はじめに
概要
PyTorchを使ってLSTMとGRUネットワークでアンパンマンの画像の上から半分ずつをシーケンスデータとして学習してアンパンマンの真ん中から下を生成して比較してみました。
比較するためのコードと結果を紹介します。
学習データにはGoogle画像検索から取得したデータとyoutubeから自分でデータを作成しました。
学習データはこんな感じで500枚ほどあります。

生成結果はこんな感じです。

実行環境はGoogle Colabで行いました。
背景
こちらのUdemyの講座
【PyTorch+Colab】PyTorchで実装するディープラーニング -CNN、RNN、人工知能Webアプリの構築-
を受講したのですが、この中でRNNによる画像生成という講義があって、Fashion-MNISTの画像を時系列として捉えて学習して、画像を生成することを学びました。本記事はこちらの応用で、アンパンマンの画像生成をLSTMとGRUで行い、その結果を比べてみます。
対象読者
- PyTorch初心者の方
- RNNで画像生成がどれくらい可能か興味ある方
- LSTMとGRUの違いを視覚的に確認したい方
簡単にLSTMとGRUについて
LSTMはRNNの発展系で、短期/長期の傾向の情報を学習できたり、不要な傾向の情報を忘れたり、どれくらい覚えるかを調整するLSTM層が中間層としてあります。情報をどれくらい取り入れるかだったり、忘れるかだったりはtanhやシグモイド関数を利用するゲートが行っています。
GRUはLSTMの変形ネットワークでLSTMに比べて計算量が少なく、高速な一方、表現力が落ちると言われています。LSTMで設けたゲートよりも種類や数を少なくして、表現力を犠牲にして高速化を図っているようです。
本当にこのような差異が現れるかを本記事では比較してみます。
それでは、データを準備して、コードを説明していきます。
データ準備
データのディレクトリ構成は以下のようにしています。
anpanma/
├ train/
│ └ anpanman/
│ └ *.png x 500+枚
├ val/
│ └ anpanman/
│ └ *.png x 10枚
-
anpanman/trainにはアンパンマンの画像が500枚ほどあります。
-
anpanman/valには下のアンパンマンの画像が10枚あります。

-
anpanman/valの画像を生成して比較してみます。
-
このデータを今回使うGoogle Colabのアカウントに紐づくGoogle Driveにアップロードします。
コード紹介
Google Colabを使ってコードを書いていきます。ランタイムのタイプはGPUにしましょう。
ライブラリimport
まずは今回使用するライブラリをimportします。
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
変数定義
これから使う各変数を定義します。
- 画像データは後で58 * 58 にリサイズします。
-
img_sizeは本記事で使用するの画像データの横方向の長さです。 - LSTM/GRUに学習させるシーケンスの長さ(
seq_length)は画像の縦方向の半分です。画像の縦方向からseq_length分の長さを学習させて、その次の1縦分である1行分を生成します。 - LSTM/GRUに渡す特徴量の数(
input_size)は画像の横方向の長さです。なのでLSTM/GRUに入力するデータのshapeは(batch_size, seq_length, input_size)となります。 - 隠れ層の数(
hidden_size)はハイパーパラメータです。 - 出力層の数(
output_size)は画像の横方向の長さ(img_size)です。1縦分である1行分を生成します。 - 1枚の画像に含まれるシーケンスデータの数(
data_size_in_img)は画像の縦方向の長さの半分の長さです。
# 画像データは後で56*56にリサイズする
# 画像の横方向の長さ
img_size = 56
# シーケンスの長さ(画像の縦方向の半分)
seq_length = 28
# 入力層のニューロン数(画像の横方向の長さ)
# LSTM/GRUに入力する特徴量を画像の横方向の長さ(`input_size`) * シーケンスの長さとする
input_size = img_size
# 隠れ層のニューロン層
hidden_size = 256
# 出力数(画像の横方向の長さ)
output_size = img_size
# 1枚の画像に含まれるシーケンスデータの数
data_size_in_img = 56 - seq_length
Google Driveをマウント
データ準備で準備した3つのデータファイルをGoogle Driveにアップロードします。ここではGoogle Driveの直下に置くことを想定しています。
from google.colab import drive
drive.mount('/content/drive')
transformsを作成
データを変換するためのtransformsを作成します。変換の種類はリサイズと白黒画像化とTensor型変換です。本記事では、生成する画像は白黒画像とします。
# transform作成
transform = transforms.Compose([
# img_size * img_sizeにリサイズ
transforms.Resize((56 ,img_size)),
# 白黒画像にする
transforms.Grayscale(num_output_channels=1),
# Tensor型に変換
transforms.ToTensor()
])
データを分割してdatasetsに変換
学習用と評価用にデータをそれぞれディレクトリを指定して、取得します。
ImageFolder便利です!
# ImageFolderで指定したフォルダごとにラベルを作成してくれる
train_dataset = datasets.ImageFolder("/content/drive/My Drive/anpanman/train", transform=transform)
val_dataset = datasets.ImageFolder("/content/drive/My Drive/anpanman/val", transform=transform)
学習データと評価用データのサイズを確認
意図した通りにデータが入っていることを確認します。
print(len(train_dataset))
print(len(val_dataset))
504
10
学習データからDataLoaderインスタンス作成
batch_sizeをtrain_dataset全てとしてインスタンス作成します。
# batch_sizeは全データ数とするDataLoaderを作成
dataloader = DataLoader(train_dataset, batch_size=len(train_dataset), shuffle=False)
学習データから画像とラベルを取得
学習データからDataLoaderインスタンス作成で作成したdataloaderから画像(train_imgs)とラベル(labels)を取得して、チャンネル数次元を削除します。サンプル数(data_size)は学習データから作成するシーケンスデータの総数です。labelsは使用しません。
# イテレータ化
dataiter = iter(dataloader)
# データ取得
train_imgs, labels = dataiter.next()
# train_imgsのチャンネルの次元を削減 (画像数, channel, H, W) -> (画像数, H, W)
train_imgs = train_imgs.reshape(-1, img_size, img_size)
# シーケンスデータの総数 = train_imgsの数 * 1枚の画像に含まれるシーケンスデータの数
data_size = len(train_imgs) * data_size_in_img
画像データとシーケンスデータの総数を確認
画像データ(train_imgs)のshapeは(画像数, H, W)です。
print(len(train_imgs))
print(data_size)
print(train_imgs.size())
504
14112
torch.Size([504, 56, 56])
シーケンスデータを作成
LSTM/GRUに入力するデータは時系列情報を持たせる必要があリます。ここではLSTM/GRUに入力する入力データ(input_data)と正解データ(correct_data)を作成します。これらの関係は以下の図のようになります。

入力データ(input_data)はシーケンスの長さseq_length分を1枚の画像に含まれるシーケンスデータの数data_size_in_img回ずらして作るデータ群で、正解データ(correct_data)は入力データ(input_data)に対応していて、入力データ(input_data)の次の行データになります。
それではコードを説明していきます。
-
input_data(シーケンスデータの総数, シーケンスの長さ, 画像の横方向の長さ)とcorrect_data(シーケンスデータの総数, 画像の横方向の長さ)をzerosで初期化します。 - 画像データを1枚ずつ、画像中のシーケンスデータの数分ループします。
- そのループの中で入力データ(
input_data)と正解データ(correct_data)にデータを投入していきます。上の図のことを全ての画像データに対して、やっていきます。 - ループが全て終わったら、入力データ(
input_data)と正解データ(correct_data)をTensor型に変換して、Datasetインスタンスを作成して、DataLoaderインスタンスを作成します。DataLoaderのバッチサイズは32でシャッフルします。
# 学習データ初期化
input_data = np.zeros((data_size, seq_length, input_size))
# 正解データ初期化
correct_data = np.zeros((data_size, output_size))
# 学習データ数分ループ
for i in range(len(train_imgs)):
# 1枚の画像に含まれるシーケンスデータの数分ループ
for j in range(data_size_in_img):
# data_size_id = i*シーケンス長+j、0からlen(train_imgs)*シーケンス長までが入る
data_size_id = i*data_size_in_img+j
# input_dataにtrain_imgsのn_time分のシーケンスデータを入れていく
input_data[data_size_id] = train_imgs[i, j:j+seq_length]
# collect_dataにinput_dataの次のデータ(1行分)を入れていく
correct_data[data_size_id] = train_imgs[i, j+seq_length]
# Tensorに変換
input_data = torch.tensor(input_data, dtype=torch.float)
correct_data = torch.tensor(correct_data, dtype=torch.float)
# データセットの作成
dataset = torch.utils.data.TensorDataset(input_data, correct_data)
# データローダの設定
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
入力データと正解データのshape確認
入力データ(input_data)と正解データ(correct_data)のshapeはそれぞれ(シーケンスデータの総数, シーケンスの長さ, 画像の横方向の長さ)と(シーケンスデータの総数, 画像の横方向の長さ)となっています。
print(input_data.size())
print(correct_data.size())
torch.Size([14112, 28, 56])
torch.Size([14112, 56])
LSTM/GRUモデルを定義
ここでは、LSTMとGRUモデルのクラスを定義します。両者のコードの違いとしては、self.rnnで呼び出すネットワークだけです。
import torch.nn as nn
import torch.nn.functional as F
# モデルの構築
class LSTM(nn.Module):
def __init__(self):
super().__init__()
# LSTM層にはinput_sizeにはimg_size、hidden_sizeはハイパーパラメータ、batch_firstは(batch_size, seq_length, input_size)を受け付けたいのでTrueにする
self.rnn = nn.LSTM(input_size=input_size, hidden_size=hidden_size, batch_first=True)
# 全結合層のinputはLSTM層のoutput(batch_size, seq_length, hidden_size)と合わせる。outputはimg_size
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# y_rnnは(batch_size, seq_length, hidden_size)となる
y_rnn, (h,c) = self.rnn(x, None)
# yにはy_rnnのseq_length方向の最後の値を入れる
y = self.fc(y_rnn[:, -1, :])
return y
lstm = LSTM()
lstm.cuda()
print(lstm)
LSTM(
(rnn): LSTM(56, 256, batch_first=True)
(fc): Linear(in_features=256, out_features=56, bias=True)
)
# モデルの構築
class GRU(nn.Module):
def __init__(self):
super().__init__()
# GRU層にはinput_sizeにはimg_size、hidden_sizeはハイパーパラメータ、batch_firstは(batch_size, seq_length, input_size)を受け付けたいのでTrueにする
self.rnn = nn.GRU(input_size=input_size, hidden_size=hidden_size, batch_first=True)
# 全結合層のinputはGRU層のoutput(batch_size, seq_length, hidden_size)と合わせる。outputはimg_size
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# y_rnnは(batch_size, seq_length, hidden_size)となる。LSTMと違ってcellはない。
y_rnn, h = self.rnn(x, None)
# yにはy_rnnのseq_length方向の最後の値を入れる
y = self.fc(y_rnn[:, -1, :])
return y
gru = GRU()
gru.cuda()
print(gru)
GRU(
(rnn): GRU(56, 256, batch_first=True)
(fc): Linear(in_features=256, out_features=56, bias=True)
)
評価用データから画像とラベルを取得
学習データから画像とラベルを取得と同様に評価用データをバッチサイズ(disp_size=10)でシャッフルなしでDataLoaderインスタンスを作成して画像(disp_imgs)とラベル(labels)を取得します。
# 評価用データ作成
# 生成し表示する画像の数
disp_size = len(val_dataset)
# batch_size=disp_sizeでデータローダの設定
disp_loader = DataLoader(val_dataset, batch_size=disp_size, shuffle=False)
# イテレータ化
dataiter = iter(disp_loader)
# データ取得
disp_imgs, labels = dataiter.next()
# チャンネル数の次元を削減
disp_imgs = disp_imgs.reshape(-1, img_size, img_size)
LSTM/GRUで画像生成する関数の定義
この後に学習の際に、アンパンマン画像の生成具合を確かめるための関数を定義します。
- まず最初に評価用データを全ての枚数横並びで表示します。
- 次にLSTMで生成した画像を表示します。そのループの中でまずは評価用データの画像の上からシーケンスの長さ分をLSTMの入力データに使うため、(batch_size, seq_length, img_size)に調整します。
- LSTMの出力は1縦分、1行分の生成されたデータが入っていて、shapeは(batch_size, img_size)となっているので、batch_size方向を除いて、先ほどLSTMに入力したデータの次の行に代入します。
- という感じで生成したデータをループごと代入していって、次の生成のための入力データに使います。
- このループを評価用データごとに行って全ての評価用データに対する画像生成が終わったらその画像を横並びに表示します。
- GRUもLSTMと同様です。
- 書き方が冗長なんですが、ご容赦ください、、
# 画像生成用の関数
def generate_images():
# オリジナルの画像(disp_imgs)の表示
print('Original:')
plt.figure(figsize=(20,2))
# n_disp回ループする
for i in range(disp_size):
# subplot(1行, 10列, サブ領域No)
ax = plt.subplot(1, disp_size, i+1)
plt.imshow(disp_imgs[i], cmap='Greys_r', vmin=0.0, vmax=1.0)
# 軸を非表示にする
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
# 下半分をRNNにより生成する
print('LSTM Gen:')
# disp_imgsをクローンする
lstm_gen_imgs = disp_imgs.clone()
plt.figure(figsize=(20,2))
# n_disp回ループする
for i in range(disp_size):
# 1枚の画像に含まれるシーケンスデータの数
for j in range(data_size_in_img):
# 予測のための入力値をi番目のgen_imgsのシーケンス長分とする
# (i, H, W)を(batch_size, seq_length, img_size)にする
x = lstm_gen_imgs[i, j:j+seq_length].reshape(1, seq_length, img_size)
# GPU対応
x = x.cuda()
# gen_imgsのシーケンス分の次のデータ(1w分)に予測値(1w分)を代入する
# 次のループでは、代入した予測値を含む入力値でまた予測する
# net(x)[0]として、batch_size方向を取る(batch_size, img_size) -> (img_size)
lstm_gen_imgs[i, j+seq_length] = lstm(x)[0]
# subplot(何行か, 何列か, サブ領域No)
ax = plt.subplot(1, disp_size, i+1)
plt.imshow(lstm_gen_imgs[i].detach(), cmap='Greys_r', vmin=0.0, vmax=1.0)
# 軸を非表示にする
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
print('GRU Gen:')
gru_gen_imgs = disp_imgs.clone()
plt.figure(figsize=(20,2))
for i in range(disp_size):
for j in range(data_size_in_img):
x = gru_gen_imgs[i, j:j+seq_length].reshape(1, seq_length, img_size)
x = x.cuda()
gru_gen_imgs[i, j+seq_length] = gru(x)[0]
ax = plt.subplot(1, disp_size, i+1)
plt.imshow(gru_gen_imgs[i].detach(), cmap='Greys_r', vmin=0.0, vmax=1.0)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
学習と画像生成
- 損失関数は平均二乗誤差、最適化関数はAdamを使用します
- 1epochでLSTM/GRU、それぞれについて、学習します。
- 学習内容は、損失計算 -> 勾配初期化 -> 逆伝播 -> 最適化です。
- 100回ごとに、LSTM/GRUの損失値と累積学習時間とLSTM/GRUで画像生成する関数の定義で定義した関数
generate_images()を呼び出して、画像生成結果を表示します。
from torch import optim
import time
# 学習
loss_fnc = nn.MSELoss()
# 最適化アルゴリズム
lstm_optimizer = optim.Adam(lstm.parameters())
gru_optimizer = optim.Adam(gru.parameters())
# LSTM/GRUの損失を入れる変数を初期化
lstm_record_loss_train = []
gru_record_loss_train = []
# LSTM/GRUの学習時間を入れる変数を初期化
lstm_record_total_time = 0
gru_record_total_time = 0
for i in range(501):
# ネットワークを学習モードにする
lstm.train()
gru.train()
# epochごとに記録する損失を入れる変数を初期化
lstm_loss_train = 0
gru_loss_train = 0
# LSTMの学習
lstm_start = time.time()
for j, (x, t) in enumerate(train_loader):
x, t = x.cuda(), t.cuda()
y = lstm(x)
loss = loss_fnc(y, t)
lstm_loss_train += loss.item()
lstm_optimizer.zero_grad()
loss.backward()
lstm_optimizer.step()
lstm_elapsed_time = time.time() - lstm_start
# GRUの学習
gru_start = time.time()
for j, (x, t) in enumerate(train_loader):
x, t = x.cuda(), t.cuda()
y = gru(x)
loss = loss_fnc(y, t)
gru_loss_train += loss.item()
gru_optimizer.zero_grad()
loss.backward()
gru_optimizer.step()
gru_elapsed_time = time.time() - gru_start
# バッチサイズで割って1epochの損失の平均を取る
lstm_loss_train /= j+1
lstm_record_loss_train.append(lstm_loss_train)
gru_loss_train /= j+1
gru_record_loss_train.append(gru_loss_train)
# 学習時間の全体時間を計算
lstm_record_total_time += lstm_elapsed_time
gru_record_total_time += gru_elapsed_time
# 100回に1回、LSTM/GRUの損失と画像生成結果を表示する
if i%100 == 0:
print(f"Epoch: {i}, LSTM_Loss_Train: {lstm_loss_train}, GRU_Loss_Train: {gru_loss_train}, LSTM Elapsed_Time: {lstm_record_total_time}, GRU Elapsed_Time: {gru_record_total_time}")
generate_images()
初回の学習時、まぁそんなにLSTMとGRUで差はないですね。

101回目の学習時、若干LSTMが上手そうですかね。特に左から6番目のLSTMはとても良いです。

201回目の学習時、LSTMの方がアンパンマンの口が上手くできているように見えます。

301回目以降の学習時では、もうどっちもどっちで、どっちが上手く生成できているかは判断できませんね。

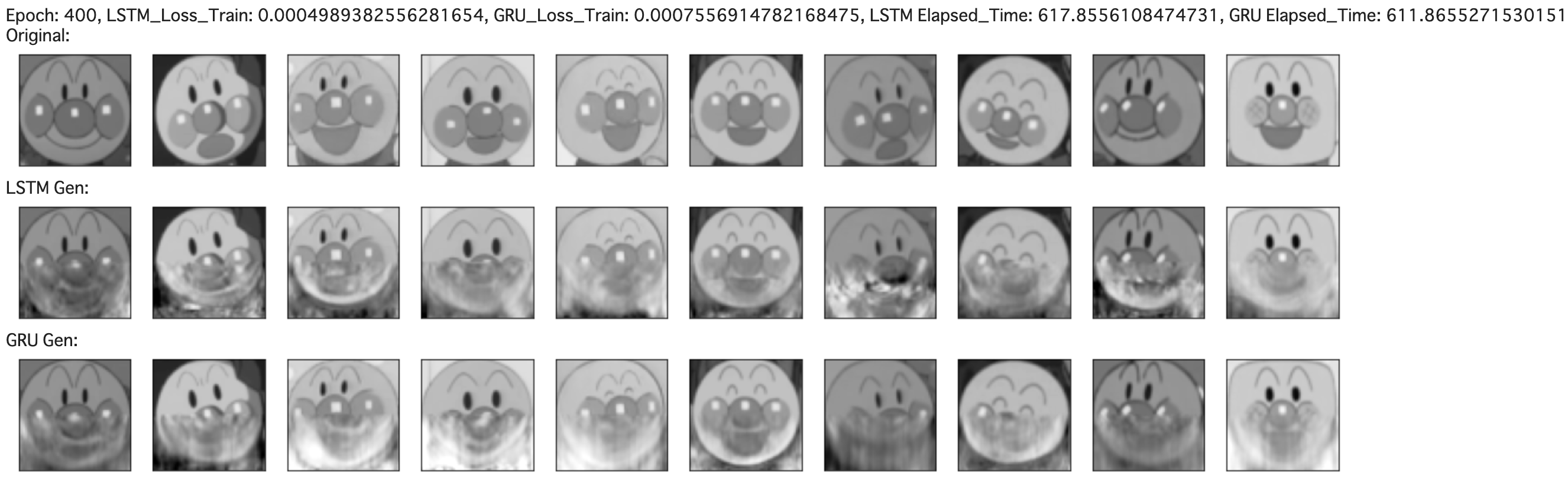

評価用の画像データが真正面を向いているものに関しては、LSTMもGRUもどちらも鼻と頬、口、輪郭を捉えることができました。
どっちが上手く生成できたかは、、遜色ないですが、LSTMの方でしょうかね。
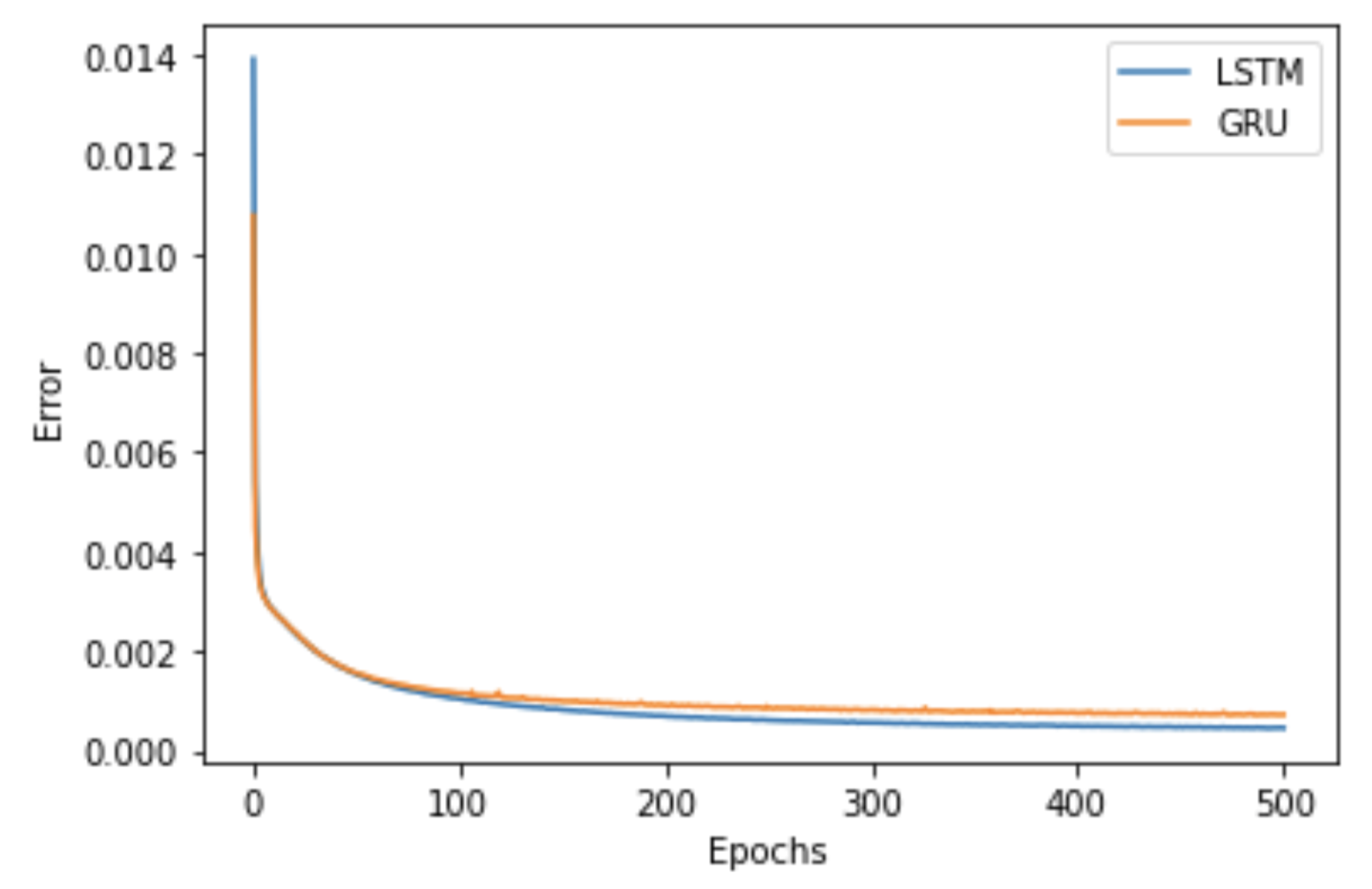
LSTM/GRUの学習時の損失をグラフ表示
LSTMとGRUの損失はLSTMの方が低いです。
plt.plot(range(len(lstm_record_loss_train)), lstm_record_loss_train, label='LSTM')
plt.plot(range(len(gru_record_loss_train)), gru_record_loss_train, label='GRU')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Error')
plt.show()
LSTM/GRUの学習にかかった時間の差分を表示
501回学習して、LSTMの方がGRUより7秒以上、遅いという結果になりました。
print(f'LSTMとGRUとの経過時間の差: {lstm_record_total_time - gru_record_total_time}')
LSTMとGRUとの経過時間の差: 7.401566982269287
終わりに
**本記事では、PyTorchを使ってLSTMとGRUの画像生成結果を比較してみました。**結果としては、あまり差はないですが、LSTMの方が、アンパンマンをうまく生成することができましたが、GRUの方が学習は早いという結果になりました。
全てのコードはhttps://github.com/tsubauaaa/LSTM_vs_GRU_generate_Anpanman/blob/master/LSTM_vs_GRU_generate_Anpanman.ipynb こちらをご確認ください。
最後までお読みいただきまして、ありがとうございました。