前回までのあらすじ
- 自作PCを作ろう!
- まずメモリを作ったよ!
- ISAを作ったよ!(コンパイラはまだ)
- アセンブリ言語を作ったよ!(コンパイラはまだ)
- CPUを作ったよ!
- 任意のプログラムを実行できるようになったよ!
- キーボード入力を受け付けられるようになったよ!(ただし独力ではない)
今回の目標
前回で,キーボード入力をオウム返しできるPCになりました.
ただそれだけだとせっかくプログラムを実行できるのに特に意味のないことしかできないので,今回は自然数同士の計算を行えることを目標とします.
前回からの変更
レジスタでタイミングエラーが出るので,パイプラインっぽい設計に変更しました.
今までは,命令フェッチや実行などを全て一クロックで終わらせていました.
しかしそれだと,実行するプログラムが長くなってくるとタイミングエラーが出てしまうので,プログラム実行を三段階に分けることにしました.
- 命令フェッチ
- 命令で指定されているレジスタなどが,書き込みまたは読み込み可能かどうかチェックする.また,実行前準備を行う
- 処理を実行する
ちなみに,タイミングエラーが出ているレジスタは以下の方法で特定することが出来ます.
僕はこれを知らなかったので,今までタイミングエラーが出たら諦めていました.
- 「implemented design」を開く
- 「reports > timing > reoprt timing summary」
- 画面の下の方に出力される
修正したaluソースはこんな感じです.長いので格納します.
alu
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer:
//
// Create Date: 2025/04/20 16:41:07
// Design Name:
// Module Name: alu_sv
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////
`include "rom.svh"
`include "decorder.svh"
`include "alu.svh"
`include "ram.svh"
`include "machine.svh"
module alu_sv (
input logic clk,
input logic resetn,
rom_read_if.master rom_read,
command_if.master command,
// メモリ読み込みインターフェース
ram_read_if.master ram_read,
// メモリ書き込みインターフェース
ram_write_if.master ram_write,
input logic [3:0] btn,
input logic [1:0] sw,
output logic [3:0] led,
output logic [5:0] rgb_led,
output logic [7:0] number,
// 割り算回路用
output logic [31:0] divisor_tdata,
output logic divisor_tvalid,
output logic [31:0] dividend_tdata,
output logic dividend_tvalid,
input logic [63:0] dout_tdata,
input logic dout_tvalid,
// 標準入出力
input logic [31:0] stdin_tdata,
input logic [ 3:0] stdin_tkeep,
input logic stdin_tlast,
output logic stdin_tready,
input logic stdin_tvalid,
output logic [31:0] stdout_tdata,
output logic [ 3:0] stdout_tkeep,
output logic stdout_tlast,
input logic stdout_tready,
output logic stdout_tvalid
);
// import文
import alu_p::*;
import ram_p::*;
import machine_p::*;
// 内部レジスタ
register_t register[6'h34:0] = {0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
// 実行フェーズ
cpu_phase_enum cpu_phase = CPU_FETCH;
// 実行前のものをいったん保存しておく
machine_p::machine_t ir = nop(); // 命令
register_t rs1_val_r = '0;
register_t rs2_val_r = '0;
machine_p::addr_t rd_addr_r = '0;
machine_p::func_t func_r = '0;
machine_p::imm_t imm_r = '0;
machine_p::mask_t mask_r = '0;
// メモリ読み込み・書き出し状態
ram_p::state_enum ram_read_state = IDLE;
ram_p::state_enum ram_write_state = IDLE;
// 標準入出力の入出力状態
ram_p::state_enum stdin_state = IDLE;
ram_p::state_enum stdout_state = IDLE;
// 割り算回路の状態
ram_p::state_enum div_state = IDLE;
// 強制リセット
logic force_reset = 1'b0;
// 組み合わせ回路
always_comb begin
// 機械語を分解してもらう
command.machine = ir;
// メモリのバースト転送はオミットする
ram_read.last = 1'b1;
ram_write.last = 1'b1;
// デバッグ用
// led = register[6'h05][3:0];
led = register[6'h32][3:0];
rgb_led = 6'h0;
// number = register[PC_ADDR][7:0];
number = register[6'h31][7:0];
// pcを出力する
rom_read.pc = register[PC_ADDR];
// 標準入出力
stdout_tkeep = 4'hf;
stdout_tlast = 1'b1;
end
// 順序回路
always_ff @(posedge clk) begin
// リセット
if (!resetn || force_reset) begin
// 実行状態をリセット
cpu_phase <= CPU_FETCH;
ir <= nop();
rs1_val_r <= '0;
rs2_val_r <= '0;
rd_addr_r <= '0;
func_r <= '0;
imm_r <= '0;
mask_r <= '0;
// 割り算回路用
divisor_tdata <= '0;
divisor_tvalid <= 1'b0;
dividend_tdata <= '0;
dividend_tvalid <= 1'b0;
div_state <= IDLE;
// メモリの読み込み・書き出し状態をリセット
ram_read_state <= IDLE;
ram_write_state <= IDLE;
// 標準入出力の状態をリセット
stdin_state <= IDLE;
stdout_state <= IDLE;
// メモリ読み書き
ram_read.address <= 0;
ram_read.mask <= 0;
ram_read.valid <= 0;
ram_write.address <= 0;
ram_write.data <= 0;
ram_write.mask <= 0;
ram_write.valid <= 0;
// レジスタ(標準入出力を覗く)
for (logic [5:0] i = 0; i <= 6'h30; i++) begin
register[i] <= 0;
end
// 強制リセット状態は元に戻さない.
// 強制リセットが働いたときはリセット状態から戻さない.
end
// 命令実行
else begin
// IOからレジスタに値を格納する
register[6'h20] <= {4'b0, btn};
register[6'h21] <= {6'b0, sw};
register[6'h31] <= stdin_tdata;
register[6'h32][2] <= stdin_tlast;
register[6'h32][1] <= stdin_tvalid;
register[6'h32][0] <= stdin_tready;
register[6'h33] <= stdout_tdata;
register[6'h34][2] <= stdout_tlast;
register[6'h34][1] <= stdout_tvalid;
register[6'h34][0] <= stdout_tready;
// CPUの実行サイクルごとに処理記載
unique case (cpu_phase)
// フェッチ
CPU_FETCH: begin
// 命令を取得してくる
ir <= rom_read.machine;
// 次のサイクルへ
cpu_phase <= CPU_CHECK;
end
// 実行前確認
CPU_CHECK: begin
// 関数タイプごとに実行
unique case (command.m_type)
// 処理を実行しない(N系)
N_TYPE: begin
// 確認はないので実行
cpu_phase <= CPU_EXECUTE;
end
// 演算系(P系)
P_TYPE: begin
// 指定されているアドレスが全て使用可能な場合のみ,処理を実行する
if (
is_readable(command.rs1)
&& is_readable(command.rs2)
&& is_writable(command.rd)
// イミディエイトデータを使用する場合,そのアドレスも確認する
&& (!command.imm[32] || is_writable(command.imm[5:0])
)
) begin
cpu_phase <= CPU_EXECUTE;
// 実行前準備
rs1_val_r <= register[command.rs1];
rs2_val_r <= register[command.rs2];
rd_addr_r <= command.rd;
imm_r <= command.imm;
func_r <= command.func;
end
else begin
force_reset <= 1'b1;
end
end
// シフト系(S系)
S_TYPE: begin
// イミディエイトデータを使用するなら
if (command.imm[32]) begin
// 指定されているアドレスが全て使用可能な場合のみ,処理を実行する
if (
is_readable(command.rs1)
&& is_writable(command.rd)
) begin
cpu_phase <= CPU_EXECUTE;
end
else begin
force_reset <= 1'b1;
end
end
else begin
// 指定されているアドレスが全て使用可能な場合のみ,処理を実行する
if (
is_readable(command.rs1)
&& is_readable(command.rs2)
&& is_writable(command.rd)
) begin
cpu_phase <= CPU_EXECUTE;
end
else begin
force_reset <= 1'b1;
end
end
// 実行前準備
rs1_val_r <= register[command.rs1];
rs2_val_r <= register[command.rs2];
rd_addr_r <= command.rd;
imm_r <= command.imm;
func_r <= command.func;
end
// 代入系(A系)
A_TYPE: begin
// イミディエイトデータを使用するなら
if (command.imm[32]) begin
// 指定されているアドレスが全て使用可能な場合のみ,処理を実行する
if (is_writable(command.rd)) begin
cpu_phase <= CPU_EXECUTE;
end
else begin
force_reset <= 1'b1;
end
end
else begin
// 指定されているアドレスが全て使用可能な場合のみ,処理を実行する
if (is_readable(command.rs1) && is_writable(command.rd)) begin
cpu_phase <= CPU_EXECUTE;
end
else begin
force_reset <= 1'b1;
end
end
// 実行前準備
rs1_val_r <= register[command.rs1];
rd_addr_r <= command.rd;
imm_r <= command.imm;
func_r <= command.func;
end
// 分岐系(F系)
F_TYPE: begin
// 使用されているアドレスが全て使用可能
// かつイミディエイトデータを使用する設定の時だけ,処理を実行する
if (
is_readable(command.rs1)
&& is_readable(command.rs2)
&& command.imm[32]
) begin
cpu_phase <= CPU_EXECUTE;
// 実行前準備
rs1_val_r <= register[command.rs1];
rs2_val_r <= register[command.rs2];
imm_r <= command.imm;
func_r <= command.func;
end
else begin
force_reset <= 1'b1;
end
end
// ジャンプ系(J系)
J_TYPE: begin
// イミディエイトデータを使用しないなら
if (!command.imm[32]) begin
// 指定されているアドレスが全て使用可能な場合のみ,処理を実行する
if (is_readable(command.rs1)) begin
cpu_phase <= CPU_EXECUTE;
end
else begin
force_reset <= 1'b1;
end
end
// イミディエイトデータを使用するならチェック不要
else begin
cpu_phase <= CPU_EXECUTE;
end
// 実行前準備
rs1_val_r <= register[command.rs1];
imm_r <= command.imm;
func_r <= command.func;
end
// メモリ系(M系)
M_TYPE: begin
// 命令ごとのチェック項目
unique case (command.func)
// メモリ読み込み
RM: begin
if (
// rdに書き込み可能か
is_writable(command.rd)
// イミディエイトデータを使用しない場合,rs1が読み取り可能かについてもチェックする
&& (command.imm[32] || is_readable(command.rs1))
) begin
cpu_phase <= CPU_EXECUTE;
// 実行前準備
rs1_val_r <= register[command.rs1];
rd_addr_r <= command.rd;
imm_r <= command.imm;
mask_r <= command.mask;
func_r <= command.func;
end
else begin
force_reset <= 1'b1;
end
end
// メモリ書き込み
WM: begin
if (
// rs2は読み込み可能か
is_readable(command.rs2)
// イミディエイトデータを使用しない場合,rs1が読み取り可能かについてもチェックする
&& (command.imm[32] || is_readable(command.rs1))
) begin
cpu_phase <= CPU_EXECUTE;
// 実行前準備
rs1_val_r <= register[command.rs1];
rs2_val_r <= register[command.rs2];
imm_r <= command.imm;
mask_r <= command.mask;
func_r <= command.func;
end
else begin
force_reset <= 1'b1;
end
end
// それ以外はオミット
default: begin
force_reset <= 1'b1;
end
endcase
end
// 標準入出力系(IO系)
IO_TYPE: begin
// 命令ごとのチェック項目
unique case (command.func)
// 標準入力
SCAN: begin
if (is_writable(command.rd)) begin
cpu_phase <= CPU_EXECUTE;
// 実行準備もしておく
rd_addr_r <= command.rd;
func_r <= command.func;
end
else begin
force_reset <= 1'b1;
end
end
// 標準出力
PRINT: begin
if (is_readable(command.rs1)) begin
cpu_phase <= CPU_EXECUTE;
// 実行前準備もしておく
rs1_val_r <= register[command.rs1];
imm_r <= command.imm;
func_r <= command.func;
end
else begin
force_reset <= 1'b1;
end
end
default: begin
force_reset <= 1'b1;
end
endcase
end
default: begin
force_reset <= 1'b1;
end
endcase
end
// 処理の実行
CPU_EXECUTE: begin
// 関数タイプごとに実行
unique case (command.m_type)
// 処理を実行しない(N系)
N_TYPE: begin
// pcをカウントアップ
register[PC_ADDR] <= register[PC_ADDR] + 1;
// フェッチに戻る
cpu_phase <= CPU_FETCH;
// 不正な値が入っても全て無視する
end
// 演算系(P系)
P_TYPE: begin
// 命令に応じて処理実行
unique case (func_r)
AND: register[rd_addr_r] <= rs1_val_r & rs2_val_r;
OR: register[rd_addr_r] <= rs1_val_r | rs2_val_r;
XOR: register[rd_addr_r] <= rs1_val_r ^ rs2_val_r;
NOT: register[rd_addr_r] <= ~rs1_val_r;
NAND: register[rd_addr_r] <= ~(rs1_val_r & rs2_val_r);
ADD: register[rd_addr_r] <= rs1_val_r + rs2_val_r;
SUB: register[rd_addr_r] <= rs1_val_r - rs2_val_r;
MUL: register[rd_addr_r] <= rs1_val_r * rs2_val_r;
// 割り算
DIV: begin
unique case (div_state)
// 入力をIPへ送信
IDLE: begin
dividend_tdata <= rs1_val_r;
divisor_tdata <= rs2_val_r;
dividend_tvalid <= 1'b1;
divisor_tvalid <= 1'b1;
div_state <= EXECUTE;
end
// IPはtreadyなし(常にready)なので1サイクル待ってRESPONSEへ
EXECUTE: begin
dividend_tvalid <= 1'b0;
divisor_tvalid <= 1'b0;
div_state <= RESPONSE;
end
// 計算結果が返ってくるまで待機
RESPONSE: begin
if (dout_tvalid) begin
// 商をrdへ格納
register[rd_addr_r] <= dout_tdata[63:32];
// imm[32]=1なら余りをimm[5:0]のアドレスへ格納
if (imm_r[32]) begin
register[imm_r[5:0]] <= dout_tdata[31:0];
end
div_state <= IDLE;
register[PC_ADDR] <= register[PC_ADDR] + 1;
cpu_phase <= CPU_FETCH;
end
end
default: force_reset <= 1'b1;
endcase
end
default: force_reset <= 1'b1;
endcase
// DIV以外はここでPCインクリメントとFETCH遷移
if (func_r != DIV) begin
register[PC_ADDR] <= register[PC_ADDR] + 1;
cpu_phase <= CPU_FETCH;
end
end
// シフト系
S_TYPE: begin
// シフト系はどの命令でもpcをカウントアップする
register[PC_ADDR] <= register[PC_ADDR] + 1;
// イミディエイトデータを使用する?
if (imm_r[32]) begin
// 命令に応じて処理実行
unique case (func_r)
SLL: register[rd_addr_r] <= rs1_val_r << imm_r[31:0];
SRL: register[rd_addr_r] <= rs1_val_r >> imm_r[31:0];
SLA: register[rd_addr_r] <= rs1_val_r <<< imm_r[31:0];
SRA: register[rd_addr_r] <= rs1_val_r >>> imm_r[31:0];
default: force_reset <= 1'b1;
endcase
end else begin
// 命令に応じて処理実行
unique case (func_r)
SLL: register[rd_addr_r] <= rs1_val_r << rs2_val_r;
SRL: register[rd_addr_r] <= rs1_val_r >> rs2_val_r;
SLA: register[rd_addr_r] <= rs1_val_r <<< rs2_val_r;
SRA: register[rd_addr_r] <= rs1_val_r >>> rs2_val_r;
default: force_reset <= 1'b1;
endcase
end
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
// 代入系
A_TYPE: begin
// 代入系はどの命令でもpcをカウントアップする
register[PC_ADDR] <= register[PC_ADDR] + 1;
// 命令がMOVの時だけ実行
if (func_r == MOV) begin
// イミディエイトデータを使用する?
if (imm_r[32]) begin
register[rd_addr_r] <= imm_r[31:0];
end else begin
register[rd_addr_r] <= rs1_val_r;
end
end
else begin
force_reset <= 1'b1;
end
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
// 分岐系
F_TYPE: begin
// 命令に応じて処理実行
unique case (func_r)
EQ: begin
if (rs1_val_r == rs2_val_r)
register[PC_ADDR] <= register[PC_ADDR] + imm_r[31:0];
else
register[PC_ADDR] <= register[PC_ADDR] + 1;
end
NE: begin
if (rs1_val_r != rs2_val_r)
register[PC_ADDR] <= register[PC_ADDR] + imm_r[31:0];
else
register[PC_ADDR] <= register[PC_ADDR] + 1;
end
LT: begin
if (rs1_val_r < rs2_val_r)
register[PC_ADDR] <= register[PC_ADDR] + imm_r[31:0];
else
register[PC_ADDR] <= register[PC_ADDR] + 1;
end
GT: begin
if (rs1_val_r > rs2_val_r)
register[PC_ADDR] <= register[PC_ADDR] + imm_r[31:0];
else
register[PC_ADDR] <= register[PC_ADDR] + 1;
end
ELT: begin
if (rs1_val_r <= rs2_val_r)
register[PC_ADDR] <= register[PC_ADDR] + imm_r[31:0];
else
register[PC_ADDR] <= register[PC_ADDR] + 1;
end
EGT: begin
if (rs1_val_r >= rs2_val_r)
register[PC_ADDR] <= register[PC_ADDR] + imm_r[31:0];
else
register[PC_ADDR] <= register[PC_ADDR] + 1;
end
default: begin
force_reset <= 1'b1;
end
endcase
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
// ジャンプ系
J_TYPE: begin
// 命令がジャンプの時だけ実行
if (func_r == JMP) begin
// イミディエイトデータを使用する?
if (imm_r[32]) begin
register[PC_ADDR] <= imm_r[31:0];
end
else begin
register[PC_ADDR] <= rs1_val_r;
end
end
else begin
force_reset <= 1'b1;
end
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
// メモリ系
M_TYPE: begin
unique case (func_r)
// メモリ読み込み
RM: begin
unique case (ram_read_state)
// 待機
IDLE: begin
// 実行を指示
ram_read_state <= EXECUTE;
// 実行状態であることを送る
ram_read.valid <= 1'b1;
// マスク情報を送る
ram_read.mask <= mask_r;
// アドレス情報を送る
if (imm_r[32]) begin
// イミディエイトデータを使用する指定なら,それを送る
ram_read.address <= imm_r[31:0];
end
else begin
// 読み込みアドレスを送る
ram_read.address <= rs1_val_r;
end
end
// メモリ読み込み実行
EXECUTE: begin
// 読み込みが完了したなら
if (ram_read.ready) begin
// 待機状態に遷移
ram_read_state <= IDLE;
// 実行状態をオフ
ram_read.valid <= 1'b0;
// データを受け取る
register[rd_addr_r] <= ram_read.data;
// プログラムカウンタをインクリメント
register[PC_ADDR] <= register[PC_ADDR] + 1;
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
end
// その他
default: begin
force_reset <= 1'b1;
end
endcase
end
// メモリ書き込み
WM: begin
unique case(ram_write_state)
// 待機
IDLE: begin
// 実行を指示
ram_write_state <= EXECUTE;
// 実行状態であることを送る
ram_write.valid <= 1'b1;
// マスク情報を送る
ram_write.mask <= mask_r;
// アドレス情報を送る
if (imm_r[32]) begin
// イミディエイトデータを使用する指定なら,それを送る
ram_write.address <= imm_r[31:0];
end
else begin
// 書き込みアドレスを送る
ram_write.address <= rs1_val_r;
end
// データを送る
ram_write.data <= rs2_val_r;
end
// メモリ書き込み実行
EXECUTE: begin
// 書き込みが完了したなら
if (ram_write.ready) begin
// 待機状態に遷移
ram_write_state <= IDLE;
// 実行状態をオフ
ram_write.valid <= 1'b0;
// プログラムカウンタをインクリメント
register[PC_ADDR] <= register[PC_ADDR] + 1;
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
end
// その他
default: begin
force_reset <= 1'b1;
end
endcase
end
// バーストはオミット
// メモリ読み込み(バースト)
BRM: begin
force_reset <= 1'b1;
end
// メモリ書き込み(バースト)
BWM: begin
force_reset <= 1'b1;
end
default: begin
force_reset <= 1'b1;
end
endcase
end
// 標準入出力系
IO_TYPE: begin
unique case (func_r)
// 標準入力
SCAN: begin
unique case (stdin_state)
// 待機
IDLE: begin
// 実行を指示
stdin_state <= EXECUTE;
stdin_tready <= 1'b1;
end
// 実行
EXECUTE: begin
// データが送られてきているなら
if (stdin_tvalid) begin
register[rd_addr_r] <= stdin_tdata;
// 一文字ずつ読み込むため,これだけ読みこんだら終了する
stdin_state <= IDLE;
stdin_tready <= 1'b0;
// プログラムカウンタをインクリメント
register[PC_ADDR] <= register[PC_ADDR] + 1;
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
else begin
// 読み取り準備が整っていることを送る
stdin_tready <= 1'b1;
end
end
// その他
default: begin
force_reset <= 1'b1;
end
endcase
end
// 標準出力
PRINT: begin
unique case (stdout_state)
// 待機
IDLE: begin
// イミディエイトデータを使用するなら
if (imm_r[32]) begin
// データを送る
stdout_tdata <= imm_r[31:0];
end
// rs1のデータを使用するなら
else begin
stdout_tdata <= rs1_val_r;
end
// 実行を指示
stdout_tvalid <= 1'b1;
stdout_state <= EXECUTE;
end
// 実行
EXECUTE: begin
// データの送信に成功したなら
if (stdout_tready) begin
// 一文字ずつ書き込むため,これだけ書き込んだら終了する
stdout_state <= IDLE;
stdout_tvalid <= 1'b0;
// プログラムカウンタをインクリメント
register[PC_ADDR] <= register[PC_ADDR] + 1;
// フェッチに戻る
cpu_phase <= CPU_FETCH;
end
else begin
// 書き込み準備が終わっていることを送る
stdout_tvalid <= 1'b1;
end
end
// その他
default: begin
force_reset <= 1'b1;
end
endcase
end
default: begin
force_reset <= 1'b1;
end
endcase
end
default: begin
force_reset <= 1'b1;
end
endcase
end
endcase
end
end
endmodule
結果が一桁になる一桁同士の足し算を行う
いきなり足し算機の完成版を作るのはハードルが高いので,まず一桁同士の足し算機を作ります.
なおかつ,計算結果も一桁になる想定です.
後々拡張する予定なのでコメントアウトしているコードがありますが気にしないでください.
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer:
//
// Create Date: 2025/04/19 20:51:41
// Design Name:
// Module Name: rom_sv
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////
`include "rom.svh"
`include "machine.svh"
`include "register.svh"
module rom_sv (
// メモリデータ読み出し
rom_read_if.slave rom_read
);
// import文
import machine_p::*;
localparam integer ROM_SIZE = 35;
localparam integer STATE_ADDR = 6'h00;
localparam integer TDATA_ADDR = 6'h01; // 入力された文字をとりあえず置いておくところ
localparam integer TVALID_ON_ADDR = 6'h02;
localparam integer TREADY_ON_ADDR = 6'h03;
localparam integer STDIN_TVALID = 6'h04;
localparam integer PARAM1 = 6'h0f; // 足される数
localparam integer PARAM2 = 6'h05; // 足す数
localparam integer PARAM3 = 6'h06; // 合計数
localparam integer PLUS_CODE = 6'h07; // 文字「+」
localparam integer EQUAL_CODE = 6'h08; // 文字「=」
localparam integer ZERO_CODE = 6'h09; // 文字「0」
localparam integer NINE_CODE = 6'h0a;
localparam integer TMP_ADDR = 6'h0b; // 計算用の一時領域
localparam integer STATE1 = 6'h0c; // 足される数の入力
localparam integer STATE2 = 6'h0d; // 足す数の入力
localparam integer STATE3 = 6'h0e; // 合計の算出
localparam integer FIRST_COMMAND = 32'h0c; // 最初の命令
localparam integer STDIN_DATA_ADDR = 6'h31;
localparam integer STDIN_SIGNAL_ADDR = 6'h32;
localparam integer STDOUT_DATA_ADDR = 6'h33;
localparam integer STDOUT_SIGNAL_ADDR = 6'h34;
// キーボード読み取りプログラム
// まず,一桁同士の足し算を作る.計算結果も一桁とする.
machine_t machines[0:ROM_SIZE - 1] = {
// 各情報を保存
// ステート
mov(4'hf, 0, STATE_ADDR, {1'b1, 32'b0}),
mov(4'hf, 0, STATE1, {1'b1, 32'h0}),
mov(4'hf, 0, STATE2, {1'b1, 32'h1}),
mov(4'hf, 0, STATE3, {1'b1, 32'h2}),
// 文字「0」を保存
mov(4'hf, 0, ZERO_CODE, {1'b1, 32'h30}),
// 文字「+」を保存
mov(4'hf, 0, PLUS_CODE, {1'b1, 32'h2b}),
// 文字「=」を保存
mov(4'hf, 0, EQUAL_CODE, {1'b1, 32'h3d}),
// 各信号を保存しておく
// tvalidがonの状態
mov(4'hf, 0, TVALID_ON_ADDR, {1'b1, 32'h2}),
// treadyがonの状態 // 使ってない
mov(4'hf, 0, TREADY_ON_ADDR, {1'b1, 32'h1}),
// 変数を初期化
mov(4'hf, 0, PARAM1, {1'b1, 32'h0}),
mov(4'hf, 0, PARAM2, {1'b1, 32'h0}),
mov(4'hf, 0, PARAM3, {1'b1, 32'h0}),
// ステートが「合計の算出」なら,一文字読み取り処理をスキップ
eq(STATE_ADDR, STATE3, {1'b1, 32'h05}),
// 一文字読み取り
// 標準入力のtvalidを抽出
and_(STDIN_SIGNAL_ADDR, TVALID_ON_ADDR, STDIN_TVALID),
// キーボード入力の割り込みが行われているなら,以下の命令をスキップ
eq(TVALID_ON_ADDR, STDIN_TVALID, {1'b1, 32'h2}),
// 最初の命令に戻る
jmp(0, {1'b1, FIRST_COMMAND}),
// (キーボード入力の割り込みが行われているなら)標準入力から一文字読み込み,一時領域へ書き込む
scan(TDATA_ADDR),
// 足される数の入力
// ステートが「足される数の入力中」ではないなら,以下の命令を飛ばす
ne(STATE_ADDR, STATE1, {1'b1, 32'h06}),
// 入力された文字が「+」ではないなら,以下の命令を飛ばす
ne(TDATA_ADDR, PLUS_CODE, {1'b1, 32'h3}),
// ステートを「足す数の入力中」に変更
mov(4'hf, STATE2, STATE_ADDR, {1'b0, 32'h0}),
// // 最初の命令に戻る
// jmp(0, {1'b1, FIRST_COMMAND}),
// // (入力された文字が「+」ではないなら)「足される数」に保存されている値を十倍する
// // まず元の数値を1ビットシフト
// sll(PARAM1, 0, PARAM1, {1'b1, 32'h1}),
// // 1ビットシフトしたものをさらに2ビットシフト
// sll(PARAM1, 0, TMP_ADDR, {1'b1, 32'h2}),
// // 1ビットシフトしたものと3ビットシフトしたものを合計
// add(PARAM1, TMP_ADDR, PARAM1),
// // 今回入力された数字を「足される数」に足す
// add(PARAM1, TDATA_ADDR, PARAM1),
// 最初の命令に戻る
jmp(0, {1'b1, FIRST_COMMAND}),
// (入力された文字が「+」ではないなら)「0」の文字コードぶん引く
sub(PARAM1, ZERO_CODE, PARAM1),
// 入力された数字を「足される数」に保存する
sub(TDATA_ADDR, ZERO_CODE, PARAM1),
// 足す数の入力
// ステートが「足す数の入力中」ではないなら,以下の命令を飛ばす
ne(STATE_ADDR, STATE2, {1'b1, 32'h06}),
// 入力された文字が「=」ではないなら,以下の命令を飛ばす
ne(TDATA_ADDR, EQUAL_CODE, {1'b1, 32'h3}),
// ステートを「合計の算出」に変更
mov(4'hf, STATE3, STATE_ADDR, {1'b0, 32'h0}),
// 最初の命令に戻る
jmp(0, {1'b1, FIRST_COMMAND}),
// (入力された文字が「=」ではないなら)入力された数字を「足す数」に保存する
// 「0」の文字コード文引く
sub(TDATA_ADDR, ZERO_CODE, PARAM2),
// 最初の命令に戻る
jmp(0, {1'b1, FIRST_COMMAND}),
// 合計の算出
// ステートが「合計の算出」ではないなら,以下の命令を飛ばす
ne(STATE_ADDR, STATE3, {1'b1, 32'h04}),
// 合計を算出
add(PARAM1, PARAM2, PARAM3),
// 「0」の文字コードを足す
add(PARAM3, ZERO_CODE, PARAM3),
// 数字を出力
print(PARAM3, {1'b0, 32'h0}),
// ステータスを「足される数の入力中」にする
mov(4'hf, STATE1, STATE_ADDR, {1'b0, 32'h0}),
// 最初の命令に戻る
jmp(0, {1'b1, FIRST_COMMAND})
};
// メモリデータの読み出し
always_comb begin
if (rom_read.pc >= ROM_SIZE) begin
rom_read.machine = nop();
end else begin
rom_read.machine = machines[rom_read.pc];
end
end
endmodule
で,PS側のプログラムはこんな感じ.
Claude Codeに解説してもらってコメント入れてもらいました.
// 一桁と一桁の足し算を行う.
// 結果は一桁の数字になる.
//
// 【DMAによるPS-PL間通信の概要】
// PS(ARM)からPL(FPGA)へのデータ送信は以下の流れで行われる:
//
// [PS DDRメモリ(write_data)]
// ↓ DMA(MM2S)がDDRからデータを読み出す
// [AXI DMA]
// ↓ AXI Streamでカスタム CPU IP へ転送
// [PL: カスタムCPU (stdin_tdata)]
//
// PL(FPGA)からPS(ARM)へのデータ受信は逆の流れ:
//
// [PL: カスタムCPU (stdout_tdata)]
// ↓ AXI Streamで転送
// [AXI DMA]
// ↓ DMA(S2MM)がDDRへデータを書き込む
// [PS DDRメモリ(read_data)]
//
// CPUプログラム側からは「変数に書いた値がFPGAに届く / FPGAが書いた値が変数に入る」
// という形で見える.実際のデータ転送はDMAがバックグラウンドで行う.
#include <iostream>
#include <string>
extern "C" {
#include <pynq_api.h>
}
int main(void) {
char bit_path[] = "./bit/top_wrapper.bit";
// AXI DMAのベースアドレス (Vivado Address Editorで /axi_dma_0/S_AXI_LITE に割り当てたアドレス)
// PSはこのアドレスを通じてDMAの制御レジスタを読み書きし,転送を命令する
const int ADDR = 0x40400000;
const int BURST_SIZE = 100; // 一度に送れるのは100文字まで
std::string line = "";
// ビットストリームをFPGAに書き込む.これによりPL側のカスタムCPUが起動する
PYNQ_loadBitstream(bit_path);
// PS-PL間でDMAが直接アクセスできる共有DDRメモリ領域を確保する.
// 通常のmallocと異なり,DMAがアクセスできる物理アドレスが保証された領域になる.
// write_memory: PSが値を書き込み,DMAがPLへ送り出す領域 (PS→PL方向)
// read_memory: DMAがPLからの値を書き込み,PSが読み出す領域 (PL→PS方向)
PYNQ_SHARED_MEMORY write_memory, read_memory;
PYNQ_allocatedSharedMemory(&write_memory, sizeof(int) * BURST_SIZE, 1);
PYNQ_allocatedSharedMemory(&read_memory, sizeof(int) * BURST_SIZE, 1);
int *write_data = (int *)write_memory.pointer; // write_memoryをint配列として扱うポインタ
int *read_data = (int *)read_memory.pointer; // read_memoryをint配列として扱うポインタ
for (int i = 0; i < BURST_SIZE; i++) {
write_data[i] = 0;
read_data[i] = 0;
}
// DMAを初期化する.ADDRのレジスタをメモリマップし,DMAを使える状態にする
PYNQ_AXI_DMA dma;
PYNQ_openDMA(&dma, ADDR);
// メイン部分
{
// 計算式の入力
std::cout << "計算式を入力してください" << std::endl;
std::cin >> line;
// 入力された計算式を1文字ずつFPGAへ送信する
// FPGAのCPUは1文字ずつSCAN命令で受け取るため,1文字ごとに転送・完了待ちを繰り返す
for (int i = 0; i < line.size(); i++) {
// 送信したい文字コードをDDRメモリ(write_data)に書き込む
// FPGAのstdin_tdataは32bitなので,char→intでゼロ拡張して格納する
// 例: '1' → 0x00000031
write_data[0] = (int)line[i];
// DMAに対して「write_memoryの先頭からsizeof(int)バイト分をPLへ送れ」と命令する
// DMAはDDRからデータを読み出し,AXI StreamでFPGAのstdin_tdataへ転送する
PYNQ_writeDMA(&dma, &write_memory, 0, sizeof(int) * 1);
// FPGAがSCAN命令でデータを受け取り,DMA転送が完了するまで待機する
// 完了 = FPGAがtready=1にしてAXI Streamのハンドシェイクが成立したとき
PYNQ_waitForDMAComplete(&dma, AXI_DMA_WRITE);
}
// FPGAからの出力を受け取る
// DMAに「PLからsizeof(int)バイト受け取ってread_memoryに書け」と命令する
// FPGAがPRINT命令でstdout_tdataに値を出力するまでここで待機する
PYNQ_readDMA(&dma, &read_memory, 0, sizeof(int) * 1);
PYNQ_waitForDMAComplete(&dma, AXI_DMA_READ);
std::cout << std::hex << (char)read_data[0] << std::endl;
}
// 使用したリソースを解放する
PYNQ_closeDMA(&dma);
PYNQ_freeSharedMemory(&write_memory);
PYNQ_freeSharedMemory(&read_memory);
return 0;
}
これでうまく動きましたので,次は合計が二けたになる一桁同士の足し算を考えていきます.
合計が二けたになる一桁同士の足し算
ここでは計算結果を二けたとしていますが,将来的には任意の桁数でも動くようにしたいです.そのため,以下の処理が必要です.
- 足し算結果を10で割り,商と余りを求める
- 余りはメモリに記録しておく.また,商を新たな
PARAM3にする -
PARAM3の値が0になるまで繰り返す
そのために割り算命令を追加しました.割り算回路自体はVivadoのDivider Generatorを使う想定です.
割り算回路はこの記事の一番上で示したalu_sv.svの内容を見てください.ブロックデザインは以下です.
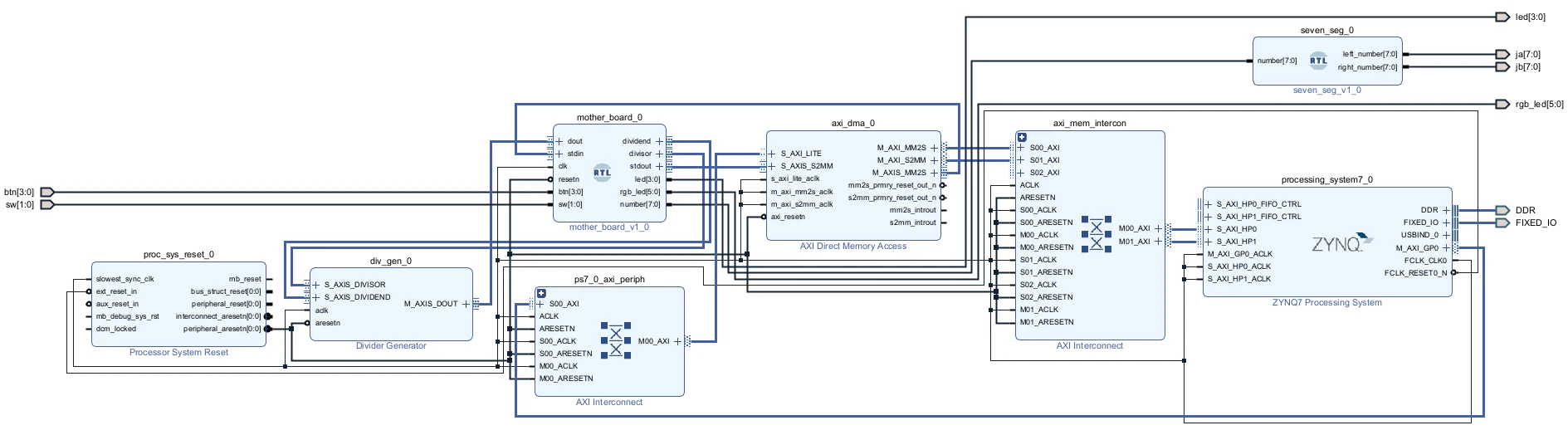
PL側のプログラムは以下のようになりました.
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer:
//
// Create Date: 2025/04/19 20:51:41
// Design Name:
// Module Name: rom_sv
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////
`include "rom.svh"
`include "machine.svh"
`include "register.svh"
module rom_sv (
// メモリデータ読み出し
rom_read_if.slave rom_read
);
// import文
import machine_p::*;
localparam integer ROM_SIZE = 50;
// ===== レジスタアドレス =====
localparam integer STATE_ADDR = 6'h00; // 現在のステート
localparam integer TDATA_ADDR = 6'h01; // 入力された文字の一時保存
localparam integer TVALID_ON_ADDR = 6'h02; // tvalidがonの状態
localparam integer TREADY_ON_ADDR = 6'h03; // treadyがonの状態 (未使用)
localparam integer STDIN_TVALID = 6'h04; // 抽出したstdinのtvalid
localparam integer TEN = 6'h05; // 数値「10」(除算用)
localparam integer DIGIT_ADDR = 6'h06; // 桁データのRAMアドレス (ループ変数)
localparam integer PLUS_CODE = 6'h07; // 文字「+」
localparam integer EQUAL_CODE = 6'h08; // 文字「=」
localparam integer ZERO_CODE = 6'h09; // 文字「0」
localparam integer WORK1 = 6'h0a; // 計算用ワークレジスタ1
localparam integer WORK2 = 6'h0b; // 計算用ワークレジスタ2
localparam integer STATE1 = 6'h0c; // 足される数の入力
localparam integer STATE2 = 6'h0d; // 足す数の入力
localparam integer STATE3 = 6'h0e; // 合計の算出
localparam integer DIGITS_BASE_REG = 6'h0f; // 桁データの先頭RAMアドレス(ループ2の終了判定用)
localparam integer STDIN_DATA_ADDR = 6'h31;
localparam integer STDIN_SIGNAL_ADDR = 6'h32;
localparam integer STDOUT_DATA_ADDR = 6'h33;
localparam integer STDOUT_SIGNAL_ADDR = 6'h34;
// ===== 定数 =====
// プログラムアドレス
localparam integer FIRST_COMMAND = 32'h0e; // 最初の命令
localparam integer LOOP1_START = 32'h25; // 桁抽出ループの先頭
localparam integer LOOP2_START = 32'h2a; // 出力ループの先頭
// RAMアドレス
localparam integer PARAM1_MEM = 32'h0; // 足される数
localparam integer PARAM2_MEM = 32'h4; // 足す数
localparam integer PARAM3_MEM = 32'h8; // 合計 (現在未使用)
localparam integer DIGITS_BASE = 32'hc; // 桁データの先頭アドレス
// キーボード読み取りプログラム
machine_t machines[0:ROM_SIZE - 1] = {
// ===== 初期化 =====
// ステート
mov(4'hf, 0, STATE_ADDR, {1'b1, 32'b0}),
mov(4'hf, 0, STATE1, {1'b1, 32'h0}),
mov(4'hf, 0, STATE2, {1'b1, 32'h1}),
mov(4'hf, 0, STATE3, {1'b1, 32'h2}),
// 文字コード
mov(4'hf, 0, ZERO_CODE, {1'b1, 32'h30}),
mov(4'hf, 0, PLUS_CODE, {1'b1, 32'h2b}),
mov(4'hf, 0, EQUAL_CODE, {1'b1, 32'h3d}),
// 各信号を保存しておく
mov(4'hf, 0, TVALID_ON_ADDR, {1'b1, 32'h2}),
mov(4'hf, 0, TREADY_ON_ADDR, {1'b1, 32'h1}), // 使ってない
// ワークレジスタを初期化
mov(4'hf, 0, WORK1, {1'b1, 32'h0}),
mov(4'hf, 0, WORK2, {1'b1, 32'h0}),
// 除算用定数を保存
mov(4'hf, 0, TEN, {1'b1, 32'd10}),
// ループ変数の初期値を設定
mov(4'hf, 0, DIGIT_ADDR, {1'b1, DIGITS_BASE}),
mov(4'hf, 0, DIGITS_BASE_REG, {1'b1, DIGITS_BASE}),
// ===== メインループ (FIRST_COMMAND) =====
// ステートが「合計の算出」なら,一文字読み取り処理をスキップ (→STATE1チェックへ)
eq(STATE_ADDR, STATE3, {1'b1, 32'h05}),
// 一文字読み取り
// 標準入力のtvalidを抽出
and_(STDIN_SIGNAL_ADDR, TVALID_ON_ADDR, STDIN_TVALID),
// tvalidがonなら次のjmpをスキップしてscanへ,offなら先頭に戻る
eq(TVALID_ON_ADDR, STDIN_TVALID, {1'b1, 32'h2}),
jmp(0, {1'b1, FIRST_COMMAND}),
scan(TDATA_ADDR),
// ===== 足される数の入力 (STATE1) =====
// ステートがSTATE1でないなら飛ばす (→STATE2チェックへ)
ne(STATE_ADDR, STATE1, {1'b1, 32'h06}),
// 入力された文字が「+」でないなら飛ばす (→PARAM1保存へ)
ne(TDATA_ADDR, PLUS_CODE, {1'b1, 32'h3}),
// ステートを「足す数の入力中」に変更
mov(4'hf, STATE2, STATE_ADDR, {1'b0, 32'h0}),
jmp(0, {1'b1, FIRST_COMMAND}),
// // (入力された文字が「+」ではないなら)「足される数」に保存されている値を十倍する
// // まず元の数値を1ビットシフト
// sll(PARAM1, 0, PARAM1, {1'b1, 32'h1}),
// // 1ビットシフトしたものをさらに2ビットシフト
// sll(PARAM1, 0, TMP_ADDR, {1'b1, 32'h2}),
// // 1ビットシフトしたものと3ビットシフトしたものを合計
// add(PARAM1, TMP_ADDR, PARAM1),
// // 今回入力された数字を「足される数」に足す
// add(PARAM1, TDATA_ADDR, PARAM1),
// 入力された数字をRAMに保存
sub(TDATA_ADDR, ZERO_CODE, WORK1),
wm(4'hf, 0, WORK1, {1'b1, PARAM1_MEM}),
// (fall-through: STATE!=STATE2なのでSTATE2チェックをスキップしSTATE3チェックへ)
// ===== 足す数の入力 (STATE2) =====
// ステートがSTATE2でないなら飛ばす (→STATE3チェックへ)
ne(STATE_ADDR, STATE2, {1'b1, 32'h07}),
// 入力された文字が「=」でないなら飛ばす (→PARAM2保存へ)
ne(TDATA_ADDR, EQUAL_CODE, {1'b1, 32'h3}),
// ステートを「合計の算出」に変更
mov(4'hf, STATE3, STATE_ADDR, {1'b0, 32'h0}),
jmp(0, {1'b1, FIRST_COMMAND}),
// 入力された数字をRAMに保存
sub(TDATA_ADDR, ZERO_CODE, WORK1),
wm(4'hf, 0, WORK1, {1'b1, PARAM2_MEM}),
jmp(0, {1'b1, FIRST_COMMAND}),
// ===== 合計の算出 (STATE3) =====
// ステートがSTATE3でないなら飛ばす (→リセットへ)
ne(STATE_ADDR, STATE3, {1'b1, 32'h10}),
// PARAM1, PARAM2をRAMから読み込む
rm(4'hf, 0, WORK1, {1'b1, PARAM1_MEM}),
rm(4'hf, 0, WORK2, {1'b1, PARAM2_MEM}),
// 合計を算出
add(WORK1, WORK2, WORK1),
// DIGIT_ADDRをループ先頭にリセット
mov(4'hf, 0, DIGIT_ADDR, {1'b1, DIGITS_BASE}),
// ===== ループ1: 各桁をRAMに積む (LOOP1_START) =====
// WORK1 ÷ 10 → 商=WORK1, 余り=WORK2
div(WORK1, TEN, WORK1, {1'b1, WORK2}),
// 余り(今の桁)をRAM[DIGIT_ADDR]に保存
wm(4'hf, DIGIT_ADDR, WORK2, {1'b0, 32'h0}),
add(DIGIT_ADDR, STATE2, DIGIT_ADDR), // DIGIT_ADDR++
// 商が0ならループ終了(→ループ2へ),そうでなければループ先頭へ
eq(WORK1, STATE1, {1'b1, 32'h2}),
jmp(0, {1'b1, LOOP1_START}),
// ===== ループ2: 逆順に出力 (LOOP2_START) =====
sub(DIGIT_ADDR, STATE2, DIGIT_ADDR), // DIGIT_ADDR--
// RAM[DIGIT_ADDR]から桁を読み込む
rm(4'hf, DIGIT_ADDR, WORK1, {1'b0, 32'h0}),
add(WORK1, ZERO_CODE, WORK1), // 文字コードに変換
print(WORK1, {1'b0, 32'h0}),
// DIGIT_ADDRが先頭に戻ったらループ終了(→リセットへ),そうでなければループ先頭へ
eq(DIGIT_ADDR, DIGITS_BASE_REG, {1'b1, 32'h2}),
jmp(0, {1'b1, LOOP2_START}),
// ステートをリセット
mov(4'hf, STATE1, STATE_ADDR, {1'b0, 32'h0}),
// 最初の命令に戻る
jmp(0, {1'b1, FIRST_COMMAND})
};
// メモリデータの読み出し
always_comb begin
if (rom_read.pc >= ROM_SIZE) begin
rom_read.machine = nop();
end else begin
rom_read.machine = machines[rom_read.pc];
end
end
endmodule
PS側のプログラムは以下.
// 一桁と一桁の足し算を行う.
// 結果は任意の桁数になりうる(例: 5+6=11).
// 入力は「数値1+数値2=」の形式で1文字ずつFPGAへ送信し,
// 出力はFPGAが出力しなくなるまで(デッドロックするまで)1文字ずつ受け取る.
//
// 【DMAによるPS-PL間通信の概要】
// PS(ARM)からPL(FPGA)へのデータ送信は以下の流れで行われる:
//
// [PS DDRメモリ(write_data)]
// ↓ DMA(MM2S)がDDRからデータを読み出す
// [AXI DMA]
// ↓ AXI Streamでカスタム CPU IP へ転送
// [PL: カスタムCPU (stdin_tdata)]
//
// PL(FPGA)からPS(ARM)へのデータ受信は逆の流れ:
//
// [PL: カスタムCPU (stdout_tdata)]
// ↓ AXI Streamで転送
// [AXI DMA]
// ↓ DMA(S2MM)がDDRへデータを書き込む
// [PS DDRメモリ(read_data)]
//
// CPUプログラム側からは「変数に書いた値がFPGAに届く / FPGAが書いた値が変数に入る」
// という形で見える.実際のデータ転送はDMAがバックグラウンドで行う.
#include <iostream>
#include <string>
extern "C" {
#include <pynq_api.h>
}
int main(void) {
char bit_path[] = "./bit/top_wrapper.bit";
// AXI DMAのベースアドレス (Vivado Address Editorで /axi_dma_0/S_AXI_LITE に割り当てたアドレス)
// PSはこのアドレスを通じてDMAの制御レジスタを読み書きし,転送を命令する
const int ADDR = 0x40400000;
const int BURST_SIZE = 100; // 一度に送れるのは100文字まで
std::string line = "";
// ビットストリームをFPGAに書き込む.これによりPL側のカスタムCPUが起動する
PYNQ_loadBitstream(bit_path);
// PS-PL間でDMAが直接アクセスできる共有DDRメモリ領域を確保する.
// 通常のmallocと異なり,DMAがアクセスできる物理アドレスが保証された領域になる.
// write_memory: PSが値を書き込み,DMAがPLへ送り出す領域 (PS→PL方向)
// read_memory: DMAがPLからの値を書き込み,PSが読み出す領域 (PL→PS方向)
PYNQ_SHARED_MEMORY write_memory, read_memory;
PYNQ_allocatedSharedMemory(&write_memory, sizeof(int) * BURST_SIZE, 1);
PYNQ_allocatedSharedMemory(&read_memory, sizeof(int) * BURST_SIZE, 1);
int *write_data = (int *)write_memory.pointer; // write_memoryをint配列として扱うポインタ
int *read_data = (int *)read_memory.pointer; // read_memoryをint配列として扱うポインタ
for (int i = 0; i < BURST_SIZE; i++) {
write_data[i] = 0;
read_data[i] = 0;
}
// DMAを初期化する.ADDRのレジスタをメモリマップし,DMAを使える状態にする
PYNQ_AXI_DMA dma;
PYNQ_openDMA(&dma, ADDR);
// メイン部分
{
// 計算式の入力
std::cout << "計算式を入力してください" << std::endl;
std::cin >> line;
// 入力された計算式を1文字ずつFPGAへ送信する
// FPGAのCPUは1文字ずつSCAN命令で受け取るため,1文字ごとに転送・完了待ちを繰り返す
for (int i = 0; i < line.size(); i++) {
// 送信したい文字コードをDDRメモリ(write_data)に書き込む
// FPGAのstdin_tdataは32bitなので,char→intでゼロ拡張して格納する
// 例: '1' → 0x00000031
write_data[0] = (int)line[i];
// DMAに対して「write_memoryの先頭からsizeof(int)バイト分をPLへ送れ」と命令する
// DMAはDDRからデータを読み出し,AXI StreamでFPGAのstdin_tdataへ転送する
PYNQ_writeDMA(&dma, &write_memory, 0, sizeof(int) * 1);
// FPGAがSCAN命令でデータを受け取り,DMA転送が完了するまで待機する
// 完了 = FPGAがtready=1にしてAXI Streamのハンドシェイクが成立したとき
PYNQ_waitForDMAComplete(&dma, AXI_DMA_WRITE);
}
// FPGAからの出力を受け取る(FPGAが出力しなくなるとデッドロック)
while (true) {
PYNQ_readDMA(&dma, &read_memory, 0, sizeof(int) * 1);
PYNQ_waitForDMAComplete(&dma, AXI_DMA_READ);
std::cout << (char)read_data[0] << std::flush;
}
}
// 使用したリソースを解放する
PYNQ_closeDMA(&dma);
PYNQ_freeSharedMemory(&write_memory);
PYNQ_freeSharedMemory(&read_memory);
return 0;
}
足す数と足される数が二けた以上になる足し算
まず,mul命令が必要ですね.これは冒頭のalu_sv.svを見てください.
といっても,Verilogの*を使っただけなんですけど.
PL側のプログラムは以下.
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer:
//
// Create Date: 2025/04/19 20:51:41
// Design Name:
// Module Name: rom_sv
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////
`include "rom.svh"
`include "machine.svh"
`include "register.svh"
module rom_sv (
// メモリデータ読み出し
rom_read_if.slave rom_read
);
// import文
import machine_p::*;
localparam integer ROM_SIZE = 62;
// ===== レジスタアドレス =====
localparam integer STATE_ADDR = 6'h00; // 現在のステート
localparam integer TDATA_ADDR = 6'h01; // 入力された文字の一時保存
localparam integer TVALID_ON_ADDR = 6'h02; // tvalidがonの状態
localparam integer TREADY_ON_ADDR = 6'h03; // treadyがonの状態 (未使用)
localparam integer STDIN_TVALID = 6'h04; // 抽出したstdinのtvalid
localparam integer TEN = 6'h05; // 数値「10」(除算用)
localparam integer DIGIT_ADDR = 6'h06; // 桁データのRAMアドレス (ループ変数)
localparam integer PLUS_CODE = 6'h07; // 文字「+」
localparam integer EQUAL_CODE = 6'h08; // 文字「=」
localparam integer ZERO_CODE = 6'h09; // 文字「0」
localparam integer WORK1 = 6'h0a; // 計算用ワークレジスタ1
localparam integer WORK2 = 6'h0b; // 計算用ワークレジスタ2
localparam integer STATE1 = 6'h0c; // 足される数の入力
localparam integer STATE2 = 6'h0d; // 足す数の入力
localparam integer STATE3 = 6'h0e; // 合計の算出
localparam integer DIGITS_BASE_REG = 6'h0f; // 桁データの先頭RAMアドレス(ループ2の終了判定用)
localparam integer STDIN_DATA_ADDR = 6'h31;
localparam integer STDIN_SIGNAL_ADDR = 6'h32;
localparam integer STDOUT_DATA_ADDR = 6'h33;
localparam integer STDOUT_SIGNAL_ADDR = 6'h34;
// ===== 定数 =====
// プログラムアドレス
localparam integer FIRST_COMMAND = 32'h10; // 最初の命令
localparam integer LOOP1_START = 32'h2e; // 桁抽出ループの先頭
localparam integer LOOP2_START = 32'h33; // 出力ループの先頭
// RAMアドレス
localparam integer PARAM1_MEM = 32'h0; // 足される数
localparam integer PARAM2_MEM = 32'h4; // 足す数
localparam integer PARAM3_MEM = 32'h8; // 合計 (現在未使用)
localparam integer DIGITS_BASE = 32'hc; // 桁データの先頭アドレス
// キーボード読み取りプログラム
machine_t machines[0:ROM_SIZE - 1] = {
// ===== 初期化 =====
// ステート
mov(4'hf, 0, STATE_ADDR, {1'b1, 32'b0}),
mov(4'hf, 0, STATE1, {1'b1, 32'h0}),
mov(4'hf, 0, STATE2, {1'b1, 32'h1}),
mov(4'hf, 0, STATE3, {1'b1, 32'h2}),
// 文字コード
mov(4'hf, 0, ZERO_CODE, {1'b1, 32'h30}),
mov(4'hf, 0, PLUS_CODE, {1'b1, 32'h2b}),
mov(4'hf, 0, EQUAL_CODE, {1'b1, 32'h3d}),
// 各信号を保存しておく
mov(4'hf, 0, TVALID_ON_ADDR, {1'b1, 32'h2}),
mov(4'hf, 0, TREADY_ON_ADDR, {1'b1, 32'h1}), // 使ってない
// ワークレジスタを初期化
mov(4'hf, 0, WORK1, {1'b1, 32'h0}),
mov(4'hf, 0, WORK2, {1'b1, 32'h0}),
// 除算用定数を保存
mov(4'hf, 0, TEN, {1'b1, 32'd10}),
// ループ変数の初期値を設定
mov(4'hf, 0, DIGIT_ADDR, {1'b1, DIGITS_BASE}),
mov(4'hf, 0, DIGITS_BASE_REG, {1'b1, DIGITS_BASE}),
// PARAM1, PARAM2 をRAM上で0に初期化 (WORK1=0 を利用)
wm(4'hf, 0, WORK1, {1'b1, PARAM1_MEM}),
wm(4'hf, 0, WORK1, {1'b1, PARAM2_MEM}),
// ===== メインループ (FIRST_COMMAND) =====
// ステートが「合計の算出」なら,一文字読み取り処理をスキップ (→STATE1チェックへ)
eq(STATE_ADDR, STATE3, {1'b1, 32'h05}),
// 一文字読み取り
// 標準入力のtvalidを抽出
and_(STDIN_SIGNAL_ADDR, TVALID_ON_ADDR, STDIN_TVALID),
// tvalidがonなら次のjmpをスキップしてscanへ,offなら先頭に戻る
eq(TVALID_ON_ADDR, STDIN_TVALID, {1'b1, 32'h2}),
jmp(0, {1'b1, FIRST_COMMAND}),
scan(TDATA_ADDR),
// ===== 足される数の入力 (STATE1) =====
// ステートがSTATE1でないなら飛ばす (→STATE2チェックへ)
ne(STATE_ADDR, STATE1, {1'b1, 32'h0a}),
// 入力された文字が「+」でないなら飛ばす (→PARAM1更新へ)
ne(TDATA_ADDR, PLUS_CODE, {1'b1, 32'h3}),
// ステートを「足す数の入力中」に変更
mov(4'hf, STATE2, STATE_ADDR, {1'b0, 32'h0}),
jmp(0, {1'b1, FIRST_COMMAND}),
// PARAM1 = PARAM1 × 10 + 入力桁
rm(4'hf, 0, WORK1, {1'b1, PARAM1_MEM}),
mul(WORK1, TEN, WORK1),
sub(TDATA_ADDR, ZERO_CODE, WORK2),
add(WORK1, WORK2, WORK1),
wm(4'hf, 0, WORK1, {1'b1, PARAM1_MEM}),
jmp(0, {1'b1, FIRST_COMMAND}),
// ===== 足す数の入力 (STATE2) =====
// ステートがSTATE2でないなら飛ばす (→STATE3チェックへ)
ne(STATE_ADDR, STATE2, {1'b1, 32'h0a}),
// 入力された文字が「=」でないなら飛ばす (→PARAM2更新へ)
ne(TDATA_ADDR, EQUAL_CODE, {1'b1, 32'h3}),
// ステートを「合計の算出」に変更
mov(4'hf, STATE3, STATE_ADDR, {1'b0, 32'h0}),
jmp(0, {1'b1, FIRST_COMMAND}),
// PARAM2 = PARAM2 × 10 + 入力桁
rm(4'hf, 0, WORK1, {1'b1, PARAM2_MEM}),
mul(WORK1, TEN, WORK1),
sub(TDATA_ADDR, ZERO_CODE, WORK2),
add(WORK1, WORK2, WORK1),
wm(4'hf, 0, WORK1, {1'b1, PARAM2_MEM}),
jmp(0, {1'b1, FIRST_COMMAND}),
// ===== 合計の算出 (STATE3) =====
// ステートがSTATE3でないなら飛ばす (→リセットへ)
ne(STATE_ADDR, STATE3, {1'b1, 32'h10}),
// PARAM1, PARAM2をRAMから読み込む
rm(4'hf, 0, WORK1, {1'b1, PARAM1_MEM}),
rm(4'hf, 0, WORK2, {1'b1, PARAM2_MEM}),
// 合計を算出
add(WORK1, WORK2, WORK1),
// DIGIT_ADDRをループ先頭にリセット
mov(4'hf, 0, DIGIT_ADDR, {1'b1, DIGITS_BASE}),
// ===== ループ1: 各桁をRAMに積む (LOOP1_START) =====
// WORK1 ÷ 10 → 商=WORK1, 余り=WORK2
div(WORK1, TEN, WORK1, {1'b1, WORK2}),
// 余り(今の桁)をRAM[DIGIT_ADDR]に保存
wm(4'hf, DIGIT_ADDR, WORK2, {1'b0, 32'h0}),
add(DIGIT_ADDR, STATE2, DIGIT_ADDR), // DIGIT_ADDR++
// 商が0ならループ終了(→ループ2へ),そうでなければループ先頭へ
eq(WORK1, STATE1, {1'b1, 32'h2}),
jmp(0, {1'b1, LOOP1_START}),
// ===== ループ2: 逆順に出力 (LOOP2_START) =====
sub(DIGIT_ADDR, STATE2, DIGIT_ADDR), // DIGIT_ADDR--
// RAM[DIGIT_ADDR]から桁を読み込む
rm(4'hf, DIGIT_ADDR, WORK1, {1'b0, 32'h0}),
add(WORK1, ZERO_CODE, WORK1), // 文字コードに変換
print(WORK1, {1'b0, 32'h0}),
// DIGIT_ADDRが先頭に戻ったらループ終了(→リセットへ),そうでなければループ先頭へ
eq(DIGIT_ADDR, DIGITS_BASE_REG, {1'b1, 32'h2}),
jmp(0, {1'b1, LOOP2_START}),
// ===== リセット =====
mov(4'hf, STATE1, STATE_ADDR, {1'b0, 32'h0}),
mov(4'hf, 0, WORK1, {1'b1, 32'h0}),
wm(4'hf, 0, WORK1, {1'b1, PARAM1_MEM}), // PARAM1 = 0
wm(4'hf, 0, WORK1, {1'b1, PARAM2_MEM}), // PARAM2 = 0
jmp(0, {1'b1, FIRST_COMMAND})
};
// メモリデータの読み出し
always_comb begin
if (rom_read.pc >= ROM_SIZE) begin
rom_read.machine = nop();
end else begin
rom_read.machine = machines[rom_read.pc];
end
end
endmodule
PS側のプログラムは変更なし.
実行結果
こんな感じです.
今後の展望
Claude Codeに協力してもらっていたら思っていた以上に爆速で進んでしまったので,次のことは何も考えていません.
とりあえず残件としては以下の通りになるので,このどれかをやる形になりますかね.
- キーボード操作を受け付けて,出力はUARTで出すようにする(PSの力を借りずに単体で動くようにする)
- 足し算以外にも四則演算は全部できるようにする
- アセンブラとコンパイラを作る
余談
初めて知ったのですが,Vivado標準のエディタではなく任意のエディタを使用する設定方法があるそうです.
以下,Claude Codeの出力の一部.
Tools → Settings → Text Editor → Current Editor → Custom Editor を選択し、以下を設定:
Executable: C:/Users/<ユーザー名>/AppData/Local/Programs/Microsoft VS Code/Code.exe
Arguments: [file name] --goto [file name]:[line number]
いやーClaude Codeって凄いですね.何でも知ってますね.