はじめに
ウェブサービスのシステムなど一部の分野では Docker コンテナはかなり普及しているようです。そのようなところでは、Kubernetes などのコンテナ・オーケストレーション・システムと組み合わせて、システムのデプロイメントと運用を効率的に行うことが Docker コンテナ利用の主目的だと思います。
別の、 Docker コンテナ利用目的として、ソフトウェアのインストールを簡単に行うという側面もあります。たとえば、TensorFlow や PyTorch など、ディープラーニング・フレームワークは非常に多くのライブラリの土台の上に成り立っていて、インストールの際には、まず、それらのライブラリ群をインストールする必要があります。各ライブラリもディープラーニング・フレームワークも頻繁にバージョンアップを繰り返していますので、バージョンのミスマッチにより、インストールの失敗に直面することはめずらしくありません。そのため、Docker Hub などのレジストリでは、あらかじめ、ディープラーニング・フレームワークを始め、多くのフレームワークやアプリケーションがインストール済みのかたちのイメージで公開されています。それらを使えば、ほぼインストールに失敗することなく、手軽に利用を開始することが可能です。
ところで、Jetson Nano のオペレーティングシステム+ソフトウェア開発キットである JetPack の最近のバージョンには最初から Docker 環境がセットアップされています。本記事はこの機能を利用することで、ディープラーニング・フレームワークをとてもかんたんに Jetson Nano 開発者キットにインストールできることを紹介します。
NVIDIA NGC
NVIDIA 社が運営している NGC というサイトをご存知ですか? NGC では GPU に最適化されたディープラーニング、機械学習、ハイパフォーマンス・コンピューティング(HPC)用ソフトウェアが提供されています。Docker イメージの他にも、ディープラーニングの学習済みモデルや、学習用スクリプトなど便利なソフトウェアがたくさん公開されています。NVIDIA GPU 用ソフトウェアに特化した Docker Hub のようなものと言えるでしょう。
この NGC において、ついに、Jetson 用 TensorFlow と PyTorch の Docker イメージが公開されました。特に、Machine Learning for Jetson/L4T は、TensorFlow、PyTorch、onnx、numpy、pandas、scipy、scikit-learn、JupyterLab などディープラーニングを含む機械学習で必要なパッケージがすべて含まれています。もう、TensorFlow や PyTorch のインストールに何時間も費やす必要はありません。
コンテナの実行
では早速、Jetson Nano 開発者キットで、Machine Learning for Jetson/L4T イメージをダウンロード(Pull)して、それをコンテナとして実行してみましょう。
通常、NGC では、あらかじめ API キーを取得して、その API キーを使って NGC 上の Docker イメージにアクセス可能となりますが、本記事作成の時点で、Jetson 向けイメージの場合は API キーなしでアクセス可能な様子です。
まず、NGC から Docker イメージをダウンロード(Pull)します。コロン以降はタグといってバージョンを示します。その部分は、必要とするバージョンのタグに書き換えてください。
$ sudo docker pull nvcr.io/nvidia/l4t-ml:r32.4.2-py3
次に、コンテナを実行します。
$ sudo docker run -it --rm --runtime nvidia --network host nvcr.io/nvidia/l4t-ml:r32.4.2-py3
コンテナが起動すると、自動的に JupyterLab サーバがスタートします。ウェブブラウザで http://localhost:8888 にアクセスして、パスワード nvidia を入力すると、JupyterLab を使うことができます。
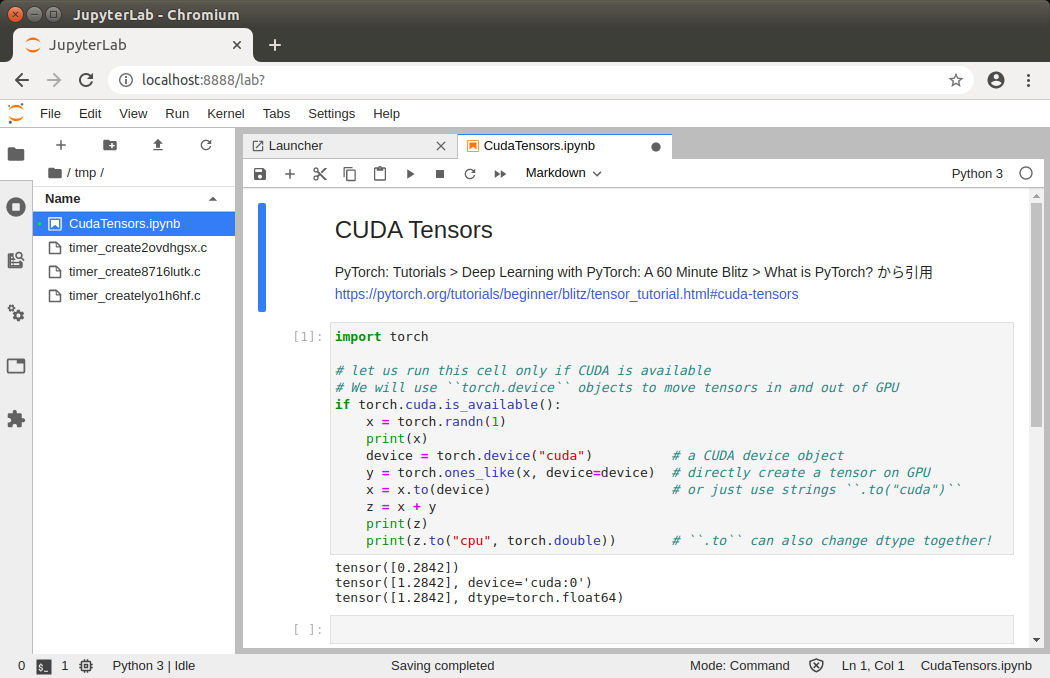
ためしに、PyTorch の公式サイトで公開されている CUDA Tensors サンプルコードで動作確認してみましょう。以下のとおり、変数 x を定義する部分を追加しています。
import torch
# let us run this cell only if CUDA is available
# We will use ``torch.device`` objects to move tensors in and out of GPU
if torch.cuda.is_available():
x = torch.randn(1)
print(x)
device = torch.device("cuda") # a CUDA device object
y = torch.ones_like(x, device=device) # directly create a tensor on GPU
x = x.to(device) # or just use strings ``.to("cuda")``
z = x + y
print(z)
print(z.to("cpu", torch.double)) # ``.to`` can also change dtype together!
下図のとおり、正しく実行できました。
コンテナ内のシェル・プロンプトで exit と入力すると、コンテナを終了して、ホスト側へ戻ります。
# exit
コンテナをクリーンアップしない方法
上記の例では、docker run コマンドに --rm オプション を付けて、コンテナ終了時に、コンテナ内のファイル・システムをクリーンアップします。コンテナ内で行ったファイル・システムの変更を保存しておきたい場合は、この --rm オプション外します。さらに、コンテナに名前を付けておくと、コンテナを再起動する際に楽です。いろいろなやり方があると思いますが、私が使っている方法は以下のとおりです。
以下の例では、コンテナに my-l4t-ml という名前を付けています。
また、-v $HOME:$HOME オプションで、ホスト側のホーム・ディレクトリをコンテナ内のファイル・システムへマウントしています。ホストとコンテナの間でデータのやり取りを行うためです。なお、マウントはセキュリティ上の問題になることもあるので、注意して使ってください。
-d オプションを指定すると、コンテナはデタッチド・モードで起動し、コンテナはバックグラウンドで動作します。
$ sudo docker run --name=my-l4t-ml -d -v $HOME:$HOME -it --runtime nvidia --network host nvcr.io/nvidia/l4t-ml:r32.4.2-py3
動作中のコンテナに入ってシェルを実行するコマンドは以下のとおりです。一つのコンテナに対して、複数のシェルを実行することもできます。
$ sudo docker exec -it my-l4t-ml /bin/bash
動作中のコンテナを停止させたいときは以下のコマンドを発行します。
$ sudo docker stop my-l4t-ml
停止中のコンテナは以下のコマンドで再起動できます。
$ sudo docker restart my-l4t-ml
必要のなくなったコンテナは以下のコマンドで削除できます。
$ sudo docker stop my-l4t-ml
$ sudo docker rm my-l4t-ml
まとめ
JetPack にデフォルトでセットアップされている Docker と、NVIDIA NGC により、Jetson Nano 開発者キットに対して、とてもかんたんにディープラーニング・フレームワークをインストールできることを紹介いたしました。
おまけ
docker コマンドを発行するときに、sudo を付けるのが面倒ならば、以下の記事が参考になります。
Dockerコマンドをsudoなしで実行する方法
以上です。