はじめに
@sugaretさんの、「モバイルゲーム運用におけるマスターデータ管理の話あれこれ」を読んで、自分も書き溜めてたメモがあったので整理してみようかと。やってみたら思ってた以上に大変でした…
これを書いた人
- スマホゲーム開発のテクニカルディレクター(技術系雑用係)
- 元々は非ゲーム系のエンジニア(C,Java)
- いわゆるJenkinsおじさん。Gitlabサーバーなどの管理も
- Ruby 好き
- PlantUML 好き
- お仕事募集中?
想定読者
いわゆるスマホ向けのオンラインゲーム開発における、マスターデータの運用フローに悩むディレクター/エンジニア/プランナー
マスターデータの開発・運用にあたって、
- どのようなことを決めなければならないのか
- どの作業に工数がかかり、ミスが起きやすいのか
- どのような工夫をしたか
を整理しています。@sugaretさんの記事に比べると、開発フェーズにフォーカスした話も多いです。
マスターデータ周りって、開発の終盤まで仮実装で突き進んでたり、運営がはじまってからも日々細かなトラブルを人力で解決してたり、というケースが、いまもあちこちに転がってるんじゃないかと思います。
ですが、 開発の最初期からしっかりワークフローを組むことで、大きなメリットがありますよ、それはそのまま運用にも活かせますよ 、という話です。
チーム規模としては、プログラマーとプランナーがそれぞれ3〜10名くらいいる構成を想定しています。さらに規模が大きくても適用可能だろうとは思います。が、各1〜2名で開発期間が3カ月、のように規模が小さい場合はコスト過剰かもしれません。
前提として理解しておくべきポイント
先に、マスターデータについて理解しておくべき点を整理しておきます。
以下を理解できている場合は、次の章(課題と解決方針)まで読み飛ばしても構いません。
- マスターデータは複数の表の集合
- マスターデータには「構造」と「値」がある
- 構造:それぞれの表がどのような列を持ち、それらがどのように参照しあうか
- 値:それぞれの表のそれぞれの列に入る値
- マスターデータの値は頻繁に変更される
- ゲームの仕様が変われば、マスターデータの構造も変わる。特に開発中はそれが頻繁に起きる
- マスターデータの構造が変われば、それを参照するサーバー及ぶクライアントのプログラムも変更が必要になる
- したがって、マスターデータの構造の変更には、プランナーとエンジニアのコミュニケーションが必須
マスターデータとは
ゲームの動作やバランスを決定するためにあらかじめ設定しておく、表形式で表せるパラメータ。実際の開発現場では、単に「マスター」と呼ばれることが多いです。プレイヤーごとに値が変化するデータ(こちらはユーザーデータと呼ぶことが多いようです)は含めません。
多くのスマホゲームは、アプリ起動時に最新のマスターデータをダウンロードし、そのデータを参照しながら動作します。また、サーバー側のプログラムも、同様にマスターデータを参照します。
プログラムとマスターデータを分離しておくことで、
- マスターデータ部分は非プログラマでも容易に変更できる
- マスターデータの更新だけで済む場合は、アプリのバージョンアップを回避できる(アプリのバージョンアップは、林檎様の審査を通したりしなければならず時間がかかる)
といったメリットがあります。
マスターデータの例
例えば、これから開発しようとしているゲームに、以下のような仕様があるとします。
- このゲーム内には「武器」がある
- 武器にはそれぞれ「名前(name)」と「攻撃力(attack)」というパラメータがあり、装備一覧表示時に使う「アイコン(icon)」のファイル名も必要
- 武器はそれぞれ1つの「必殺技(skill)」を持つ
- 必殺技にも「名前(name)」があり、使用時の「攻撃力(attack)」を通常の攻撃とは別に持つ
- 必殺技には、炎や風といった「属性(attribute)」がある
実際のゲームではもっと複雑になりますが、ここまでを元にしたマスターデータのサンプルはこんな感じになります。
「武器」のマスターデータ
| id | name | attack | icon | skill_id |
|---|---|---|---|---|
| 1000 | 大地の剣 | 100 | sword1.png | 1 |
| 1001 | 風の剣 | 200 | sword2.png | 2 |
| 1002 | 氷の槍 | 300 | lance1.png | 3 |
| 1003 | 炎の槍 | 400 | lance2.png | 4 |
「必殺技」のマスターデータ
| id | name | attack | attribute |
|---|---|---|---|
| 1 | アースアタック | 200 | 4 |
| 2 | ウインドアタック | 400 | 3 |
| 3 | アイスアタック | 600 | 2 |
| 4 | ファイアアタック | 800 | 1 |
「必殺技」の属性の定義
炎=1
氷=2
風=3
土=4
※「武器」マスターのskill_id列に入っているのは、「必殺技」マスターのIDです。このように、ある表が別の表への参照を持つことは非常に多いです。
このように、マスターデータには「構造(=どのような表や列が必要なのか)」と「データ(=実際に表に入れる値)」があり、構造はゲームの仕様、さらには プログラムの作りやすさや変更しやすさ と極めて密接に関連します。
一方で、多くの場合、値を決めるのはプランナーの担当領域でプログラマは関与しません。ただ、プランナーにとっても、マスターデータの構造は データの把握しやすさ・変更しやすさ に直結する重要なポイントとなります。
なお、最後に出てくる『「必殺技」の属性の定義』は、今回説明する事例においてはマスターデータではありません。マスターデータとして定義することも可能ですが、そうしなかった理由があります。これについては後ほど。
マスターデータの制作フロー
以下は、このドキュメントが想定するフローです。
もしかしたら、マスターデータの構造をプランナーが決めてるケースはあるかもしれませんが、他はどこの現場でも大差ないはずです。
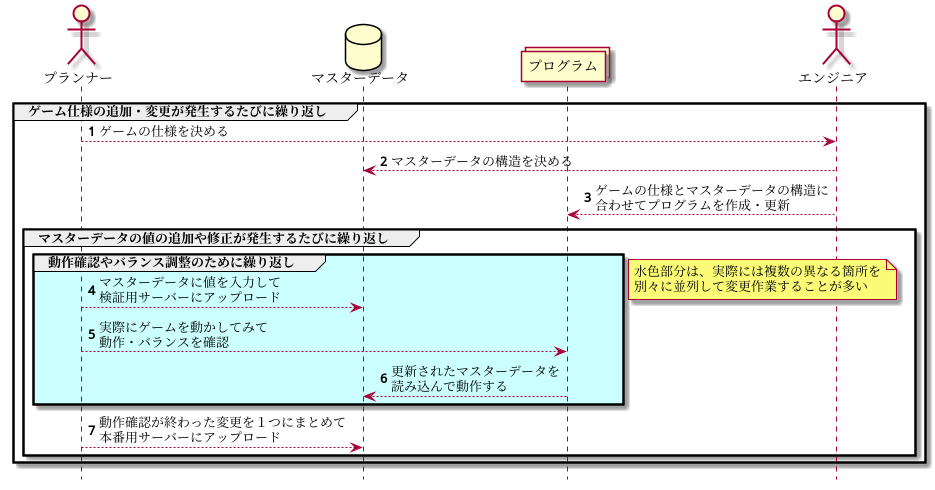
課題と解決方針
前置きが長くなりましたが、ここからが本題です。
実際の開発現場での実体験をもとに抽出した課題と、私がとった解決方針を書いていきます。
課題1: 入力・閲覧・検索がしやすいこと
マスターデータに関する作業のうち、最も時間が費やされるのが値の入力・修正です。
したがって、マスターデータをどのようなファイルフォーマットにし、どのツールで編集するのかは重要です。
自分が知る限り、多くの会社で、ExcelかGoogleスプレッドシートのどちらかが使われているようです。
→ マスターデータはExcelで保存
方針として、 マスターデータはExcelファイル形式(.xlsx)で保存 するようにしました。
ここで読むのをやめる人が半分くらいいそうな気がします・・・気持ちはよくわかります。エンジニアの皆さんはExcelが大嫌いです(ちなみに、今回説明するフローでは、VBAは一切使っていません)。
さらに、Googleスプレッドシートには、同じシートを同時に複数の人が編集できるという、非常に魅力的に思える利点もあります。
ではなぜExcelを選択したのか、それについては次の項目で。
課題2: 変更箇所を誰もがすぐ把握できること
マスターデータの変更は、ゲームの動作に大きな影響を与えます。これはつまり、マスターデータの値の変更には細心の注意が必要、ということです。
他のメンバーが行った変更点を素早くレビューしたい、というケースは非常に多いですし、「なんでこの箇所にこんな値が入ってるのか?」を過去に遡って調べなければならなくなる、なんてこともザラです。
さらに、残念なことに人間はミスをする生き物なので、変更するつもりじゃなかった箇所まで変更してしまったり、あとで元に戻すつもりだったテストデータを戻し忘れたりすることも(稀によく)あります。
日々の作業の効率を落とさないためには、全てのマスターデータに対して、 「いつ、誰が、どういう目的で、どの表の、どの箇所を、どのように変更したのか」を誰もが後から把握できるような仕組み が必要です。
→ マスターデータはGitで管理
方針として、 マスターデータのExcelファイルと、そこから生成したCSVファイルを、Gitで管理 するようにしました。
Gitはまさに、「いつ、誰が、どういう目的で、どのファイルの、どの箇所を、どのように変更したのか」を管理するための、極めて強力かつよく使われているツールです。
前項で読むのをやめなかった人のさらに半分が、ここで読むのをやめる気がします・・・気持ちはよくわかります。プランナーの皆さんはGitが大嫌いです(使ったことがない人に使わせると、たいていの人は3日で大嫌いになります)。
ただ、実際にマスターデータのExcelファイルをGitで管理してみた経験から断言しますが、これによって得られる 「いつ、誰が、どういう目的で、どの表の、どの箇所を、どのように変更したのか」を誰もが後から把握できる という恩恵は、Gitを学習するためのコスト・バイナリ形式であるExcelファイルを手動でマージする手間・Gitに不慣れなメンバーをエンジニアがフォローする負担などなどを踏まえても、十分に見合うものです。
ちなみに、Googleスプレッドシートにも履歴機能はありますが、それぞれの変更をどういう目的で行ったのかを記録できない、差分が把握しづらいなど、機能が貧弱すぎてそのままでは使い物になりません。
例えば、マスターデータが100個のスプレッドシートで構成されていて、それを5人のプランナーで作業している場合に、「プランナーAさんが昨日の朝10時以降に変更した箇所をすべて抽出したい」といった状況が発生したら、どれだけの手間がかかるかは想像したくもありません。が、Gitで管理していれば、これは数秒で終わる作業です。
というわけで、前項でExcelを選択した理由は、Excel形式のファイル(とcsvの組み合わせ)ならGitで管理できるからです。Googleスプレッドシートで同様のことをやるには専用のツールを自前で作らねばならず、しかもGit以上の利便性は得られそうになかったので…
課題3: 管理フローを全員に徹底できること
マスターデータは複数の表で構成され、それを複数の開発メンバーが編集&参照します。
さらに、マスターデータは、全員で同じ内容を1セットだけ共有するわけではありません。作業の目的別に複数のセットを用意し、それらを同時並行で参照・編集するのが常です。(運営中の「安定版」にはアイテムを追加しつつ、将来向けに開発している「機能追加版」ではマスターの構造にまで手を入れる、といった具合に)。
このような状況下では、 表を管理するためのルールを明確にし、さらにそれを全員が守っている状態を常に維持 しないと、待っているのはカオスの一言です。しかし人間はミスをする生き物であり、これはカオスな状況に拍車をかけます。
→ Gitのフローを工夫して管理ルールを半強制する
マスターデータをGitで管理することによるメリットとして、管理ルールを明確化&強制しやすくなりますし、作業セットをいくら増やしても混乱することがなくなります。具体的には、
- 1つの表につき1つのExcelファイルにして、Excelファイルの集合でマスターデータを構成する
- 各表のExcelファイルと、そこからデータ部分を書き出したcsvファイルとを、常に両方セットでGit管理
- 「安定版」や「機能追加版」に対してリリース用のブランチを作り、
- そこからさらに作業目的ごと(アイテム追加, バトルバランス調整, etc...)のブランチを作る
- リリース用のブランチへのマージは要テスト&レビュー
という、GitHubフローの変形を使いました。Excelファイルはバイナリなので、差分を追跡できるように、対応するcsvファイルをツールで自動生成しています。
ここでもう1つ重要なのは、 作業目的ごとにブランチを細かく切ること です。
これによってマスターデータの更新差分のレビューが容易になります。
また、ブランチ間の差分も必然的にシンプルになるため、Excelを使う際の大きなデメリットとなる作業内容の手動マージも、基本的には行もしくは列をシンプルにコピペする程度で済むようになり、手間は許容範囲内に収まります。マージ差分もcsv形式で簡単にチェックできるため、マージミスがあってもすぐに気づけます。
また、トラブルが発生したときのリバートや、マージの際のチェリーピックなども比較的容易に行えます。
作業目的ごとにブランチを切るのはGitを使用した開発フローの定石でもありますが、これによって、「 マスターデータのマージ作業や、トラブル時の修正作業を、マスターデータの該当箇所を編集したメンバーがいなくても対応できる ケースが大幅に増える」 という非常に大きなメリットが得られます。
一方で、 「Googleスプレッドシートのように同じシートを複数人が編集できてしまうと、変更差分と変更目的の追跡が困難になる」 ので、今回のような管理手法を使う場合、Googleスプレッドシートはむしろ相性が悪い、と言えます。
課題4: 構造定義の変更を、全員に、素早く、齟齬なく共有できること
ゲーム仕様に合わせて、マスターデータの構造定義、すなわち、
- それぞれの表にどのような列(パラメータ)が必要か
- それぞれの列にどのようなルールで値を入れるのか
を決めなければなりません(例えば、「武器」のマスターデータには「攻撃力」という列が必要で、その値は0〜65535の範囲の整数になる、といった具合)。
実際の開発では、ゲームの仕様を試行錯誤する過程で、表にパラメータを追加したり削除したり、という変更が極めて頻繁に発生します。
そして、マスターデータの構造を変更すると、それに合わせてサーバー及びクライアントのプログラムも修正が必要です。
そうすると、 仕様の更新とマスターデータの構造の更新をきっちり合わせなければならない のですが、仕様を試行錯誤するためのスピード感を重視すると、マスターデータの構造の更新が追いつかず、仕様がどこまで反映されているのかがあいまいになってしまいがちです。
かといって、試行錯誤のためのスピード感を保てないような、負担が大きいフローにしてしまうのも問題です。
これらの結果として、最初に書いたように、「マスターデータ周りって、開発の終盤まで仮実装で突き進んでたり〜」なんてことになってしまいがちではないでしょうか。
ここで重要になるのは、「マスターデータの構造定義を更新し、サーバーとクライアント側のプログラムに変更を反映」するための手間(と心理的ハードルの高さ)を、どれだけ削減できるか、ということです。
→ 構造定義とデータを同じファイルに書く
まず、 マスターデータのExcelファイルの先頭のシートを、マスターデータの構造定義記述用にし、これを仕様とする ようにしました。
構造定義は自由記述ではなく、プログラムから読み取れるように書式を決めています。
→ 構造定義からコードを自動生成
そのうえで、 マスターデータに書いた構造定義をベースに、クライアント及びサーバープログラム用のマスターデータ読み込みコードを自動生成 しています。自動生成にはApache thriftを使っています。
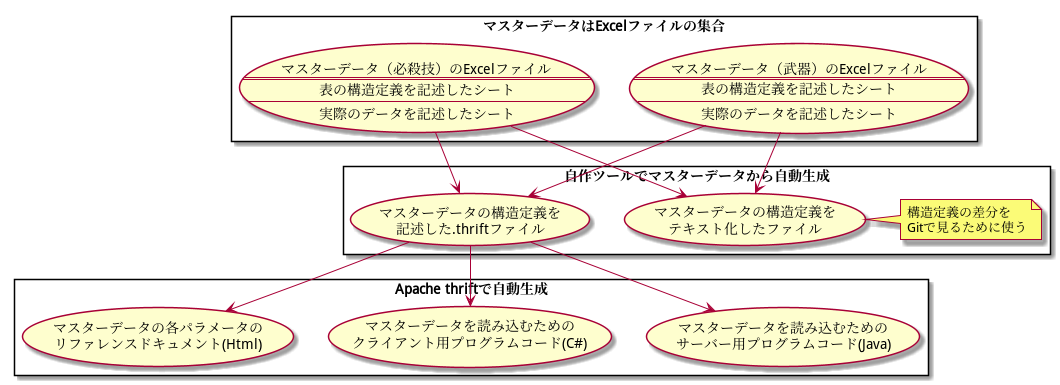
Apache thriftは、「データの構造を定義したファイルから、その構造のデータを参照するためのコードを、様々な各プログラミング言語向けに自動生成してくれる」ツールだと思ってください。ちなみに、プログラムだけじゃなく、Html形式のドキュメントも生成できます。
マスターデータの構造定義が変更されても、少ない手間で新しい構造のマスターデータを読み込めるようにプログラムを修正できるため、仕様の試行錯誤を繰り返す開発初期〜中期フェーズにおいても有用でした。
パラメータ名を変更したり、不要なパラメータを削除したり、といったリファクタリングもやりやすいです。
また、マスターデータの構造定義をテキスト化したファイルをGitで管理することにより、構造定義の変更履歴を追跡できます。これも、開発チーム内の情報共有に役立ちます。
課題5: データの変更ミスを素早く検出できること
マスターデータを何度も変更していくと起きやすいトラブルの原因の多くは、値の入れ間違いや不整合です。
「武器の表に設定されている必殺技のIDが、必殺技の表には書かれてない」とか、「男性キャラ専用の武器なのに、女性キャラしか使えないはずの必殺技がセットされている」とか。
このような値の間違いや不整合を検出する処理を「バリデーション」と呼びます。
特に開発中はゲームの仕様が二転三転するため、細かい仕様変更がドキュメントに埋もれてしまうこともありますし、仕様変更によって、昨日まで正しかった値が今日からは不正な値になることもしょっちゅうです。つまり、バリデーション処理も、日々の仕様変更に合わせて更新していかなければなりません。
これ、かなり面倒なことに思えます。そのためどうしても、 「マスターデータの値のバリデーションは、仕様が落ち着くまで後回し」 になりがちです。
→ バリデーションを後回しにしない
しかし、以下の理由から、 「バリデーションを開発初期から行っておく方が、チーム全体の開発コストは減る」 というのが実感です。
- マスターデータを動作確認してみて初めてミスに気づくより、マスターデータを保存してすぐに気づけたほうが、プランナーの手戻りが小さい
- マスターデータの問題箇所を目視で探すよりも、機械的に検出するほうが早くて確実
- 仕様の細部になればなるほど、仕様に矛盾があっても、実際に実装してみないとそれに気づけない
- 仕様の細部になればなるほど、コミュニケーションミスによるマスターデータの値の解釈ズレが発生しやすい
特に3・4番目が見落とされがちじゃないかと思いますが、「〇〇マスターの△△の列が□□になっている場合に限り、▲▲の列の値が効果を発揮する」みたいな「例外的な仕様」って、ゲームを作っていくと山のように発生します。が、それが仕様書の端っこに書かれるだけだと簡単に埋もれます。その仕様を後から更に二転三転させたりすると、もはや何が正しいのかわからなくなります。
そして、この手の問題は、一度見逃されてしまうと、それが発覚するまでに長い時間がかかります。
バリデーション処理を早期に&できるだけ厳密に実装し、さらに、このような仕様に対するチェックも含めておくことで、プランナーの作業手戻りも、仕様変更時の作業漏れも減らせます。
メリットの多くを享受するのがプランナーで、バリデーション処理を実装するのがプログラマーのため、どうしても敬遠されがちではありますが、全体で見た場合には、かけたコストに十分に見合うリターンが得られるはずです。
→ バリデーションはプランナーの手元で実施
マスターデータを修正してバリデーションする、のサイクルをできるだけ高速に回せるようにすることが大事です。
内製のバリデーションツールをローカルのPC上で実行できるようにしてあるので、原則としてはバリデーションをパスしないマスターデータは、GitリポジトリにPushされずにすみます。
その上で、GitリポジトリにマスターデータをPushしたときに、Jenkinsを使って自動的にバリデーションするようにしてあります。
課題6: マスターデータの参照関係が把握しやすいこと
冒頭の例でも書いたように、マスターデータを構成する表は、別の表への参照を列として持つ場合があります。
マスターデータの構造が複雑化してくると、このような参照も増えていきます。参照が増えれば増えるほど、 「この表の、この列をいじったとき、他の表にどういう影響が出るのか」がわかりにくい 状態になってしまいます。
→ マスターデータの参照関係を可視化する
マスターデータの構造定義記述用のシートに参照関係を記述し、それをPlantUMLを使って可視化する ようにしました。
PlantUML は、テキスト形式でUMLを書くと、いい感じにレイアウトした画像を自動生成してくれるツールです。
UMLってなに?というのは置いといて、例えば、マスターデータの例に出てきた武器と必殺技の表とその参照関係を、PlantUML用に書くとこうなります。
Object Weapon {
+id
--
name
attack
icon
skill_id
}
Object Skill {
+id
--
name
attack
attribute
}
Skill <-- Weapon : skill_id
このテキストをPlantUMLに入力すると、
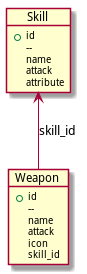
のような画像が自動生成されます。
これを使って、マスターデータの構造定義を変更したら、表の依存関係を可視化した図を自動で更新するように しています。
具体的に言うと、先に書いたように、マスターデータの構造定義を変更するたびに.thriftファイルを自動生成していますが、そのついでに、参照関係を可視化するためのPlantUML記述を埋め込んだマークダウンファイルも自動生成し、GitリポジトリにPushしています。
マスターデータの構造定義を変更したら、「各種ファイルを自動生成してGitリポジトリにPushするだけ」で、ブラウザ上で常に最新のマスターデータの依存関係を可視化した図を確認できるため便利です。
(セルフホスト版のGitLabだとマークダウンに埋め込んだPlantUMLをレンダリングできますが、できないシステムのほうが多いかも・・・)
この例に限らず、PlantUMLは、論理的な構造を記述するだけで様々な図を自動生成してくれます。マウスを使って矢印を繋いだり、箱の大きさをいじったり、項目が増えるたびに箱の配置を修正しなおす必要はありません。
今回のように実装をリバースエンジニアリングして可視化する以外にも、シーケンス図を書いたり依存関係を整理したりといった用途で有用です。
もちろん、このページに出てくる図は、全てPlantUMLで書かれています。
課題7: 列挙型の定義を管理しやすくすること
(マスターデータの例)の項に出てきた『必殺技の属性の定義(炎=1、氷=2・・・)』のような、いわゆる列挙型の定数は、値を変更した場合のプログラムに対する影響度が極めて大きいため、マスターデータ形式にせず、プログラム内に直接定義することが多いのではないかと思います。
しかし、これらの値もゲームの仕様変更によって意味が変わりますし、サーバーとクライアントのプログラマ、マスターデータを入力するプランナーが認識を合わせて作業する重要性と難しさは、すでに書いてきたとおりです。
→ 列挙型の定義もGit管理し、コードを自動生成する
Apache thriftを使って、マスターデータの構造定義からアクセスコードを自動生成した話を先に書きました。列挙型(いわゆるEnum)も同様に定義ファイルをGitで管理し、サーバー用とクライアント用のコードを自動生成しています。
雑多な補足
- 内製ツールは、ほぼRubyで書きました。主にrubyXLというライブラリを使って.xlsxファイルを読み書きしています
- 生成したマスターデータは、GitのSHA-1を使って管理しています。配信サーバーに格納するときもSHA-1をファイル名の一部に使うことで、取り違えが起きにくくなりました。
- 自動生成するファイルは、元となるファイルを変更した人のローカルPC上で全て生成し、コミット時に事前チェックした上でリポジトリにpushしてもらうようにしています。pushを受けたらJenkinsを使った検証処理でファイルを自動生成し直し、コミット漏れがないかどうかをチェックしています。
最終的なファイル生成の流れ
ここまで説明してきた内容を図にまとめます。
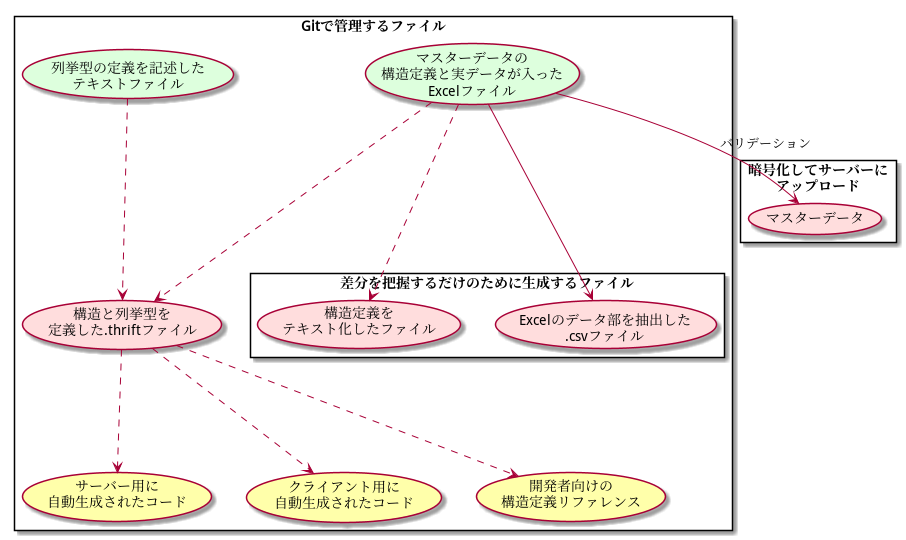
緑は手作業で変更するファイル。赤は内製ツールで、黄はApache thriftでそれぞれ自動生成されます。
また、実線はプランナー、破線はエンジニアが、変更差分に責任を持ちます。
まとめ
ここまでやった結果、マスターデータ周りのフローで感じていたストレスは大幅に減らせた、と思います。それなりの規模の新規案件をやるのであれば、今回のやり方を踏襲するつもり、というくらいには満足できています。
ただし、残念ながらこのフローを回すには、内製ツールの作り込みが必要です。
@sugaretさんの記事の最後にもあったように、各開発現場にはそれぞれ事情があり、どこまで工数をかけられるかというのは悩ましい問題ですが、比較的工数をかけて突き詰めた1つの形として参考にしていただければと思います。