宣伝
「おしゃべり魔理沙AI」という霧雨魔理沙とおしゃべりできるline-botを作りました。
よかったら遊んでみてください。

- linebotのurl
- linebotの運営用Xアカウント
作者のお財布事情とlinebotとの兼ね合いにより、通算で月200回しか使えないです。
「動かないな」と思ったら、そういうことです。
赤字垂れ流しなので許してください。
概要
ローカルLLMをファインチューニングして、東方projectというゲームに出てくる霧雨魔理沙とおしゃべりできるlinebotを作りました。
Qiitaの記事としては「①モデル編」と「②linebot編」の2つになります。
「②linebot編」のリンクはこちら
「①モデル編」では「おしゃべり魔理沙モデル」の作り方について説明していきます。
作成したモデル自体はhuggingface上に公開しているのでよければ遊んでみてください。

詳細
LLMから思い通りの出力を得る手法として、現実的な手法では
- プロンプトエンジニアリング
- ファインチューニング
が挙げられます。
プロンプトエンジニアリングはモデルに手を加えずにプロンプトにいれる文章を工夫することで思い通りの出力を得る手法です。
Chat-GPTやGPT-4、llama-2などのとんでもなく大きいモデルで有効なものの、そこまで大きくないモデルでは、そこまでの精度は期待できません。日本語ローカルLLMに関しては現状そこまで大きなモデルも出ていないため、使用を見送りました。
ファインチューニングは手持ちの小規模のデータを用いることで、一度学習されたモデルを追加で学習させる手法です。
データセットを用意する手間や、学習させる手間はありますが、日本語ローカルLLMでも十分に機能します。
今回は、このファインチューニングを使うことで、既存のモデルを改造して「おしゃべり魔理沙モデル」を作っていきます。
LLMをファインチューニングするにあたり、問題となるのは
- モデルをどうするか
- データセットをどうするか
- 学習方法をどうするか
- 推論方法をどうするか
の4点が挙げられます。
それぞれについて次節以降で説明していきます。
モデルをどうするか
instruction tuningの有無に関して
LLMはinstruction tuning有無で分類できます。
本来の素のモデル(instruction tuningなしモデル)は、文章の続きをかくモデルです。
これに対して、質疑応答データセットなどで追加学習を行い、質問により正確に答えられるよう学習したのがinstruction tuningモデルです。
「おしゃべり魔理沙モデル」では両方試しましたが、応答の精度にそんなには差がない印象でした。
若干、instruction tuningモデルの方が応答が長くなる傾向があったので、あれば使うくらいの印象です。
どのモデルがいいのか
2023年9月現在の主な日本語ローカルLLMは下表のとおりです。
| モデル名 | パラメータ数 | 商業利用 | instruction tuning | 特記事項 |
|---|---|---|---|---|
| weblab-10b | 100億 | 不可 | あり | 英日モデル |
| ELYZA-japanese-Llama-2-7b | 70億 | 可 | あり | 英語モデルをファインチューニングしたもの |
| japanese-stablelm-base-alpha-7b | 70億 | 一部可 | あり | instruction tuningは商業利用できない |
| open-calm-7b | 70億 | 可 | なし | |
| japanese-novel-gpt-j-6b | 60億 | 可 | なし | 小説用モデル |
| bilingual-gpt-neox-4b | 40億 | 可 | あり | 英日モデル |
| japanese-large-lm-3.6b | 36億 | 可 | あり | |
| japanese-gpt-neox-3.6b | 36億 | 可 | あり |
weblab以外はすべてファインチューニングして試しました。
結果として、キャラのなりきりに関して言えば「japanese-novel-gpt-j-6b」が一番精度が良かったです。
理由としては、恐らく小説で学習されているため、キャラクターの口調に適用し易いのだと思います。
次点で「japanese-stablelm」も良かったです。
これも、AIのべりすとから提供されたデータセットを用いているからだと思います。
データセットをどうするか
データセットの整形方法
文章の中から、会話文のみを抜き出し
魔理沙:おはよう
霊夢: おはよう。今日もいい天気ね
魔理沙: そうだな
のような[発言者]: [発言内容][改行記号]というフォーマットに統一しました。
データセットの水増し方法
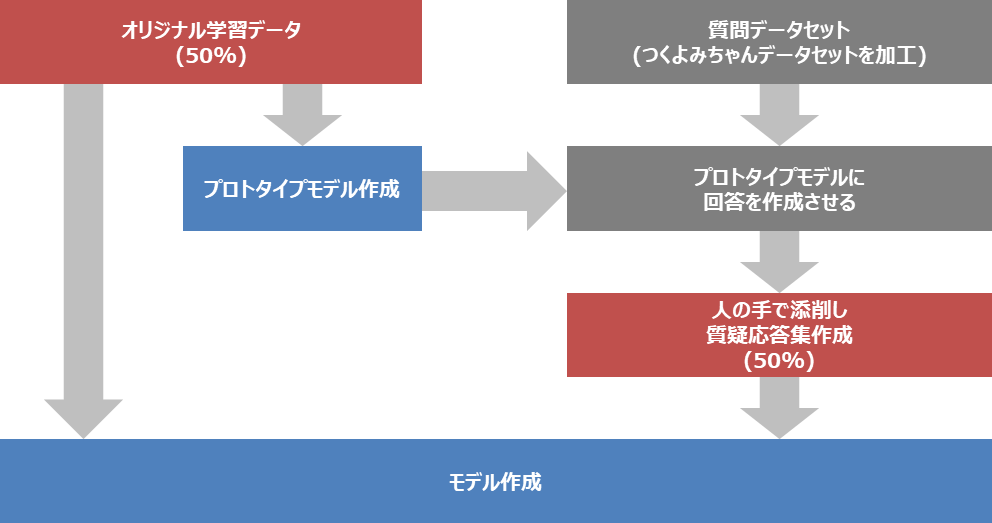
データの分量が心もとなかったため、この図のような流れでデータセットの水増しを行いました。
手順としては
- オリジナル学習データを基にプロトタイプモデルを作成
- プロトタイプモデルに質問データセットを投げることで回答を取得
- 回答を人の手により添削
- オリジナル学習データと回答から作ったデータを併せてモデルに学習
となります。
ChatHaruhiという論文では、プロトタイプモデルのところをChatGPTにやらせていました。
多分そちらのほうがいい精度が出る気がしますが、OpenAIの利用規約的にグレーだったので控えました。
学習方法をどうするか
QLoRAについて
LLMは数十億やそれ以上のパラメータをもつため、これを愚直にファインチューニングすることは、なかなか庶民には厳しいものです。
そのため、必要なパラメータ数やメモリ量を削ることで、そこそこのスペックのPCでもファインチューニングできるようにする必要があります。そのための代表的な手法がQLoRAです。
QLoRAとは「量子化(Q)」+「行列分解による低ランク学習(LoRA)」のことです。
量子化によりパラメータのデータの取り方を荒くし、低ランク学習によりパラメータ数を少なくしています。
この辺はすでに色々な解説記事があるため、そちらを参照していただければと思います。
学習対象について
今回のモデルでは、魔理沙の発言でのみ学習させ、それ以外の箇所では損失関数を計算させないようにします。
具体的にいうと
魔理沙: おはよう
霊夢: おはよう。今日もいい天気ね
魔理沙: そうだな
上の例の場合は、太字の箇所のみ損失関数を計算させるようにします。
そのために、太字以外のデータセットのlabelsを-100にする必要があります
(labelsというのは推論における正解データであり、labels=-100が損失関数計算させないよーというサインとなっている)
これを実現するために「魔理沙: 」と「[改行記号]」で挟まれた領域以外全て-100となっているlabelsを作成してあげます。
start_token = [25197, 326,] # 魔理沙
end_token = [32001] # 改行記号
def target_grad(vec,start=start_token,end=end_token,negative_token=-100):
vec = copy.deepcopy(vec)
#start
itrs_start = []
delta_start = len(start)
for itr in range(len(vec)-delta_start+1):
if vec[itr:itr+delta_start]==start:
itrs_start.append(itr+delta_start)
# end
itrs_end = []
delta_end = len(end)
for itr in range(len(vec)-delta_end+1):
if vec[itr:itr+delta_end]==end:
itrs_end.append(itr+delta_end)
# end_startと紐づけ
itrs_end_new = []
for itr_start_0,itr_start_1 in zip(itrs_start,itrs_start[1:]+[1e10]):
for itr_end in itrs_end:
if itr_start_0 < itr_end and itr_end<itr_start_1:
itrs_end_new.append(itr_end)
break
# 間に挟まれているか判別
for itr in range(len(vec)):
for itr_start,itr_end in zip(itrs_start,itrs_end_new):
if (itr_start <= itr) and (itr<itr_end):
break
else:
vec[itr]=negative_token
return vec
train_data = [tokenize(text, tokenizer) for text in データセット]
for i in range(len(train_data)):
train_data[i]["labels"] = target_grad(train_data[i]['input_ids'])
推論方法をどうするか
LLMというのは文章の続きを書いてくれるモデルです。
そのため、魔理沙の発言を取得したい場合は、「その発言」が文章の続きとなるような文をプロンプトに入れればいいわけです。
例えば、ユーザーが「おはよう」といったときの魔理沙の応答が見たい場合は
ユーザー: おはよう
魔理沙:
とプロンプトに入れるとモデルが続きを書いてくれます。
ただし、このままでは
ユーザー: おはよう
魔理沙: おはよう。今日もいい天気だな。
ユーザー: そうだね。それにしても顔色いいけどなにかあった?
魔理沙: それは...
...
といったふうに永遠と続きを書いてしまいます。
そのため、eos_token_id(このトークンが出ると文章が打ち切りになるサイン)に改行記号をいれます。
ユーザー: おはよう
魔理沙: おはよう。今日もいい天気だな。
で応答が止まります。
最後に、自分の使っているサンプルコードを載せます。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, useFast=True)
ret_token = tokenizer("[SEP]", truncation=True, add_special_tokens=False)['input_ids'][-1] # 改行記号
bra_token = tokenizer("(", truncation=True, add_special_tokens=False)['input_ids'][-1]
space_token = tokenizer(" ", truncation=True, add_special_tokens=False)['input_ids'][-1]
def generate(text,input=None,maxTokens=512):
prompt = prompt_conversation(f"ユーザー: {text}[SEP]魔理沙: ")
input_ids = tokenizer(prompt,
return_tensors="pt",
truncation=True,
add_special_tokens=False
).input_ids.cuda()
with torch.no_grad():
outputs = model.generate(
input_ids = input_ids,
max_length=maxTokens,
do_sample=True,
temperature=0.1,
top_p=0.9,
top_k=20,
no_repeat_ngram_size=2,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id,
bad_words_ids=[[bra_token]], # このトークンを出力に使わない
eos_token_id = [tokenizer.eos_token_id,ret_token,space_token] # このトークンが出たら出力を打ち切る
)
outputs = tokenizer.decode(outputs.tolist()[0][input_ids.size(1):],skip_special_tokens=True)
return outputs.replace("\n","")
まとめ
LLMをファインチューニングしてキャラクターと対話する手法についてまとめました。
次回はこれをどうlinebotにしたかについて説明しておりますので、よければ御覧ください。