本記事はCraft Egg Advent Calendar 2021の12/24の記事です。
12/23の記事は@mrtm30さんの「[Unity] Adaptive Performanceを試してみた」でした。
はじめに
メリークリスマス!@tsune_ceです。
2015年以降AIが急速な成長をしている中、私は今までAIに携わってきませんでした。
AIがどういったものか触れてみる為、今回の題材にしてみました。
なにするか
自分が興味が持てるものを題材にしたほうが学習のモチベーションを保てると思い、「パチスロのボーナス回数予測」にしてみました。
やること
プログラミング言語と必要なライブラリ
機械学習が得意なPythonを使用します。
今回使用するライブラリは以下です。
- pandas
データの入手と加工 - matplotlib
データの可視化 - sklearn
機械学習の手法 - category_encoders
文字列を数字にエンコード
基本的な機械学習の流れ
機械学習(英語表記:Machine Learning)は、AIに内包される分野で、特定のタスクをトレーニングにより機械に実行させるものである、と定義されています。
基本的な処理は以下の流れになります。
- 「データ入手と加工」
データの概要をとらえ、目的の機械学習に利用できることの確認と見やすい形に整えます。
- 「データ可視化」
データを表やグラフを用いて可視化します。
- 「アルゴリズム選択」
目的やデータに適したアルゴリズムを選択します。
- 「学習プロセス」
選択したアルゴリズムを基にしてモデルを学習します。
- 「精度評価」
学習済みモデルを使い予測します。
- 「試験運用」
ここまでは既存のデータで評価を行なっていますが、実際の評価は未知のデータでの評価が必要になります。
試験運用では、モデル作成時に未知のデータで評価を行います。
評価が思わしくない結果の場合は、各プロセスの1から5を見直します。
- 「結果利用」
試験運用の結果、目的に対し利用可能な精度が確保できれば学習済みモデルを保存し予測を行います。
要約すると、「与えられたデータから学習し、規則を発見し、新規のデータに対して予測ができる」ことになります。
データの準備
予測するにはデータが非常に重要です。昔はなかったのですが、昨今はホールの出玉情報を公開しているWEBサイトがあり、そこからデータを取得する事ができます。
しかしWEBサイトに対し誤ったスクレイピングをしてしまうと違法となってしまう為、今回はセーフティに実際の本番データを模したダミーデータで行うことにしました。スクレイピングについては後述します。
(参考)スクレイピング
今回は使用しませんが、参考までにスクレイピングの基本的なやり方を記載します。
弊社のWEBサイトをスクレイピングしてみます。
# URLを開くための関数とクラスを定義
from urllib import request
# HTMLおよびXMLドキュメントを解析
from bs4 import BeautifulSoup
# 弊社のWEBページ
url = "https://www.craftegg.co.jp/corporate/vision/"
html = request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
print(soup.title) # 取得したtitleタグを表示
print(soup.h1) # 取得したh1タグを表示
a = soup.findAll('p')
print(a) # 取得したaタグをすべて表示
print(len(a)) # 取得したすべてのaタグの個数を表示
出力結果
<title>ビジョン・ミッション|企業情報|Craft Egg</title>
<h1><a href="/"><img alt="CraftEgg" src="https://www.craftegg.co.jp/wp-content/themes/craftegg2020/common/images/logo.svg"/></a></h1>
[<p>私たちは、他の誰でもない自分の人生を、良い時も悪い時も自分の意志で生きている状態こそが、人生が豊かな状態だと考えています。それは決してやさしい人生ではないかもしれませんが、そういった生き方は人として成長し、成熟していくために必要で、沢山の人が一生をかけて成熟し、また周りの人を導いていく先に、より良い社会があるのだと信じています。<br/>人々が自分の人生を、自分の意志で生きられる社会の実現に、私たちは生み出すコンテンツを通じて貢献していきます。 </p>, <p>エンターテインメントは触れた人々を様々な方向に動かす力を持っています。<br/>その中でも、私たちが提供するキャラクターコンテンツは、キャラクター一人ひとりの生き方や考え、成長していく姿を通じ、人々の心を打ち、生きる活力を届けられるものだと考えています。その体験は触れた人の意志を育み、人生を豊かにする力があると信じています。<br/>私たち自身がコンテンツを愛し、お客さまにどんな体験を届けるべきかを考えられる会社であり続けたいと考えています。</p>, <p class="corporateList__text">私たちの強みと<br/>目指す未来について</p>, <p class="corporateList__text">Craft Eggの会社情報</p>, <p>Craft Eggは、一人ひとりが<br/>コンテンツを通じてお客さまの<br/>人生を豊かにすることを第一に考える、<br/>世界で一番ユーザーファーストな<br/>ものづくりをする組織でありたいと<br/>考えています。</p>, <p>どうすればより良くなるかを考え続け、<br/>自らの意志で責任を持って行動すること、<br/>そしてチームで起きている全てのことに<br/>当事者意識を持てることが、<br/>よりよい成果につながります。</p>, <p>年齢、職業、国など<br/>あらゆる枠組みに囚われて物事を<br/>決めつけることをせず、<br/>ありのままの姿を素直に<br/>受け入れることが、<br/>時代に合った素晴らしい<br/>コンテンツを生み出します。</p>, <p>既存のやり方や枠組みを超え、<br/>時に大胆に、あらゆる障害を<br/>取り除いて物事を考えることが、<br/>個人や会社、コンテンツの<br/>大きな飛躍には必要不可欠です。</p>, <p>Craft Eggは新しい技術や<br/>価値観の変化に柔軟に適応し、<br/>世の中に価値を生み出し続けたいと<br/>考えています。それには一人ひとりが<br/>今何をすることが大切かを考え、<br/>時に過去積み上げたものを捨ててでも、<br/>チャレンジし成長を続けることが必要です。</p>, <p>コンテンツの大きな成長のためには、<br/>目先の短期的な利益にとらわれることなく、<br/>長期的な価値を最大化することを<br/>諦めてはいけません。<br/>お客さまとの長く素晴らしい関係を<br/>築くことが大事です。</p>, <p>チームでより大きな成果を出すために、<br/>互いに理解し続けようとすることを諦めず、<br/>相手に理想を押し付けず、<br/>敬意をもって率直なコミュニケーションを<br/>とり続けることが大事だと考えています。<br/>そして同時に、自分の間違いを素直に<br/>認める心を持つことが必要です。</p>, <p>Craft Eggは組織が<br/>永続的に成長するために、<br/>積極的に優秀な人を中に迎え、<br/>年次や年齢の上下や役割に関係なく、<br/>お互いがお互いの仕事での成長、<br/>人間としての成長を考えられる<br/>会社でありたいと考えています。</p>, <p>お客さまの人生を豊かにする<br/>コンテンツをつくるために、<br/>まずCraft Eggのメンバー一人ひとりに、<br/>他の誰でもない自分の人生を、<br/>人間として成長しながら、<br/>自らの意志で責任をもって<br/>豊かに生きて欲しいと考えています。</p>, <p class="l-footer__pp"><a href="/privacypolicy/">プライバシーポリシー</a></p>, <p class="l-footer__copy">©Craft Egg Inc. All Rights Reserved.</p>]
15
このようにWEBページから要素を抜き出し、機械学習に必要なデータを集め加工していきます。
またスプレイピングで気をつける事としては以下になります。
- WEBサイトがプログラムでのアクセスを許可していること
WEBサーバにrobots.txtというファイルがあり、アクセス可否の内容が記載されています。
詳細はGoogle Developersの仕様を参照してください。 - 連続して悪意のあるアクセスをしないこと
WEBサーバに負荷がかかり、サーバが落ちてしまうこともあります。
ライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
import category_encoders as ce
from sklearn.ensemble import RandomForestRegressor
データの取得
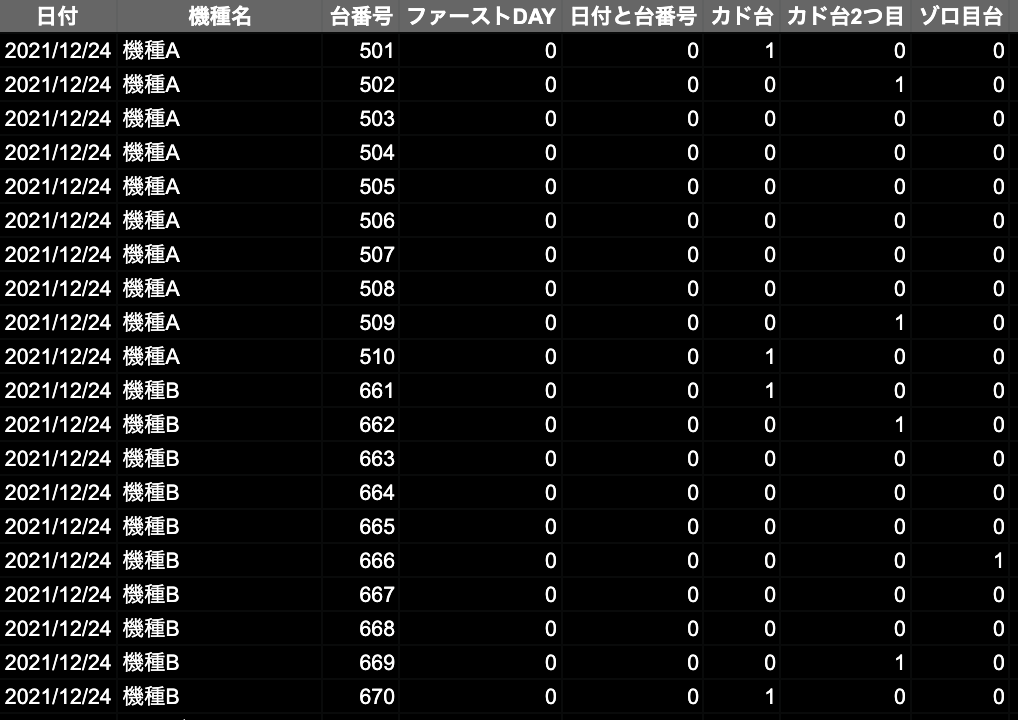
20年前の「機種A」「機種B」という2種の台が、図のように並んでいると仮定します。
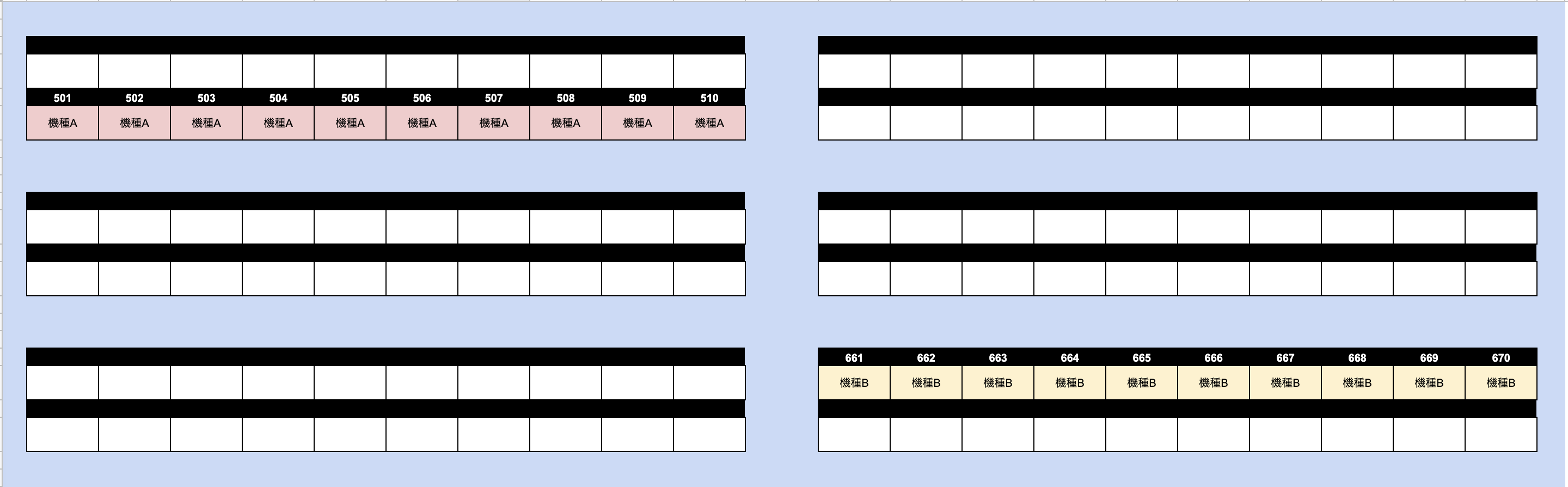
「機種A」「機種B」のプレイデータです。
本来はスクレイピングしたデータになります、こちらはダミーデータです。
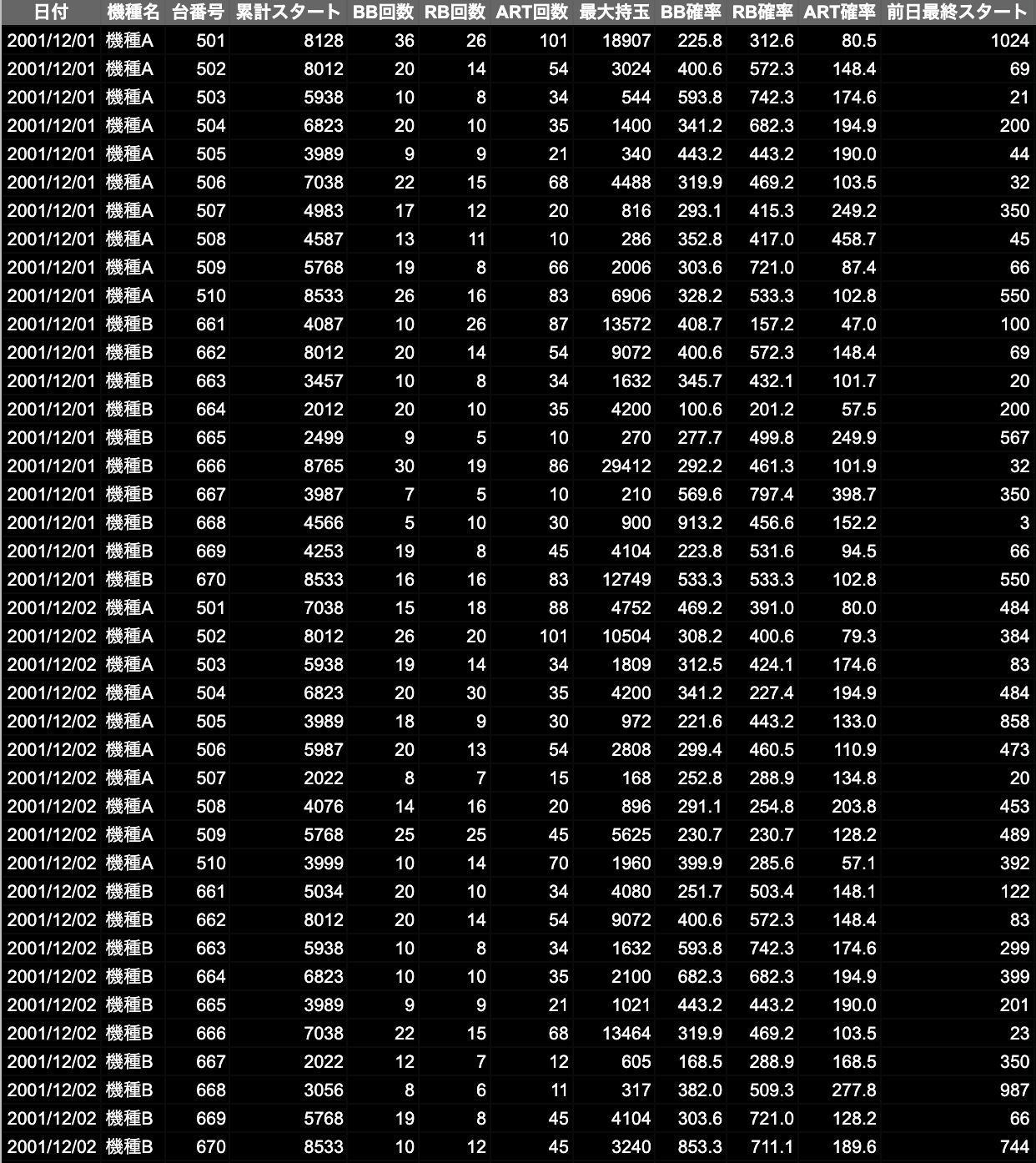
データのとりこみ
train = pd.read_csv('data.csv')
データの出力内容を確認する時にデフォルトの設定が省略して表示されてしまう為、pandasのオプションを変更します。
pd.options.display.max_columns = None
pd.options.display.width = None
データの加工
モデルに学習させる為にデータの加工を行います。
今回は機械学習のタスクである「教師あり学習」という方式をとります。
教師あり学習とは正解となるラベルデータが存在する場合に用いられます。
# BB、RB、ART回数をbonus回数としてまとめる
# 日付を年月日で分ける
train["bonus"] = train["BB回数"] + train["RB回数"] + train["ART回数"]
train["year"] = train["日付"].apply(lambda x: x.split("/")[0])
train["month"] = train["日付"].apply(lambda x: x.split("/")[1])
train["day"] = train["日付"].apply(lambda x: x.split("/")[2])
## 機種名を数値に変換
columns = ["機種名"]
change_columns = ce.OrdinalEncoder(cols=columns, handle_unknown='impute')
train_transform = change_columns.fit_transform(train)
特徴量
スプレイピングしたデータだけでは、機械学習にとって十分なデータにはなりません。
予測精度をあげるためには、特徴量のデータが欠かせません。
特徴量とは特徴が数値化されたもので、ヒトでいうと年齢・性別・身長・体重・血液型などがあたります。
予測精度が高い機械学習には良質なデータが必要となりますが、そのデータには特徴量の質と量が大きく影響しています。
データに加え、特徴量のデータを追加していきます。
仮に、このホールには以下のような特徴があったとします。
- 毎月1日はファーストDAYというイベントがあり高設定の台が多い。
- 日付と台番号下2桁がマッチした場合、高設定になりやすい。
- カド台は高設定になりやすい。
- カド台の隣は高設定になりやすい。
- 台番号の下2桁がゾロ目の場合、高設定になりやすい。
※ 高設定 = 基本的にパチスロは設定1〜6まであり、数字が大きい方が出玉が多くなりやすい。
特徴量を追加したデータです。0と1で表します。
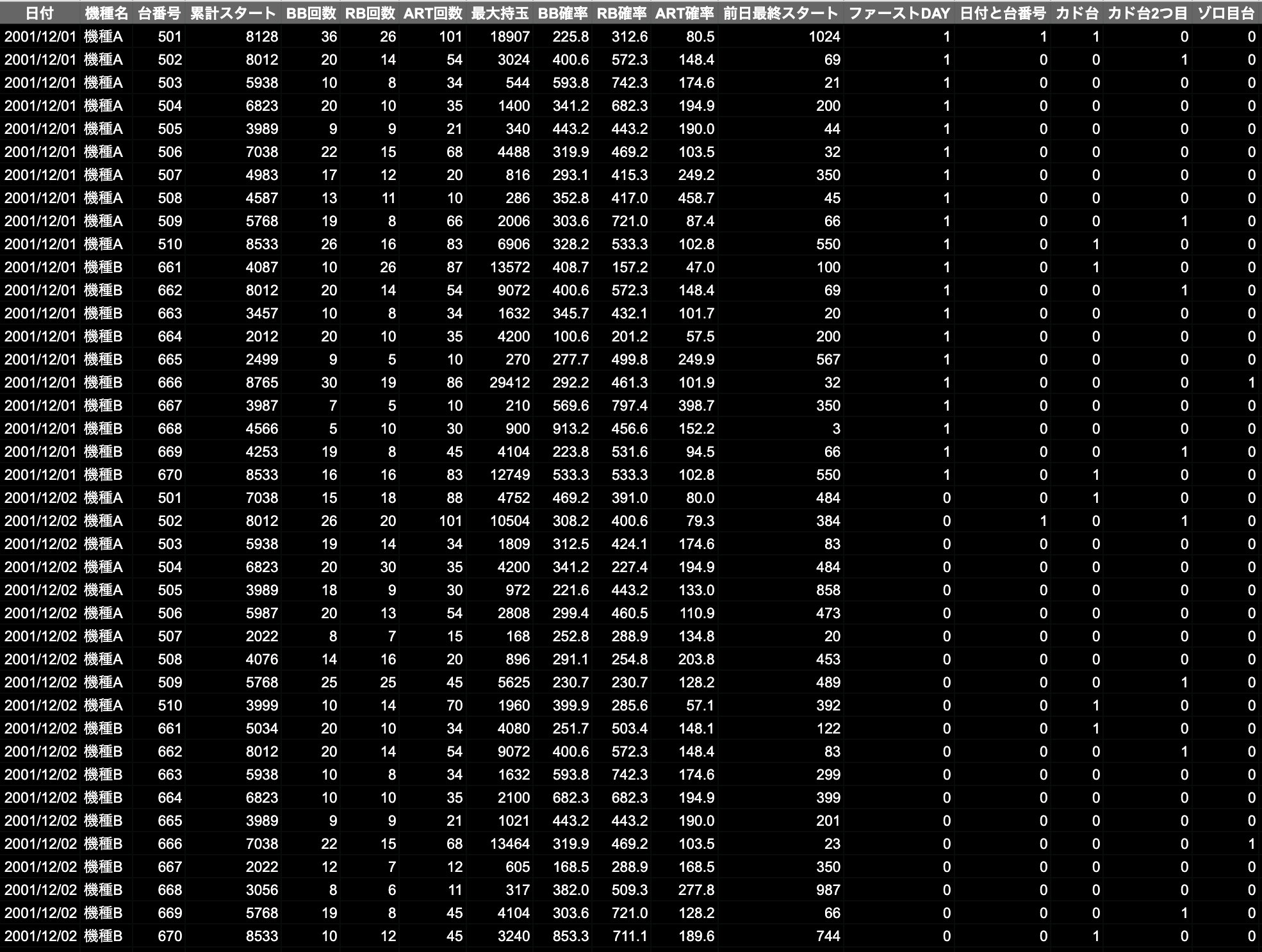
説明変数と目的変数
「教師あり学習」の正解となるラベルデータとは、タスクとなる課題に対して目的となる値です。
今回はボーナス回数(bonus)になります。
正解ラベルの目的であるデータを目的変数と呼びます。
目的変数以外のデータは目的データを説明することから説明変数と呼びます。
# 説明変数
x_train = train_transform[["year", "month", "day", "台番号", "機種名" "ファーストDAY", "日付と台番号", "カド台", "カド台2つ目", "ゾロ目台"]]
# 目的変数
y_train = train_transform["bonus"]
モデルの学習
今回はランダムフォレストというアルゴリズムを使用します。
確率を複数の説明変数の組み合わせで算出する機械学習手法です。
モデルに説明変数と目的変数をセットして学習します。
model = RandomForestRegressor()
model.fit(x_train, y_train)
予測
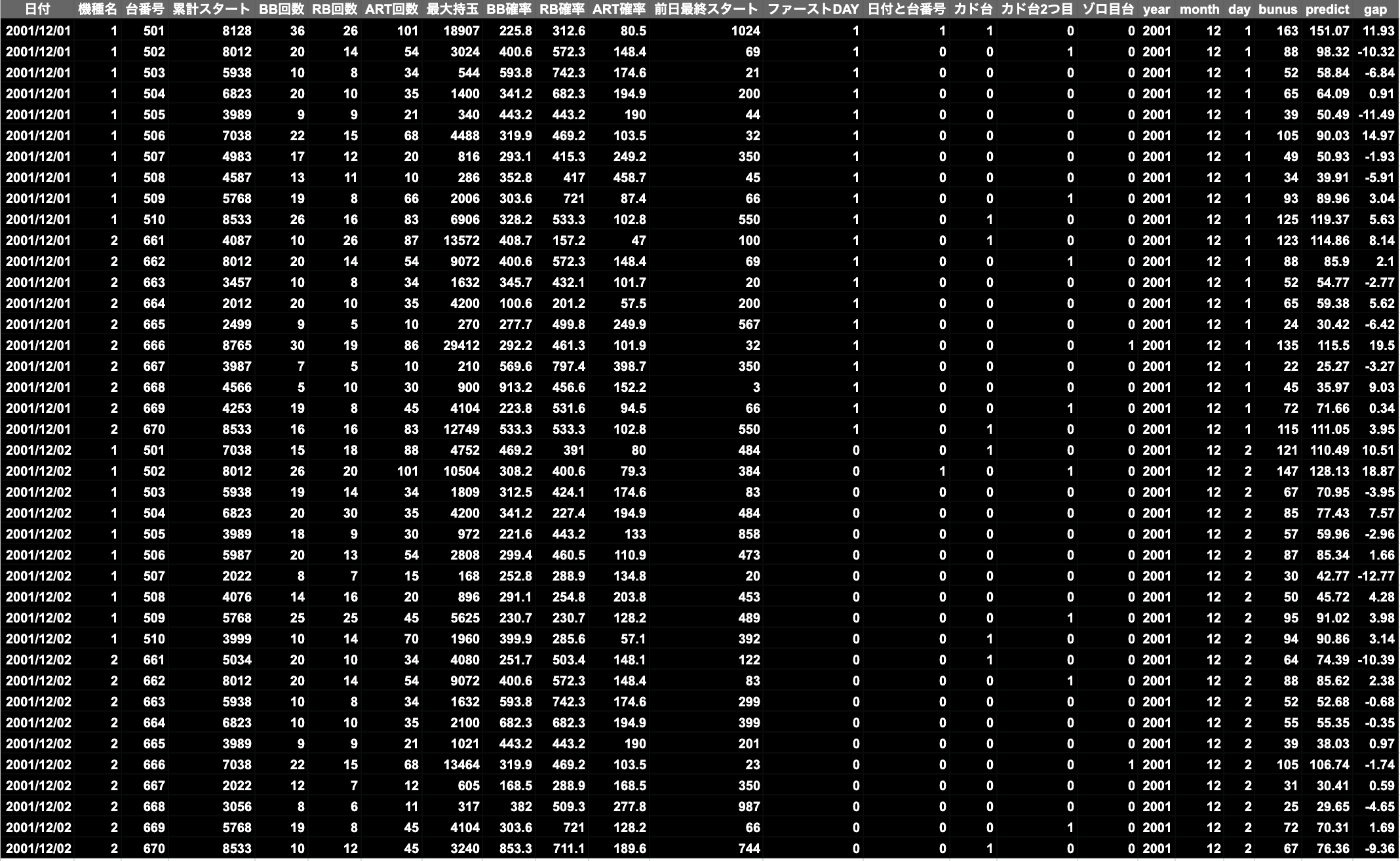
予測をします。
データと予測のズレを確認します。
predict = model.predict(x_train)
train_transform["predict"] = predict
train_transform["gap"] = train_transform["bonus"] - train_transform["predict"]
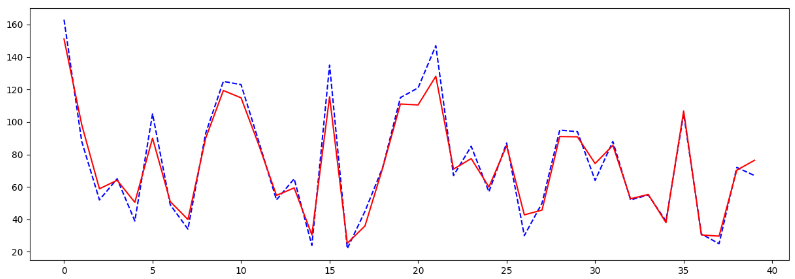
出玉が爆発した台や、ハマった台はズレが多少ありましたが、データと予測のギャップはさほどないような結果になりました。
データの可視化
見やすいようにデータと予測のズレを可視化します。
データは青色のグラフ、予測は赤色のグラフです。
plt.figure(figsize=(15, 5))
plt.plot(train_transform["bonus"], color="blue", linestyle="dashed")
plt.plot(train_transform["predict"], color="red")
plt.show()
少しのズレである事がよくわかります。
クリスマスイブの出玉予測
ようやく出玉予想ができる状態となりました。
それでは現代である2021/12/24に「機種A」と「機種B」をこちらのホールでプレイした場合の出玉予想を行います。
日付を2021/12/24にして、予測に必要なデータだけcsvにします。
データの取得・加工を行い、学習済みモデルに説明変数をセットして予測します。
train_eve = pd.read_csv('data_eve.csv')
train_eve["year"] = train_eve["日付"].apply(lambda x: x.split("/")[0])
train_eve["month"] = train_eve["日付"].apply(lambda x: x.split("/")[1])
train_eve["day"] = train_eve["日付"].apply(lambda x: x.split("/")[2])
columns = ["機種名"]
change_columns = ce.OrdinalEncoder(cols=columns, handle_unknown='impute')
train_eve_transform = change_columns.fit_transform(train_eve)
x_train_eve = train_eve_transform[["year", "month", "day", "台番号", "機種名", "ファーストDAY", "日付と台番号", "カド台", "カド台2つ目", "ゾロ目台"]]
predict_eve = model.predict(x_train_eve)
train_eve_transform["predict"] = predict_eve
クリスマスイブの出玉予測結果
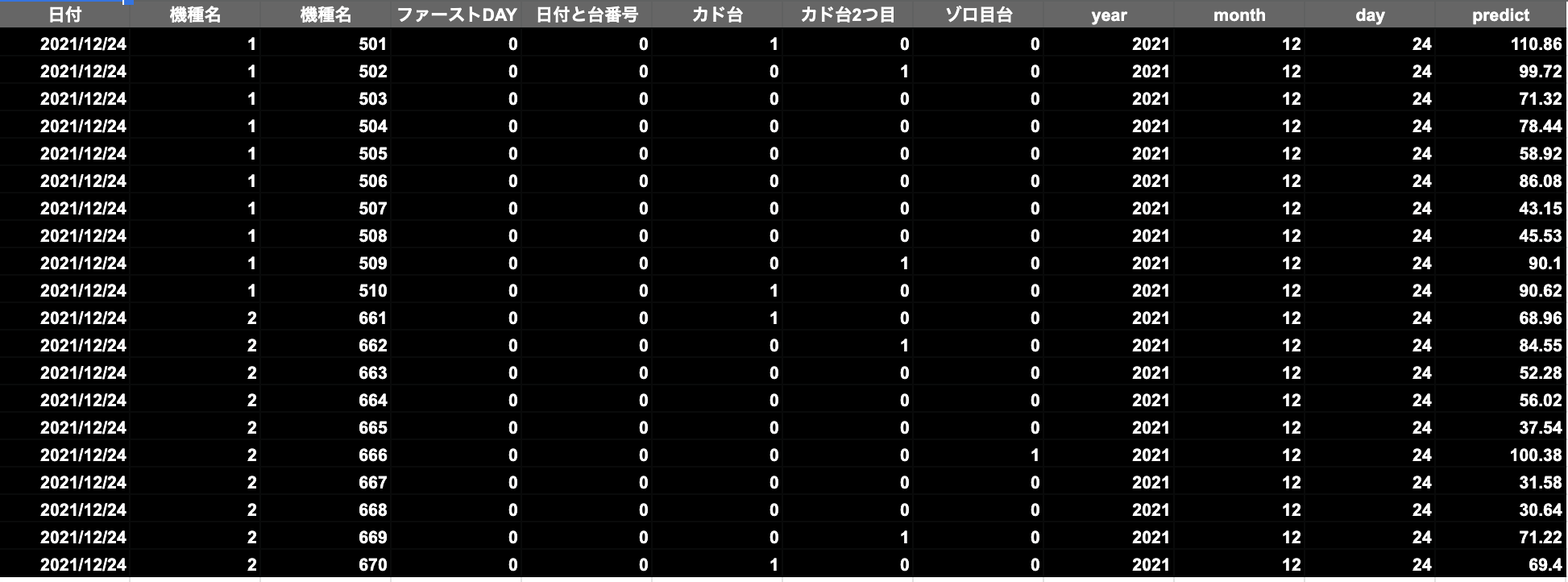
クリスマスイブの出玉予想は、501番台(カド)と666番台(ゾロ目)がボーナス合算100回以上でる結果となりました。
さいごに
はじめて機械学習に触れてみましたが、所感としてはとても難しく深い、そしてデータを入手するのが大事であり大変、といった感想でした。
今回のデータ量としては2日分・2機種しかないですし、これが365日・全機種のデータが揃っていたらもっと精度の高い出玉予測ができたのではないでしょうか。
またWEBで調べたり機械学習の書籍読んだりして感じた事として、まだ全体の0.001%くらいしか触れていない気がします。
ランダムフォレスト以外にも様々なアルゴリズムが用意されていますし、パチスロだけではなくゲーム開発にも活かせると思うので色々使えるようになりたいです。
明日は@Tomy_0331さんの記事です。
Craft Egg Advent Calendar 2021を振り返ります。