Looker Advent Calendar 2020の23日目の記事になります。
ZOZOテクノロジーズでLookerに触れているデータエンジニア 遠藤です。
結局、昨年末から1年ぶりの投稿になってしまいました。。。
はじめに
ZOZOテクノロジーズではLookerをデータガバナンスツールとして使用しています。
(弊社におけるLooker利用法の詳細は**こちらからご覧ください 
とくに、弊社ではLookerをELTツールとしても活用していて、ELTの結果を"中間テーブル"として格納しています。
中間テーブルの生成は、@hase-ryoさんのLooker Advent Calendar 2019 5日目の記事にもあるとおり、
Looker利用のパフォーマンス向上においてとても有用です。
そこで、本記事では、Looker上で中間テーブル生成をどのように柔軟に管理していくか?について報告します。
PDT機能
Lookerには、**PDT(永続的な派生テーブル)**という、viewで設定したderived_tableのアウトプットを物理データとして好きなタイミングで保存する機能が存在します。
PDTの概要・基本は以下の記事で参照できます。
例えば、PDT生成の基本例の1つとして、以下のようなdatagroupを使用したviewが挙げられます。1
view: pdt_temp_table {
derived_table: {
datagroup_trigger: temp_datagroup
explore_source: temp_table {
column: id {}
column: column_1 {}
column: column_2 {}
column: column_3 { field: temp_table.temp_column_a }
column: update_timestamp { field: temp_table.update_timestamp_time }
}
}
(中略)
}
datagroup: temp_datagroup {
sql_trigger: SELECT FORMAT_TIMESTAMP('%F',CURRENT_TIMESTAMP(),'Asia/Tokyo') ;;
max_cache_age: "24 hours"
}
まず、datagroup: temp_datagroupを定義して、定義したdatagroupをPDTとして生成したいviewのderived_table内にdatagroup_trigger: temp_datagroupと記述します。
すると、datagroup内のsql_triggerで設定したクエリの値が変化した際に、中間テーブルが自動的にCREATEされます。
(以下の図はpdt_temp_table.viewにおいて自動的に生成されたBigQuery中間テーブルの例です)
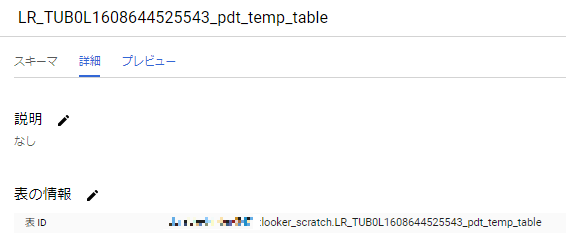
PDTで生成された中間データは、所定のlook・dashboardのデータ元として自動的にキャッシュのように用いられます。
中間テーブルを柔軟に作成する
基本的なPDT機能を用いた中間テーブル作成は以下の懸念点があります。
- 中間データの出力方法はテーブルが新規にCREATEされるのみ(=テーブルが乱立する)
- 中間データ格納先のDBスキーマとテーブル名はLookerの規則で決められてしまう2
これらの懸念点を踏まえて柔軟に中間テーブルを作成するには、新たに中間テーブルを作成するためのダミーのviewを設定することで解決します。
view: pdt_temp_table_basics {
derived_table: {
explore_source: temp_table {
column: id {}
column: column_1 {}
column: column_2 {}
column: column_3 { field: temp_table.temp_column_a }
column: update_timestamp { field: temp_table.update_timestamp_time }
}
}
}
view: pdt_temp_table_dummy {
derived_table: {
datagroup_trigger: temp_datagroup
create_process: {
sql_step: CREATE OR REPLACE TABLE default_dataset.pdt_temp_table AS
${pdt_temp_table_basics.SQL_TABLE_NAME} ;;
sql_step: CREATE OR REPLACE TABLE ${SQL_TABLE_NAME} AS
SELECT 1 AS dummy ;;
}
}
dimension: dummy {}
}
pdt_temp_table_dummy.viewでは、create_process・sql_stepという項目が追加されました。
また、view: pdt_temp_table_dummy内での記述${pdt_temp_table_basics.SQL_TABLE_NAME} は、view: pdt_temp_table_basicsにおけるderived_tableのクエリ文を参照するという意味を表しています。(これはカスケードと呼ばれる機能です)
なお、上記のview: pdt_temp_table_dummyのexploreを実行すると、Looker UI側のexplore画面は以下のように意味を持たない出力結果になります。
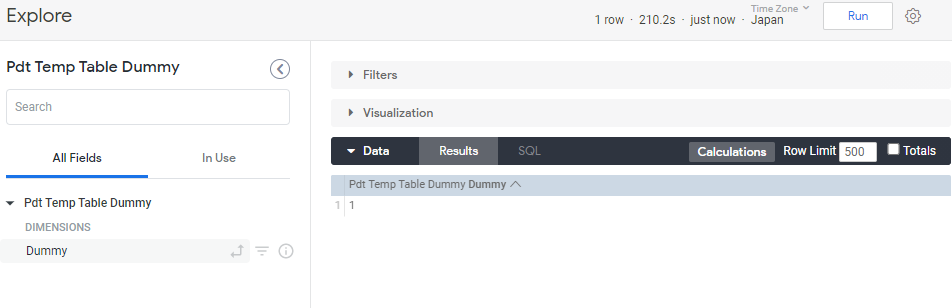
ただし、view: pdt_temp_table_dummyのexploreの実行中にcreate_process内のsql_stepのDDL文が順に実行され、
以下のように、DDL文で指定した名称(=名称が「LR_●●●...」ではない)中間テーブル「temp_table」がCREATEされます。
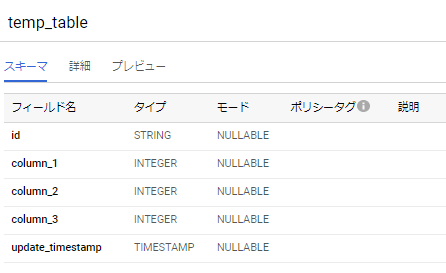
もちろんsql_stepでは、INSERT・DELETE文も記述することも可能で、一部データのみ更新するといったことも可能になります3(=かなり柔軟な中間テーブル運用が可能になります)。
中間テーブル自動更新を設定する際の注意点
Lookerでは、先述のとおり、datagroup_triggerにおいて更新するトリガーを設定することで、中間テーブルデータを自動的に更新できるようになりますが、その際に、注意点が2点あります。
user_attributesの取り扱いに注意
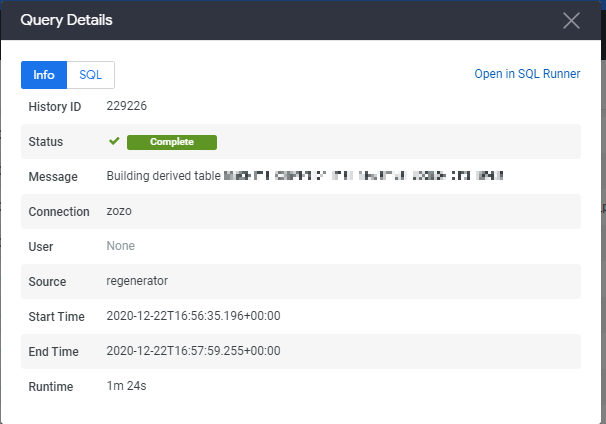
トリガー由来でPDTを生成する実行ユーザーはLookerのシステムユーザーになります。
(以下のクエリ実行ログ画面によるとUser: Noneと表されている)
一方、Lookerにはユーザーアカウントごとに引数を設定できる「user_attributes」という機能がありますが、現在、Lookerのシステムユーザーにuser_attributesの値の割り当てを設定することは不可能です。
そのため、datagroupの項目を含むviewに対してuser_attributesの記述({{ _user_attributes['●●●'] }})はできません。
(Lookerのシステムユーザーにおけるuser_attributesの引数は全て空値になります)
ただし、それを逆手にとって、*pdt_temp_table_dummy.view(version2)*では、自動更新と手動更新の処理分岐をLiquid記法のif文で記述することで同一view内で実現しています。
view: pdt_temp_table_filtered {
derived_table: {
explore_source: temp_table {
column: id {}
column: column_1 {}
column: column_2 {}
column: column_3 { field: temp_table.temp_column_a }
column: update_timestamp { field: temp_table.update_timestamp_time }
filters: {
field: temp_table.update_timestamp_time
value: "{{ _user_attributes['start_date'] }} to {{ _user_attributes['end_date'] }}, {{ _user_attributes['end_date'] }} for 1 days"
}
}
}
}
view: pdt_temp_table_dummy {
derived_table: {
datagroup_trigger: temp_datagroup
create_process: {
sql_step: {% if _user_attributes['start_date'] == '' %}
CREATE OR REPLACE TABLE default_dataset.pdt_temp_table AS
${pdt_temp_table_basics.SQL_TABLE_NAME} ;;
{% else %}
INSERT default_dataset.pdt_temp_table
(id,
column_1,
column_2,
column_3,
update_timestamp)
${pdt_temp_table_filtered.SQL_TABLE_NAME}
{% endif %} ;;
sql_step: CREATE OR REPLACE TABLE ${SQL_TABLE_NAME} AS
SELECT 1 AS dummy ;;
}
}
dimension: dummy {}
}
sql_triggerのクエリ設定
datagroupで設定するsql_triggerのクエリは、connection内の「PDT And Datagroup Maintenance Schedule」でcron設定することで、定期的に実行されます。
(デフォルトでは5分)
その定期的なクエリ実行を繰り返す中で、クエリの値に変化が生じた場合にPDTの自動作成がLookerシステム内で起動します。
Looker公式では、以下のようなsql_triggerのクエリ設定方法を提示してくれています。
- TIMESTAMP関数を用いたクエリ(例:hourly, 毎日●:00のdaily)
- データ差分を示すカラムに対する集計クエリ(例:idの最大値, update_timestampの最大値, テーブル全体のレコード数)
しかし、このクエリ設定で重いクエリを設定すると、PDT自動生成を行う前の段階でDBリソースに影響を与えかねません。
(とくに、データ差分をトリガにしたい場合はよく起こりうる話です)
そこで、テーブルデータの更新・追加状況をログとして記録するテーブル(例:以下の図のようなpdt_update_log)の作成をお薦めします。
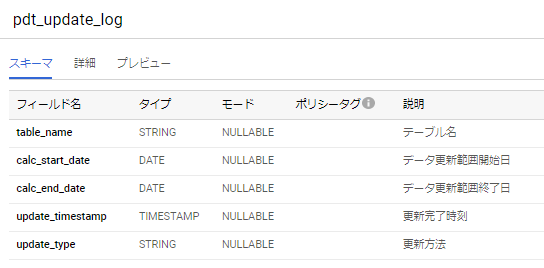
pdt_update_logテーブルを使用したクエリをsql_triggerに設定することで、PDT作成に依存する元テーブルのupdate状況を低コストのクエリで監視できます。
このように、DBリソースに優しい適切なsql_triggerのクエリ設定の工夫はとても重要です。
おわりに
本記事では、Lookerを用いた中間テーブル管理法の例・注意点を紹介させていただきました。
なお、中間テーブルの運用は、DBリソースに負荷をかけるので、DB管理者の方とよく相談しながら進めていただければと思います。
今回も小技を紹介してしまいましたが、このような小技を
先々月リニューアルされた日本語版のLooker Forumに
Lookerユーザーの皆さんにとって充実することを願って。。。
まとめ
- Lookerを用いた中間テーブルの生成・管理はPDT機能を用いる
- create_process・sql_stepでDDL文を発行することで中間テーブルを柔軟に作成・更新できる
- PDTの自動更新ではuser_attributesは使用不可
- PDT自動実行トリガー設定内のsql_triggerクエリは低コストを心がける(デバッグ実行ログをテーブルとして展開してそのテーブルにクエリを投げるのも手)
さらにお知らせ
私が現在所属している ZOZOテクノロジーズ 推薦基盤チームでは一緒に楽しく働くデータエンジニアを募集しています!
ご興味のある方はぜひこちらをご覧ください!
-
Looker 7.0からはpublish_as_viewを用いて作成する方法もあります ↩
-
Looker公式ドキュメントによると、[scratch schema name].[connection registration key]_[model_name]_[view_name]となるように格納するDB(データセット)とテーブル名が決まります ↩
-
sql_stepに記述できるDDL文はDBエンジンの制約やLookerで設定したDB実行ユーザの権限によって依存します ↩