はじめに
Dance Dance Revolution(DDR)というゲームは知っているでしょうか?
リズムにあわせてパネルを踏むリズムゲーム(音ゲー)の1つです
一般的な音ゲーでは、パネルの踏み方(譜面)ごとに難易度が指定されています
今回は、この譜面をもとに公式が指定した難易度を予測する回帰モデルを作りました
どうやって作ったか: 理論編
DDRに対して基盤モデルのファインチューニングを行うことで、難易度予測を行います
しかし、先行研究やhuggingfaceを探したのですが、難易度推定自体は行われているようです1が、なぜかDDRの基盤モデルはありませんでした
そのため、まず自分で基盤モデルを作り、次にそれを使って難易度推定のファインチューニングを行います
回帰・分類モデルの一般論
基盤モデル・ファインチューニングについてざっくり説明します
わかっている方は読み飛ばして大丈夫です
データをもとに、特定の変数の値(今回の場合はDDRの難易度)を予測するモデルを、回帰・分類モデルといいます
最近では、時系列・画像・言語などの非構造データでは、深層学習を用いた手法が最高精度を出すことが知られており、最もスタンダードな手法の1つとなっています
一方、深層学習で確かな精度をだすには、大量のデータが必要になります
この問題を解決する手法が「基盤モデル」と「ファインチューニング」です
まず初めに大量のデータで、事前学習と呼ばれる本来解きたいタスクとは異なる別のタスクを行いそのドメイン(言語・画像など)に対し対応力を持った「基盤モデル」を作成します
次に、特定のタスクをターゲットにした別のデータで「基盤モデル」を学習(ファインチューニング)させます
これにより、後段のタスクにおいてはデータセットが少量の状況でも、十分な精度のモデルを作ることができます
当然、前段の「基盤モデル」では大量のデータが必要ですが
- 「基盤モデル」での学習は、教師データの用意が不要(自己教師あり学習)な場合が多く、データを集めやすい
- すでに他人が作った基盤モデル(例:言語・画像・音声)がオープンソースとして公開されており、流用できる
などで解決しています
モデルアーキテクチャ
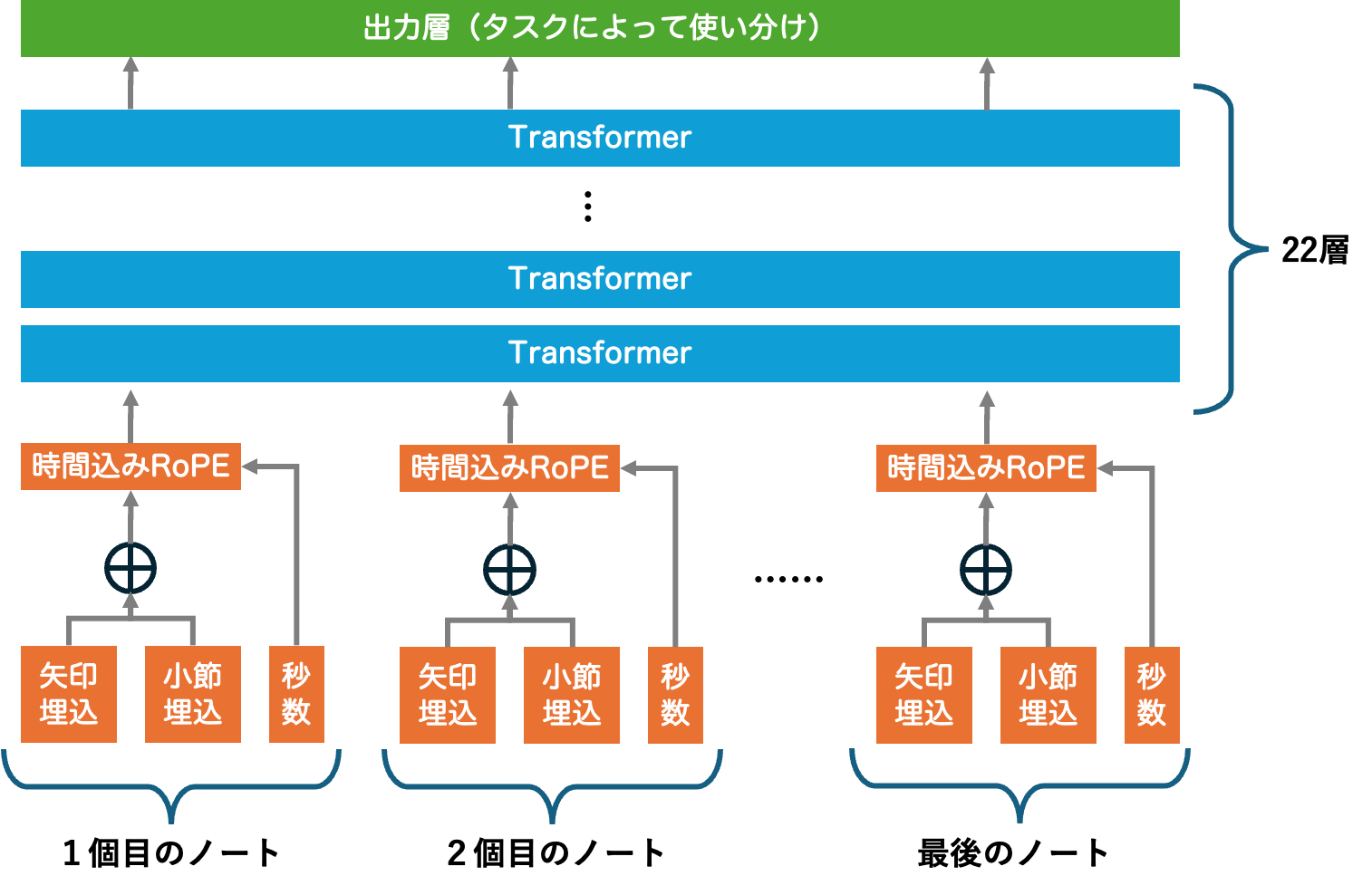
全体像としては、このような感じで構築しました
まず初めに、各ノートの情報を一本のベクトルにします(オレンジの部分)
その後、Transformer層を複数通すことでノート間の"文脈"を把握します
最後に出力層で、欲しい情報を取得させます
- 矢印埋め込み
- 小節埋め込み
- 時間込みRoPE
は自分の造語なので、それぞれ説明していきます
矢印埋め込み
DDRは上下左右の4種類のノートが流れることで譜面が構成されます
ノートはフリーズアロー(FA)という押っぱなしを要求するものや、ショックアロー(SA)という特定の時間は全てのパネルを踏んではいけないギミックがあります
そのため、「左下上右通常ノート」と「左下上右FA」と「SA」の計9次元のベクトルで表現しました
具体的には

といった感じです
FA開始は「通常ノート」「FA」のフラグを両方たて、FA中は「FA」のフラグのみ立てるようにします
また、FA終了はあまり難易度に貢献しなそうなため記録しません
この9次元のベクトルに対し、全結合層を通したものを矢印埋め込みとしています
小節埋め込み
このノートが何小節目に表れるかの表現を取得します
ここでの小節は、小数も取り得るように拡張しています
例えば、3小節目の四分ノートはそれぞれ2, 2.25, 2.5, 2.75, 3となります
この何小節かのデータを埋め込みとして一本のベクトルにしていきます
ここで、小節の絶対位置と相対位置や、BPMの倍とり・半とりを踏まえた上でベクトルにしていきたいです
そのため、
\begin{align}
\boldsymbol{e} &= W \mathrm{concat}(\boldsymbol{e}_1, \boldsymbol{e}_2, \cdots \boldsymbol{e}_i \cdots)
\\
\boldsymbol{e}_i &= \left[\sin \frac{2\pi}{2^{9-i}}\frac{x}{2}, \cos \frac{2\pi}{2^{9-i}}\frac{x}{2}, \sin \frac{2\pi}{2^{9-i}}\frac{x}{3}, \cos \frac{2\pi}{2^{9-i}}\frac{x}{3}\right]
\end{align}
という形でベクトルにしています
ここで $x$ はそのノートが何小節目かです
これには、absolute positional encodingの形で小節情報がエンコーディングされるという利点に加え、$i$ が大きい領域では見かけ上のBPMだけが倍になった場合も同じ値を返すようになります
DDRでは、曲によりBPMにばらつきが大きく(だいたい50~500ぐらい)、仮に同じ難易度だとしても、それにより譜面の密度が大きく異なってしまいます
また、曲中で突然BPMが倍・半分になるようなゲーム上の演出も多用されます
そのことから、そのような場合でも同じ値を返す成分と、そうでない成分の両方を持つような式をたて、高周波領域の表現力を高めました
分母の $2^9$ 部分は、最も小節数が多い曲でも一周しないような値として選定
$x/3$は三連符があるので作りましたが、いらないかも
時間込みRoPE
Transformer Encoderは全てのベクトル間を相互に参照するため、それ自体に方向や場所という概念はありません
そのため、「ここが何番目か」という場所の情報を最初に付与する必要があります
最近では、RoPEという場所でベクトルを回転させる手法がよく使われています
しかしDDRの場合、「高難易度曲の序盤の100コンボ目」と「低難易度曲の終盤の100コンボ目」では情報が異なり、場所による回転は筋が悪そうです
そのため、「開始何秒のノートか」という情報を元にベクトルを回転させました
具体的にはRoPEの回転角が時間に比例するように
\begin{align}
\begin{pmatrix}
x'_{2i} \\
x'_{2i+1}
\end{pmatrix}
&=
\begin{pmatrix}
\cos \omega_it & -\sin \omega_it\\
\sin \omega_it & \cos \omega_it
\end{pmatrix}
\begin{pmatrix}
x_{2i} \\
x_{2i+1}
\end{pmatrix}
\\
\omega_i &= \frac{2\pi}{t_{min}\cdot(t_{max}/t_{min})^{2i/d}}
\end{align}
としています
この式は、回転周期を $t_{min}$ から $t_{max}$までをログスケールで等分割させています
なので、 $t_{min}$ は表現できる高周波の分解能、 $t_{max}$ は低周波の分解能です
DDRの公式譜面では、最大で秒間20回ほどステップを踏む必要があります
逆に言えば、それよりも高周波の情報を表現できる必要はありません
そのため、$t_{min}$ は1/20より数倍小さい0.01秒としました
また、DDRの公式譜面は長い曲でも2分台で終わります
そのため、 $t_{max}$ はそれより数倍長い360秒としています
Transformer層
具体的なアーキテクチャ・パラメータなどはmodernbert-baseを参考にしています
- LayerNormalization : 各ベクトルの平均・分散を適切な値にするよう線形変換する。これによりレイヤーを重ねても値の発散・収束が起こりにくくなり学習が安定
- Multi-Head Self-Attention : 各ベクトルをもとに加重平均で別のベクトルをつくる処理。異なる重み付けを複数用意し最終的にそれらを結合させる(Multi head)。離れたノートの情報を統合したベクトルが作れる
- 残差接続 : 変換前後の足し算。変換操作が差分だけを考えるようになるため学習が安定
- FeedForwardNetwork : 全結合 → GeGLU → 全結合
Transformerの詳しい解説は、別の場所で色々とされているので、適宜論文など読んでください
パラメータは
- 層の数 : 22
- 次元数 : 768
- ヘッド数 : 12
です
「こんなに層増やさなくても......」と思うかもしれませんが、事前にpretrainなしのモデルで層と精度を検証したら単調に増加しました
頭打ちにならなかったので、もっと増やしてもいいかもしれません
データセットについて
DDRにはstepmaniaという類似のフリーゲームがあり、ユーザーがサイトに譜面を公開することで、その譜面を遊ぶことができます
今回は、その公開された譜面をベースにモデルを構築していきます
具体的なデータセットについては、先行研究を参照
これらの公開された譜面は、DDRに準拠する形での難易度設定・譜面になっているもの(便宜上以降は公式譜面と呼びます)もあれば、各個人が自由に投稿した譜面(以降は非公式譜面と呼びます)もあります
非公式譜面は公式譜面に比べデータサイズが多いのですが、その反面、質には問題があります
- 各投稿者が自由に難易度をつけるため、一貫した難易度が付与されていない
- 公式譜面にはない独自ギミックがある(トリルや3つ以上の同時押しなど)
- 公式譜面と見比べると、尺が長すぎる・ノート(矢印)数が多すぎる
一つ目は、同じ投稿者の曲なら対比には使えそうです
一方後半の2つは、既存の(DDR公式の)難易度の範疇外になるので、これを用いるのはノイズになりそうです
そのため、基盤モデルを作る事前学習・ファインチューニングのための対照学習・ファインチューニングのための教師あり学習の3種類の用途ごとにデータを使い分けました
(対照学習とは2つのデータ間の値の差分を大きく・小さくするような学習方法のことです。後で詳しく説明します)
| 学習 | データ数 | 公式 非公式 |
独自 ギミック |
長尺 | 膨大な ノート |
備考 |
|---|---|---|---|---|---|---|
| 事前 | 446,852 | 非公式も | あり | あり | なし | - |
| 対照 | 211,399 | 非公式も | なし | なし | なし | 同じ曲に2つ以上の難易度があるもの |
| 教師あり | 7,442 | 公式 | なし | なし | なし | - |
ここで、膨大なノートの譜面を全てのデータセットから除外したのは、リズムゲームの譜面が可変長配列であるため、計算リソースを抑えることが目的です
公式譜面の最大ノート数が1000ちょっとだったため、ノート数の上限は1024としています
加えて、DDRの譜面は左右・上下を入れ替えてもそこまで大きくは変わらないです。
そのため、データの水増しとして学習時は、50%の確率で左右を入れ替え、50%の確率で上下を入れ替えをしています
基盤モデル学習について
MLMを参考に、一部のノートを隠しそれを当てさせる学習を行いました
マスク率はmodernbertを参考に30%としています
具体的には、各譜面において30%のノートを選び、ノートの矢印情報をゼロベクトル([0,0,0,0, 0,0,0,0, 0])に置き換えます
その上で、Transformerの最後に9次元ベクトルを返す線形層を追加
それをlogitとする多値分類問題として、削除した30%のノートを当てるよう学習を行います
損失関数は交差エントロピーを用いました
ファインチューニングについて
難易度
DDRの難易度は1から19までの19段階表記です
これはカテゴリ変数と解釈もできますが、今回は連続変数として回帰モデルを解いていきます
これは、難易度がより連続値を取ることで、「これ12.4と推論されたから、Lv12の割に難しいな」や「公式の難易度は16なのに、15.7と出ているから少し簡単そう」などを知ることができ、いわゆる詐称・逆詐称を見抜けて嬉しいというモチベーションがあります
モデル
ファインチューニングはTransformerレイヤーの先に
\begin{align}
\boldsymbol{h}_{mean} &= W_{meam}\mathrm{meanpool}(\boldsymbol{h}_{1}, \boldsymbol{h}_{2}, \cdots)
\\
\boldsymbol{h}_{sum} &= W_{sum}\mathrm{sumpool}(\boldsymbol{h}_{1}, \boldsymbol{h}_{2}, \cdots)
\\
\boldsymbol{h}_{max} &= W_{max}\mathrm{maxpool}(\boldsymbol{h}_{1}, \boldsymbol{h}_{2}, \cdots)
\\
z &= \boldsymbol{w}^T\mathrm{concat}(\mathrm{tanh}\boldsymbol{h}_{mean}, \mathrm{tanh}\boldsymbol{h}_{sum}, \mathrm{tanh}\boldsymbol{h}_{max}) + z_0
\\
y &= 20\mathrm{sigmoid}(z)
\end{align}
を加えることで計算しています
ここで ${h}_{1}$, $h_2$, ...は各ノートごとの最終Transformerレイヤーの出力です
それにたいし、集約関数として平均化・総和・最大値をとっています
これは、
- meanpooling : 平均の難易度寄与
- sumpooling : スタミナ切れなどの物量に比例する難易度寄与
- maxpooling : 曲中の難所区間による難易度寄与
を意識しています
(本当に効果あるかは検証してないです)
次に活性化関数 $\tanh$ を通した後に全結合層を通すことで難易度情報 $z$ を取得しています
$\tanh$ の理由ですが、最大1000個のベクトルを総和する関係上、値域が上下ともに有界なものを選びました
最大・最小値(19, 1)付近では勾配が適切に計算されないおそれはありますが、ここに属するデータが少ないので多分問題ない気がしています
最後に、20倍のシグモイドにすることで、実際の値域[1,19]に近い値にしています
損失関数
ここでは、教師あり学習と対照学習それぞれでデータセット・損失関数を用意し、同時に学習を行いました
教師あり学習としては、$y$ に対する教師データと差の二乗平均であるMSEを採用しました
一つの曲に対し複数の異なる難易度が付けられている曲があります
これらのデータは、たとえ難易度のつけかたに作成者のバイアスが強く乗っていたとしても大小関係は信頼できるものが多いと予想できます
対照学習として、これらのデータの大小関係を学習させました
具体的には、ヒンジロスの形で、同じ曲の高難易度譜面の出力を $z_+$, 低難易度譜面の出力を $z_-$としたとき、
\tau\cdot\mathrm{max}\left(\epsilon-z_+ + z_- -, 0 \right)
を最小化させるように学習させます
最近ではsoftplusの方が主流ですが、 $z_+ - z_->\epsilon$ を満たしているときにlossを発生させたくなかったのでヒンジロスを選びました
今回は、$z_+, z_-$ 間で公式難易度1つ以上は変わっていそうと仮定し、$\epsilon=1$ としました
どうやって作ったか: 実装編
データ整形について
stepmaniaの譜面はsimfile(拡張子は.sm)という拡張子で管理されます
他の拡張子もあるようなのですが、DDR公式にないギミックが増えること、.smに比べて少ないことから除外しました
これをpython上で扱うライブラリとして、simfileというものがあり、今回はそれでデータ整形しました
これは、ノートの状態やこの時の時間・BPMなども簡単に求めることができ、使いやすかったです
モデルを回す上での工夫
基盤モデルを作るとなると
- モデルサイズが大きい
- 大きめのバッチサイズを要求される
- 計算時間が長い
などの、計算リソースの問題がでてきます
クラウドでA100などのつよつよGPUを借りるのも手ですが、以前30万請求されたトラウマがあるので、今回は私物のゲーム用GPUで学習を行いました
そのため、計算リソース・計算速度を改善するのに使った小手先のテクニックを紹介していきます
ちなみにライブラリはTorch・Trainerを使っています
Attentionの全結合を減らす
Attentionは全てのノート間の相互作用を計算するので、計算時間はノート数の2乗に比例します
そのため、計算時間のボトルネックはAttentionの処理になりがちです
ここの時間を早くするために、全ノート同士の計算は4層にごとにし、それ以外は近くにノートのみの相互作用を考えるように変更しました
データセットをストレージから逐次読み込む
学習では、データセットとして10万件以上の可変長配列データを用います
当然、それらはメインメモリにすらのらないので、ローカルのデータを逐次データセットとして読み込ませます
class DDRDataset(Dataset):
def __init__(self, ...) -> None:
# 中略
def __getitem__(self, index: int) -> Dict[str, torch.Tensor]:
path_supervised = self.path_map_supervised[index]
df_supervised = pd.read_parquet(path_supervised)
path_contrastive = self.path_map_contrastive[index]
df_contrastive = pd.read_parquet(path_contrastive)
return {
"x": df_supervised.x,
"time": df_supervised.time,
"cycle": df_supervised.cycle,
"y": df_supervised.y,
"x_plus": df_contrastive.x_plus,
"time_plus": df_contrastive.time_plus,
"cycle_plus": df_contrastive.cycle_plus,
"x_minus": df_contrastive.x_minus,
"time_minus": df_contrastive.time_minus,
"cycle_minus": df_contrastive.cycle_minus,
}
こんな感じです
Dataloaderの別スレット化
データセットをストレージから逐次読み込む場合、各バッチが回り終わった後、データを読み込む処理に時間がかかります
そのため、そこの処理を別スレットに回すようにしています
自分は、GPU稼働率が100%に張り付かないとき、この設定をオンにするようにしています
実装方法は、TrainerのTrainingArgumentsで dataloader_num_workers={2以上・CPU数-1が目安} すればOKです
ただし、ipynbで学習するときはスタックします
半精度 bfloat16
データ精度を半分に落とすことで、VRAMの消費を減らすことができます
また、精度もそこまで大幅には下がることがないと知られています
半精度としては、torch.float16とtorch.bfloat16があります
bfloat16の方が新しく、新し目のGPUであるなら、同じメモリ消費量でより精度が優れた学習・推論ができると知られています
実装方法は、TrainerのTrainingArgumentsで bf16=True, fp16=False すればOKです
gradient checkpoint
勾配蓄積
勾配に基づいたパラメータの更新を見送ることで、実質的なバッチ数を増やす処理です
今回のような大規模で層が多いモデルは、ある程度のバッチ数がないと学習が安定しません
一方で大規模なモデルでは、計算リソースの都合でバッチ数を小さくせざるおえないです
勾配蓄積を使うことで、その2つの問題を解決できます
実装方法は、TrainerのTrainingArgumentsで gradient_accumulation_steps={2以上の数字} すればOKです
gradient checkpoint
勾配情報を一部しか保存せず、勾配計算時に再度計算させることで、VRAMを節約する機能です
その代わりに、計算時間が少し長くなります
実装方法は、TrainerのTrainingArgumentsで gradient_checkpointing=True することです
VRAMの解放
ファインチューニング時は2つのデータセット、3つの譜面をそれぞれVRAMに載せます
3つともノートが多い譜面を取ることがあるため、場合によっては大きなVRAMになり、共有メモリに侵食することがあります
モデルが共有メモリに侵食すると、モデルの計算速度が落ちるため、バッチ終了時にVRAMの解放を行なっています
結果
validationデータのRMSEは0.73となりました
なお、推論時は上下・左右を入れ替えた $z$ の平均から値を算出してます
各難易度別の箱ヒゲ図はこんな感じです
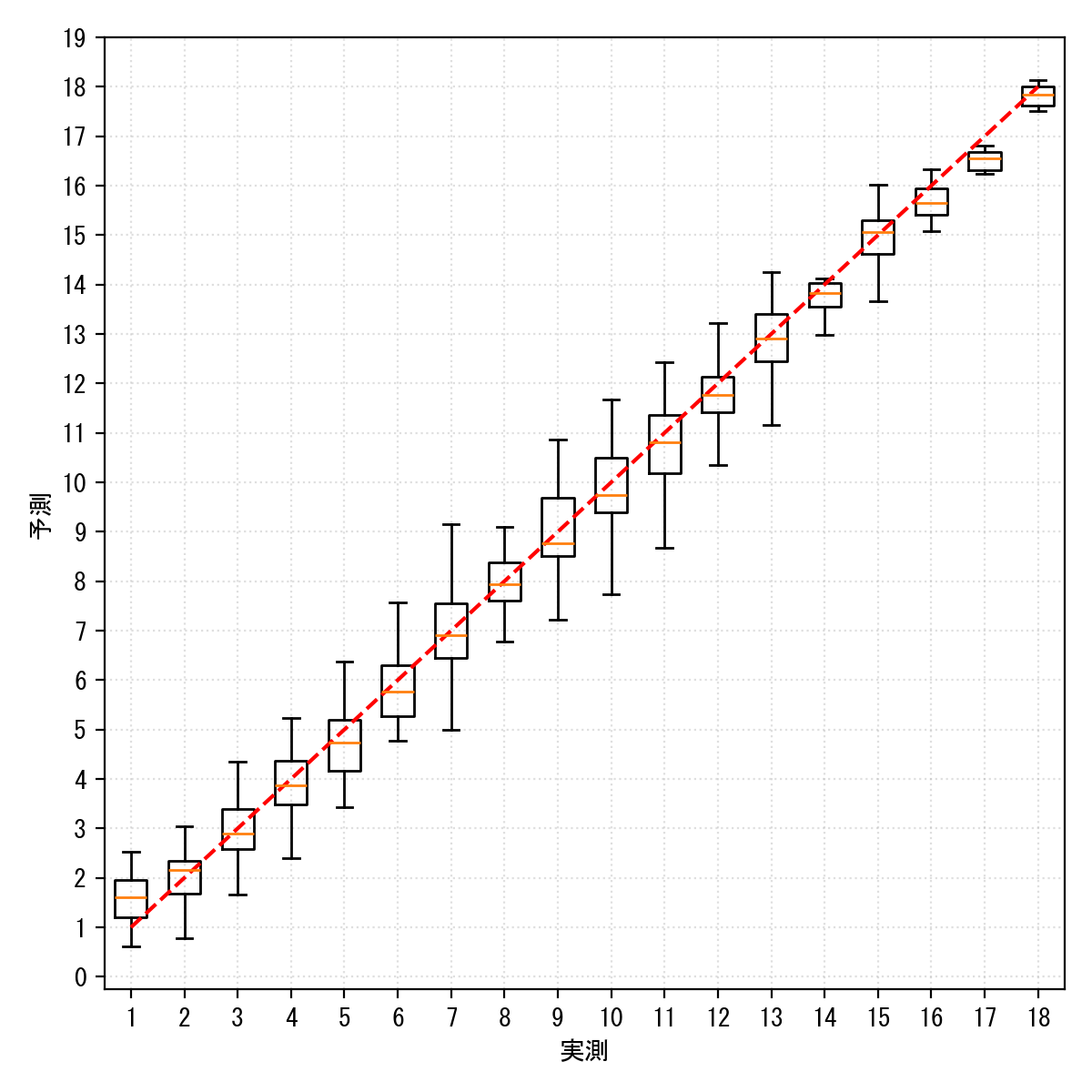
外れている値はあるものの、四分位点は難易度 $\pm 0.5$ に収まっており、そこそこなモデルができたのかもしれません
感想
ニッチだけど十分にデータがある、けど質の高いデータは少数という特殊な状況だったため、基盤モデルを一人で作る羽目になりました......
モデルが回り切るまで数週間かかるので、それまでPCをさわれないのが辛かったです
ですが、実験で基盤モデルなしで回したときに比べ、lossのおちがよくなり、基盤モデルの重要性を再確認できました
モデルのアーキテクチャ周りでは、譜面停止がモデルで入れなかったのが気がかりです
今思うと、ショックアローと同じ形で、ノートの形でモデルに入れると良かったかも......
あと、BPM・ステップの踏む時間・ステップの小節数のうち2つが分かれば残りのひとつが自然ともとまるので、BPMをモデルに入れなかったのですが、多少冗長でも入れたほうが精度が良くなるかもしれません
この記事はドワンゴ Advent Calendar 2025の17日目になります。
ですが、この記事は100%趣味で作成しており、会社の方針・業務とは無関係です