GYAOのtsです。
我々のチームは、オールパブリッククラウドで、Microservice Architectureを採用した次期バックエンドを設計中です。
経緯
前回の投稿でjsonをBlobコンテナに用意したので、今回はそれを取り込んで、1ドキュメントずつServicebusにpublishする。また、別のfunctionでそれをsubscribeし、DocumentDBにstoreする。
json:testLines.json
{ "original_id" : "1", "b":false , "c":0 , "d":1 , "e":2 , "f":0.345 , "g":"あ" , "h":"い" }
{ "original_id" : "2", "b":false , "c":0 , "d":1 , "e":2 , "f":0.345 , "g":"あ" , "h":"い" }
{ "original_id" : "3", "b":false , "c":0 , "d":1 , "e":2 , "f":0.345 , "g":"あ" , "h":"い" }
servicebusの準備
 topicは作成しておく。
topicは作成しておく。
AzureFunctions(publish)
今回は言語はC#でいく。理由は一番できることが多いから。その理由で行くと、
選択肢はC#, js, F#かな。
統合
 当然inputはblob、outputはDocumentDB。
当然inputはblob、outputはDocumentDB。
NuGet
ファイルを1行1行読むのはいいが、それを1件ずつパースする。
楽チンパースするために今回はJson.NETを使用する。NuGetでinstallする。
 左下のFunctions APPの設定からAppServiceエディターに移動。
左下のFunctions APPの設定からAppServiceエディターに移動。
 project.jsonを作成する。
project.jsonを作成する。
project.json
{
"frameworks": {
"net46":{
"dependencies": {
"Newtonsoft.Json": "9.0.1"
}
}
}
}
project.lock.jsonが自動で作成される。
これでinstall完了。
開発
using System.IO;
using System.Text;
using Newtonsoft.Json;
public static void Run(string myBlob, string name, Stream inputBlob, ICollector<string> outputSbMsg, TraceWriter log)
{
log.Info($"C# Blob trigger function Processed blob\n Name:{name} \n Size: {myBlob.Length} Bytes");
StreamReader reader = new StreamReader(inputBlob, Encoding.UTF8);
string line;
while ((line = reader.ReadLine()) != null)
{
Item item = JsonConvert.DeserializeObject<Item>(line);
string id = item.Id;
if (String.IsNullOrEmpty(id)) {
outputSbMsg.Add(line);
}
else {
log.Info("can't accept id.");
}
}
reader.Close();
}
public class Item
{
[JsonProperty("id")]
public string Id { get; set; }
}
AzureFunctions(subscribe)
こっちはかなりシンプル
統合
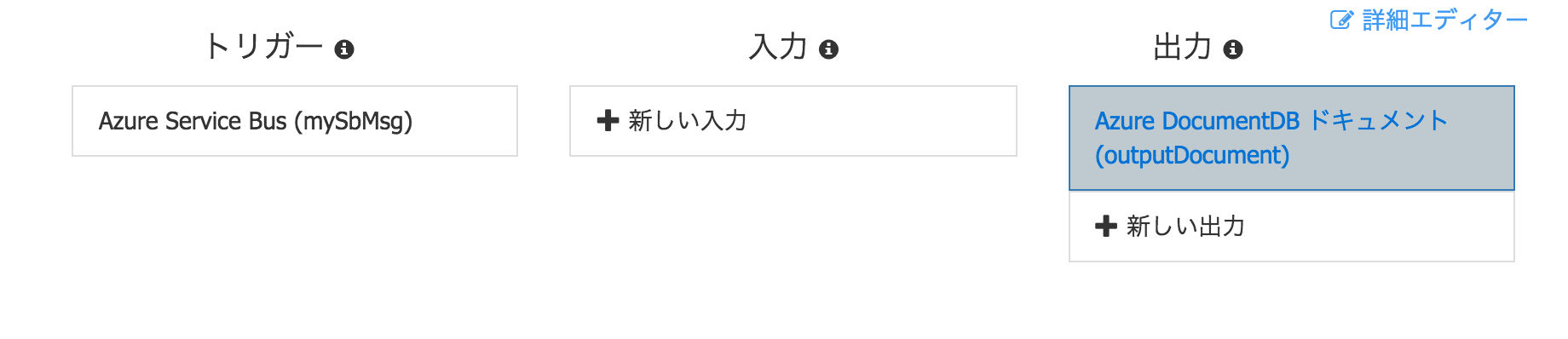
開発
using System;
using System.Threading.Tasks;
public static void Run(string mySbMsg, out object outputDocument, TraceWriter log)
{
// log.Info($"C# ServiceBus topic trigger function processed message: {mySbMsg}");
outputDocument = mySbMsg;
}
次回
以上でBlobのコンテンツトリガでDocumentDBへの保存までが完了。
Servicebusのtopicを通してあるので、subscriberを新たに増やすことで同じデータがブロードキャストされる利点はある。
次回はMachineLearningと連携してみる。