はじめに
LangServeという、LangChainの関数をAPI化できるツールがあると聞いたので、LangServeとStreamlitをもちいてBedrockを使ったチャットアプリを構築してみたので、その方法をまとめます。
環境の構築
LangServeはLangChainをREST APIとしてデプロイするためのツールです。FastAPIと呼ばれるPythonのWebフレームワーク上で動作します。Python環境があれば動作するので、ローカルPCでもEC2でも動かすことができます。ここではまず、ローカルPC上でLangServeを動かすための環境構築手順を紹介します。
ローカル環境での環境構築
python仮想環境の設定 (optional)
パッケージ導入の依存関係をプロジェクトごとに管理するため、venvを導入します。
mkdir [project dir]
python3 -m venv .venv
source .venv/bin/activate
python -V
必要なパッケージのインストール
pip install "langserve[all]"
pip install fastapi
pip install uvicorn
pip install langchain-aws
#以下はoptional
pip install openai
pip install anthropic
最小構成でチェック
以下のプログラム(sample.py)を書いてチェックします。
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
以下のように実行。
python sample.py
INFO: Started server process [20726]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
別のターミナルを開き、以下を確認。
curl http://localhost:8000
=> {"Hello":"World"}
Amazon Bedrockの呼び出し
以下のようにプログラムを作成します(server.py)。 例として、OpenAIと素のanthoropicもコメントアウトした状態でいれてみましたが、ここでは使用していません。
from fastapi import FastAPI
#from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langchain_aws.chat_models.bedrock import ChatBedrock
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
version="1.0",
description="LangServe application",
)
# 参考:OpenAIやAnthoropicを使いたい場合、以下を有効にする
#add_routes(
# app,
# ChatOpenAI(),
# path="/openai",
#)
#add_routes(
# app,
# ChatAnthropic(),
# path="/anthropic",
#)
add_routes(
app,
ChatBedrock(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
region_name="us-east-1",
streaming=True),
path="/bedrock")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
BedrockにアクセスするためにはAWSのクレデンシャルが必要となるので、ターミナルに環境変数として以下のように設定します。
export AWS_ACCESS_KEY_ID=XXXXXXX (ご自身のアクセスキー)
export AWS_SECRET_ACCESS_KEY=XXXXXXXX (ご自身のシークレットアクセスキー)
以下のように実行。
python server.py
INFO: Started server process [24061]
INFO: Waiting for application startup.
__ ___ .__ __. _______ _______. _______ .______ ____ ____ _______
| | / \ | \ | | / _____| / || ____|| _ \ \ \ / / | ____|
| | / ^ \ | \| | | | __ | (----`| |__ | |_) | \ \/ / | |__
| | / /_\ \ | . ` | | | |_ | \ \ | __| | / \ / | __|
| `----./ _____ \ | |\ | | |__| | .----) | | |____ | |\ \----. \ / | |____
|_______/__/ \__\ |__| \__| \______| |_______/ |_______|| _| `._____| \__/ |_______|
LANGSERVE: Playground for chain "/bedrock/" is live at:
LANGSERVE: │
LANGSERVE: └──> /bedrock/playground/
LANGSERVE:
LANGSERVE: See all available routes at /docs/
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
ブラウザにてhttp://localhost:8000/docsにアクセスすると、SwaggerUIの画面が表示されます。
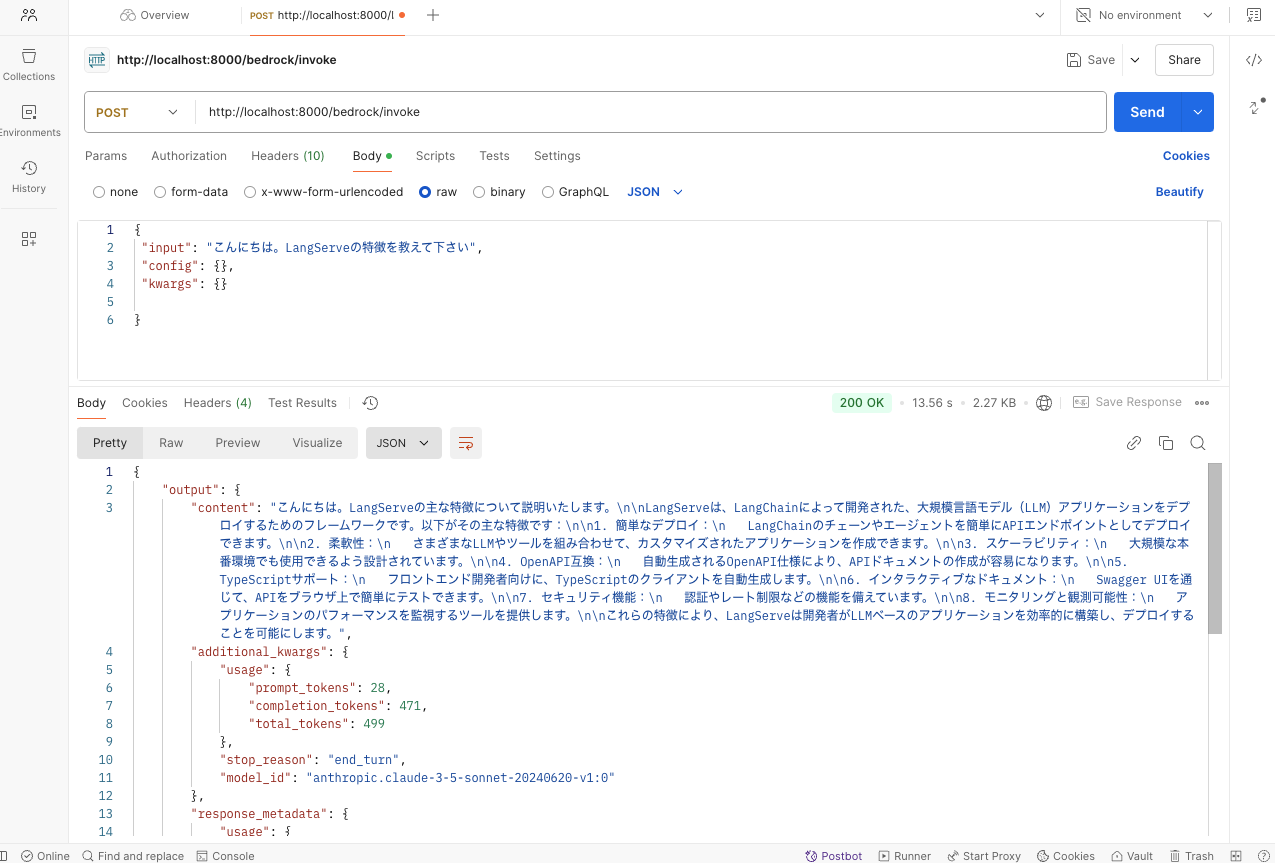
PostManなどのクライアントでREST APIに対してコマンドを投げると、Bedrockからの返信を確認することができます。
Streamlitからの呼び出し
以上でLangServeによるサーバーが構築できたので、APIを呼び出すStreamlitのアプリを作成します。まず、必要なパッケージをインストールします。
pip install boto3
pip install streamlit
pip install langchain-community
pip install langchain
以下のようにstreamlitのプログラムを作成します(app.py)。ここではまず、RAGのことは考えずに、Bedrockでチャットを行うアプリを作成しています。
import streamlit as st
import boto3
import json
import requests
def main():
"""メイン関数はStreamlitアプリでのチャットのやり取りを処理します。
この関数はチャットインターフェースを初期化し、ユーザー入力を処理し、AIモデルからのレスポンスを表示します。
"""
# セッション状態にチャットメッセージがない場合は初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# 既存のチャットメッセージを表示
if st.session_state.messages:
for info in st.session_state.messages:
with st.chat_message(info["role"]):
st.write(info["content"])
# 新しいユーザー入力を処理
if prompt := st.chat_input(""):
# ユーザーメッセージをセッション状態に追加
st.session_state.messages.append({"role": "Human", "content": prompt})
# ユーザーのメッセージを表示
with st.chat_message("Human"):
st.write(prompt)
# リクエスト用のデータ
json_data = json.dumps(
{
"input":prompt,
"config":{},
"kwargs":{}
}
)
#チャット結果をストリーム出力
with st.chat_message("Assistant"):
response = st.write_stream(
streaming_recieve(json_data)
)
# レスポンスをセッション状態に追加
st.session_state.messages.append({"role": "Assistant", "content": response})
def streaming_recieve(json_data):
"""
json_dataに対する レスポンスを生成するジェネレータ
"""
URL="http://localhost:8000/bedrock/stream"
print(json_data)
response = requests.post(
URL,
data=json_data,
headers={
"Content-Type": "application/json",
"Accept":"application/json"
},
stream=True
)
response_iter = response.iter_lines(decode_unicode=True)
for line in response_iter:
if line:
if line.startswith("event: data"):
#langserverではstreamingの場合、"event: data"の行に続き
#"data: "から始まる行で生成された回答が出力される
line = next(response_iter)
line = line[len('data: '):] #接頭文字の削除
content = json.loads(line) #文字列をJSONに変換
print(content)
line = content["content"] #中身の取り出し
yield line
if __name__ == "__main__":
main()
以下のようにstreamlitのプログラムを実行します。
streamlit run app.py --server.port 8080
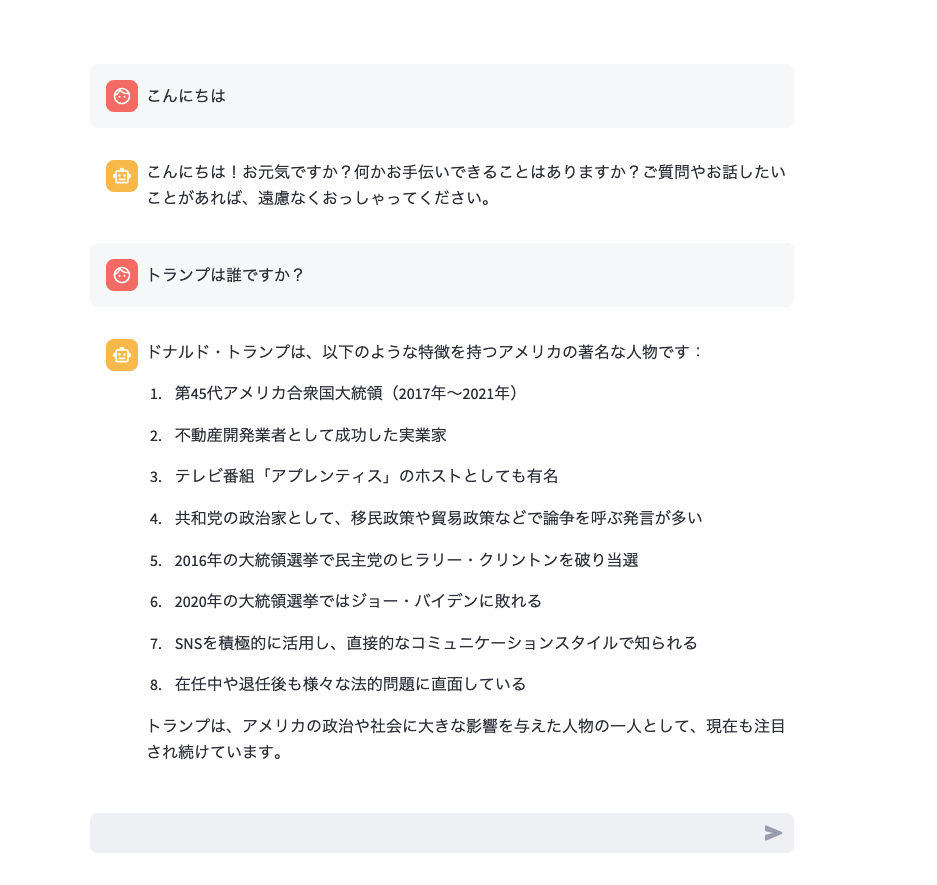
ブラウザの画面が立ち上がるので質問を入力すると、Bedrockからの返信が得られます。
注意:連続でプロンプトに入力すると、Bedrockのスロットルに引っかかりエラーになることがあります。その場合でもしばらく待てば入力可能です。
raise error_class(parsed_response, operation_name)
| botocore.errorfactory.ThrottlingException: An error occurred (ThrottlingException) when calling the InvokeModelWithResponseStream operation (reached max retries: 4): Too many requests, please wait before trying again.
下記リンクによると、on-demand modeではリクエストがquotaの制限より低くても、複数のカスタマーの間でshared capacity poolが使用されているため、Demandが高く、モデルが多くのリクエストを処理している場合にはスロットリングが発生する可能性があるとのこと。対策としては、Provision Throughputを設定する必要があるようです。試してみたところでは、Claude3.5よりもClaude3のほうがスロットルになりにくいように見えました。
https://repost.aws/questions/QU11DRlMZfRDy0ngHxpO1VCw/throttlingexceptions-while-using-on-demand-bedrock-runtime-for-invoking-claude-v2-1
https://docs.aws.amazon.com/bedrock/latest/userguide/prov-throughput.html
RAGの適用
上記のチャットアプリにRAGを適用してみます。
Knowledge baseの作成
S3バケットの作成
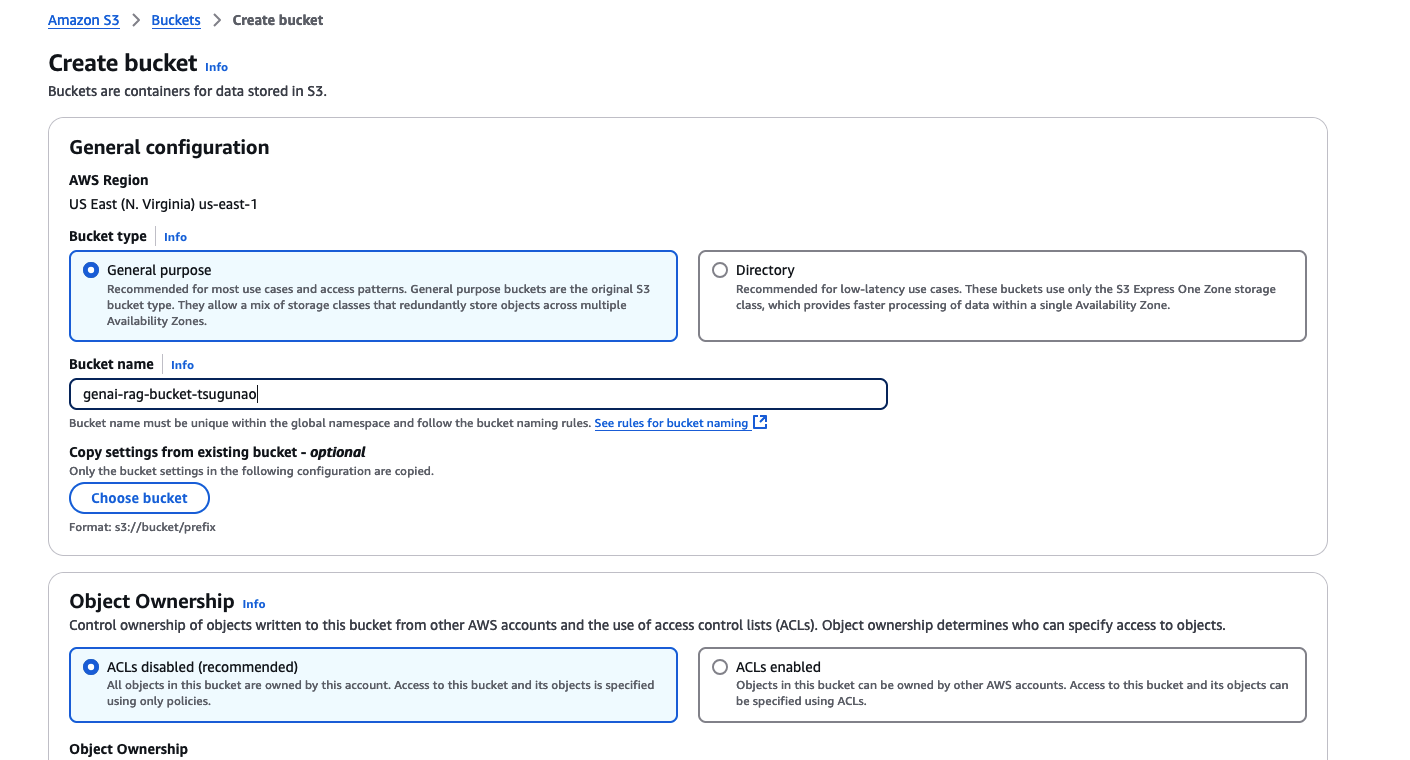
まずS3バケットを作成します。AWSマネジメントコンソールからS3を選択し”Create bucket”をクリックし、名前をつけてS3バケットを作成します。
knowledge baseの作成
1.Amazon Bedrockのコンソールへ行き、左側のメニューから"Knowledge bases"をクリックします。
(us-east-1のリージョンで作成しました。リージョンにより選択できるモデルに違いがあるので注意)
2.Create Knowledge baseをクリックします。
3.Provide knowledge base detailsの画面に遷移するので、必要項目を入力します。
- knowledge baseの名前をつけます
- IAMはCreate and use new service roleを選択
- data sourceはS3を選択
Nextをクリック.
-
Configure data sourceの画面に遷移するので必要項目を入力します
- S3 URLの箇所で先ほど作成したS3バケットを指定します
あとはデフォルトのままNextをクリック.
-
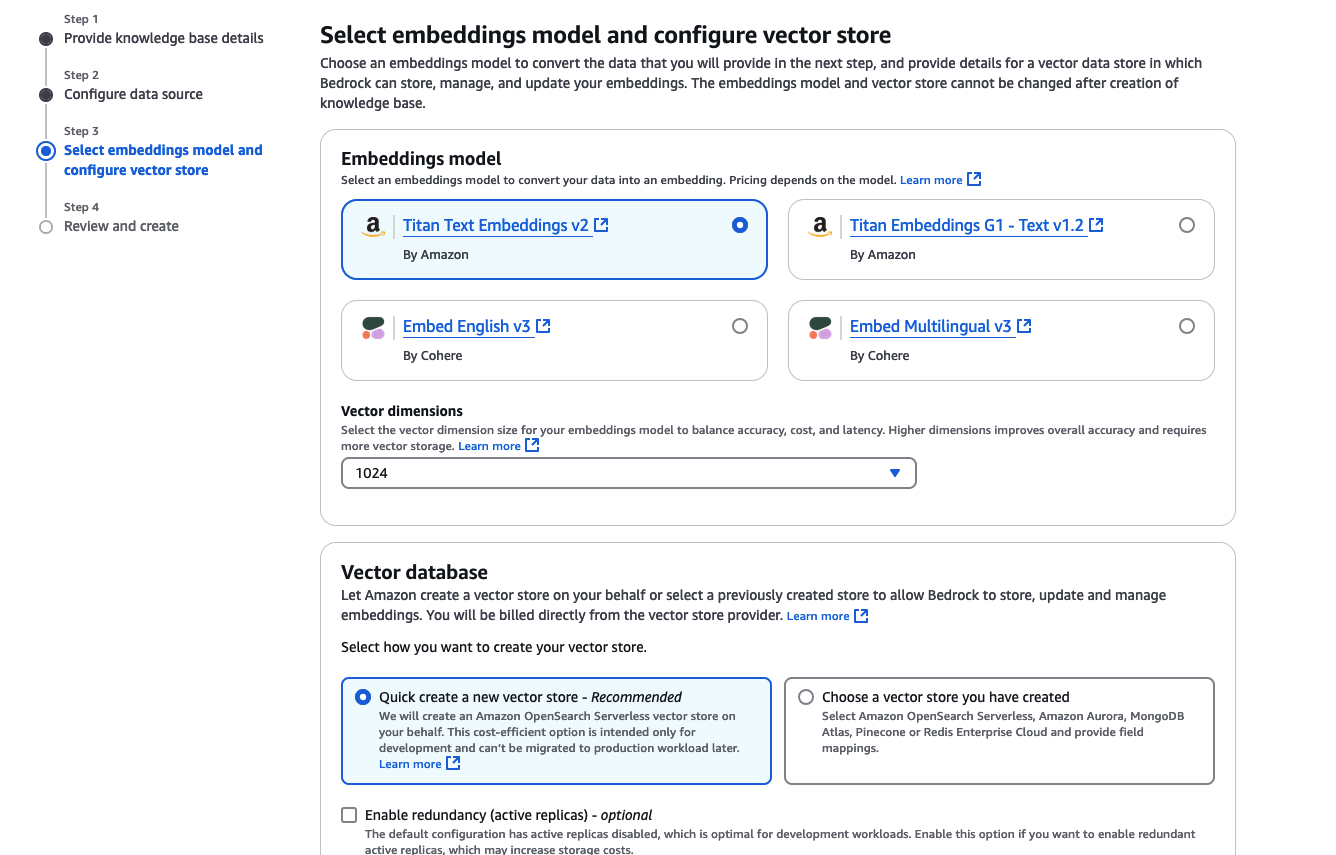
Select embeddings model and configure vector storeの画面に遷移するので以下のように設定します。
- Embddings modelにTitan Text Embeddings v2を選択
- Vector databaseにて
Quick create a new vector storeを選択
あとはデフォルトのままNextをクリック.
-
Create Knowledge baseボタンをクリックします。
しばらくするとKnowledge baseが作成されるので、Knowledge base IDをメモしておきます。
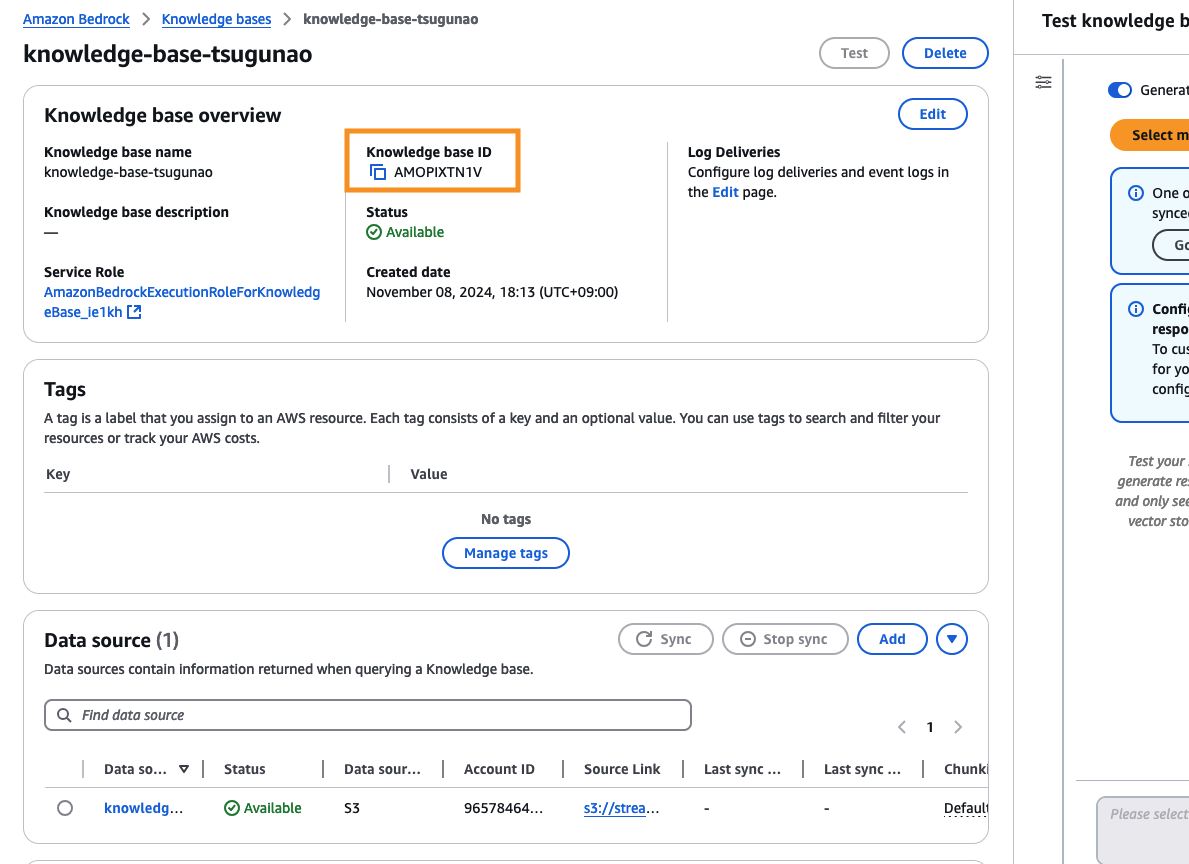
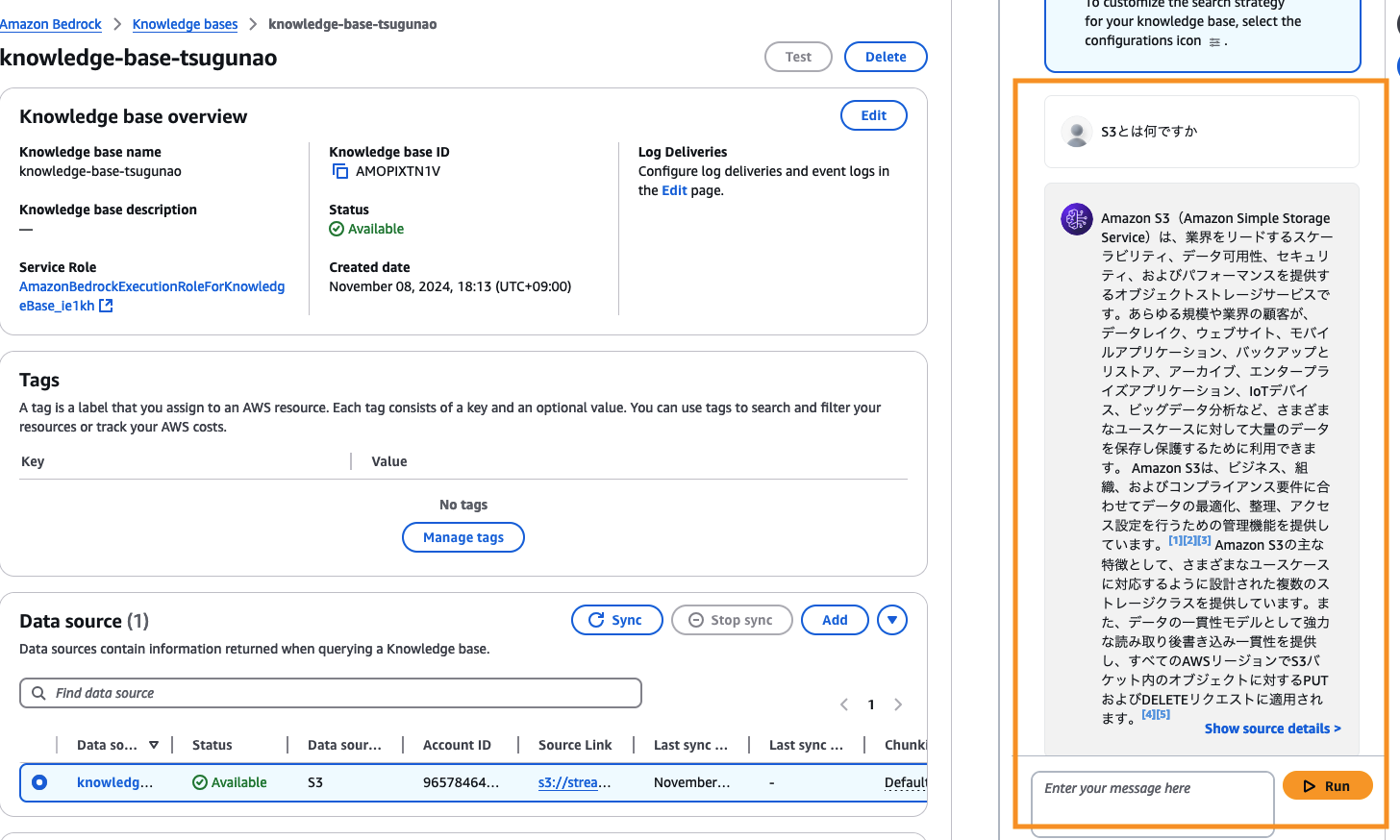
Knowledge baseを試すために、RAGとして試してみたい文書を先ほど作成したS3バケットにアップロードし、Data sourceの箇所で、Sync ボタンを押します。(Syncにしばらく時間がかかります)
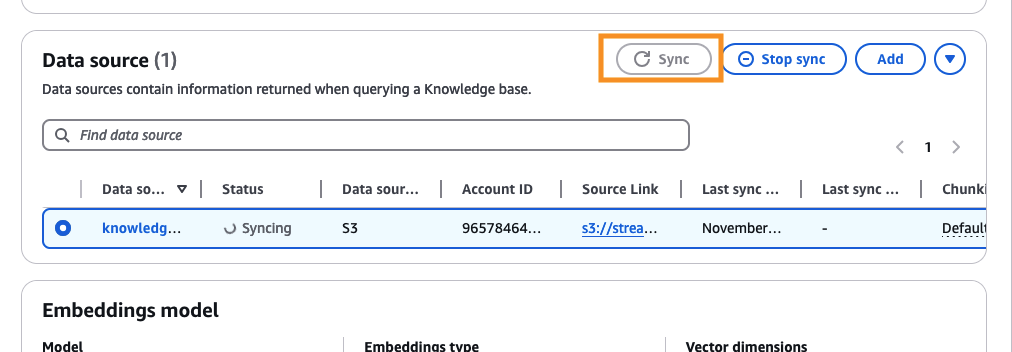
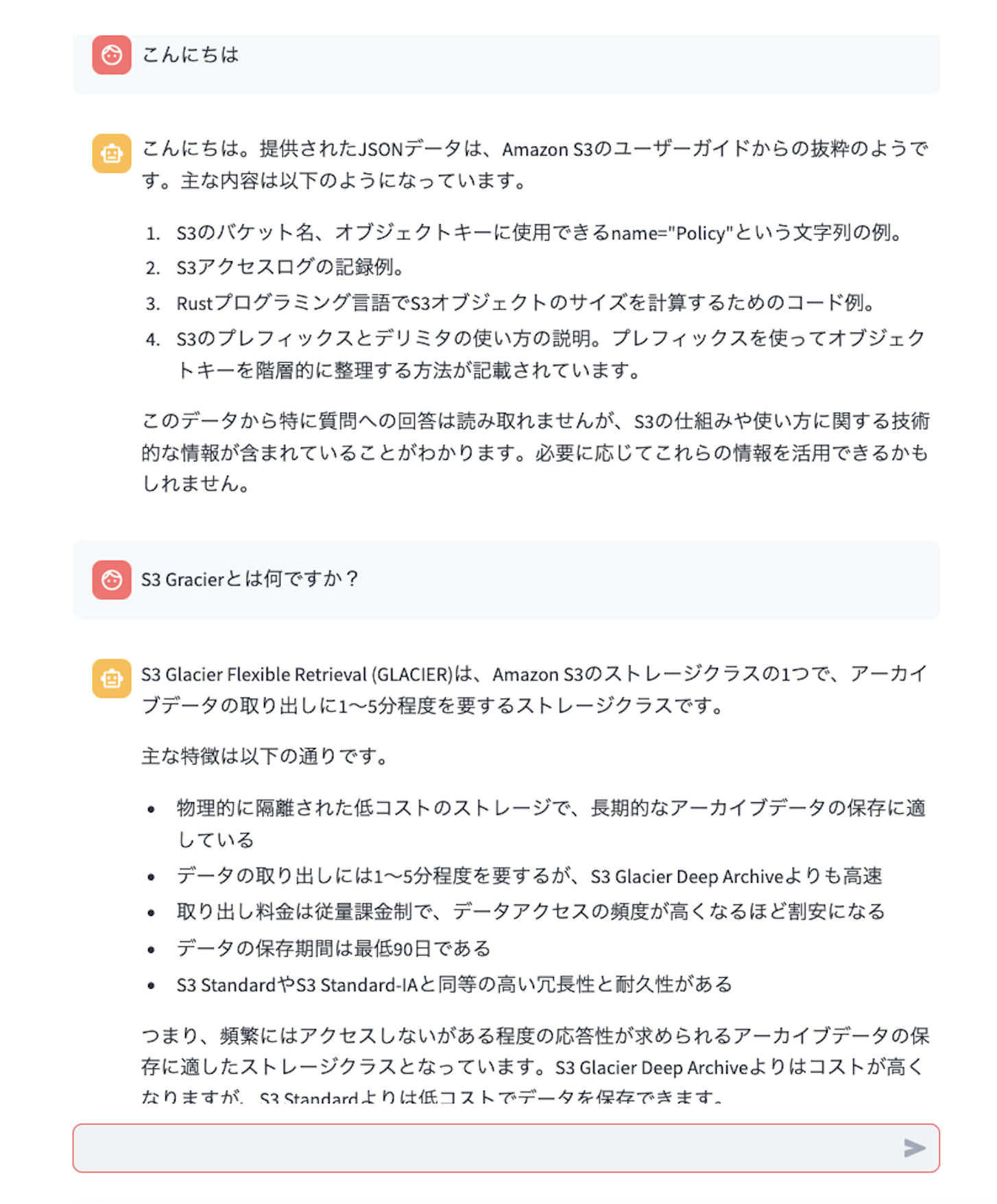
Syncが終了すると、右側のTest knowledge baseからテストを行うことができます。(ここでは例としてS3のユーザーガイドの文書を登録したので、S3について質問しています)
Streamlitプログラムの編集
StreamlitのプログラムをKnowledge baseを参照するように編集します。LangServeにはknowledge baseへのアクセスのAPIは用意されていないように見えたので、ここではboto3経由でbedrockのAPIを呼び出す形で実装します。以下のように実装します。st.secretとしてKnowledge base IDを参照したいので、.streamlit/secret.tomlというファイルを作成し、KNOWLEDGE_ID = "XXXXXXXXのように先ほどメモしておいたKKNOWLEDGE_IDを設定します。
import streamlit as st
import boto3
import json
import requests
def main():
"""メイン関数はStreamlitアプリでのチャットのやり取りを処理します。
この関数はチャットインターフェースを初期化し、ユーザー入力を処理し、AIモデルからのレスポンスを表示します。
"""
# セッション状態にチャットメッセージがない場合は初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# 既存のチャットメッセージを表示
if st.session_state.messages:
for info in st.session_state.messages:
with st.chat_message(info["role"]):
st.write(info["content"])
# 新しいユーザー入力を処理
if prompt := st.chat_input(""):
# ユーザーメッセージをセッション状態に追加
st.session_state.messages.append({"role": "Human", "content": prompt})
# ユーザーのメッセージを表示
with st.chat_message("Human"):
st.write(prompt)
docs_info = retrive_knowledgebase(prompt)
info = json.dumps(docs_info["retrievalResults"])
json_data = json.dumps(
{
"input":'{"question":'+prompt+',"info":'+info+'}',
"config":{},
"kwargs":{}
}
)
with st.chat_message("Assistant"):
response = st.write_stream(
streaming_recieve(json_data)
)
st.session_state.messages.append({"role": "Assistant", "content": response}
)
def streaming_recieve(json_data):
"""
json_dataに対する レスポンスを生成するジェネレータ
"""
URL="http://localhost:8000/bedrock/stream"
print(json_data)
response = requests.post(
URL,
data=json_data,
headers={
"Content-Type": "application/json",
"Accept":"application/json"
},
stream=True
)
if response.encoding is None:
response.encoding = 'utf-8'
response_iter = response.iter_lines(decode_unicode=True)
for line in response_iter:
if line:
if line.startswith("event: data"):
#langserverではstreamingの場合、"event: data"の行に続き
#"data: "から始まる行で生成された回答が出力される
line = next(response_iter)
line = line[len("data: "):] #接頭文字の削除
content = json.loads(line) #JSON取り出し
line = content["content"] #中身
yield line
def retrive_knowledgebase(prompt):
# Bedrock runtime用のAWS Boto3クライアントを初期化
retrieve_bedrock = boto3.client(
service_name="bedrock-agent-runtime", region_name="us-east-1"
)
# knowledge base から情報を取得
docs_info = retrieve_bedrock.retrieve(
knowledgeBaseId=st.secrets["KNOWLEDGE_ID"],
retrievalQuery={"text": prompt},
)
return docs_info
if __name__ == "__main__":
main()
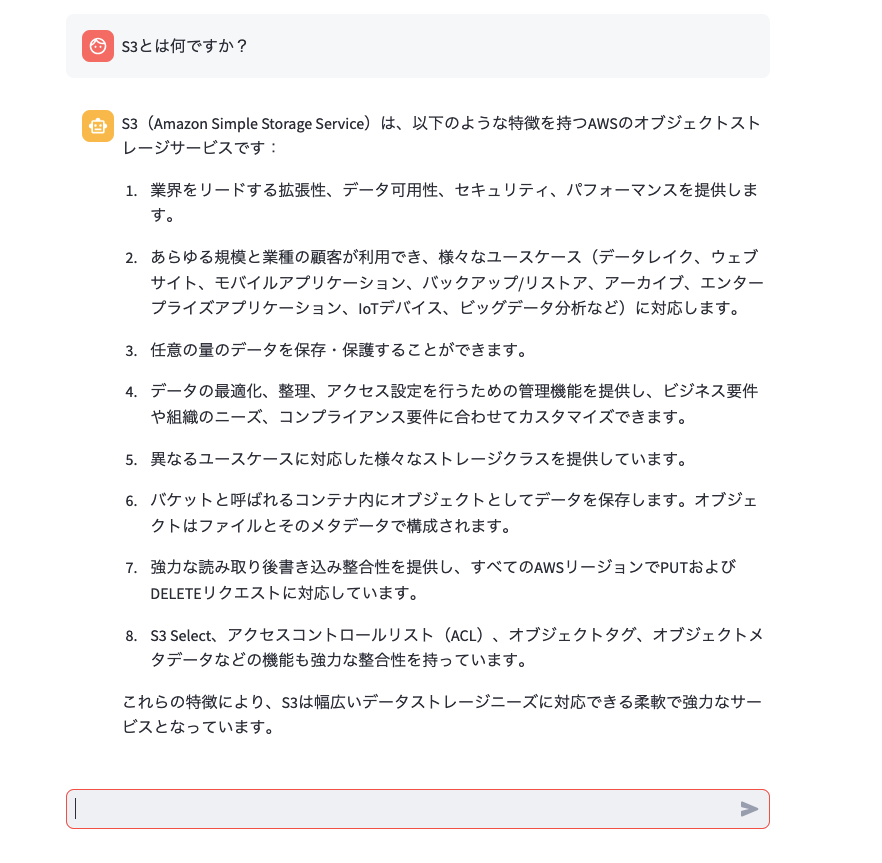
プログラムを以下のように実行し、RAGを使用したチャットアプリが動作することを確認します。
streamlit run app.py --server.port 8080
EC2上でのホスティング
これまでは、ローカルPC上で動作確認をしておりましたが、作成したアプリ及びLangServeをEC2上で動作するようにします。
インスタンスの立ち上げ
AWSマネジメントコンソールからEC2インスタンスを立ち上げます。Pythonが動作すればよいのでどのAMIでもよいですが、今回はAmazon Linux 2023 AMIのt2.microを選択しました。途中キーペアを作成する画面があるので、名前をつけてダウンロードしておきます。VPCはDefaultで存在しているVPCを選択し、SubnetはPublicな(インターネットゲートウェイにつながっている)サブネットを選択します。あとはデフォルトのまま、Launch Instanceボタンをクリックし、インスタンスを作成します。
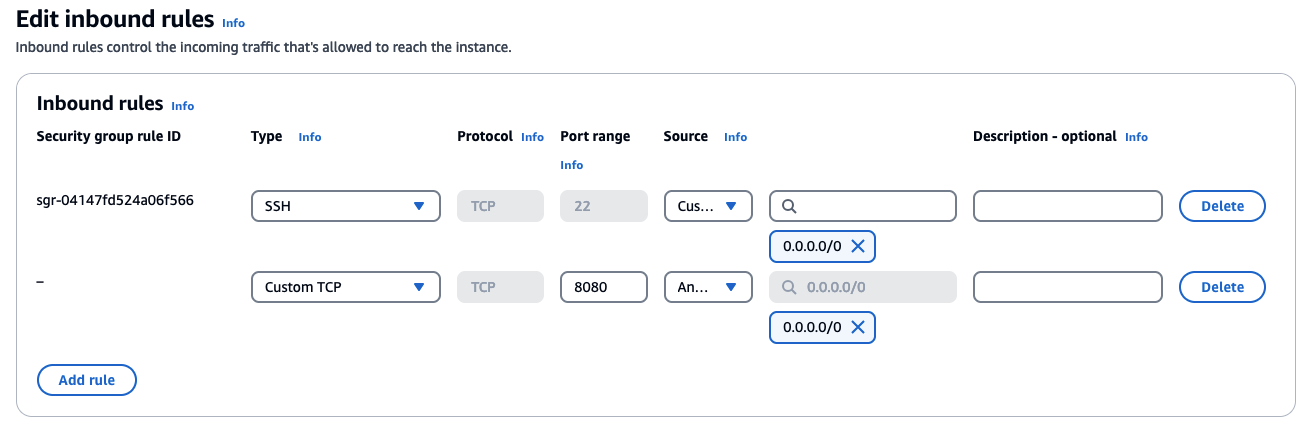
インバウンドルールの設定
Streamlitが使用するポートに外部からアクセスができるようにEC2のセキュリティグループに対してインバウンドルールの設定を行います。Streamlitを起動するときのコマンドとして、streamlit run app.py --server.port 8080 として8080番ポートを使用しているため、8080番ポートをあけるように設定します。アクサス元のIPアドレスの指定もできるので必要に応じて設定します。
インスタンスに接続
以下のようにsshでインスタンスに接続します。
ssh -i your.pem ec2-user@ec2-XXX-XXX-XXX-181.compute-1.amazonaws.com
The authenticity of host 'ec2-XXX-XXX-XXX-181.compute-1.amazonaws.com (xx.xxx.xxx.xxx)' can't be established.
ED25519 key fingerprint is SHA256:.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'ec2-XXX-XXX-XXX-181.compute-1.amazonaws.com' (ED25519) to the list of known hosts.
, #_
~\_ ####_ Amazon Linux 2023
~~ \_#####\
~~ \###|
~~ \#/ ___ https://aws.amazon.com/linux/amazon-linux-2023
~~ V~' '->
~~~ /
~~._. _/
_/ _/
_/m/'
[ec2-user@ip-XXX-XX-XXXX ~]$
ローカルにあるプロジェクトのディレクトリを丸ごとzip化して、EC2インスタンスにコピーします。
scp -i .your.pem ragchat.zip ec2-user@ec2-XXX-XXX-XXX-181.compute-1.amazonaws.com:/home/ec2-user/
EC2上でコピーしたzipファイルを解凍し、必要なパッケージをインストールします。
python3 -m venv my_venv
source my_venv/bin/activate
pip install "langserve[all]"
pip install fastapi
pip install uvicorn
pip install langchain-aws
pip install boto3
pip install streamlit
pip install langchain-community
pip install langchain
S3とBedrockにアクセスできるロールを作成します。
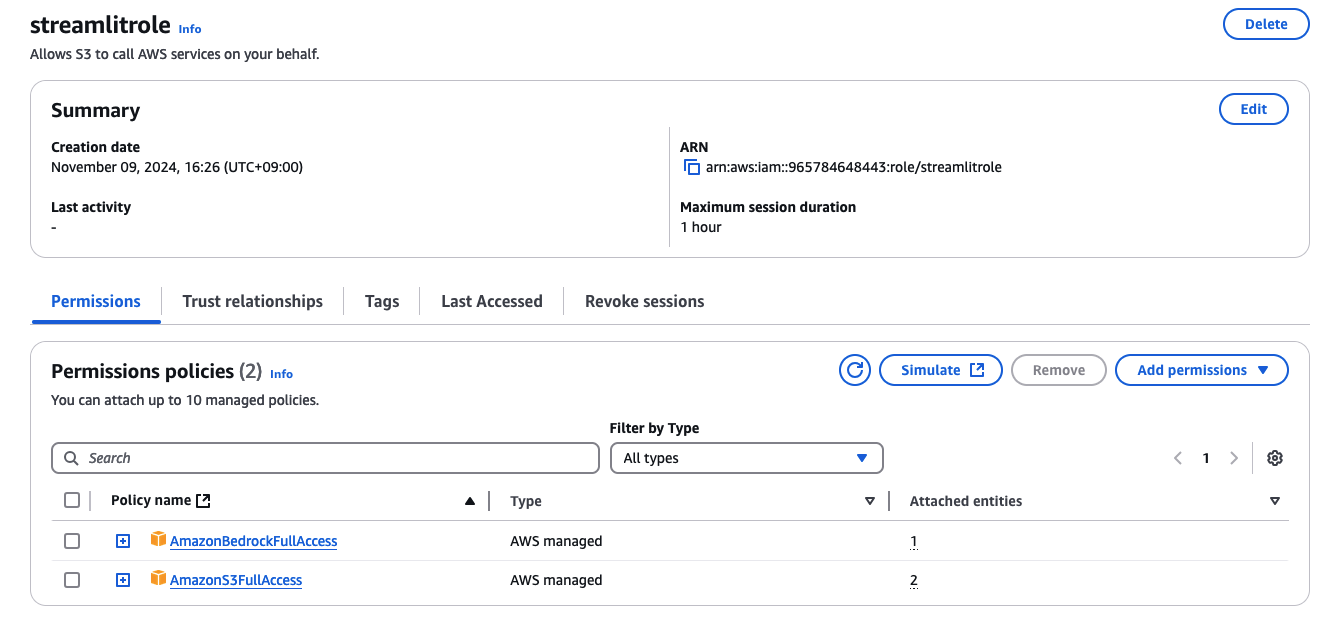
ロールには"ec2.amazonaws.com"を信頼関係に設定します。
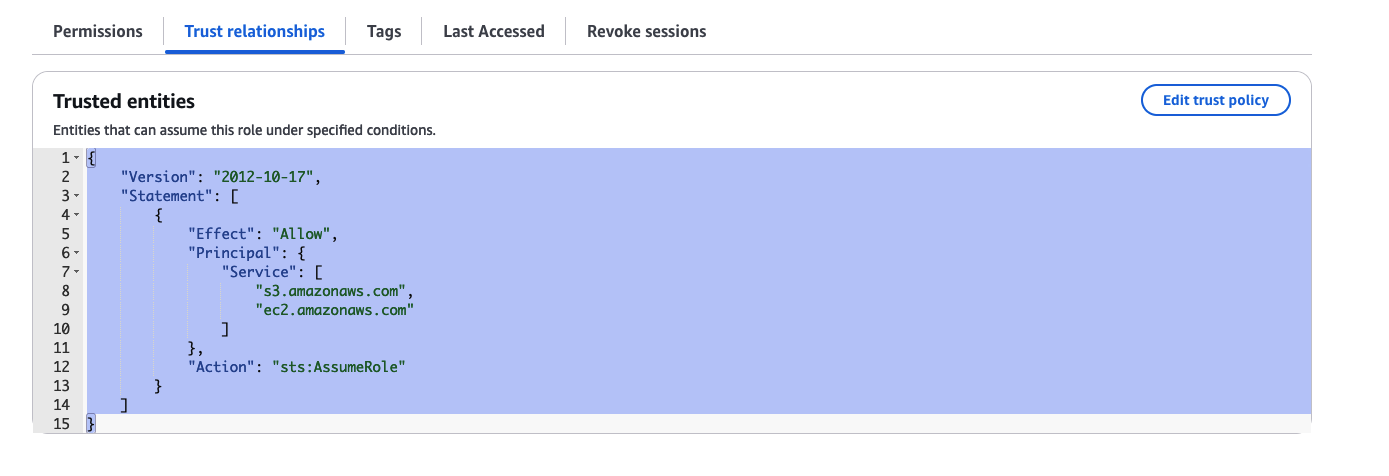
インスタンスプロファイルを作成します。インスタンスプロファイルはAWSマネジメントコンソールからは作成できないのでCLIで以下のように作成し、ロールにアタッチします。
aws iam create-instance-profile --instance-profile-name <your instance profile name>
aws iam add-role-to-instance-profile --instance-profile-name <your instance profile name> --role-name <your role name>
EC2の画面の、Actions>Security>Modify IAM Roleから作成したインスタンスプロファイルを選択します。
プログラムの実行
以下のようにプログラムを実行します。
python server.py
INFO: Started server process [5509]
INFO: Waiting for application startup.
__ ___ .__ __. _______ _______. _______ .______ ____ ____ _______
| | / \ | \ | | / _____| / || ____|| _ \ \ \ / / | ____|
| | / ^ \ | \| | | | __ | (----`| |__ | |_) | \ \/ / | |__
| | / /_\ \ | . ` | | | |_ | \ \ | __| | / \ / | __|
| `----./ _____ \ | |\ | | |__| | .----) | | |____ | |\ \----. \ / | |____
|_______/__/ \__\ |__| \__| \______| |_______/ |_______|| _| `._____| \__/ |_______|
LANGSERVE: Playground for chain "/bedrock/" is live at:
LANGSERVE: │
LANGSERVE: └──> /bedrock/playground/
LANGSERVE:
LANGSERVE: See all available routes at /docs/
INFO: Application startup complete.
別のターミナルで以下を実行します。
streamlit run app.py --server.port 8080
EC2のパブリックDNSの8080番ポートにアクセスすると、Streamlitのアプリケーションを実行することができます。