Cloud Pak for Data (以下CP4D) の分析プロジェクトで、Notebookから作成したJobを実行した時のログを生成する方法です。
背景として、CP4D v3.0時点ではJob実行ログに任意のログメッセージを含めることができません。(将来機能改善されるはず)
詳細:Job実行ログ
分析プロジェクトのジョブを開き、実行結果であるタイムスタンプ部分をクリックすると、

実行ログが表示されます。しかしこのログはJob (Notebook) を実行したときのPython環境に関するもののみ記録されており、ここに任意のログメッセージを書き込むことができません。(2020/6/11 CP4D v3.0LA時点)

回避策として、Notebook内からログをファイルに出力し、それを分析プロジェクトのデータ資産 (Data Assets) として登録する方法を作成しました。
ログファイルを出力するNotebook例
Python標準のLoggerを使って、コンソール(Notebook内のoutput)とログファイルの両方にログを出力します。
ログファイルはproject_libを使って、分析プロジェクトのデータ資産に登録します。
ログ設定に関してはこちらの記事を参考にさせていただいております。
from pytz import timezone
from datetime import datetime
# logger設定
logger = logging.getLogger("mylogger")
logger.setLevel(logging.DEBUG)
# ログフォーマット設定
def customTime(*args):
return datetime.now(timezone('Asia/Tokyo')).timetuple()
formatter = logging.Formatter(
fmt='%(asctime)s.%(msecs)-3d %(levelname)s : %(message)s',
datefmt="%Y-%m-%d %H:%M:%S"
)
formatter.converter = customTime
# コンソールへのログ出力用ハンドラ設定(Notebook内表示用。レベルはDEBUGに指定)
sh = logging.StreamHandler()
sh.setLevel(logging.DEBUG)
sh.setFormatter(formatter)
logger.addHandler(sh)
# ファイルへのログ出力用ハンドラ設定(Job実行用。レベルはINFOに指定。ログファイルはカレントディレクトリに出力し後ほどData Assetに登録する)
logfilename = "mylog_" + datetime.now(timezone('Asia/Tokyo')).strftime('%Y%m%d%H%M%S') + ".log"
fh = logging.FileHandler(logfilename)
fh.setLevel(logging.INFO)
fh.setFormatter(formatter)
logger.addHandler(fh)
# Data Asset登録用ライブラリ
import io
from project_lib import Project
project = Project.access()
使い方の例です。
try:
logger.info('%s', '処理スタート started')
# やりたい処理をここに書く
# 随時ログメッセージを出力
logger.debug('%s', 'dummy debug message')
logger.info('%s', 'dummy info message')
# わざとエラーを発生させる(0除算)
test = 1/0
except Exception as e:
logger.exception('%s', str(repr(e)))
# ログファイルのData Assetへの書き出し(エラー発生時)
with open(logfilename, 'rb') as z:
data = io.BytesIO(z.read())
project.save_data(logfilename, data, set_project_asset=True, overwrite=True)
# ログファイルのData Assetへの書き出し(正常終了時)
with open(logfilename, 'rb') as z:
data = io.BytesIO(z.read())
project.save_data(logfilename, data, set_project_asset=True, overwrite=True)
実行結果
Notebook内で実行してみると、以下のようにログがoutputとして得られ、ログファイルがデータ資産に生成されます。
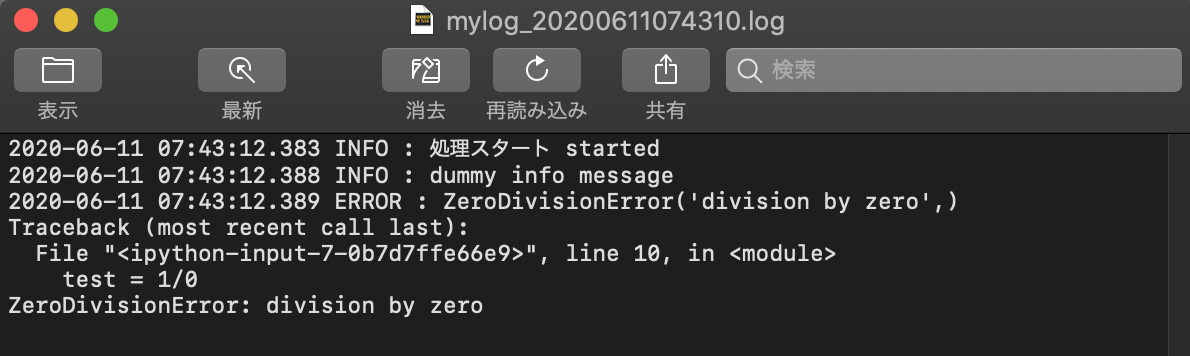
2020-06-11 07:43:12.383 INFO : 処理スタート started
2020-06-11 07:43:12.388 INFO : dummy info message
2020-06-11 07:43:12.389 ERROR : ZeroDivisionError('division by zero',)
Traceback (most recent call last):
File "<ipython-input-7-0b7d7ffe66e9>", line 10, in <module>
test = 1/0
ZeroDivisionError: division by zero
また、Notebookをバージョン保存してJobを作成して、Jobを実行すると、ログファイルがデータ資産に生成されます。
生成されたログファイルはこんな感じです。

ダウンロードして中身を確認してみます。ログファイルはレベルをINFOにしたのでDEBUGメッセージは含まれてません。
ログファイル名に関する考察
データ資産がログファイルで埋まっていくのは、データ資産の本来の用途を考えると気持ちいいものではありません。なので、ログファイルは1つとして常に上書きしていく方法が考えられます。
しかし、CP4DはOpenShift(Kubernates)なので、JobのPython環境はPodとして実行時に生成され終了したら消滅します。なので、1つのファイル名の場合、最新のJob実行分のみがログファイルに記録され、過去履歴は上書きで消えてしまいます。
そのため、上の例ではログファイル名にタイムスタンプを含めて、履歴を残すようにしてみました。
このあたりは、用途に応じて調整していただければ。
以上、データ資産がログで埋まるのはイマイチですが、本来のJobログに任意のログ出力ができるようになるまでは、しばらくこれで凌ぐしか無いです。他には、DBテーブルにログを記録していくという方法も考えられます。