こんにちは。本日の担当は@ttanimuraです。
今年も冬がやってきました。
私の場合、寒い季節は日本酒(燗):ワイン:焼酎:ハイボール=5:2:2:1ぐらいの確率分布に従って晩酌しているわけですが、12月24日、25日あたりではワイン、特に赤ワインの確率がグッと高まります。
酒は雰囲気込みで楽しむもの。季節のイベントに乗っかってみるのもたまには楽しいものです。
ということで赤ワインです。
UCIが公開している機械学習のデータセット(UCI machine learning repository)の中に
Wine Quality Data Setというものがあります。
ポルトガルの赤ワインについて、クエン酸濃度やアルコール度数などのワインの成分値と、品質スコア(0~10)が収録された有名なデータセットです。
1 - fixed acidity
2 - volatile acidity
3 - citric acid
4 - residual sugar
5 - chlorides
6 - free sulfur dioxide
7 - total sulfur dioxide
8 - density
9 - pH
10 - sulphates
11 - alcohol
Output variable (based on sensory data):
12 - quality (score between 0 and 10)
シンプルなデータですが、このデータを題材にして気軽にディープラーニングの勉強をしてみたいというのが本日の本題です。成分値からスコアを予測してみます。
Neural Network Console
ご存知の方も多いかもしれませんが、今年、SONYさんからディープラーニングの統合開発環境が発表されました。
https://www.sony.co.jp/SonyInfo/News/Press/201708/17-073/index.html
なんと、無料で使えます。太っ腹。
私の場合、業務でディープラーニングを使う機会がなく、最近ではコードを書くことすらめっきり減りました。そんな私にとって、教科書でアルゴリズムを学びながらワイン片手にカジュアルにネットワークいじって動作を試せるGUI環境があるのはとても助かります。私のような初心者に限らず、多層の構造を視覚的に捉えられる恩恵は大きいのではないでしょうか。
さて、Neural Network Consoleはアプリ版、クラウド版の2種類が提供されています。(利用はこちらから)
両方使ってみた感想としてはアプリ版の方が圧倒的にお薦めなのですが、残念ながらアプリ版は今のところWindowsにしか対応していません。今後に期待です。
使ってみる
データの準備
では使っていきます。まずは事前準備です。
先ほどのデータセット(winequality-red.csv)をダウンロードします。
最初にcsvの列名を変更します。
Neural Network Consoleの求めるカラム名をつけてあげる必要があります。
x__0:ラベル名という形で名前をつけます。xが変数名で任意の名前でいいのですが、今回は面倒なのでxのままでいきます。
__を挟んだ数値が当該変数(ベクトル)のインデックスになります。ラベル名は任意です。今回はデータセットの元々の項目名をラベル名とします。
こんな感じです。
x__0:fixed acidity x__1:volatile acidity x__2:citric acid x__3:residual sugar x__4:chlorides x__5:free sulfur dioxide x__6:total sulfur dioxide x__7:density x__8:pH x__9:sulphates x__10:alcohol y:quality
次にデータセットを分割します。
Neural Network Consoleへの入力データとして事前にtraining用、validation用、test用のデータを用意する必要があります。今回のデータは1600件のレコードがありますので、適当に1200件、200件、200件に分割しました。ここはメモ帳で頑張りました。
データセットの登録
Neural Network Consoleを起動します。
まずは、データセットの登録です。
アプリの場合は、DATASETタブからOpen Datasetですぐに登録できます。
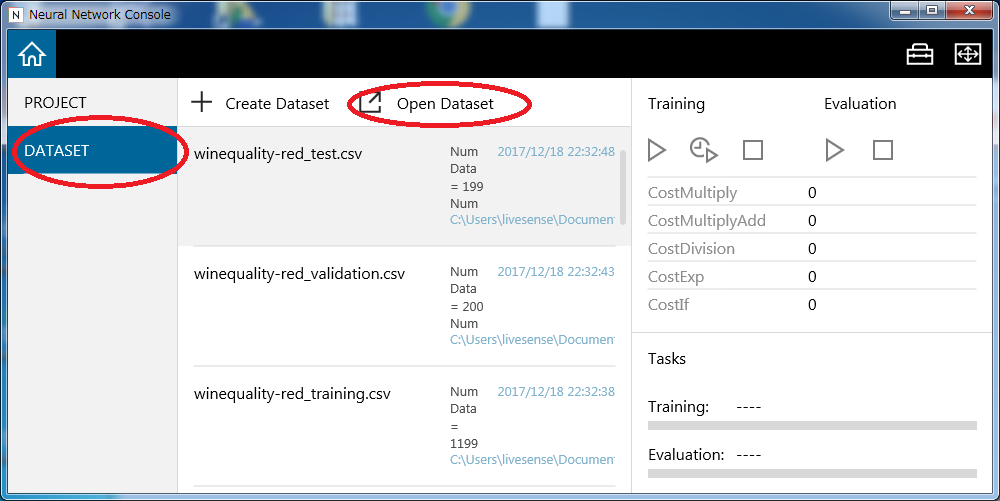
クラウド版の場合は一手間必要です。アップローダーをダウンロードして、クラウドの画面で提供されたトークンをコピペしてクライアントからアップロードします。割と待ちます。我慢です。
回帰モデルの作成
いよいよ、モデルを作ります。
New Projectからプロジェクトを作って、まずは先ほど登録したデータセットを今回利用するデータとして登録していきます。
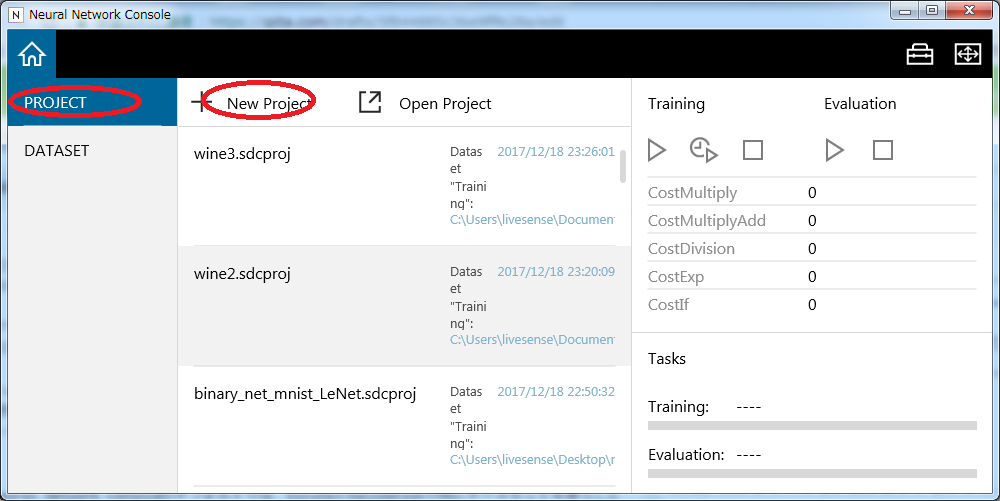
Neural Network Consoleのデフォルトでは、ExcuterとValidationで同じデータセットを使うことになっていますが、汎化性能の評価としてはここは分けておきたいところ。そこでConfigタブからExecuteを選択し、DatasetをValidationからTestに変更します。
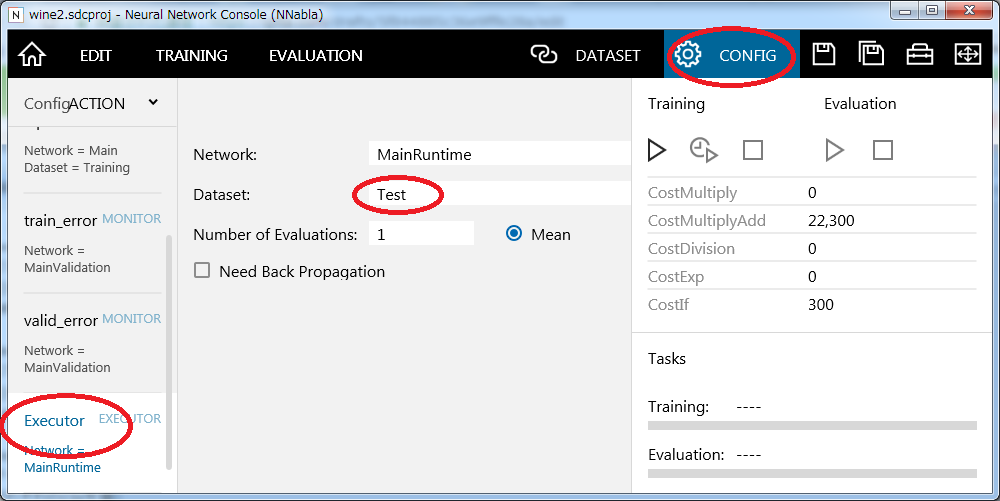
次にモデルにデータセットを紐付けます。データセットタブを開きます。デフォルトではTrainingとValidationの2つのデータセットが登録可能になっていますので、ActionからAddを選択してTestを追加します。これでTrainingとValidation、Testの3つのデータセットが登録可能になりましたので、先ほど登録したCSVファイルを紐付けます。
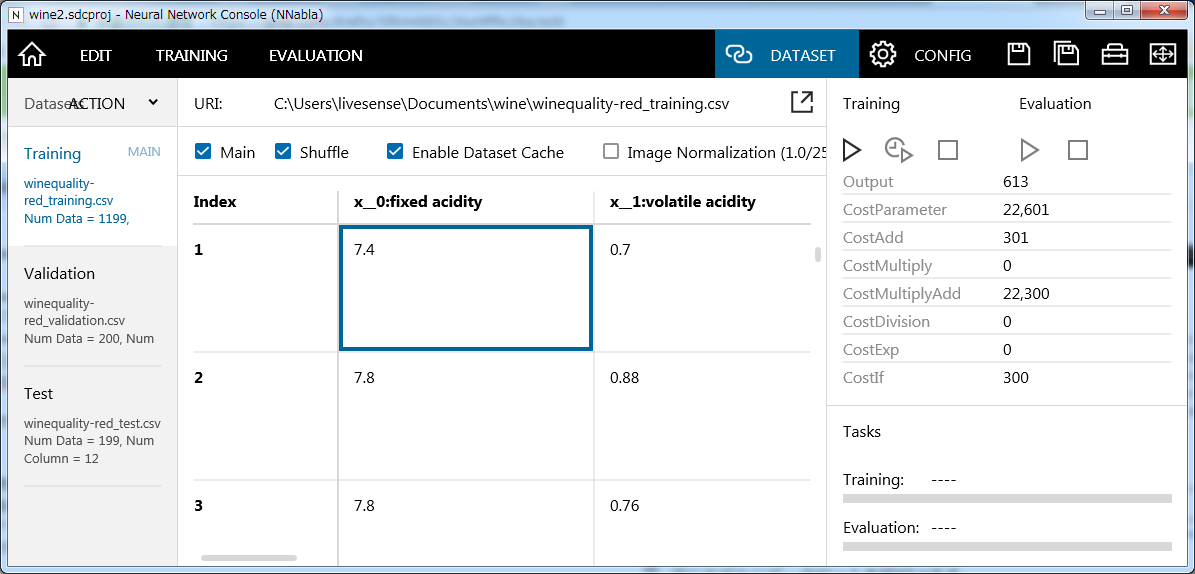
いよいよネットワーク構造を定義していきます。
まずは入力層、出力層だけのシンプルな回帰モデルを作ってみます。
最初に入力層を作ります。
基本Inputのコンポーネントをドラッグアンドドロップで持ってくるだけの簡単な操作ですが、一箇所だけパラメータを変更する必要があります。データのサイズです。今回は11個の変数を入力とするので11に変更します。デフォルトでは画像入力を想定して3次元の値がセットがされており、サイズくらい自動でセットされるだろうという甘い考えでいるとエラーになってしまいます。私はしっかり嵌りました。
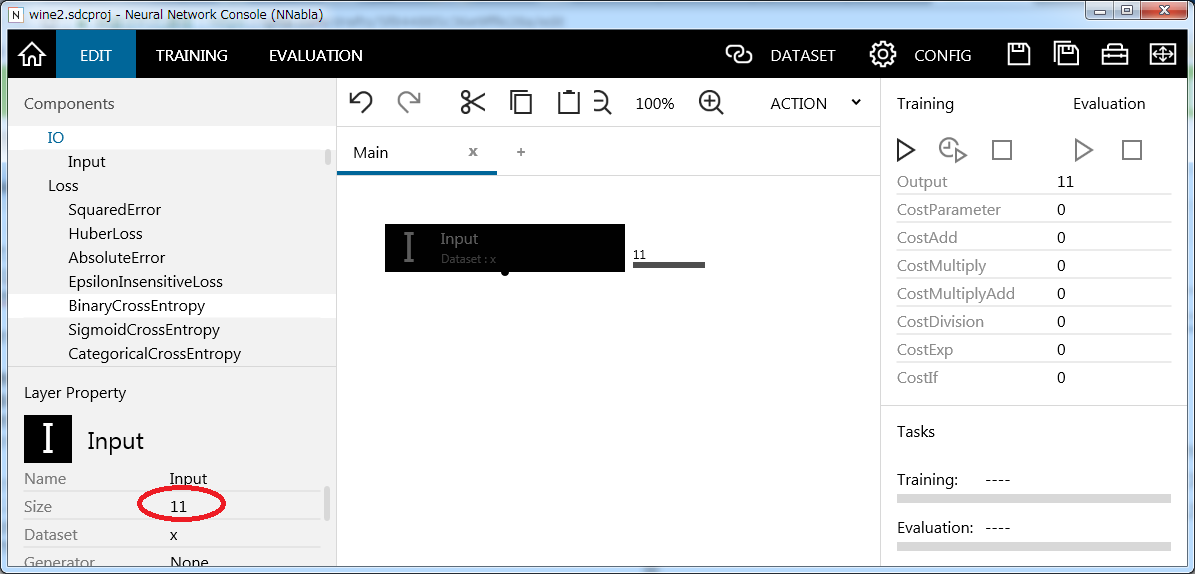
とりあえず、回帰モデルということで次の層にAffineレイヤーを持ってきます。Affineレイヤーの各ユニットは、入力となるレイヤーのユニットの線形結合で表現されます。このAffineレイヤーのユニット数を1にセットすればシンプルな回帰モデルを表現できます。最後に誤差関数としてSquaredErrorをつなげてあげればネットワーク完成です。
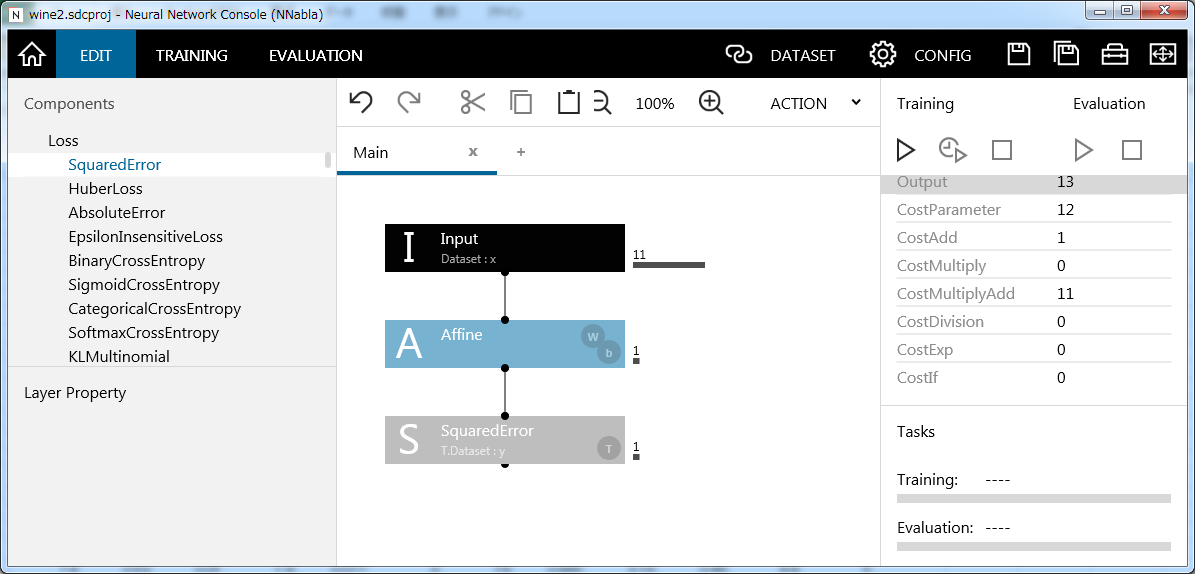
この状態でTrainingの実行ボタンを押してみます。すると、学習が始まり学習曲線が更新されていきます。動いていく様子が分かるのでワクワクします。
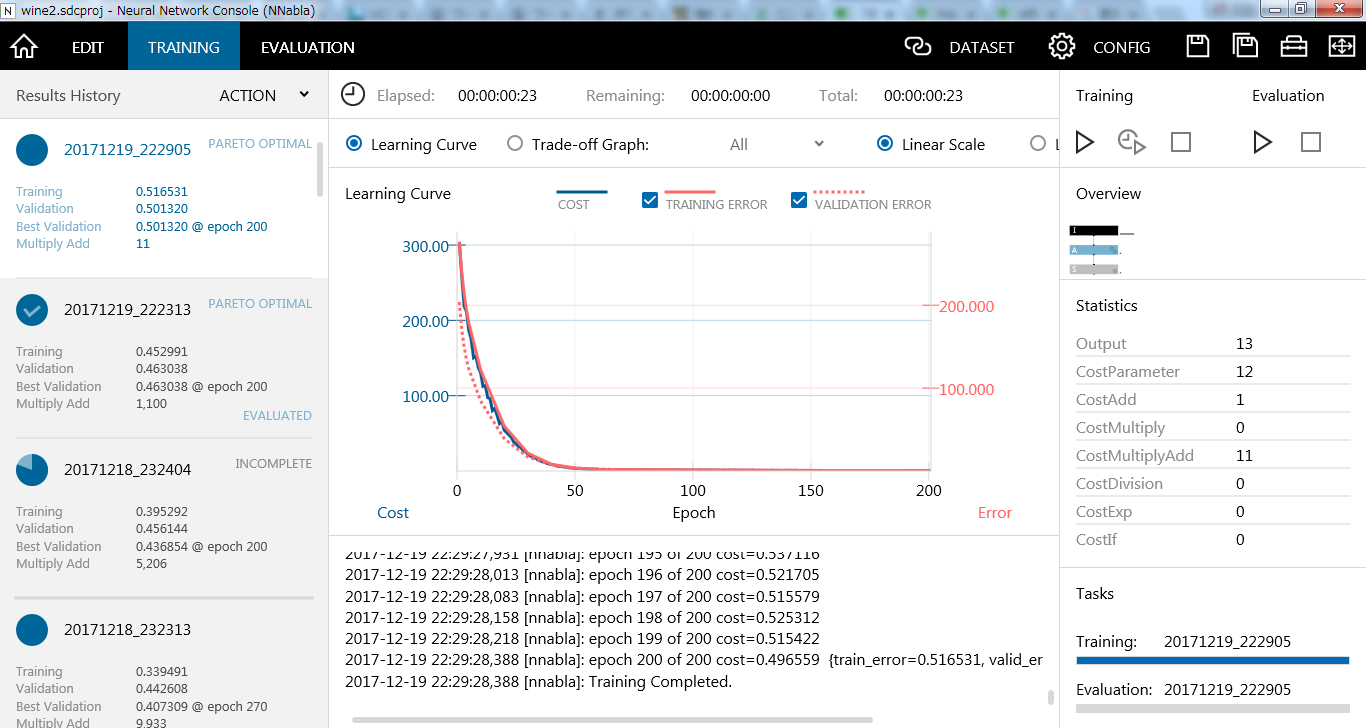
なお、クラウド版の場合はしばらく待ち状態になってから学習が始まります。まあ待ちます。我慢です。
赤の実線がTraining Errorで破線がValidation Errorです。今回のモデルでは50ぐらいのEpoch数で最適化が完了しているのが分かります。
このままEvaluationを実行します。
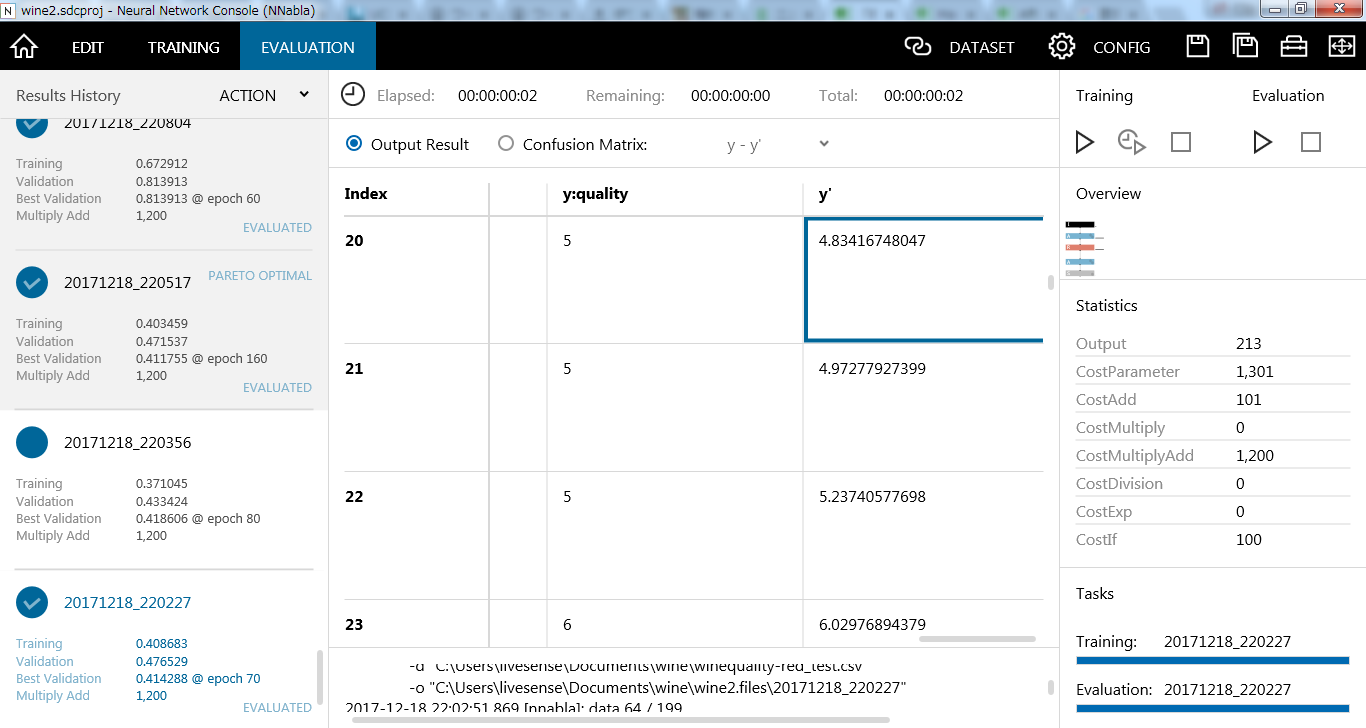
y:qualityの右にy'という列が追加されています。これがモデルの予測値です。なんだかそれっぽい雰囲気なのは分かります。さらにConfusionMatrixを選ぶとAccuracyが確認できて0.56となっています。予測値の半分くらいは正解していることになります。この時点で私のテイスティングの精度は超えている気がします。
層を追加してみる
上の例だと全然ディープじゃないので、無理やりディープにしてみます。
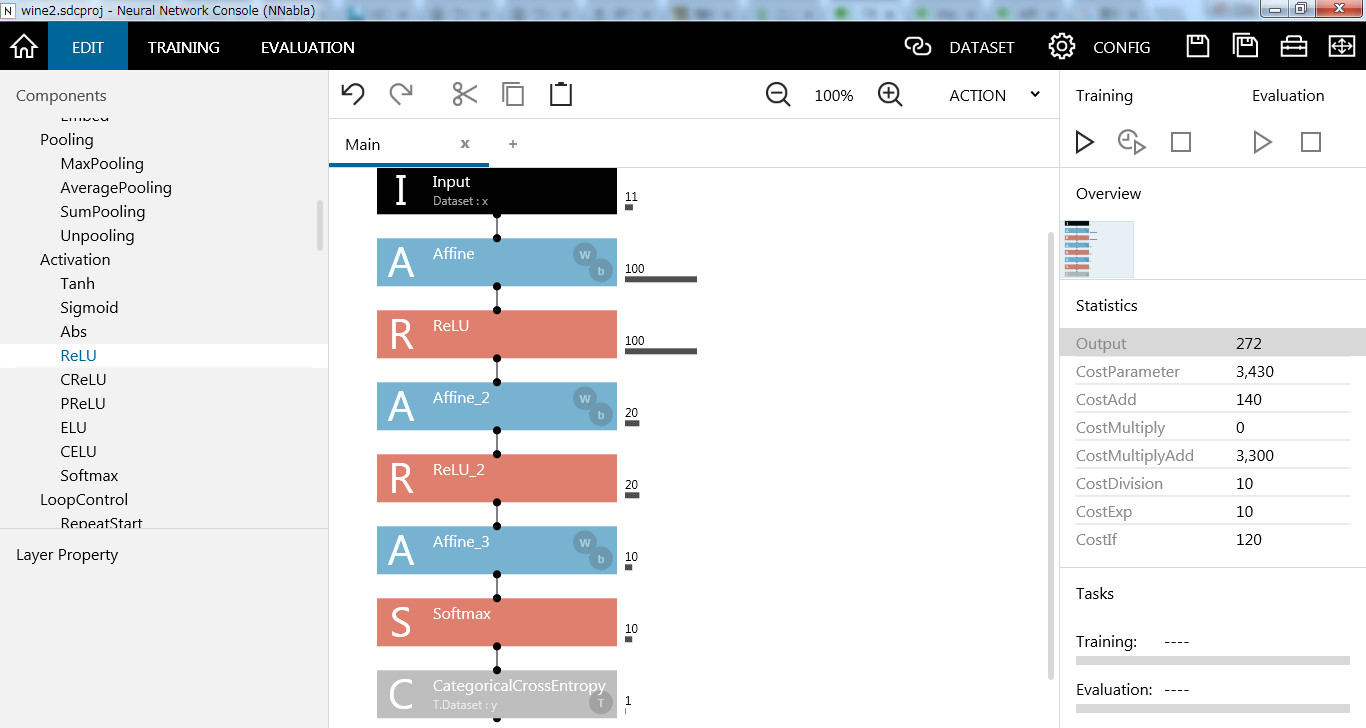
こんな感じで、いくらでも層を追加できます。ここではReLUを使ってますが、活性化関数も色々準備されています。ドキュメントもしっかり整備されていて便利です。
さらに先ほどは回帰問題としてモデルを組み立てていましたが、今回は多値分類として出力層の活性化関数にSoftmax、誤差関数にCategoricalCrossEntropyを選びました。
実行してみましたが、Accuracyは0.51、残念ながら先ほどよりも精度は下がりました。そんなに甘くないです。
その他にもいろいろ
Configタブから色々変更が出来ます。分かりやすいところで、Epoch数やミニバッチのサイズを選ぶことが出来ます。
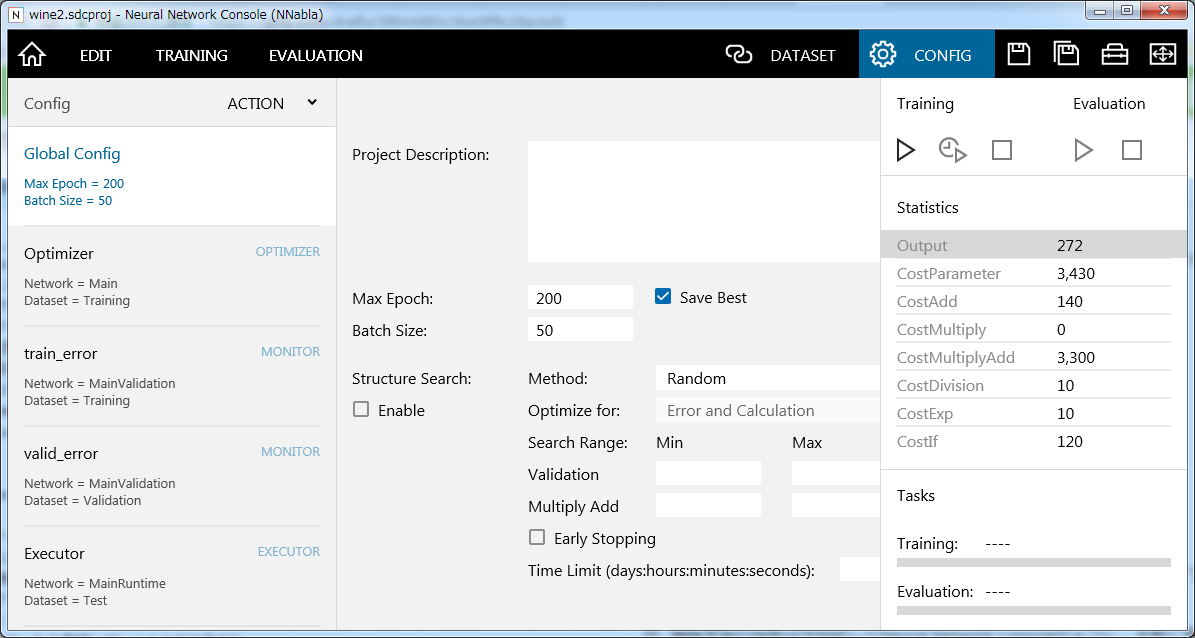
さらにStructure SearchのEnableをOnにすると、コンポーネントを入れ替えて色々なモデル構造を探索してくれるようになります。面白いのですが、私が試した限りではうまくいきそうな予兆は見えませんでした。
ご注意
Structure SearchをONにした状態で学習を実行すると、ユーザが明示的に学習停止ボタンを押すなどしない限り永久に学習が継続されます。
まあ、面白いので一度動かしてみてください。飽きたら自分で止めましょう。
最後にOptimizerです。
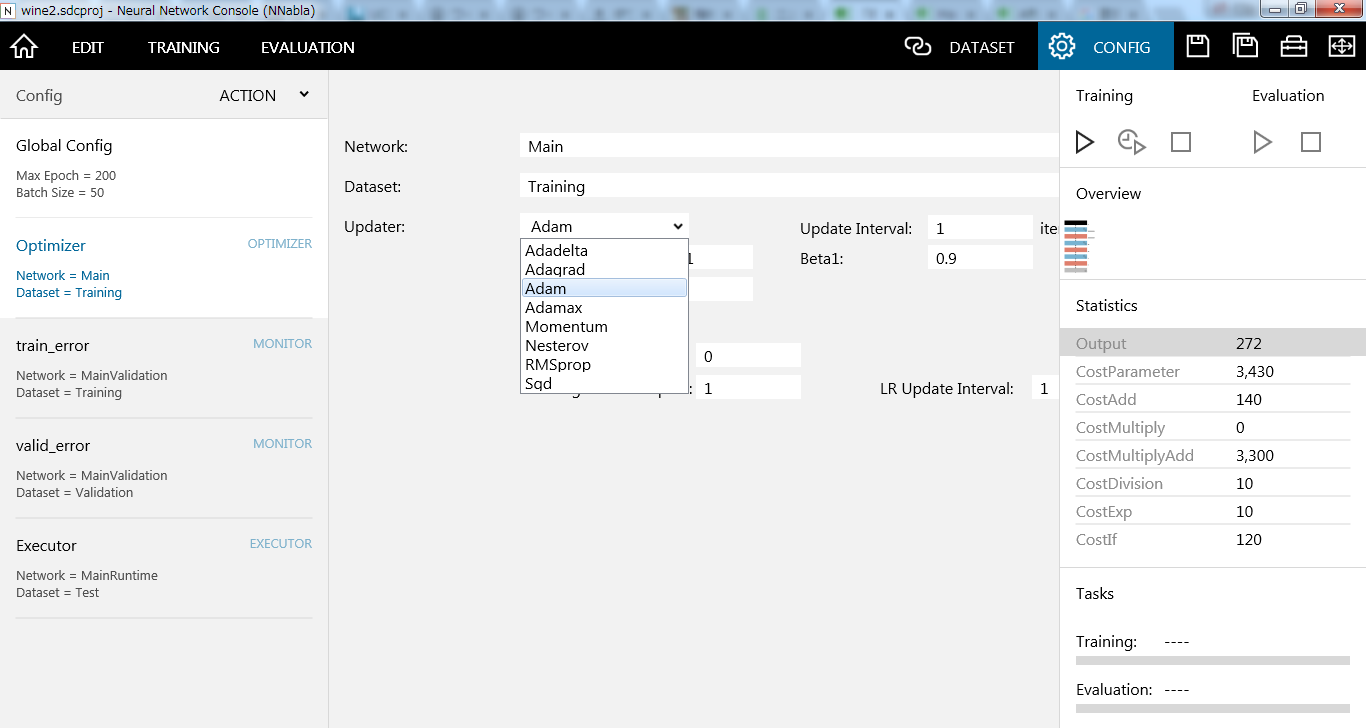
ここでは、更新アルゴリズムの設定を行うことが出来ます。色々選べます。
先のミニバッチのサイズ含めて試してみましたが、実務でやるのは大変そうで、Neural Network Consoleに限った話ではないのですが、パラメーターチューニング簡単ではないな、というのが月並みな感想です。
最後に
ほんとに便利な時代になったと思います。
今回はWine Quality Data Setを学習データとして使いましたが、酒飲みの立場からすると、ワインの味の感じ方はそれ自体の質に加えて、飲む日の天候、ワインの温度、グラス、あわせる料理、そして何よりどこでだれと飲むかが重要というのが正直なところです。
機械学習の技術は今回試したNeural Network Consoleのように手軽に使えるものがどんどん出てきています。ワインを飲むシチュエーションのように一般化されていないデータを蓄積して、データによる差別化を行っていくことが今後のサービスには必要ですね。
乾杯