0.はじめに
NTTデータの鶴ヶ崎です。
公共分野の技術戦略組織に所属しており、普段はクラウド(主にAWS)を用いたシステム構築等を行っています。
今回はEC2×td-agent構成のログ機能におけるログ連携遅延が発生したため、当時のトラブルシューティング事例を共有しようと思います。同様の問題を抱える方の参考になれば幸いです。
目次
1.本記事の前提情報
本題に入る前に前提情報を説明します。
1.1 Fluentd、td-agentとは
-
Fluentd
- OSSのログなどのデータを収集可能なソフトウェア
- https://docs.fluentd.org/

-
td-agent
- Fluentdの安定版
- Fluentdの安定版
-
Fluentd、td-agentの特徴
- エージェント・サーバ型の構成をとることで、複数サーバからログを集約可能
- 各ログをリアルタイムでログ連携先サーバに連携し、連携先のログストア(buffer)に保管
- bufferから、設定タイミングでログ出力(flush)
-
Fluentd、td-agentの利点
- bufferにログを蓄積するため高信頼性
- LinuxやWindows等マルチプラットフォーム対応
- ログに限らず各種データをNoSQLやS3等様々な媒体に出力可能
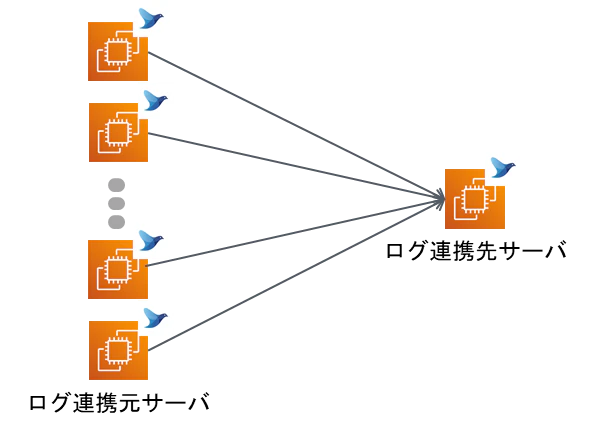
1.2 システム構成
本トラブルシューティング事例のシステム構成は以下図のようになっています。
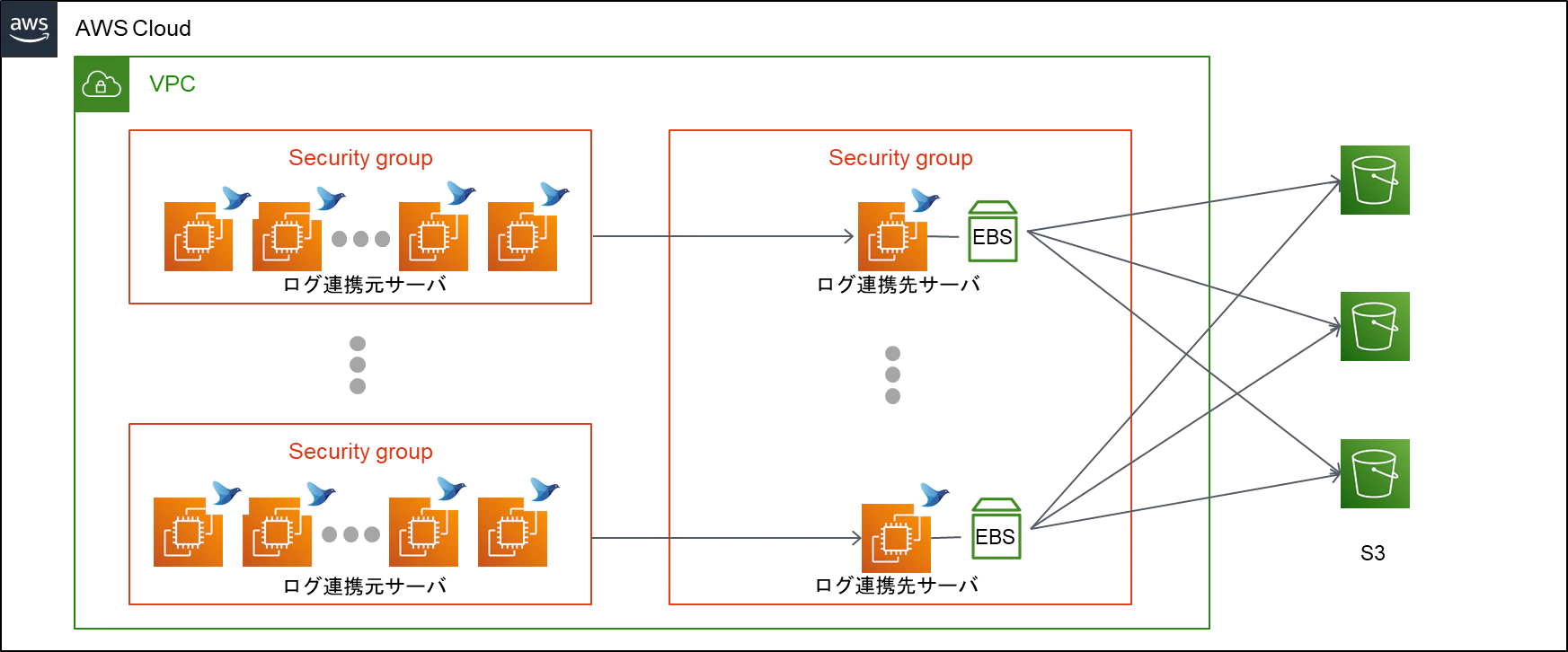
ポイント
- 以下の順序でS3にログ出力
- 各ログ連携元サーバ → ログ連携先サーバのbufferにログを保持
- ログ連携先サーバのbufferから1時間に1回flush
- 1時間に1回のバッチでS3に出力
- confによりbufferをメモリでなくディスクに保存する設定
- CentOS 7系EOLを迎えるに伴い、ログ連携元・先サーバのOSディストリビューション変更を実施
- 変更前:CentOS 7.3
- 変更先:Rocky Linux 8.6
- OSディストリビューション変更に伴い、td-agentのメジャーバージョンアップを実施
- VerUP前:2.3.6
- VerUP後:3.8.1
上記変更後のログ連携元・先の各サーバは以下の構成となります
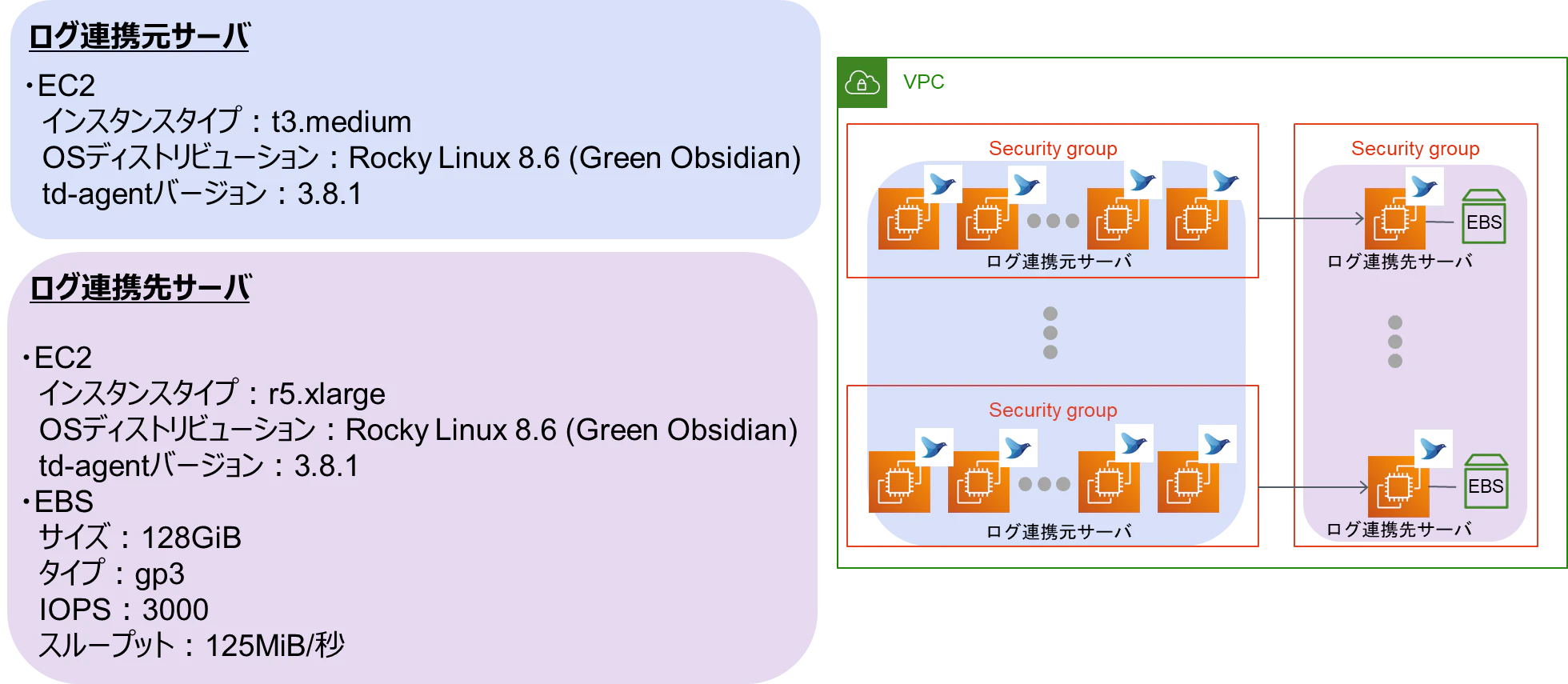
-
ログ連携元サーバ
- EC2
- インスタンスタイプ:t3.medium
- OSディストリビューション:Rocky Linux 8.6 (Green Obsidian)
- td-agentバージョン:3.8.1
- EC2
-
ログ連携サーバ
- EC2
- インスタンスタイプ:r5.xlarge
- OSディストリビューション:Rocky Linux 8.6 (Green Obsidian)
- td-agentバージョン:3.8.1
- EBS
- サイズ:128GiB
- タイプ:gp3
- IOPS:3000
- スループット:125MiB/秒
- EC2
2.発生したトラブル
OSディストリビューション変更/td-agentのメジャーバージョンアップ後、ログ連携先サーバからS3へのログ出力が以前より2時間以上遅延していることが発覚しました。
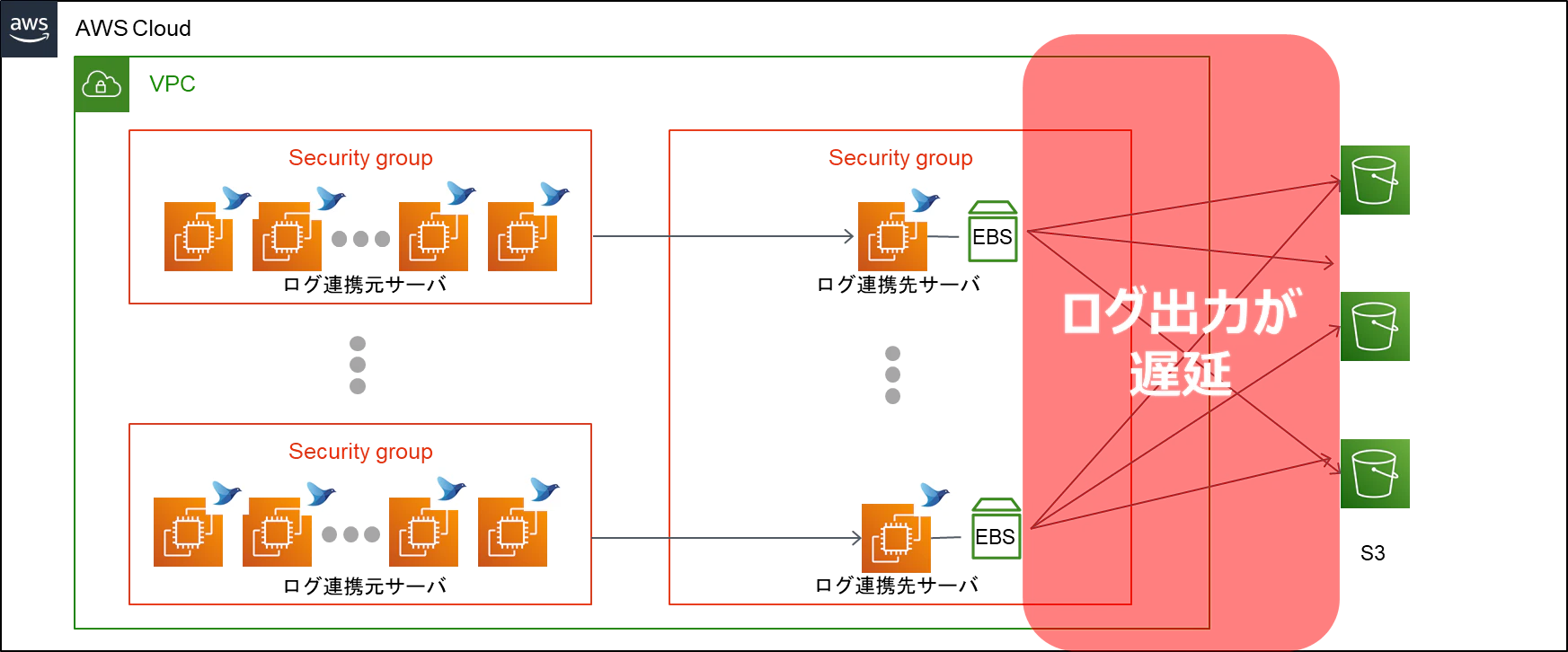
2.1 被疑箇所の特定
再掲ですが以下の順序でS3にログ出力しています。
- 各ログ連携元サーバ → ログ連携先サーバのbufferにログを保持
- ログ連携先サーバのbufferから1時間に1回flush
- 1時間に1回のバッチでS3に出力
各処理を順にみていきます。
-
各ログ連携元サーバ → ログ連携先サーバのbufferにログを保持
- 意図通りにログ連携先サーバにログ保持されているため、被疑箇所でないと判定
- 意図通りにログ連携先サーバにログ保持されているため、被疑箇所でないと判定
-
ログ連携先サーバのbufferから1時間に1回flush
- 意図したタイミングよりも約20分遅くflush完了しており、本来より1,2時間後のバッチでS3出力されているため、「2」が被疑箇所と判定
- 意図したタイミングよりも約20分遅くflush完了しており、本来より1,2時間後のバッチでS3出力されているため、「2」が被疑箇所と判定
-
1時間に1回のバッチでS3に出力
- 本来の時間に「2」でflushされたログは意図した時間にS3出力されていることを確認
- 「2」の理由から、被疑箇所でないと判定
2.2 原因の特定
「2. ログ連携先サーバのbufferから1時間に1回flush」の処理に影響するものとして以下が考えられるため、以下3つのいずれかに問題があると予測し確認を行った。
- ログ起因
- td-agentバージョンアップ起因
- OSディストリビューション変更起因
原因の候補をみていきます。
-
ログ起因
- OSディストリビューション/td-agentのメジャーバージョンアップ前後でログ量の大幅増はないので、原因でないと判定
- OSディストリビューション/td-agentのメジャーバージョンアップ前後でログ量の大幅増はないので、原因でないと判定
-
td-agentバージョンアップ起因
-「1」「3」の調査より、 「2」が原因である可能性が高いと推測した。
-
OSディストリビューション変更起因
- 以下2点より、原因でないと判定
- CPU使用率、I/Oなどリソース状況が高負荷でない
- Rocky Linuxとtd-agentが動作サポートされていることも確認
- 以下2点より、原因でないと判定
2.3 原因の深堀
td-agentの何が原因なのかを見ていきます。
調査からtd-agentメジャーバージョンアップにより、buffer/flushの仕様に変更があったようです。バージョンアップ前はbufferからのflushは10分未満で終わってましたが、バージョンアップ後は1ログあたりのflushに平均30分かかっていることがわかりました。そのため、flush自体に時間がかかっていることが原因で問題が発生していると仮定しました。
(参考)
Buffer Pluginsのv0.12/v1.0
Fluentd (td-agent) のバージョンアップ [td-agent2 から td-agent3 へバージョンアップ]
3.対策立案
flush自体に時間がかかっていることが原因で問題が発生していると仮定し、以下3案を比較しました。
- 1時間に1回のflushを、ログ連携元サーバからログ連携都度flushに変更
- 1時間に1回のflushから変更せず、flush時のスレッド数を増やす
- 1時間に1回のflushから変更せず、I/O・スループット性能の高いインスタンスタイプ・EBSボリュームに変更
以下比較より案1/2が候補となりますが、効果が高い案1を採用しました。
| 比較軸 | 案1 | 案2 | 案3 |
|---|---|---|---|
| コスト | 〇 追加コスト無 |
〇 追加コスト無 |
△ インスタンスタイプ・EBSボリュームの差額が発生 追加コストの承認作業が発生 |
| 時間 | △ td-agent.confの変更、MWレベルの再起動のみ(案2より変更箇所多) |
〇 td-agent.confの変更、MWレベルの再起動のみ |
✕ インスタンスタイプ・EBSボリュームの変更、OSレベルの再起動が必要 |
| 効果 | 〇 即flushするためログ遅延発生確率が低 |
△ 1ログあたりのflushに時間を要しているため出力時間大幅短縮の見込みが薄い |
〇 高性能へ変更するため効果大 |
今回は案1を採用しましたが、以下の場合はそれぞれの案が優位だと考えます。
- 案2を採用する場合
- ログのS3出力頻度が1時間に1回よりも少なくて良い場合
- ログ種別が多かったり、など並列処理の効果が見込まれる場合
※CPUリソースに余裕がある必要有り - 1ログあたりのflushに時間を要してない場合
- 案3を採用する場合
- CPUやI/Oなどがボトルネックである場合
- 長期的にログ量増が見込まれる場合
- 一時的なサービス断が許容される場合
- 追加コストを許容する場合
- 標準インスタンスに対してEBS帯域を強化した「r5b.xlarge」を選択する場合
- オンデマンド時間単価が「USD 0.252」から「USD 0.298」に値上がります
r5.xlargeの場合
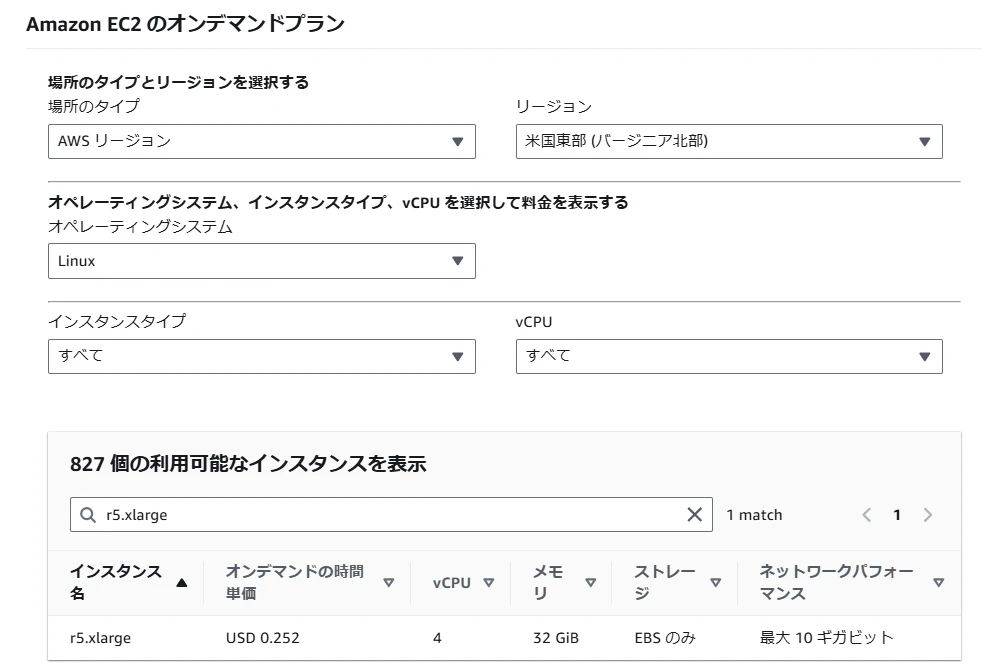
r5b.xlargeの場合
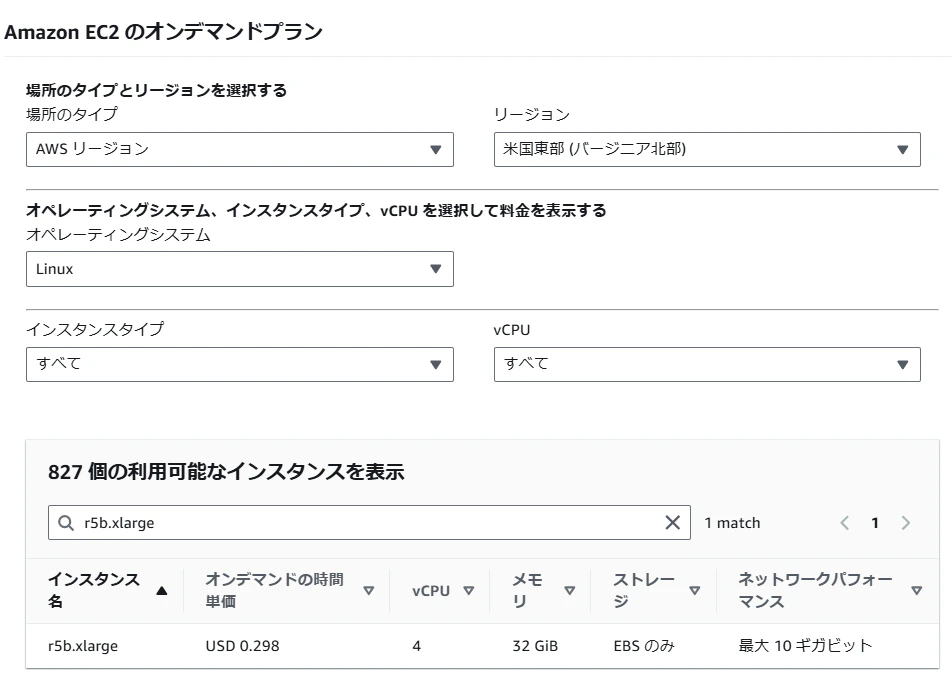
参考Amazon EC2 オンデマンド料金
- オンデマンド時間単価が「USD 0.252」から「USD 0.298」に値上がります
- EBSタイプを「プロビジョンド IOPS SSD (io2) - IOPS」に変更した場合
- 「USD 0」から「USD 0.065」に値上がります
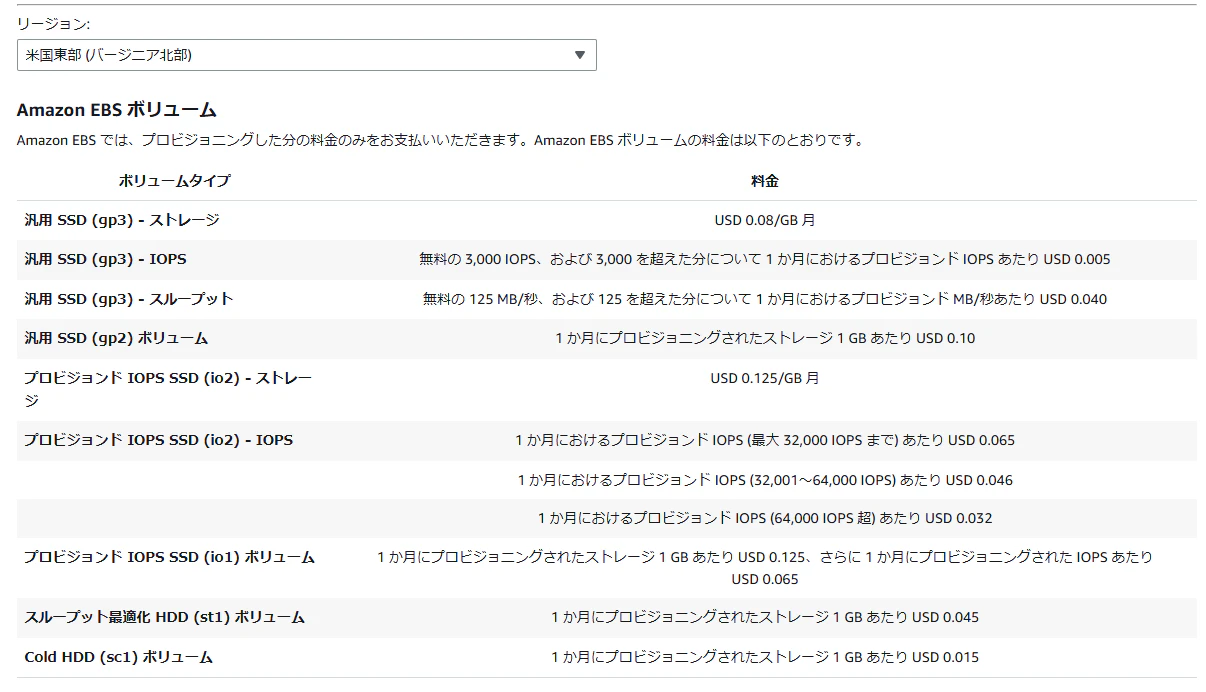
参考Amazon EBS の料金
- 「USD 0」から「USD 0.065」に値上がります
- 標準インスタンスに対してEBS帯域を強化した「r5b.xlarge」を選択する場合
案3を採用する場合、以下2点の注意が必要です。
- EC2インスタンスタイプ変更はOSレベルの再起動が必要
- エラスティックボリュームにより停止無しでEBSタイプ変更可能
4.対策実施
案1「1時間に1回のflushを、ログ連携元サーバからログ連携都度flushに変更」を実施します。

変更点
- appendパラメータ
- 既存ファイルにflushするかどうかの設定
- 既存ファイルに追記する形でflushするため「true」を指定
- time_slice_formatパラメータ
- 出力ファイルフォーマットの設定
- 連番を付与するためファイル名末尾に「_0」を追加
- flush_modeパラメータ
- flushの動作モードの設定
- ログ連携され都度flushするため「immediate」を指定
- timekey_waitパラメータ
- flushタイミングの設定
- 現行では毎時10分flushのため「10m」を指定してたが、都度flushに変更するため削除
変更前
<match log.data/fluentd/pdca**>
@type file
path /${tag[1]}/${tag[2]}
format single_value
symlink_path /${tag[1]}/${tag[2]}.log
time_slice_format %Y%m%d%H_${tag[3]}_1a
compress gzip
<buffer tag, time>
@type file
path /data/fluentd/pdca/log/
flush_at_shutdown true
queue_limit_length 512
chunk_limit_size 256m
timekey 60m
timekey_wait 10m
</buffer>
</match>
変更後
<match log.data/fluentd/pdca**>
@type file
append true
path /${tag[1]}/${tag[2]}
format single_value
symlink_path /${tag[1]}/${tag[2]}.log
time_slice_format %Y%m%d%H_${tag[3]}_1a_0
compress gzip
<buffer tag, time>
@type file
flush_mode immediate
path /data/fluentd/pdca/log/
flush_at_shutdown true
queue_limit_length 512
chunk_limit_size 256m
timekey 60m
timekey_wait 10m
</buffer>
</match>
5.設定変更による影響調査
遅延発生時と同じ条件で負荷掛け試験を実施したところ、CPU使用率・I/Oともに微増したが軽微なものであったため問題ないことを確認しました。
6.おわりに
EC2×td-agent構成におけるログ連携遅延でお困りの方の参考になれば幸いです。
※本ブログに記載した内容は個人の見解であり、所属する会社・組織とは関係ありません。また、誤った情報が含まれる可能性もありますのでご留意ください。