はじめに
あなたは誰?
- 2013年に新卒入社し、DeNAでひたすらゲームを作っているエンジニアです。
- やってきたこと
- トラフィックが比較的エグめのブラウザゲームの運用
- 新規アプリゲームの運用
- 新規アプリゲームの開発
- 興味
- 筋トレ、ブロックチェーン、飯、料理、お笑い

なんの記事?
- モバイルゲーム開発/運用にマスターデータの管理はつきもの。
- これだけ多くのゲームがリリースされているのに、デファクトっぽい手法が確立されていない。
- なんなら、弊社内でもそこそこのダイバーシティが観測できる。
- 今回はマスターデータ管理における要素をまとめ、どのようなソリューションが社内で展開されてきたか、どのような状態が理想的かを考えてみる。
- 対象読者はモバイルゲームの運用をしていた方々や、これから運用される方々。
- 知見を集めて幸せな世界を作りたいです。
マスターデータって何?
- ここではモバイルゲームの運用において、デプロイ時点で運営側が先に用意しているアセット群のうち、文字列で表現されるデータ群のことを指す。
- ex. 例えば、モンスターとそのモンスターが持つ技のマスターデータを以下のように表現できる。
モンスター
| monsterId | name | hitPoint |
|---|---|---|
| 1 | ザコカエル | 100 |
| 2 | リーダーカエル | 200 |
| 3 | ボスカエル | 500 |
技
| wazaId | name | power |
|---|---|---|
| 1 | カエルパンチ | 100 |
| 2 | カエルキック | 200 |
| 3 | カエルジャンプ | 500 |
モンスターと技のマッピング
| monsterId | wazaId |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 2 | 2 |
| 3 | 2 |
| 3 | 3 |
- (対比) ユーザーデータ: ユーザのアクションによって追加される文字列で表現されるデータ群。
- cf. マスターデータ(weblio)
マスターデータが作られてからリリースされるまでのフロー
弊社で観測できるものを抽象化すると、ざっくりこんな感じです。
(*開発の際はそもそも「何をマスターデータとするのか」というお話から始まるんですが、運用にフォーカスするためにここでは省略します。)
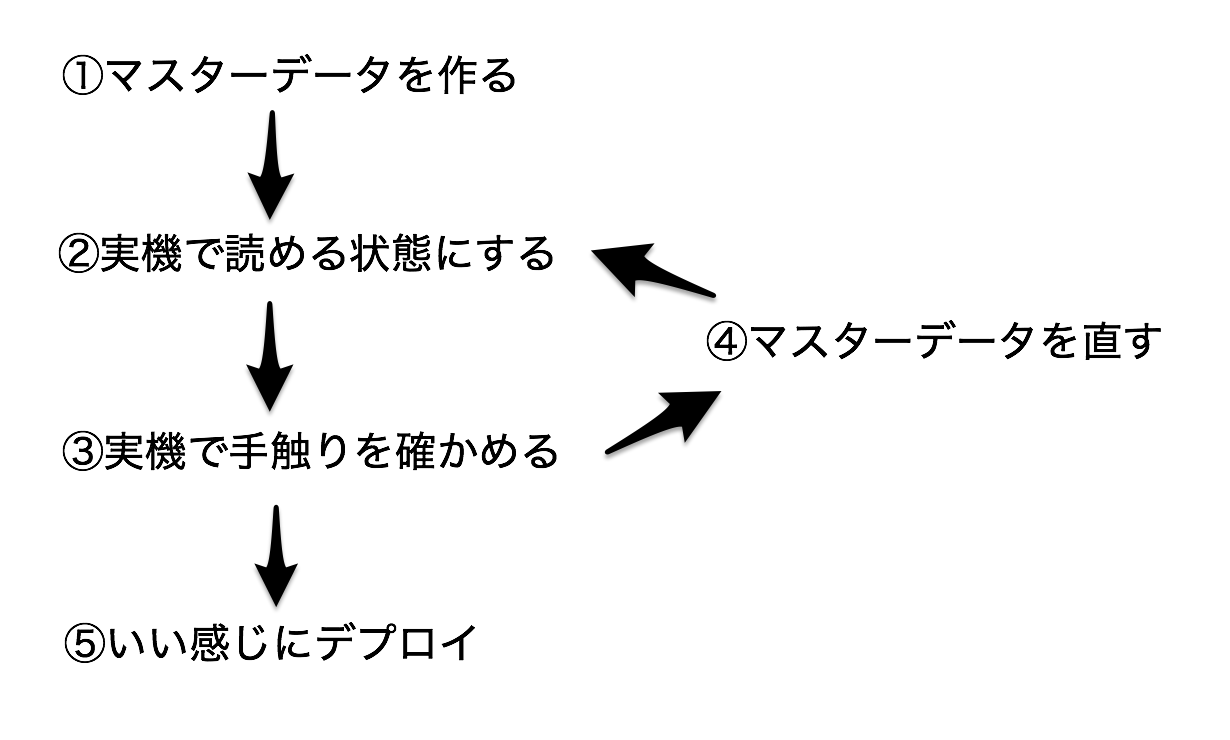 具体的にどのような手順を踏んでいるのかを解説します。
具体的にどのような手順を踏んでいるのかを解説します。
①マスターデータを作る
- アップデート内容をマスターデータとして作成する。
- 作成方法は様々ですが、表の形式で扱うことが多いためにエクセルやGoogleSpreadSheet(以下GSS)が社内ではメジャー。
②実機で読める状態にする
- マスターデータをいい感じに変換したりして、実機から読み込める状態にする。
- csv化してデータベースに突っ込む。
- json化してバイナリに含めてビルドしてみる。
③実機で手触りを確かめる
- アップデートの内容が意図しているものになっているかのチェック。
- データの内容によって多岐にわたるが、例えば「想定レベルのユーザーが勝利できること」のようなチェック。
④マスターデータを直す
- ③でチェックした結果、意図と異なる状態になっている時に、ここで修正する。
- 実際の作業としては①から②の流れとそれほど変わらない。
⑤いい感じにデプロイ
- ②-④のループを気が済むまで繰り返した後に行う、本番反映作業を行う。
それぞれの工程でかかるつらみ
ここでは僕が実際に見てきた工程ごとのつらみの具体例を示します。
(*①と④は基本的に同じ事を行うのでまとめています。)
①マスターデータを作る/④マスターデータを直す
- アップデートを繰り返すごとに、マスター作成難易度が上がっていく。
- 紐づくデータが肥大化することが多く、どの項目がゲーム内の何に対応しているのか分かりづらくなりがち。
- 「もう使ってないんだけどね〜」というカラムもあったりする。参照されないので適当な値が詰められていたり。
- 同時編集が難しい。
- 複数人で1シートをいじるような方式だと、作業中のデータまで反映されてしまいがち。
- 「xxxのマスターいじります!」と声を掛け合いながら作業をすることもあった。
②実機で読める状態にする
- 確認するために用意するべきアセットが分かりづらいことがある。
- 例えばキャラクターの動きを確認するためにはマスターデータだけではなく、3Dモデルのデータも必要である。
- データの取得方式によっては反映作業自体に時間がかかる。
- DBに反映するだけでいいなら一瞬だが..
- Unityで読むためのアセットバンドルをビルドする時間が日に日に長くなりがち。
③実機で手触りを確かめる
- 確認自体に時間がかかる。
- アップデート対象は「最新ステージの追加」のような、DLしたてのユーザが遊べるものではないことが多い。
- 対象がヘビーユーザー向けのものだと、プレイするための条件がたくさんあったりする。
- 想定デッキでバトルを試したいが、その準備も大変だったりする。
- (ネイティブアプリの場合)実機へのDLに時間がかかる。
⑤いい感じにデプロイ
- ホントにリリースしていいの?チェックがつらい。
- gitの差分をcsv/jsonの状態で見ていたりする。
- データ的には正しいけど、リリース時期合ってる?
- このキャラクターがこんなに強くていいの?
- なんか関係なさそうなテーブルの差分でてるけど大丈夫?
- しかしここで意外とミスが見つかるので馬鹿にできなかったりする。
- gitの差分をcsv/jsonの状態で見ていたりする。

実際の運用例
僕が見てきた現場の運用例です、どこを犠牲にしてなんのメリットを取っていたかを説明します。
ブラウザゲームA
| データ作成 | データ反映 | データ閲覧 |
|---|---|---|
| エクセル | 自前のwebアプリ | 自前のwebアプリ |
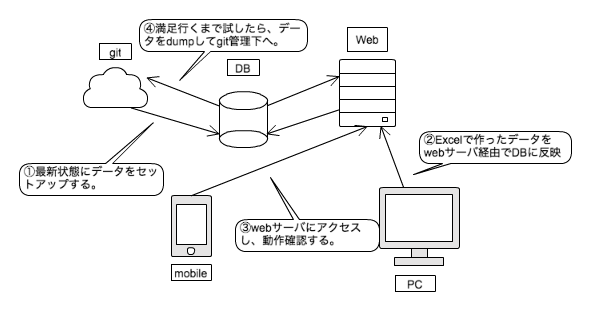
マスタ作成フローの概要
- マスターの種類ごとにエクセルファイルが存在し、ファイルサーバーで管理されている。
- 作業者ごとに確認用のサーバーが割り当てられており、その時点でのリリースバージョンにセットアップされている。
- 作業としてはエクセルファイルを編集した上で保存し、自前のwebアプリを経由して特定環境のDBに反映する。
- ブラウザゲームなので、モバイル端末のブラウザ経由で該当環境にアクセスして動作確認をする。これを繰り返す。
- 満足したら、mysqldumpでcsv化し、git管理下に配備する。
- 最終的にcsvをmysqlに突っ込むことでマスターデータの本番反映を行う。
考察
- データが肥大化して複雑化する問題に対しては、エクセルシートをカスタマイズして「入力が必要な箇所」をできるだけ減らすなどすることで、作業内容をできるだけ単純化することで回避していた。
- それでもナレッジが人に依存してしまうケースは多々あったため、引き継ぎで苦しむことは多くあったように思う。
- 基本的に分業はリリースバージョンごとであり、リリースバージョンごとにシートが分かれているため、作業が重なることは少なかった。
- 新キャラクター追加などに関しては共通シートの更新が必要だったりする構造になっていたりしたので、そこに関しては「どの環境にどこまで反映するのか」ということ手作業で実行する必要があった。
- マスターデータに紐づくアセットなどは、画像が必要なケースなどがよくあったが、適当にコピーしてダミーデータとして使うことが多かった。
- アプリゲームではないので、DBを更新さえしてしまえば動作確認ができるため、直して確認するというサイクルはかなり高速に回すことができていた。
- リリースバージョンごとにブランチで管理されていたため、作業中は他の作業の影響を受けにくい構造になっていた。
- ただしリリースのためには、リリースされているブランチから現在のブランチまでをmergeしておく必要があり、csvがconflictしたときが非常に大変だった。
- その差分を作成した人たちを巻き込んで、正しい状態を確認する必要があった。
アプリゲームB
(*WebViewを多用しているため、ハイブリッドという方が適切かも)
| データ作成 | データ反映 | データ閲覧 |
|---|---|---|
| GSS | GoogleAppScript(以下GAS)を利用した独自ツール | GSS |
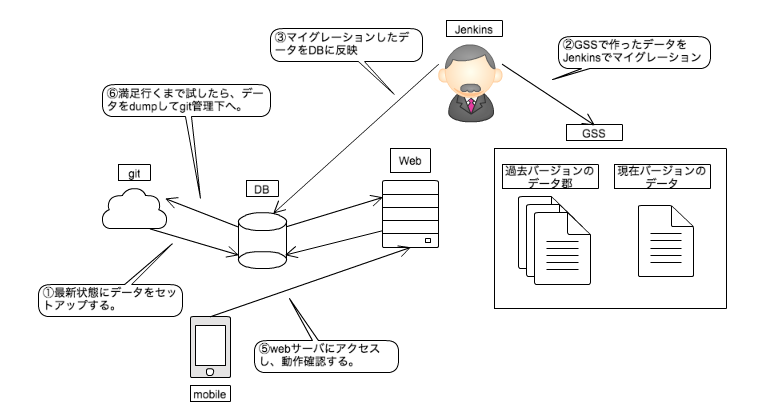
マスタ作成フローの概要
- ディレクトリによってリリースバージョンとその前後関係を表現している。
- それぞれのディレクトリの中にそのバージョンで追加変更するマスターデータのGSSがある。
- GSSに入力するマスターデータの内容は差分で表現されている。そのため特定のバージョンまでのマスターデータのGSSをマイグレーションすることで、統合データが完成する。
- ex. 以下のような感じ。
|--001
| |--GSS1
| |--GSS2
| └--GSS3
└--002
|--GSS1
└--GSS2
- 変更後に独自ツールを実行すると、リリース済みのデータからそのバージョンまでのデータをマイグレーションし、DBに突っ込んだ状態にしてくれる。
- 実機での動作確認をし、問題があれば直して再度ツールを実行する。
- 満足したら、mysqldumpでcsv化し、git管理下に配備する。
- 最終的にcsvをmysqlに突っ込むことでマスターデータの本番反映を行う。
所感
- マスターデータ複雑化問題に対しては、GSSの機能を利用してvalidationをしたり、リレーションチェックを行ったりして入力する際に弾いたり、選択肢を提示することで平易化に努めていた。
- リリースバージョン別での作業は完全に独立しているので、他の人の作業に影響を受けなくなっている。
- ただし、それまでのマスターデータを全部マイグレーションする仕様上、以前のマスターデータにエラーが混じっていた場合、それ以降のバージョンはすべてバグをはらむことになってしまう。
- ちなみにリリースバージョン内での作業は、GSSを使用しているので同時編集はサポートされているが、別の人が同じシート上で作業している場合は作業中のデータまで反映されてしまうため、別個でマイグレーションの対象にならない作業用のディレクトリを切って試していた模様。
- WebViewが主たるゲームのコア部分だったため、反映と確認の作業はブラウザゲームと同じようなノリで行うことが出来ていた模様。
- 自動化が進んでいるため、GSSをいじる以外はJenkins経由でポチるだけでいい感じに反映してくれていた。
- しかし、マスターの量の増加に伴って、マイグレーション作業にかかる時間が増加してしまっていた。
- 便利ツールだったが、ツールのメンテナンス担当者が明確にいるわけでなく、メンテナンス自体の難易度が高くなってしまっていた。
- gitで管理しているものの、GSS側を正として管理していたため、特定バージョンでconflictした場合はマスターデータをDLしてそのデータで上書きしてしまえるという性質を持っていた。
- GSSが簡単に修正してしまえるので事故る可能性は高かった。
アプリゲームC
| データ作成 | データ反映 | データ閲覧 |
|---|---|---|
| GSS | GASを利用した独自ツール2 | GSS |
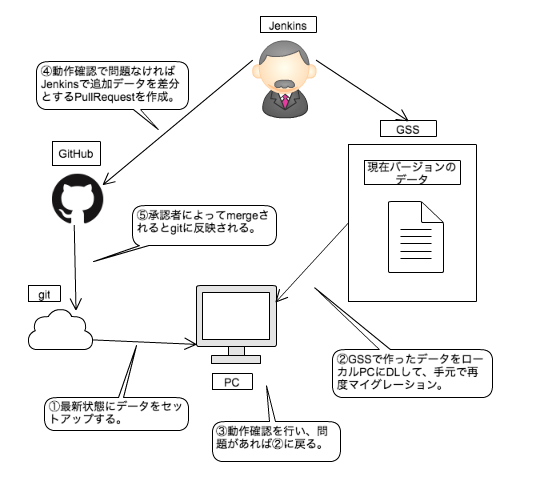
マスタ作成フローの概要
- ディレクトリによってリリースバージョンとその前後関係を表現している。
- バージョンを表現するディレクトリ内に作業者毎のディレクトリが存在している。
- それぞれのディレクトリの中にそのバージョンで追加変更するマスターデータのGSSがある。
- ex. 以下のような感じ。
|--001
| |--jiro
| | └--GSS1
| └--taro
| |--GSS1
| └--GSS2
└--002
└--hanako
|--GSS1
└--GSS2
- マスターを追加変更する場合は対応する名前空間にシートを作成し、マスターデータを書き込む。
- 変更後にマスターデータを作業者のローカルに落としてくることで、変更データを加えたものの動作確認を行う。
- 満足行くまでこれを繰り返す。
- データが完成したら「追加変更したデータを差分として吐き出すようなPullRequestをそのブランチに対して投げる」というJenkinsのjobを走らせる。
- 作業者、または承認者が内容を確認の上、mergeする。
- それぞれのバージョンはリリースされるまで、ブランチ上で別々の差分ファイルとして管理されており、データを読むタイミングでマイグレーションしたデータを作成する。
- リリースすると「リリース後データ」という枠で一緒くたに管理される。
- 実機確認をする際は、特定ブランチのgit管理下にあるものをmBaaSに突っ込んで読み込めるようにする。
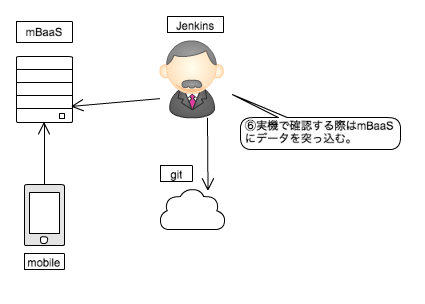
所感
- GSSでの複雑化しない工夫はアプリゲームBと同様に行われていた。
- 同時作業に関しても同様だが、同じバージョンで分業できるところが異なる。
- 差分で表現することのリスクとして「別ファイルで同じ行を変更している場合にどうするのか」というような点があるが、そのあたりは運用でカバーしていた。
- 運用でカバーされているという前提にしても、検知する仕組みぐらいあっても良かったように思う。
- マイグレーションのフローがアプリゲームBから改善されている。
- GSS上でマイグレーションするわけでなく、それぞれのバージョンのgit管理下においてるものをマイグレーションするため、きちんと検証が済んでいるものを取り込むことができる。
- プログラムコードと共に取り込まれるために、マスターデータとプログラムコードが乖離することもない。
- (厳密にはマスターデータの話ではないが)確認に時間がかかることがある。
- マスターデータ自体はmBaaSに上げて確認するというフローだったのでそれほど時間はかからない。
- マスターデータと合わせてその他のリソースも調整する必要があることが多々あった。
- Unityゲームだったため、それらはアセットバンドルとして配信するため、アセットバンドルのビルドをする必要があったが、それに時間がかかる。

これからの展望
ここまで、実際の運用での具体的な対応方針や、いろいろなつらみについて語ってきました。社内外にデファクトとなりそうな解決方法がないという風にお話しましたが、実は社内でこれを解決しようとしているプロジェクトがあります。
現代のアプリ開発で主に必要になりそうな以下の4つの機能を搭載しています。
- editor
- データ作成
- viewer
- データ閲覧
- convertor
- データ変換
- validator
- データ検証
詳細については開発中のため、この程度にとどめておきますが、上手く行けば将来どこかで紹介されるかもしれません。
おわりに
色々書いてきましたが、ヒットするかわからないゲームに対して最初からツールエンジニアをアサインして、今回お話したあたりのフローをバリバリに整備していくというのは難しい判断かもしれません。僕自身、ミニマムなチームでコードとしては微妙な品質なものを量産しつつ、人海戦術で運用をカバーしながら、サービスとしては素晴らしいものを生み出すということを目にしています。
運用の現場を経験された方々からすると、現実的じゃないだろうと思われる点も多数あると思います。このような状態は継続的な努力によってのみ実現できるものであり、一度ツールを整備したら終わりというものではないと思います。継続的な見直しやアップデートには当然ですが工数がかかり続けます。
なので必ずしも理想の状態を維持しながら運用している現場だけが素晴らしく、それ以外は駄目などというつもりはありません。しかし「どんな状態が理想なのか」を語れないと、迷った際に「何を選択して、何を犠牲にするのか」という問題に対して適切な判断を下せないのではないでしょうか。
ということでこんな感じの状態が理想だよね、というお話を積極的にして行きたい所存です。
