初めに
この記事は2021年から2022年にかけて開催された「PetFinder.my - Pawpularity Contest」の内容を振り返るために書いています。開始1か月後から参加し、私の結果は、114 / 3537 (Solo silver medal, Leaderboard) でした。
Kaggle に コード を公開していますので、ご興味のある方は是非。
PetFinderコンペについて
概要
2020年にも開催されたPetFinderコンペです。今年のお題は PetFinder.my にて掲載されている犬 or 猫の写真のページビュー(統計処理あり)を当てることでした。コンペではページビューのことを「Pawpularity」と呼んでいました。
Petfiner.my には捨てられた犬や猫の写真が掲載されています。Pawpularity を正確に予測するモデルを構築することによって、どのような写真を撮影すればクリック数が多くなるのか/少なくなるのかが分かるようになります。これにより、犬や猫の里親が早く見つかることに貢献できます。ちなみに、前回コンペは、里親が見つかるまでの早さを直接的に予測するコンペでした。
データと評価方法
与えられたデータは、画像データ(9,912枚)と、CSVデータです。今回も Code competition であり、テストデータは数枚だけ提供されている状況でした。しかし、今回のテストデータは完全なノイズ画像/ランダムな数値の CSV となっていたため、テストデータに関する情報は一切与えられていませんでした。Metrics は RMSE でした。
以下にデータの詳細を記載します。
- 画像データ
犬と猫の画像データです。1枚の画像の中に複数の犬/猫が写っているケースや、文字情報(性別、年齢等)が記載されているケース等がありました。全てのデータを見たわけではないですが、犬か猫のどちらかが写っていると思われます。 - CSVデータ
各画像データに対するメタデータです。メタデータは12列あり、目が写っているか、写真がぼやけているか等の項目に対して 0 or 1 の値が入力されていました。1 が該当を意味します。最後の13列目が Pawpularity です。これは、0~100 の値を取ります。
提出したアプローチ
最終的には、Pseudo Label による Semi-Supervised Learning を実施したモデル + 通常の手法で学習を実施したモデル、計7モデルのアンサンブルを提出しました。Pipeline は以下の通りです。
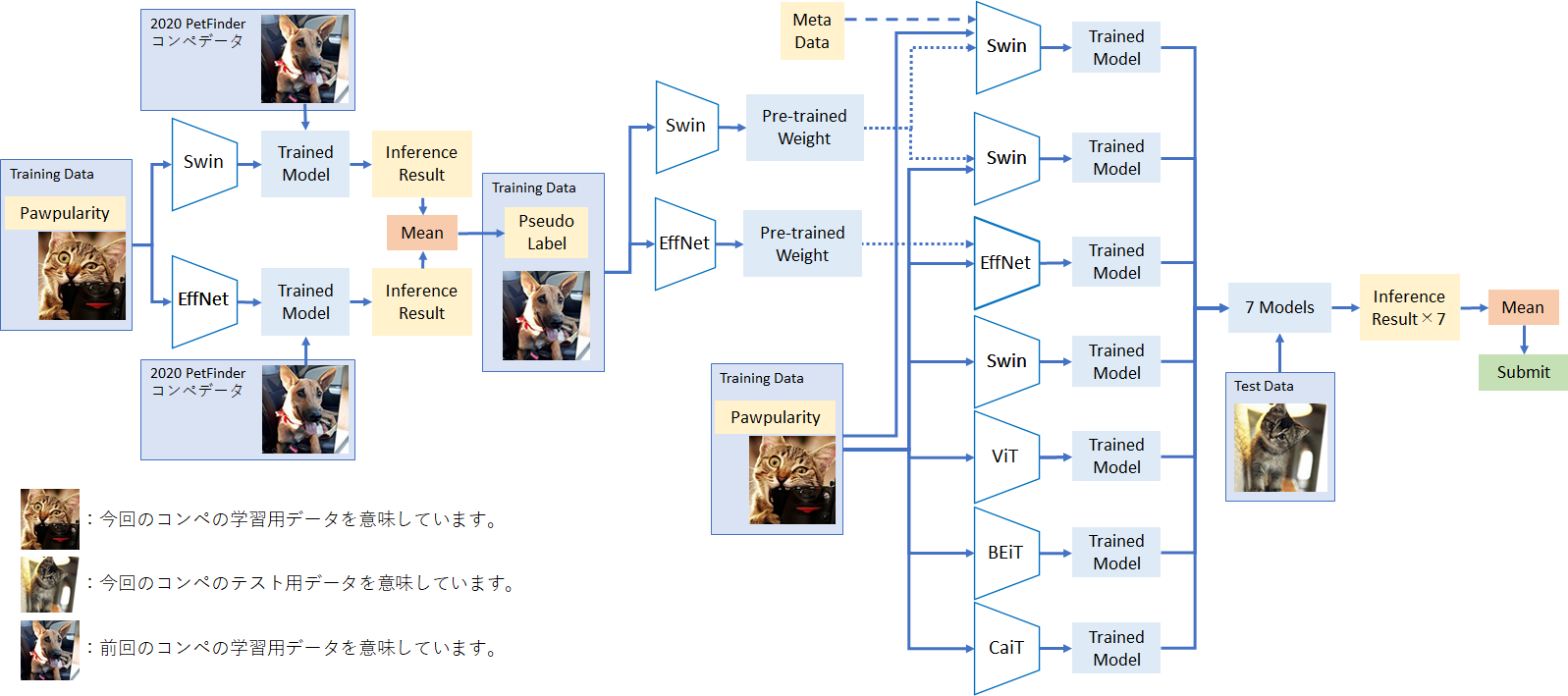
図中に出てくるモデルの正式名称及び timm での設定名称(利用したPre-trained model)は以下の通りです。上図の中央上に出てくる「Pre-trained weight」を入力している3モデル以外は、timm の Pre-trained weight を利用しています。これらのモデルは timm のサイトに掲載されている 精度表 を基に、Kaggle の GPU 環境に乗るアルゴリズムを選定しました。アルゴリズムの詳細は今回の記事では割愛します。
- Swin: Swin Transformer, swin_large_patch4_window7_224_in22k / swin_large_patch4_window7_224 , paper
- EffNet: EfficientNet, tf_efficientnet_b5_ns, paper
- ViT: Vision Transformer, vit_large_patch16_224, paper
- BEiT: BERT Pre-Training of Image Transformers, beit_base_patch16_384 , paper
- CaiT: Class-Attention in Image Transformers, cait_s24_384, paper
以下で詳細を説明する Semi-Supervised Learning 以外の学習は、KFold = 4 で実施しています。また、全ての推論は TTA1 = 2 で実施しています。そのため、実際の推論は各モデル 4 * 2 = 8 推論している計算です。
Transformer 系のアルゴリズムは、画像の入力サイズが固定されているため、timm の Weight の名称に付いている画像サイズを利用しています(例:swin_large_patch4_window7_224 は、画像サイズ 224)。EfficientNet は画像サイズ 512 で学習しています。
次の章からパイプラインの詳細及び Tips を書いていきます。
詳細
Semi-Supervised Learning
2020年に開催された PetFinder コンペがあったため、過去データを使って Pseudo Label を作成しました。作成手順は色々あるようですが、基本的には、まずは現コンペのデータで1つ以上のモデルを学習させることから始めます。次に、正解ラベルを保有していない別データに対して推論を行い、疑似ラベル(Pseudo Label)を取得します。
クラス分類系のタスクであれば、出力が確率になっているため、例えば、別データに対して推論した結果、確率 0.9 以上のデータを採用する、といったように、比較的推論結果が合っていると思われるデータを利用することが出来ます。しかし、今回の出力は、0~100 の値をとる連続値データであったため、この方法が使えません2。そのため、こちら の TensorFlow Speech Recognition Challenge 3rd place solution を参考に、Semi-Supervised Learning を実施しました。Discussion の中で2つの方法が紹介されています。1つ目は、学習データとして「100% of training data + 20%-35% of test data selected per epoch」を利用する方法、2つ目は「100% of test data」を利用する方法です。どちらも試した結果、精度向上が出来た2つ目の方法を採用しました。
Pipeline の図を見てわかるよう、Semi-Supervised Learning を実施したのは、Swin と EffNet だけです。この2つのモデルは精度向上が出来たのですが、例えば、BEiT を同じ手順で学習させると、通常の学習手法(現コンペのデータで普通に学習)より、精度が悪化しました。ViT、CaiT で試す時間はなかったのですが、こちらも同じ傾向になる可能性があったため、最終的には Swin と EffNet でのみ Semi-Supervised Learning を実施しました。
Swin Transformer + Image + Meta data
Semi-Supervised Learning で学習した Pre-Trained weight をベースに、Meta data を加えて Fine-tuning を実施しました。アーキテクチャは下図の通り大きく2パターンを考えました。ただ、パターン1だと画像自体に改良を行うため、学習した表現が壊れてしまう恐れがありました。そのため、パターン2を採用し、低めの学習率で数エポックだけ学習を実施しました。Meta data との結合部分は、結合だけでなく足し算や掛け算等でもOKです。色々試した結果、精度が良かった足し算を採用しました。
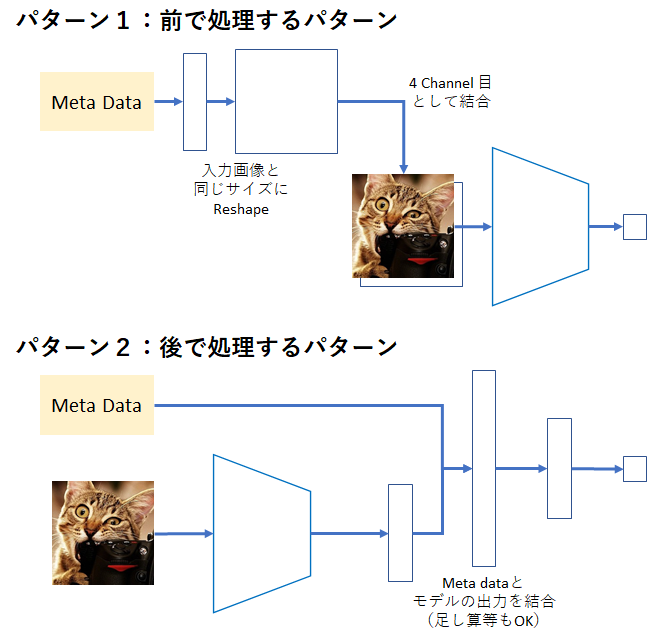
ちなみに、パターン1と2の両方実施するのもありです。Semi-Supervised Learning ではなく、通常の Pre-trained weight を使って学習する場合は、両方実施したケースが一番精度が高かったです。
アンサンブル
今回のコンペで精度向上に繋がった一番の要素は、色々な種類のモデルをアンサンブルすることだったと思います。多くの人が、多種多様なモデルをアンサンブルしていました。私もコンペ序盤にアンサンブルで精度が上がることに気付き、Semi-Supervised Learning の実装を一通り終えた後は、アンサンブル用のモデルを作成していました。
今回のコンペでは、アンサンブル手法に単純な平均を利用しました。他には 重み付き平均、Stacking 等、アンサンブル手法にも色々種類があります。私も Stacking は実装して、最終提出の2枠に入れた(CV Best)のですが、過学習していたようでスコアが非常に低かったです。銀メダルが取れたのは、もう一つの Public Leaderboard Best でした。
Tips
Pytorch vs FastAI
今回のコンペでは、FastAI を利用している人が多数いました。私は、コンペ序盤は Pytorch で実装した学習スクリプトを利用して、実験を繰り返していました。その後(約1カ月後)、Public Notebook/Discussion を一通り確認したところ、FastAI の部分以外は同じような実装をしているにも関わらず、精度が高い、という Notebook が散見されました。そこで、Pytorch の実装を全て FastAI に変えて学習したところ、精度改善に繋がりました。
FastAI には「lr_find」「fit_one_cycle」という強力な手法が提供されています。ir_find は、学習率と Loss の関係性を Plot してくれるため、良い精度に到達する学習率の目星をつけることが出来ます。また、fit_one_cycle は、学習時に学習率を上下させることによって、鞍点(Saddle point)に落ちにくくすることが可能な手法です。今回のデータでは、これらの手法が効いたのだと思います。実装も簡単なので、是非試してみてください。
BCE Loss
今回のコンペの目的変数は 0~100 の値を取る変数でした。通常ですと、Loss を RMSE 等の連続値を扱うものにすると思います。しかし、今回は 0~100 の値を 100 で割り、0~1 に変換し、BCE Loss(Binary Cross Entropy Loss)を計算するという手法が主流になっていました。Loss を変更しただけで精度向上が確認できたので、これは応用範囲の広い手法だと思いました。
Cross Validation (bin)
KFold の手法として、今回は Stratified KFold を利用しました。これは、設定した列の値の分布を維持するようにデータを分割してくれる手法です。最初は、Pawpularity を設定し、これの分布を維持するように4つのデータセットに分割をしていました。コンペ終盤、改めて Public Notebook/Discussion を読んでいたところ Pawpularity を Rice Rule で分割した bin で、Stratified KFold しているものがありました。またしても、コードの内容はほぼ同じで、 bin のところだけが異なり精度が高いという現象が起きていたため、私も bin に変更しました。
Rice Rule は、正規分布のデータに対して bin 数を算出する式であり、他にも Sturges’ Rule や、Square-root Rule 等があります。どれを選ぶかは分布の形と、試行錯誤というところでしょうか。
重複データの削除
今回のコンペには全く同じ、または、ほぼ同じ画像が数十枚含まれていました。これも Public Notebook/Discussion を見ていて気付いたものです。除外の方法 が公開されており、手法としては、画像の Hash 値を計算して、画像の類似度を計算するものでした。今回私が利用したデータは全て、この処理を実施した後のデータです。
終わりに
前回参加したNFLコンペ(記事はこちら)から連続しての Kaggle 参加で、銀メダルを獲得することが出来ました。いつも Kaggle の環境しか使わないのですが、銀圏はいけたものの金圏はまだまだ遠い印象です。画像・言語系コンペの上位入賞者の多くは、Cloud 契約して GPU 使ってたりする印象なので、勉強も兼ねて Cloud 使ってみるのもありかなと思い始めています。今年1回ぐらいはやってみようかな。もちろんもっと独自の手法を考えるのも非常に重要ですが。今回も学びの多いコンペでした。参加された皆様、お疲れさまでした。
-
TTAは、Test Time Augmentation の略です。参考 cifar10 で Test Time Augmentation (TTA) の実験 ↩
-
連続値を 10 刻みでクラス化し、分類問題として解くことを試しましたが、精度が非常に低く、向上できる気がしなかったので諦めました。 ↩