環境・ライブラリ
AWS EC2
インスタンスタイプ:p2.xlarge
Keras
目的
手塚治、藤子不二雄、高橋留美子、鳥山明、宮崎駿の5名の漫画家の画像をインターネットから集めて転移学習させて、学習で利用していない未知の画像を読み込ませて作者が誰かを予測してみる。
手法
VGG16を利用しました。16層からなるモデルですが、14層までを凍結して、15〜16層の全結合層のみを学習しました。
画像データ収集
Googleから画像を一括でダウンロードできるコマンドラインツール「google-images-download」を利用しました。
参考にしたサイト:https://co.bsnws.net/article/295
pip install google_images_download
データセット割合
1作者あたり
訓練データ:300枚
検証データ:100枚
テストデータ:35枚
5作者分用意したので、訓練データは1,500枚用意しました。
苦労した点
googleimagesdownloadの手法に行き着くのに時間が掛かった
・最初はBing Seach APIを使っていた。
・googleimagesdownloadのデフォルトは100枚までしかダウンロード出来ないが、-cdのオプションを追加することで、100枚以上のデータのダウンロードができるようになった。
画像データセットの準備に苦労した
・削除するデータ
・重複画像データ
・できる限り作者の名前が入ったデータ
・作者以外の人が書いたデータ
・作者本人の顔写真
・キャラクターグッズのデータ
・100枚の中から数枚しか使えるデータが無い場合もあるため、検索文字が大事
例)「ドラゴンボール」ではなく「天津飯 ドラゴンボール」などキャラクター名を指定した方が良質なデータが集まる気がする
以下のようなコマンドでデータを落としてきました。
googleimagesdownload -k "ジャイアン のび太" -l 500 -cd "/Users/XXXX/Downloads/chromedriver"
工夫した点
データセットの件数はそのままで少し中身を入れ替えた
修正前のデータセットは、コミックのデータセットも多く含まれています。
修正後のデータセットからは、コミックのデータセットを削減して、キャラクター画像に置き換えました。
その結果、オプティマイザ「Adam」を利用して、epochs:70で回した結果、accuracyが2ポイントほど上がりました。
実装
スクリプト、データセットはGitHubに置いてます。GitHub
※データセットが全部上げきれていないです。中途半端で申し訳ないです。。
結果
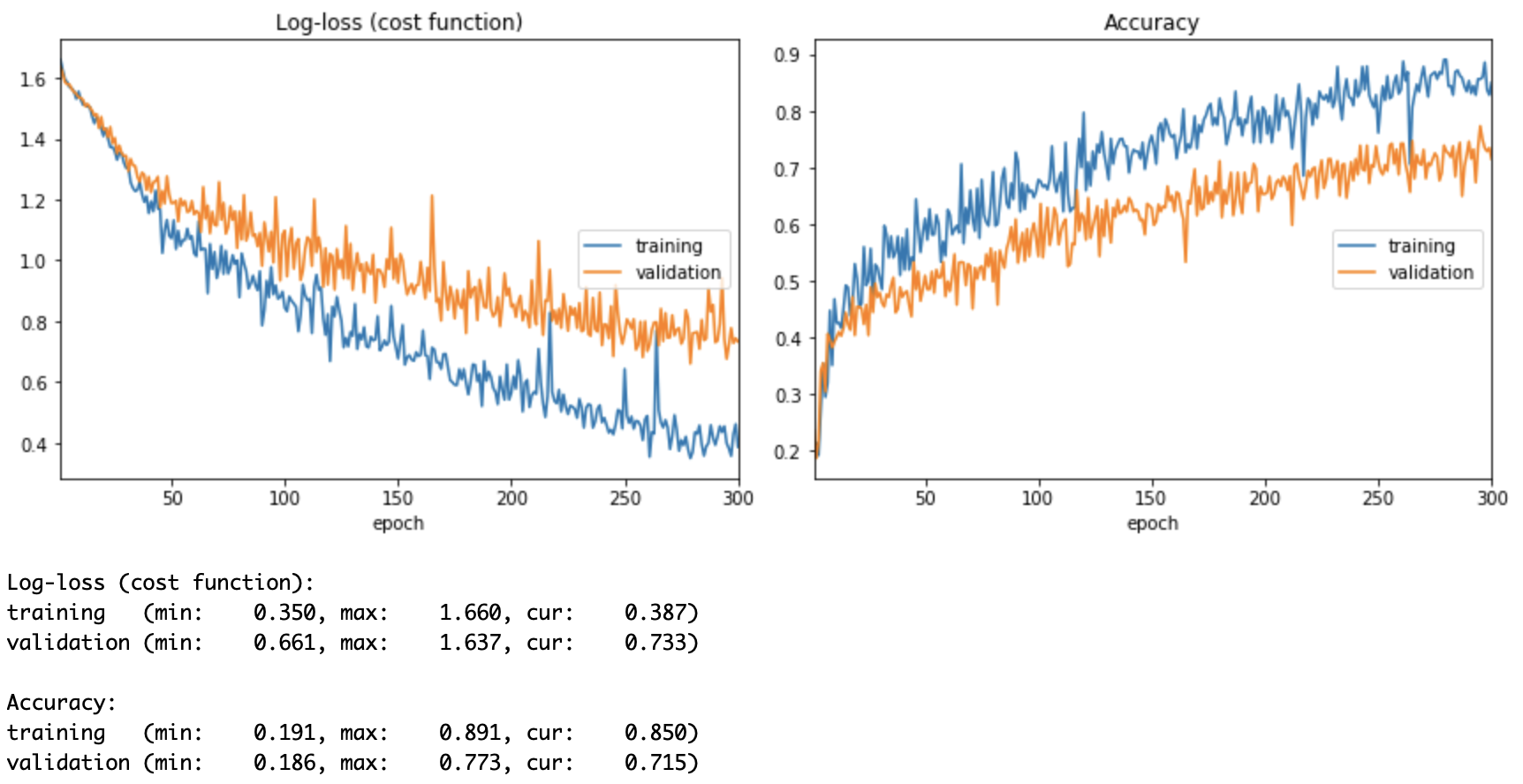
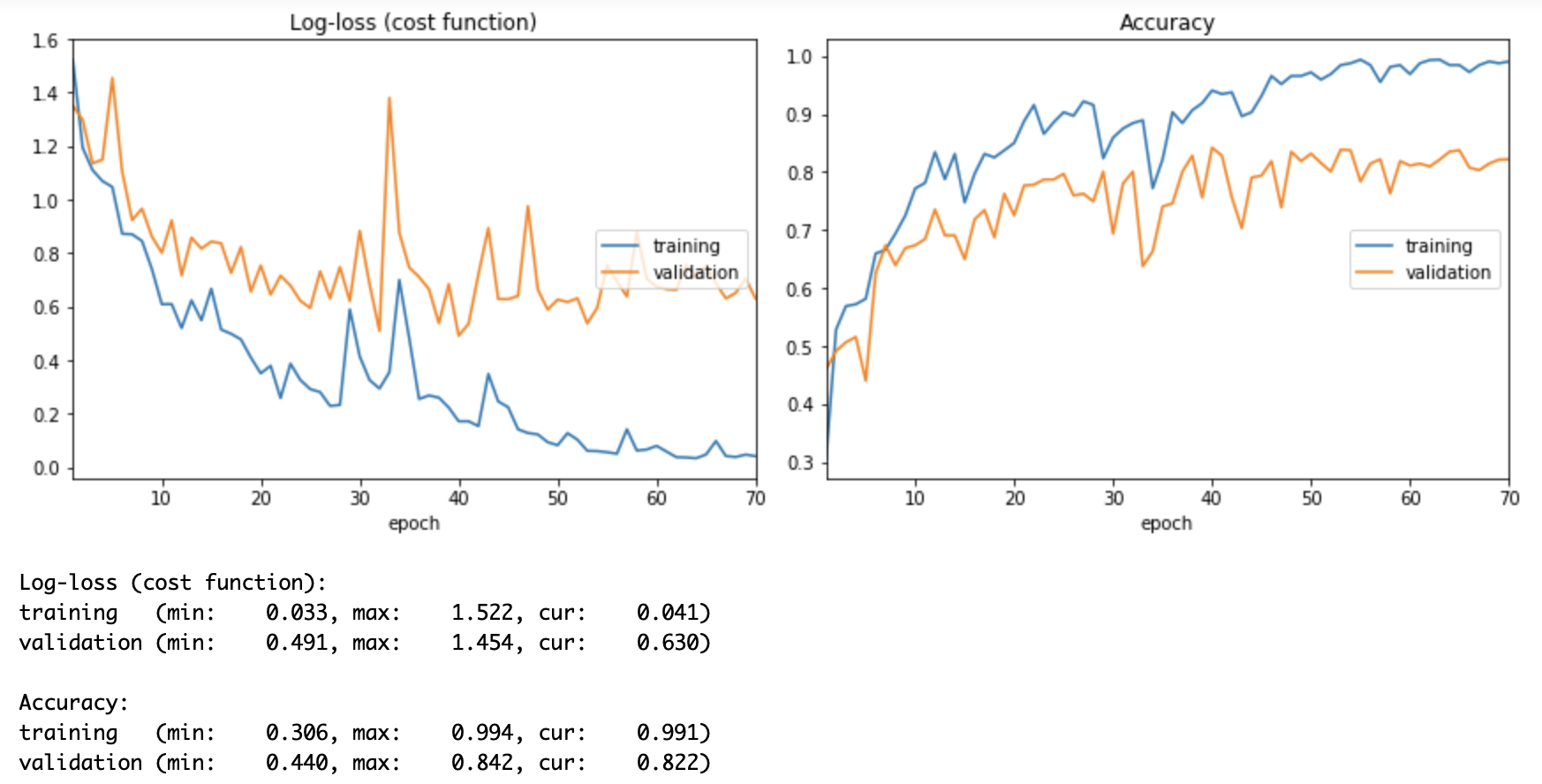
オプティマイザ「SGD」はlossが下がるのに300エポック必要なのに対して、「Adam」は 70エポックで「SGD」の精度を超えている。だいぶ低コストで学習できることが分かる。
🔷SGD
🔷Adam
データセット修正前
epochs=100 SGD test_acc: 0.584375
epochs=200 SGD test_acc: 0.678125
epochs=70 Adam test_acc: 0.80625
データセット修正後
epochs=300 SGD test_acc: 0.78807946940921
epochs=70 Adam test_acc: 0.8178807939125212
ほぼほぼ当たっている。最初(左上)の画像は鳥山明ではなく宮崎駿を間違えていますが。。

改善点
・訓練データセットを1作者あたり500枚まで増やす/コミックデータを極力減らす
・過学習対策としてドロップアウトを追加する
・データ拡張(Data Augmentation) keras.preprocessing.image.ImageDataGeneratorでvertical_flip(画像を垂直方向にランダムに反転する。)を組み込んでみる
引用
ソースコードはこちらのサイトを利用させていただきました。
投下時間
1/5(土)午後:何か実装してみることにした。最初はくずし字データセットを使って何かモデルを作ることを考えたが、それはやめて、転移学習でマンガ作者予測とすることにした。
1/6(日):参考になるサイトを見つけて、まずは動作することを確認するため3名の著名な画家(ゴッホ、ピカソ、ルノワール)のデータを集めて、分類できるか検証した。無事動いたので、マンガで試すべくデータ収集を開始。
1/7(月):マンガで試すべくデータ収集を継続。一旦終わったので学習・推論して結果確認。精度を上げるべくデータ修正。
1/8(火):修正後のデータセットで学習・推論。QiitaへUP。