主に、機械学習とかよくわからないけど、とにかく coqui-ai/TTS の v0.2.0 (2021/08/11) で追加された VITS 実装で TTS したい方向けのメモです(筆者がそれです)。Google Colab だけで試しています。
VITS の公式実装 jaywalnut310/vits を使ったメモは「VITS を使った音声変換で特定話者のゆっくり化を試す」に書いています。
0. coqui TTS って何
2021/03 に設立された coqui.ai が mozilla/TTS をフォークしてメンテしている OSS です。記事「![]() Coqui.ai is here」には mozilla/TTS メインメンテナーだった erogol さんが mozilla/TTS はもうメンテせず、coqui-ai/TTS に注力していく旨のコメントもあります。python モジュールの
Coqui.ai is here」には mozilla/TTS メインメンテナーだった erogol さんが mozilla/TTS はもうメンテせず、coqui-ai/TTS に注力していく旨のコメントもあります。python モジュールの TTS も coqui-ai/TTS 実装に変わっており、今から mozilla/TTS を使うのであれば coqui-ai/TTS の方が良さそうです。
0.1. coqui.ai 設立前後のできごと
- 2020/08/11
- 2021/03/15
-
mozilla/TTS から coqui-ai/TTS、mozilla/DeepSpeech から coqui-ai/STT がフォーク
- 原文: 「
 Coqui.ai is here」
Coqui.ai is here」
- 原文: 「
-
mozilla/TTS から coqui-ai/TTS、mozilla/DeepSpeech から coqui-ai/STT がフォーク
- 2021/04/12
- Mozilla が DeepSpeech の開発を終了し、助成プログラムを発表
- Mozillaが米NVIDIAと提携、音声データセット構築プロジェクト「Common Voice」を前進 | OSDN Magazine
といった時系列を見る感じ、Mozilla がメンテできなくなったソースをメンテしてる OSS、という印象です。
1. データの準備
「Mozilla TTS (Tacotron2) を使って日本語音声合成」のデータ準備と同様に準備しておきます。以前に作ったものを流用しているため、音声認識結果を mecab-ipadic-neologd でカナ化 → uconv でローマ字化しただけのデータを利用しています。
2. データを使った学習
Mozilla/TTS との主な違いとして、coqui-ai/TTS では config management に coqui-ai/coqpit という、facebookresearch/hydra の coqui.ai 版みたいのを利用しているので、学習時の設定変更などが簡単にできるようです(training スクリプトの引数に指定するとそれを読み込むなど)。
# !git clone https://github.com/coqui-ai/TTS
!git clone https://github.com/coqui-ai/TTS -b v0.2.0
!cd TTS/; pip install -e .[all]
最新もしくはバージョンを指定したインストールの後に、train スクリプトを実行します。
以下のようなデータがある場合
- /content/hoge/
- wavs/
- 0001.wav
- 0002.wav
- ...
- metadata.csv
- wavs/
!mkdir -p /content/drive/MyDrive/coqui-vits/
# 初回
!python TTS/recipes/ljspeech/vits_tts/train_vits.py \
--coqpit.output_path /content/drive/MyDrive/coqui-vits/ \
--coqpit.datasets.0.path /content/hoge/ \
--coqpit.datasets.0.meta_file_train metadata.csv \
--coqpit.use_phonemes false \
--coqpit.text_cleaner basic_cleaners
# 継続用
!python TTS/recipes/ljspeech/vits_tts/train_vits.py \
--continue_path /content/drive/MyDrive/coqui-vits/vits_ljspeech-* \
--coqpit.output_path /content/drive/MyDrive/coqui-vits/ \
--coqpit.datasets.0.path /content/hoge/ \
--coqpit.datasets.0.meta_file_train metadata.csv \
--coqpit.use_phonemes false \
--coqpit.text_cleaner basic_cleaners
上記のように train_vits.py をほぼそのまま使うだけですが、自分のデータで学習するために coqpit 引数でいくつか設定を上書きしています。meta_file_val を指定していないですが、内部的に meta_file_train をうまい具合に分割するようです。
上記はテキストにローマ字を利用しているケースですが、coqui-ai/TTS 内で音素変換を行う場合、use_phonemes text_cleaner は別の指定になると思います。(変換を行う際は「VITS を使った音声変換で特定話者のゆっくり化を試す」の音素変換処理部も参照ください)
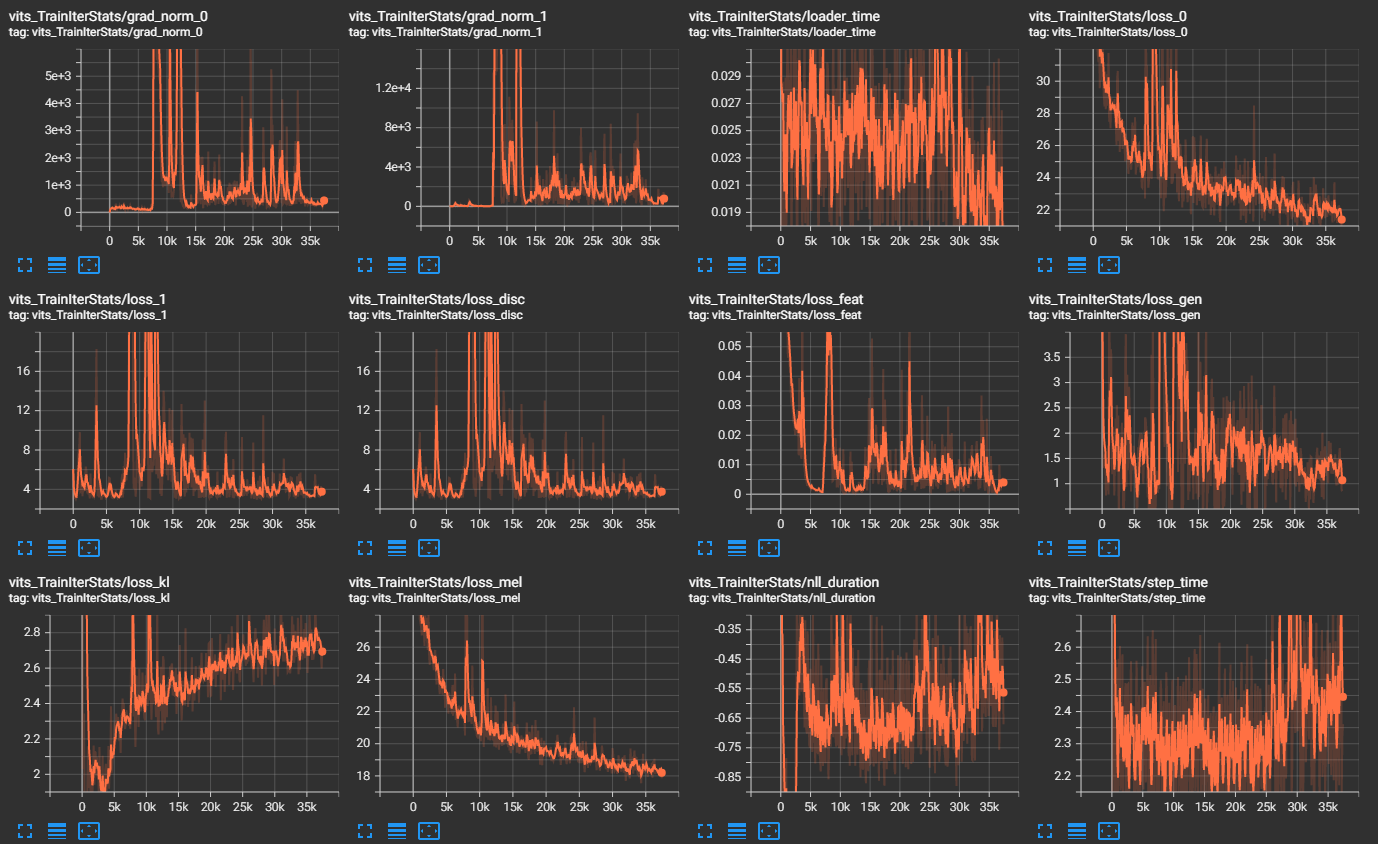
なお v0.2.0 で試していると、学習途中 10k steps 弱で RuntimeError: min(): Expected reduction dim to be specified for input.numel() == 0. Specify the reduction dim with the 'dim' argument. が出る症状に悩まされました。テキストが短いデータをデータ上含めないようにして(自動で省かれるはずですが、怪しいため)試したら少し学習が進むようになりました。それでも学習を進めていくと RuntimeError: > Detected NaN loss - {'loss_gen': tensor(nan, device='cuda:0', grad_fn=<MulBackward0>), ...}. が出るようになったのでデータによってはチューニングなりが必要そうです。
!mkdir -p /content/drive/MyDrive/coqui-tacotron2-DDC/
!python TTS/TTS/bin/compute_statistics.py \
TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \
/content/hoge/scale_stats.npy \
--data_path /content/hoge/wavs/
!python TTS/TTS/bin/train_tts.py
--config_path /content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \
--coqpit.output_path /content/drive/MyDrive/coqui-tacotron2-DDC/ \
--coqpit.datasets.0.path /content/hoge/ \
--coqpit.audio.stats_path /content/hoge/scale_stats.npy
今回とあまり関係ないですが、同様の構成を Tacotron2 DDC モデルで学習する場合は tacotron2-DDC/run.sh を参考に上記のような感じになりそうです。
3. 音声合成
!python TTS/TTS/bin/synthesize.py \
--text "souiukotomo arundanatte omoimashita." \
--model_path /content/drive/MyDrive/coqui-vits/vits_ljspeech-*/best_model.pth.tar \
--config_path /content/drive/MyDrive/coqui-vits/vits_ljspeech-*/config.json \
--out_path output.wav
音声合成は、他のモデル同様 synthesize.py を呼ぶだけで、後は E2E モデルかどうか自動判別してくれるので簡単でした。ただ音声を聴いてみた感じ、同じデータを公式実装 jaywalnut310/vits で学習させた音声が 90 点だとすると、30 点ぐらいの品質でした(割と学習が短め、30k steps ぐらいで確認したという点を差し引いたとしても)。原因がパラメータにあるのか実装にあるのかはよくわかっていません。
4. まとめ
coqui-ai/TTS v0.2.0 の時点では、VITS モデルの学習を行い合成音声なりを作る際は、若干チューニングが必要そうでした。何も考えず学習するのであれば公式実装 jaywalnut310/vits を利用した方が品質的に楽そうです。
ただ coqui-ai/TTS は継続的にリリースがあるので、今後 jaywalnut310/vits 同等になる可能性もありそうです。将来的には ONNX でのエクスポートなど他にはない機能もロードマップにあるので、今後も試していきたいです。