はじめに
「日本の伝統文化」と「AI」
「一見合わなそうだが、合わせたら面白そう・・・」
といった感じで、どちらにも興味を持った私からすると自然な成り行きで、
「日本の伝統文化 ✖ AI」
をテーマとした人生初のAIアプリを作ることとなりました。
Aidemy Premium「AIアプリ開発講座」の最終課題として作成・公開しています
読者対象:機械学習、ディープラーニング初心者
アプリの概要
「日本の伝統模様」を識別する画像認識WEBアプリ

ざっと調べると28種くらい日本の伝統模様が存在する。写真はその一部。
ミッション
「AIの力で日本の伝統文化をもっと身近に」
私のスペック
40代、妻子持ち、文系出身、Progate独学挫折レベル
目次
1. 実行環境などの基本情報
2. 実際作ったアプリ(成果物)
3. 学習モデルの作成
4. アプリの実装
5. まとめ、考察
6. 今後
1. 実行環境などの基本情報
- 実行環境
- CPU:Apple M1
- ブラウザ:Chrome
- Google Colab(T4 GPU)、Visual Studio Code
- Python 3.7.6
- ディープラーニング ライブラリ:TensorFlow
- その他ライブラリ:NumPy、Matplotlib、Flaskなど
- デプロイ:GitHub→Render
- 開発上の制約
- GitHubプッシュ制限:1ファイル100MB以下
(※後日談:Git LFSというやつを使えば無料でもっといけるらしい)
- GitHubプッシュ制限:1ファイル100MB以下
-
検証データ正解率目標
validation accuracy >=90% - 転移学習で使用したCNNモデル:VGG16
- お世話になった面々(感謝)
- Aidemyチューター
- ChatGPT3.5、GeminiなどのLLMチャットボット
- 先人たちの技術ブログ
- アプリ開発期間(実績)
- 構想からデプロイまで:約3週間
2. 実際作ったアプリ(成果物)

全ての模様という訳にはいきませんでしが
上の6種類に関しては、、、
validation accuracy = 94.1%
と、目標の検証データ正解率90%を上回る学習モデルの性能を出すことに成功しました。
※試しにページの画像(模様)をどれでもいいから自分のPCへコピーしてから
ファイルを選択でアップロードして、識別ボタンを押してもらえると回答がでます。
3. 学習モデルの作成
学習モデルの作成は、以下の手順で進めました。
(全てGoogle Colab上で実行)
3-1. データ収集(スクレイピング)
3-2. データの前処理(クレンジング)
3-3. モデルの実行
まずはデータ収集です。
3-1. データ収集(スクレイピング)
学習用に使用する画像たちを、これからせっせとGoogleドライブに保存していく訳ですが、
その前に「Googleドライブをマウントする」という作業が必要です。
これを実行するとGoogle ColabからGoogleドライブへアクセスできるようになります。
from google.colab import drive
drive.mount('/content/drive')
次に、実際に画像をインターネット上から収集する作業に入ります。 どうもicrawlerというPython便利ライブラリがあるようなので、 そちらを使ってGoogleドライブに画像データを保存していきます。(以下コード抜粋)
#必要な機能のインストール
!pip install icrawler
#pythonライブラリの「icrawler」でBing用モジュールをインポート
from icrawler.builtin import BingImageCrawler
search_word = "青海波 模様"
#ダウンロード先を指定
crawler = BingImageCrawler(storage={'root_dir': "/content/drive/MyDrive/Aidemy/dataset/SEIGAIHA"})
#ダウンロード最大数:500枚
crawler.crawl(keyword=search_word, max_num=500)
search_word = "麻の葉 模様"
#ダウンロード先を指定
crawler = BingImageCrawler(storage={'root_dir': "/content/drive/MyDrive/Aidemy/dataset/ASANOHA"})
#ダウンロード最大数:500枚
crawler.crawl(keyword=search_word, max_num=500)
集まった画像たち。
写真は矢絣(やがすり)という日本の伝統模様。

今回、入手するデータ数を最大500枚と指定しましたが、
各模様140〜330枚程度しか集まりませんでした。
色々調べてみると、下記の原因が考えられるようです。
- ウェブサイト側の制限
- 画像の利用制限
- そもそも内容がニッチなので画像が少ない、等
次はデータクレンジングです。
3-2. データ前処理(クレンジング)
モデルが正しく学習して一人前になれるよう、愛情を込めてクレンジングを行います。
行なったことは以下の通り。
- あまりに模様が歪んでいて人間でも模様を識別できない写真は削除
- ぱっと見、写真の中に模様意外の要素(着物や人間など)が大きい場合も
編集時間を考慮し思い切って削除 - たまに模様じゃない写真(文字だけなど)が入っているので当然それも削除
一通り削除をした後、
- なるべく模様だけ映るように画像をクロップ
- 次の機械学習モデリング工程で画像が正方形にリサイズされても
模様が歪まないよう画像を正方形にクロップ
といったような画像の編集を行い、データの品質向上に努めました。
正直ここが一番地味で時間ばかりが過ぎていった記憶があります。
こちらはクレンジングした後の矢絣(やがすり)模様です。

全28模様のデータクレンジングを行なった結果、
矢絣に関しては83枚、他の模様に関してもMAXで125枚、MINで5枚
という、あまり教育上良くない数値となってしまいました。
このように、最終的にはかなり手間暇かけてデータクレンジングを行いましたが、
最初からその必要性に気づいていた訳ではありませんでした。
実際には次の学習モデルを作っていく中で、
その必要性を突きつけられました・・・
3-3. モデルの実行
a. トライ&エラー
とりあえず奇跡を信じて全28模様の状態でモデルを実行してみます。
・・・失敗です
以下は結果詳細です。
(1243, 50, 50, 3)
(1243,)
(533, 50, 50, 3)
(533,)
Epoch 1/30
39/39 [==============================] - 56s 1s/step - loss: 51.0025 - accuracy: 0.0587 - val_loss: 12.4801 - val_accuracy: 0.1388
Epoch 2/30
39/39 [==============================] - 55s 1s/step - loss: 29.8298 - accuracy: 0.1038 - val_loss: 7.6184 - val_accuracy: 0.2176
Epoch 29/30
39/39 [==============================] - 54s 1s/step - loss: 3.7133 - accuracy: 0.1810 - val_loss: 3.0591 - val_accuracy: 0.1989
Epoch 30/30
39/39 [==============================] - 48s 1s/step - loss: 3.7730 - accuracy: 0.1778 - val_loss: 3.0560 - val_accuracy: 0.1970
validation loss:3.056041717529297
validation accuracy:0.19699811935424805
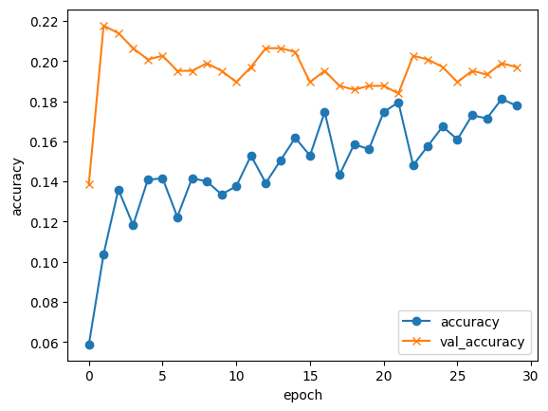
こんな感じでモデルを実行するとGoogle Colab上に結果が表示されるのですが、
validation accuracy:0.19(19%)なので目標には程遠く、最初は全然ダメでした・・・
ここから怒涛のトライ&エラー祭りとなりますが、
お見苦しいのでダイジェストでお送り致します。
| Try | validation accuracy | 模様数 | 画像サイズ | epoch |
|---|---|---|---|---|
| 01 | 0.19699811935424805 | 28 | 50x50 | 30 |
| 02 | 0.24017466604709625 | 18 | 50x50 | 30 |
| 03 | 0.42574256658554077 | 4 | 50x50 | 30 |
| 04 | 0.5742574334144592 | 4 | 60x60 | 30 |
| 05 | 0.6336633563041687 | 4 | 100x100 | 30 |
| 06 | 0.603960394859314 | 4 | 85x85 | 30 |
| 07 | 0.6435643434524536 | 4 | 70x70 | 30 |
Try_02の結果を見て、「こりゃだめだな」と見切りをつけ
大胆に模様数を減らしています。
そしてTry_07の結果を見て、
「もしかして画像の品質?」
「リサイズで模様の比率を歪めてる?」など
遠くを見つめながら考え始めます。
そして、試しに前述の方法で2種類の模様にデータクレンジングやってみると、
| Try | validation accuracy | 模様数 | 画像サイズ | epoch | クレンジング済 |
|---|---|---|---|---|---|
| 08 | 0.8275862336158752 | 4 | 70x70 | 30 | 2模様 |
一気に上がりました。
残りの2種類の模様もクレンジングしていきます。
| Try | validation accuracy | 模様数 | 画像サイズ | epoch | クレンジング済 |
|---|---|---|---|---|---|
| 09 | 0.8999999761581421 | 4 | 70x70 | 30 | 4模様 |
四捨五入してここで強引に「目標90%クリア!」といきたいところですが、
ここまでの作業で私の心にこっそり灯された「AIエンジニア」の炎がそれを許しません。
模様を追加していきます。
ここから最後まで一気にいきます。
| Try | validation accuracy | 模様数 | 画像サイズ | epoch | クレンジング済 |
|---|---|---|---|---|---|
| 10 | 0.8461538553237915 | 5 | 70x70 | 30 | 4模様 |
| 11 | 0.8169013857841492 | 6 | 70x70 | 30 | 4模様 |
| 12 | 0.8529411554336548 | 6 | 70x70 | 30 | 6模様 |
| 13 | 0.845588207244873 | 6 | 70x70 | 40 | 6模様 |
| 14 | 0.904411792755127 | 6 | 70x70 | 50 | 6模様 |
| 15 | 0.9411764740943909 | 6 | 100x100 | 50 | 6模様 |
といった感じで、
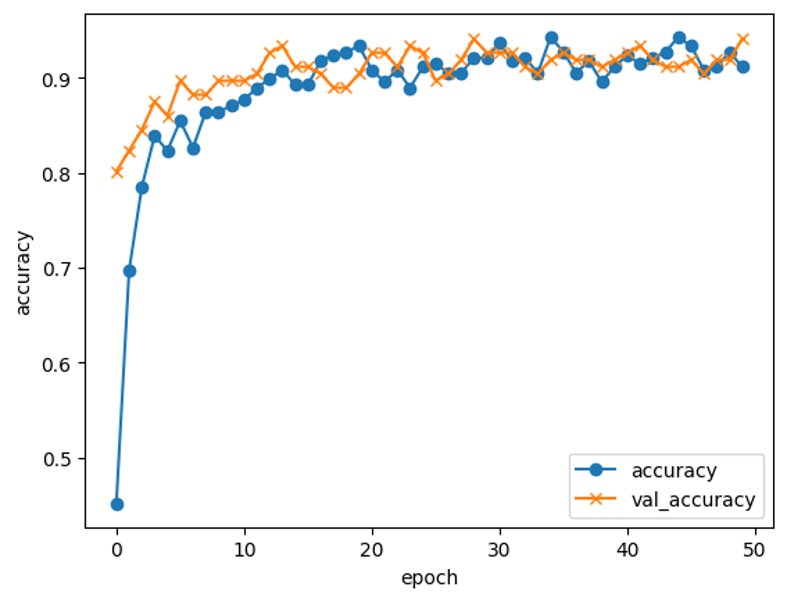
Try_15にて日本の伝統模様6種を
validation accuracy=94.1%の精度で識別できる学習モデルが完成
以下、Try_15の結果詳細です。
(317, 100, 100, 3)
(317,)
(136, 100, 100, 3)
(136,)
Epoch 1/50
10/10 [==============================] - 2s 84ms/step - loss: 1.6610 - accuracy: 0.4511 - val_loss: 0.8205 - val_accuracy: 0.8015
Epoch 2/50
10/10 [==============================] - 0s 50ms/step - loss: 0.9055 - accuracy: 0.6972 - val_loss: 0.5528 - val_accuracy: 0.8235
Epoch 49/50
10/10 [==============================] - 0s 51ms/step - loss: 0.2389 - accuracy: 0.9274 - val_loss: 0.2112 - val_accuracy: 0.9191
Epoch 50/50
10/10 [==============================] - 0s 50ms/step - loss: 0.2463 - accuracy: 0.9117 - val_loss: 0.2170 - val_accuracy: 0.9412
validation loss:0.21696993708610535
validation accuracy:0.9411764740943909
b. コード
今回の学習モデルで実行したコードです。
実行すると、model.h5という学習済みモデルが保存されます。
import os #osモジュール
import cv2 #画像や動画を処理するオープンライブラリ
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical #正解ラベルをone-hotベクトルで求める
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input #全結合層、過学習予防、平滑化、インプット
from tensorflow.keras.applications.vgg16 import VGG16 #学習済モデル
from tensorflow.keras.models import Model, Sequential #線形モデル
from tensorflow.keras import optimizers #最適化関数
from tensorflow.keras.preprocessing.image import ImageDataGenerator ### データの水増し
### Googleドライブ内の画像フォルダへのパスを変数へ格納
drive_SEIGAIHA = "/content/drive/MyDrive/Aidemy/dataset/SEIGAIHA/"
drive_SHIPPOU = "/content/drive/MyDrive/Aidemy/dataset/SHIPPOU/"
drive_SAYAGATA = "/content/drive/MyDrive/Aidemy/dataset/SAYAGATA/"
drive_YAGASURI = "/content/drive/MyDrive/Aidemy/dataset/YAGASURI/"
drive_SANKUZUSHI = "/content/drive/MyDrive/Aidemy/dataset/SANKUZUSHI/"
drive_SHIMA = "/content/drive/MyDrive/Aidemy/dataset/SHIMA/"
image_size = 100
### 画像フォルダから先頭に'.'のついた隠しフォルダを除いた全てのファイル名リストを取得
path_SEIGAIHA = [filename for filename in os.listdir(drive_SEIGAIHA) if not filename.startswith('.')]
path_SHIPPOU = [filename for filename in os.listdir(drive_SHIPPOU) if not filename.startswith('.')]
path_SAYAGATA = [filename for filename in os.listdir(drive_SAYAGATA) if not filename.startswith('.')]
path_YAGASURI = [filename for filename in os.listdir(drive_YAGASURI) if not filename.startswith('.')]
path_SANKUZUSHI = [filename for filename in os.listdir(drive_SANKUZUSHI) if not filename.startswith('.')]
path_SHIMA = [filename for filename in os.listdir(drive_SHIMA) if not filename.startswith('.')]
#画像を格納するリスト作成
img_SEIGAIHA = []
img_SHIPPOU = []
img_SAYAGATA = []
img_YAGASURI = []
img_SANKUZUSHI = []
img_SHIMA = []
### path_からファイル名を一個ずつ取り出して、画像読み込み→リサイズ→img_リストに追加していく作業
for i in range(len(path_SEIGAIHA)):
img = cv2.imread(drive_SEIGAIHA+ path_SEIGAIHA[i]) # ディレクトリ名とファイル名を合体させ、画像を読み込む
img = cv2.resize(img,(image_size,image_size)) # 画像をリサイズする
img_SEIGAIHA.append(img) # img_リストに追加
for i in range(len(path_SHIPPOU)):
img = cv2.imread(drive_SHIPPOU+ path_SHIPPOU[i])
img = cv2.resize(img,(image_size,image_size))
img_SHIPPOU.append(img)
for i in range(len(path_SAYAGATA)):
img = cv2.imread(drive_SAYAGATA+ path_SAYAGATA[i])
img = cv2.resize(img,(image_size,image_size))
img_SAYAGATA.append(img)
for i in range(len(path_YAGASURI)):
img = cv2.imread(drive_YAGASURI+ path_YAGASURI[i])
img = cv2.resize(img,(image_size,image_size))
img_YAGASURI.append(img)
for i in range(len(path_SANKUZUSHI)):
img = cv2.imread(drive_SANKUZUSHI+ path_SANKUZUSHI[i])
img = cv2.resize(img,(image_size,image_size))
img_SANKUZUSHI.append(img)
for i in range(len(path_SHIMA)):
img = cv2.imread(drive_SHIMA+ path_SHIMA[i])
img = cv2.resize(img,(image_size,image_size))
img_SHIMA.append(img)
### 画像データが少ないので「データの水増し」を実行
### データの水増し設定
datagen = ImageDataGenerator(
rotation_range=20, ### ±20度までの範囲でランダムに回転
width_shift_range=0.1, ### 画像の幅に対して±10%の範囲でランダムに水平方向にシフト
height_shift_range=0.1, ### 画像の高さに対して±10%の範囲でランダムに垂直方向にシフト
zoom_range=0.1, ### 画像を 0.9倍 から 1.1倍 の範囲でランダムに拡大・縮小する
horizontal_flip=True, ### 画像を水平方向にランダムに反転
vertical_flip=True ### 画像を水平方向にランダムに反転
)
### データの水増し実行
X_train_datagen = datagen.flow(np.array(img_SEIGAIHA), batch_size=32)
X_train_datagen = datagen.flow(np.array(img_SHIPPOU), batch_size=32)
X_train_datagen = datagen.flow(np.array(img_SAYAGATA), batch_size=32)
X_train_datagen = datagen.flow(np.array(img_YAGASURI), batch_size=32)
X_train_datagen = datagen.flow(np.array(img_SANKUZUSHI), batch_size=32)
X_train_datagen = datagen.flow(np.array(img_SHIMA), batch_size=32)
### 全てのデータを結合
X_train = np.concatenate([X_train_datagen[i][0] for i in range(len(X_train_datagen))], axis=0)
#np.arrayでXに学習画像、yに正解ラベルを代入
X = np.array(img_SEIGAIHA + img_SHIPPOU + img_SAYAGATA + img_YAGASURI + img_SANKUZUSHI + img_SHIMA)
#正解ラベルの作成
y = np.array([0]*len(img_SEIGAIHA) + [1]*len(img_SHIPPOU) + [2]*len(img_SAYAGATA) + [3]*len(img_YAGASURI) + [4]*len(img_SANKUZUSHI) + [5]*len(img_SHIMA))
label_num = list(set(y))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#学習データと検証データを用意
X_train = X[:int(len(X)*0.7)]
y_train = y[:int(len(y)*0.7)]
X_test = X[int(len(X)*0.7):]
y_test = y[int(len(y)*0.7):]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
#正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#Input関数を使用してモデルのテンソル(多次元配列)を定義
input_tensor = Input(shape=(image_size,image_size, 3))
#転移学習モデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの定義
#転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dropout(0.5))
top_model.add(Dense(256, activation="sigmoid")) #活性化関数シグモイド
top_model.add(Dropout(0.5))
top_model.add(Dense(len(label_num), activation='softmax'))
#vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#modelの19層目までがvggのモデル
for layer in model.layers[:19]:
layer.trainable = False
# 学習率を設定
learning_rate = 1e-4
# 最適化アルゴリズムを定義(SGD -> SGD(lr=learning_rate, momentum=0.9))
optimizer = optimizers.SGD(lr=learning_rate, momentum=0.9)
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# 学習の実行
#グラフ(可視化)用コード
history = model.fit(X_train, y_train, batch_size=32, epochs=50, verbose=1, validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#モデルを保存
model.save("model.h5")
ポイントとしては、データセットが各模様100枚前後と少なくなってしまった為、
その対策として以下2点を行なっている点です。
- ImageDataGeneratorによるデータの水増し
- VGG16による転移学習
c. ImageDataGenerator
ImageDataGeneratorはTensorFlowのモジュールで、
元の画像を回転、水平反転、垂直反転、ズーム、平行移動などすることによって
データの多様性を増やすことができます。これにより、データが少なくても
過学習を減らし、モデルの汎化性能を向上させることができます。
TensorFlowの公式ドキュメントによると、たくさん引数があるようなのですが、
私は以下の引数を使いました。
datagen = ImageDataGenerator(
rotation_range=20, ### ±20度までの範囲でランダムに回転
width_shift_range=0.1, ### 画像の幅に対して±10%の範囲でランダムに水平方向にシフト
height_shift_range=0.1, ### 画像の高さに対して±10%の範囲でランダムに垂直方向にシフト
zoom_range=0.1, ### 画像を 0.9倍 から 1.1倍 の範囲でランダムに拡大・縮小する
horizontal_flip=True, ### 画像を水平方向にランダムに反転
vertical_flip=True ### 画像を水平方向にランダムに反転
)
実行するとこんな感じになります。画像は毎度お馴染み矢絣(やがすり)です。

d. VGG16による転移学習
これは、既にあるVGG16という無償の高性能学習済みモデルと、
今回で言うと日本の伝統模様データを合わせて新しい学習済みモデルを作る、
といったようなイメージです。
転移学習は、元々ある学習済みモデルを活用することで、少ない画像データでも
ディープラーニングを実装できるということで界隈では割と一般的な技術のようです。
この部分です。
#Input関数を使用してモデルのテンソル(多次元配列)を定義
input_tensor = Input(shape=(image_size,image_size, 3))
#転移学習モデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
4. アプリの実装
あとはウェブページ側のデザイン、ファイルのアップローダー作成やウェブページからアップロードした画像を受け取り、学習済みモデルで識別、そしてその結果をページに表示する部分となりますが、長くなってきたのでコードのみの表示とさせて頂きます。
(全てVisual Studio Codeにて実行)
Pythonコード(画像アップロード、識別、結果表示)
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["「 青海波 SEIGAIHA 」","「 七宝 SHIPPOU 」","「 紗綾形 SAYAGATA 」","「 矢絣 YAGASURI 」","「 三崩し SANKUZUSHI 」","「 縞 SHIMA 」"]
image_size = 100
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5') #学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size)) ##True→Falseへ変更
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "模様は" + classes[predicted] + "です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
##サーバーの設定
##if __name__ == "__main__":
## app.run()
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
HTMLコード(アップローダー等ウェブページの構造定義)
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Pattern Classifier</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<a class="header-logo" href="#">Japanese Traditional Pattern Classifier</a>
</header>
<div class="main">
<h1>AIが日本の伝統模様を識別します</h1>
<div class="container">
<img src="static/images/seigaiha.jpg" alt="seigaiha pattern" width="80" height="80" style="filter: grayscale(100%);">
<img src="static/images/shippou.png" alt="shippou pattern" width="80" height="80" style="filter: grayscale(100%);">
<img src="static/images/sayagata.png" alt="sayagata pattern" width="80" height="80" style="filter: grayscale(100%);">
<img src="static/images/yagasuri.jpg" alt="yagasuri pattern" width="80" height="80" style="filter: grayscale(100%);">
<img src="static/images/sankuzushi.png" alt="sankuzushi pattern" width="80" height="80" style="filter: grayscale(100%);">
<img src="static/images/shima.jpg" alt="shima pattern" width="80" height="80" style="filter: grayscale(100%);">
</div>
<p>日本の伝統模様かな?と思ったら画像をアップロードして識別してみよう!<br>
※ 現時点で識別できる模様は上記6種類のみとなります
</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="識別" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<small>
※ Aidemy Premium「AIアプリ開発講座」の最終課題として作成・公開しています<br>
designed & developed by TSUKAGOSHI
</small>
</footer>
</body>
</html>
CSSコード(ウェブページの見た目やデザイン)
header {
background-color: #8e8c8f;
height: 60px;
margin: -8px;
display: flex;
justify-content: center; /* 横方向の中央揃え */
align-items: center; /* 縦方向の中央揃え */
}
.header-logo {
color: #fff;
font-size: 20px;
margin: 15px 25px;
font-family: Avenir, sans-serif;
}
.main {
height: 490px;
}
h1 {
color: #444444;
margin: 120px 0px 60px 0px;
text-align: center;
}
p {
color: #444444;
margin: 50px 0px 20px 0px;
text-align: center;
}
form {
text-align: center;
}
.answer {
color: #444444;
font-size: 32px;
margin: 50px 200px 150px 200px;
text-align: center;
font-weight: bold; /* フォントを太字にする */
font-family: Avenir, sans-serif;
}
.container {
display: flex;
justify-content: center;
align-items: center;
}
img {
margin: 0 10px; /* 左右に10pxの隙間を空ける */
}
footer {
background-color: #F7F7F7;
height: 60px;
margin: -8px;
position: relative;
text-align: center;
}
small {
position: absolute;
bottom: 50%;
left: 50%;
transform: translate(-50%, 50%);
}
参考:ディレクトリ構成
JPAT_APP
├── static
│ ├── images
│ └── stylesheet.css
├── templates
│ └── index.html
├── uploads
│ └── .gitkeep
├── jpat.py
├── model.h5
└── requirements.txt
5. まとめ、考察
今回、日本の伝統模様を識別するAIアプリを無事完成することができました。
検証データ正解率(validation accuracy)
・目標:90%以上
・結果:94.1%
当初スクレイピングした28模様から6模様へと大幅に規模を縮小せざるを得ませんでしたが、検証データ正解率を左右する様々なパラメータを変化させる中で、その一つ一つのパラメータの意味合いであったり、その影響度を実際にイジり倒して確認することができたことは、今回のAIアプリ開発の中でも貴重な体験だったと感じています。
ただそれ以上に重要だったのは、データクレンジングでデータ(画像)の品質を高めることだったということが結果として分かったわけなんですが、「なんで最初からそうできなかったのか?」と振り返って自問自答してみると、そこには「AIだから適当にデータを突っ込んどけばなんとかしてくれるだろ」と、AIに対して浅はかな考えをもった過去の自分がいるだけでした・・・
6. 今後
製造業(車関係)に従事しているのでそこで活かせないか検討する。