概要
今回は、社内Q&A形式のナレッジの更新や追加をbizメンバーの方が簡単に管理できるように、スプレッドシートをUIにして、S3 Vectors + Bedrock Knowledge Basesでベクトル検索するパイプラインを組んでみました!LayerX様の週2500回以上使われる社内チャットボットを支えるAmazon Bedrock Knowledge Basesで作るRAGの記事を参考にさせていただきました。
全体像
スプレッドシートにQ&Aをインポートし、カスタムメニューから「追加」を押すだけ。それだけでベクトル検索可能になります!
スプレッドシート (UI)
↓ GAS
API Gateway
↓
Lambda
↓
S3 (原本) → Knowledge Bases (ベクトル変換) → S3 Vectors (検索)
S3 Vectorsとは
S3 VectorsはS3にベクトルデータをそのまま保存・検索できるサーバーレスなベクトルストレージ機能で、2025年7月に発表(プレビュー)され、2025年12月に正式リリースされた比較的に新しいサービスです。以下はGPT先生が教えてくれた従来との比較です。まだ私はちゃんと理解できておりません(笑)
従来のRAGや検索システムは基本この構造:
Embedding生成
→ Vector DB(Pinecone / OpenSearch / pgvector / Weaviate など)
→ 類似検索
→ LLM
つまり
ストレージ = DBだった。
S3 Vectorsの構造:
S3 VectorsはEmbedding生成
→ S3(Vector Bucket)
→ 類似検索API
→ LLM
つまり
ストレージ = S3
検索 = S3ネイティブ機能になった。
今回は、Knowledge BasesがTitan Embeddings V2でテキストをベクトルに変換し、S3 Vectorsに格納します。検索時はクエリもベクトル化して、類似度で近いナレッジを返す仕組みです。S3 Vectorsはこのパイプラインの出口で、ここが安く済むおかげで全体のコストが抑えられています。
スプレッドシートの構成
| 列 | 内容 | 備考 |
|---|---|---|
| A | チェックボックス | 操作対象の選択 |
| B | ID |
KB-{UUIDv4}。GASで自動生成 |
| C | 質問 | 自然言語 |
| D | 回答 | 自然言語 |
| E | カテゴリ | メタデータフィルタ用 |
| F | 参照URL | ソース元 |
| G | 更新日 | 自動 |
| H | ステータス | 未同期 / 同期済 / deleting / deleted / エラー |
B列のIDはシート保護で編集不可にし、事故を防ぎます。また今回は、カスタムメニューも構築しています。GASのonOpen() で追加できます。

「追加」「差分更新」「削除」の3つ。A列のチェックした行に対してまとめて実行する形で、B列のNoはAPI呼び出しの前に採番してシートに書き込む形にしています。
使い方
① C,D列にQAペア、E列にカテゴリ、F列に参照URLを入力し、A列のチェックボックスをクリック!

② カスタムメニューの「ナレッジ同期」をクリック!
※今回は追加ですが、差分更新や削除も行えます!

③ OKをクリック!
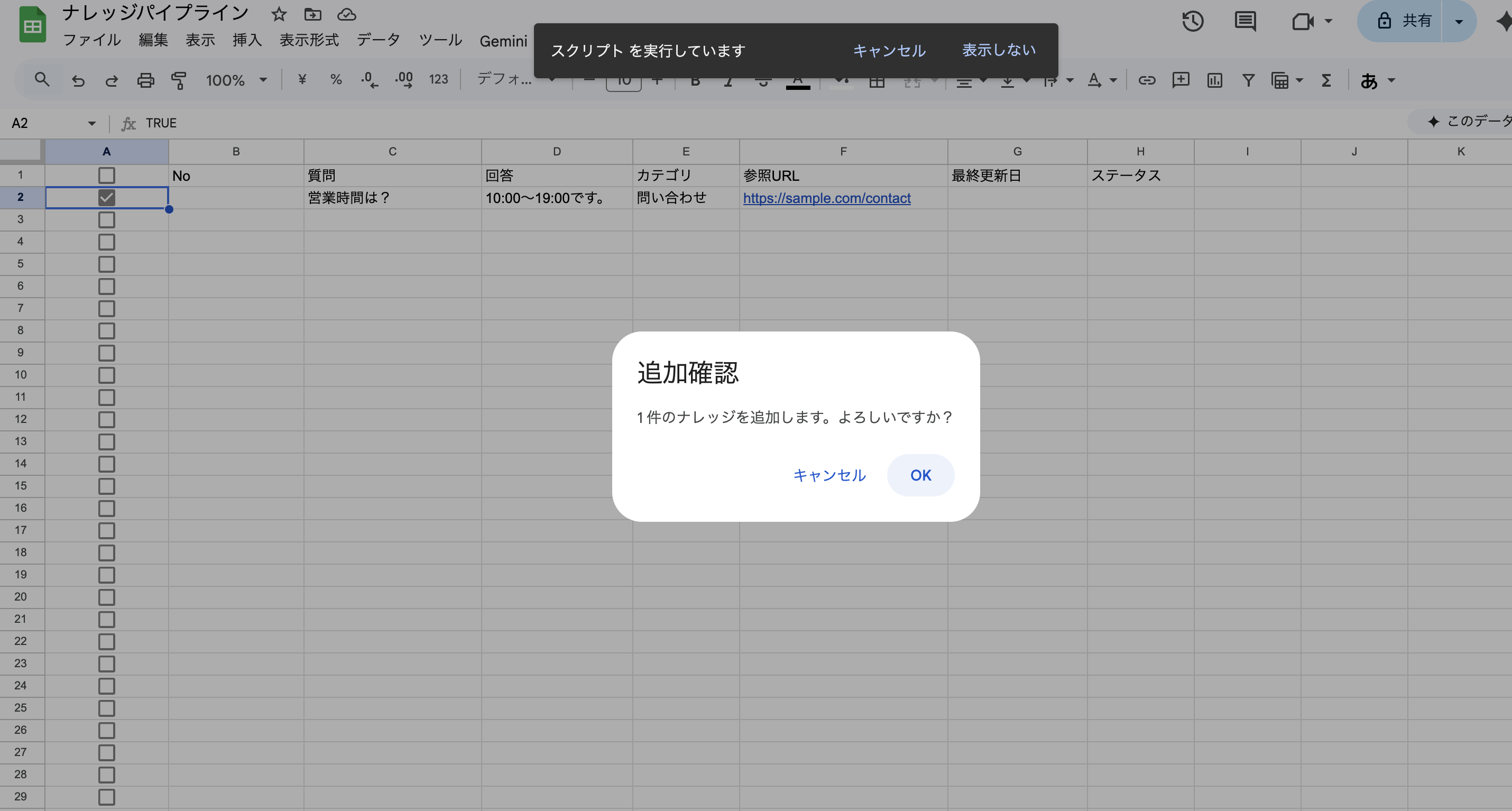
④ B列にKB- プレフィックス + UUIDv4(36桁)形式のIDが生成されます。これがAWS S3のファイル名となり、スプレッドシートの行とS3上のファイルを1対1で紐づけるキーになっています。このペアがあることで、検索時に category = "人事" や active = "true"のようなメタデータでフィルタリングできます。Markdown本文だけだとベクトル検索しかできないけど、メタデータがあれば「人事カテゴリだけから探す」「削除済みを除外する」といった絞り込みができます!
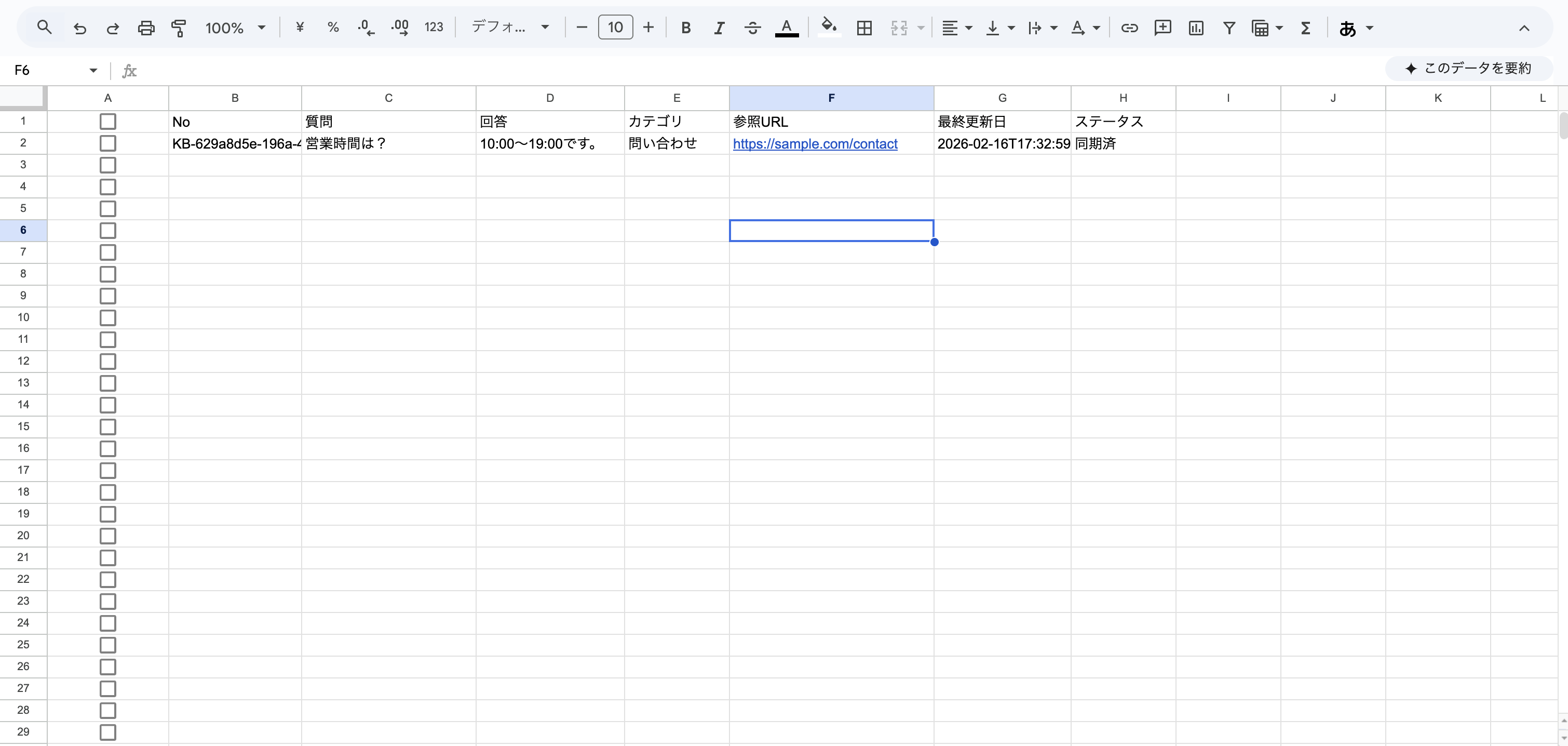
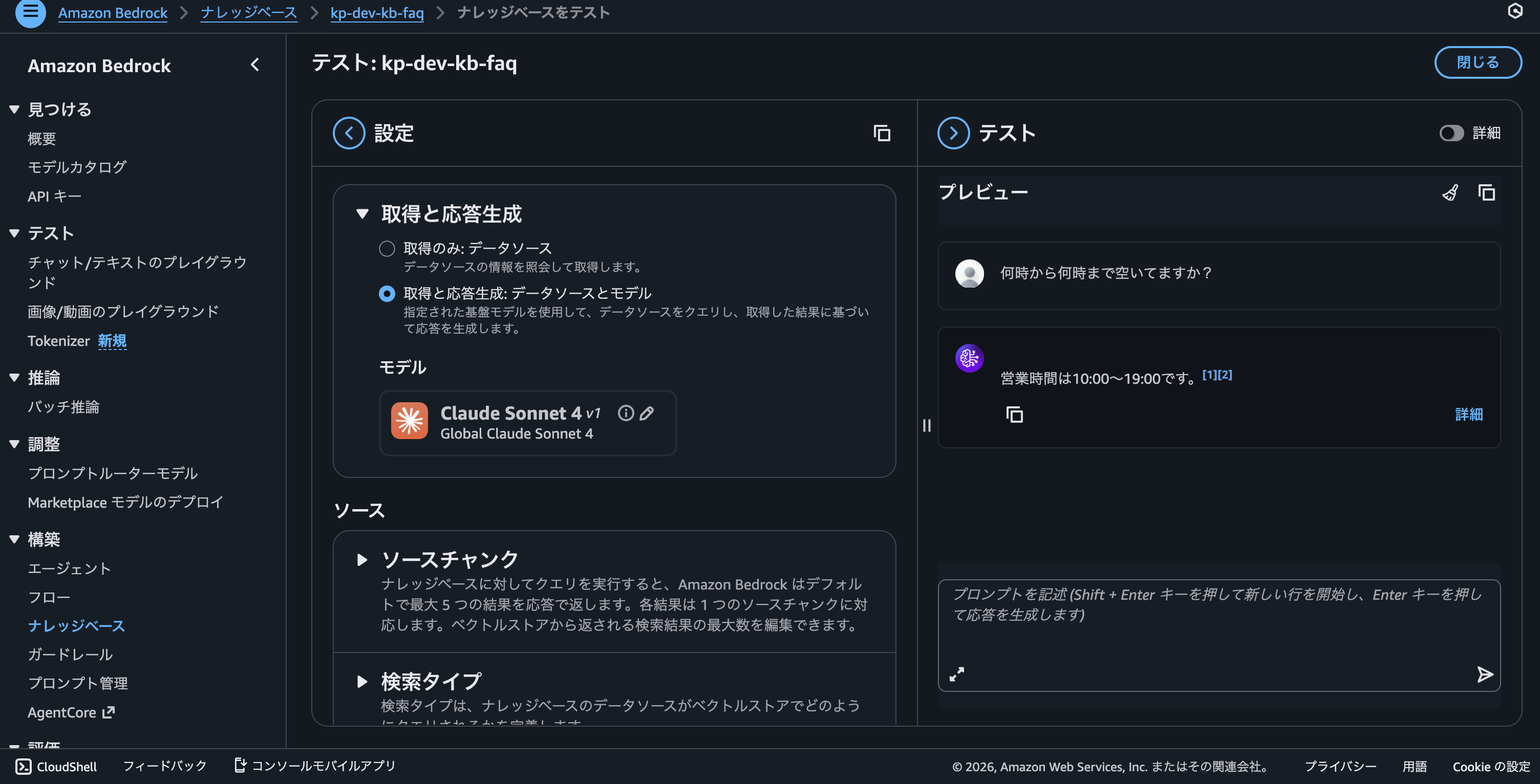
⑤ AWS knowledge bases上に即座に反映されます!
まとめ
今回のパイプライン
Knowledge BasesのVector StoreとしてS3 Vectorsを使っており、S3(原本)→Knowledge Bases(ベクトル変換)→ S3 Vectors(検索)という流れで、S3 Vectorsがパイプラインの出口になります。
差分更新の仕組み
B列のIDをキーにS3上の原本(.md + .metadata.json)を丸ごと上書きし、Knowledge Basesを再同期(再インデックス)し、本文差分の抽出ではなく、行単位の上書き。
構造化Markdownテンプレート
## Question / ## Answerのセクション分けで、質問と回答の検索重み付けを均等にしています。フッターに no、category、sourceを埋め込み、検索結果からナレッジの出所をたどれるようにしました。
論理削除とdeleting/deleted
メタデータの active を "false" にする論理削除方式。検索時に active = "true"
でフィルタすれば即座に除外できる。スプレッドシート側は deleting → deleted
の2段階で、ingestion完了前の状態を可視化。
API呼び出し前にID採番
NoはAPI呼び出しの前にシートに書き込む。通信失敗してもIDは確定済みで、ステータスが「エラー」になるだけ。再送で復旧。
最後に
S3 Vectorsのおかげで、大幅にコストを抑えてベクトル検索パイプラインを構築でき、スプレッドシートをUIにしたことでビジネスサイドの運用負荷も少なくなります。今回は、QA形式のペアでの実装ですが、今後はドキュメントファイルやPDFなどあらゆる形式のナレッジにも対応できるように、改善してきます!
参考文献
週2500回以上使われる社内チャットボットを支えるAmazon Bedrock Knowledge Basesで作るRAG