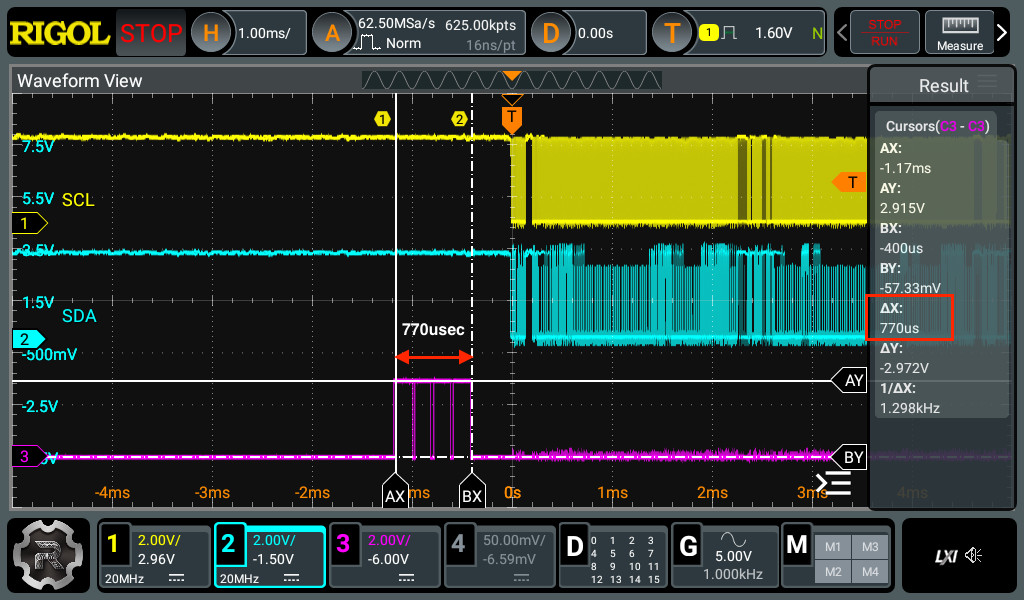
転送時間は770usecまで高速化され、およそ半分の時間まで速くなりました。
長年培った肌感覚...意外に正しい
個人的には、メモリ転送はいつも
for(int i = 0; i < width; i++) {
*dst++ = *src++;
}
という感じでやっています。
やはりアドレス計算って意外に掛け算が出てくることがあるので、可能な限り加算だけで計算したいのです。
今回はページを変えながら...という処理が必要だったので、まずは素直に可読性のいいプログラムにしようと考えました。
処理速度を測定した時、「なんとなく時間がかかりすぎてないか?」と感じたことは、正しかったわけです。
よくよく調べていくと、可読性のいいプログラムがそのままにされていて、ポインタ処理に書き換えてなかったんです。
アプリケーションでこれが問題にならなければ、ポインタに置き換えなくてもいいのかなぁとは思います。
ただ、ポインタ処理に変えても、今回はそれほど可読性が悪くない気はしました。
お客様の実際のアプリケーションがわからないので、今回はポインタに置き換えておけば安心でしょう。
アセンブラで動きを確認するのは大変なので、測定でお茶を濁しました(笑)