上記 VITS の公式実装、jaywalnut310/vits の音声変換でゆっくり化を試したメモです。
なお、筆者は VITS が何なのか全くわかっていないため、その辺の内容は別途ご参照ください。
(参考)
VITS(https://t.co/nPfudndtwZ)についてOV2Lの論文読み会で発表した.なかなか面白いTTSモデルで,資料作りも楽しかった.
— ☕ (@kaffelun) July 17, 2021
スライドURL: https://t.co/5pLbLLe1WP
1. データの準備
1.1. 特定話者のデータを作成
「Mozilla TTS (Tacotron2) を使って日本語音声合成」のデータ準備と同様に準備しておきます。以前に作ったものを流用しているため、音声認識結果を mecab-ipadic-neologd でカナ化 → uconv でローマ字化しただけのデータを利用しました。
1.1.1. g2p 音素変換処理
今回は上記のように学習をローマ字で行ったため、音素変換処理は行っていませんが、補足です。
音素変換処理する場合
テキストを音素変換して学習する場合、jaywalnut310/vits 内では bootphon/phonemizer を使った language='en-us' 決め打ち実装のため、データ作成段階で自力で変換するか、jaywalnut310/vits の修正が必要です。いくつか方法がありそうですが、だいたい
-
r9y9/pyopenjtalk などを使って Open-JTalk 音素表記にする
- 例)「ヴァーミリオン」→「b a a m i r i o N」
- 「2021年6月に発表された最新の音声合成手法「VITS」でアニメ風合成音声を作ってみた【つくよみちゃんコーパス】」のように、jaywalnut310/vits 側も symbols cleaners を修正した方が良さそうです。
-
Julius の segmentation-kit などを使って IPA(情報処理振興事業協会) 音響モデル準拠の音素表記にする
- 例)「う゛ぁーみりおん」→「b a: m i r i o N」
- ほぼ Open-JTalk そうなため、同様に jaywalnut310/vits 側の symbols cleaners を修正した方が良さそうです。
-
espeak-ng/espeak-ng (やそれをバックエンドに使った bootphon/phonemizer) などを使って IPA(国際音声記号) 表記にする
- 例)「ヴァーミリオン」→「väämiɽio̞ɴ」 (パッチ後)
- jaywalnut310/vits の内部的にも英語を IPA(国際音声記号) に変換しているので、事前に変換しておけば symbols の修正は不要…と思います。
- 現 espeak-ng/espeak-ng はカナによって足りない処理がある (ヴァー、等) のでデータによっては要パッチです。
- ガリガリ書く
- mozilla/TTS のほぼ後継 coqui-ai/TTS では bootphon/phonemizer ではなく変換処理を独自実装に置き換えて、 IPA(情報処理振興事業協会) 音響モデル準拠の音素表記に変換しているようです。
などになるかと思います。そもそも、音素表記と音声表記は別物そうなので、IPA(国際音声記号) の出力は Phoneme ではなさそうですが、jaywalnut310/vits が利用しているところを見るに英語だと近しくなるのかなと想像しています。わかりません。
1.2. ゆっくり音声データを作成
ゆっくり音声は、
「高い、使いにくい、読みにくい──音声合成研究者を悩ませるハードルを解決する“台本”、明治大学らが発表 - ITmedia NEWS」で記事にもなっていた、mmorise/ita-corpus の台本を利用して生成しました。
SofTalk を落として、コマンドラインに台本を食わせると、100 (Emotion) + 324 (Recitation)、合計 424 ファイルのデータができます(「女性02」で作った wav ファイルはこちら)。生成された wav ファイルは 8000 Hz ですが、jaywalnut310/vits のサンプル設定 では 22050 Hz 想定だったので、ffmpeg などで修正(ffmpeg -i input.wav -af loudnorm -ar 22050 -ac 1 output.wav)しました。
特定話者のデータ同様に、台本のカナを uconv でローマ字化(uconv -f UTF-8 -t UTF-8 -x Latin)して、メタデータとします。
「ゆっくりを商用利用する場合のライセンス」を読むと、新しい SofTalk は商用利用に別途ライセンスが必要そうですが、商用利用する予定もないのでそのまま最新版を利用しています。
ちなみに YouTube では 2021/06 からチャンネルが収益化してるしてないに関わらず広告表示する旨の変更が入り、2021/08 あたりから実際に非収益化チャンネルでも広告が出ているようです。後述の、出力表示に使っている埋め込み YouTube で広告が表示されるかもですが、収益化しているわけではありません。
1.3. メタデータの整形
jaywalnut310/vits にある入力ファイルを見て、複数話者用の入力メタデータを作成しておきます。
0001|ichi no bunsyou.|ichi no bunsyou.
0002|ni no bunsyou.|ni no bunsyou.
↑上記のような、LJSpeech の metadata.csv に準じたフォーマットは
/path/to/wavs/1/0001.wav|1|ichi no bunsyou.
/path/to/wavs/1/0002.wav|1|ni no bunsyou.
/path/to/wavs/2/0001.wav|2|san no bunsyou.
/path/to/wavs/2/0002.wav|2|yon no bunsyou.
↑上記のように、
- 1 列目の ID は wav ファイルのパスに変換する(.wav もつける)
- 2 列目にはスピーカー ID (sid) が必要なので、話者ごとに数字をふる
- 生テキストは不要、3 列目のノーマライズテキストだけ利用する
と修正しました。
2. jaywalnut310/vits を利用した学習
コマンドは、Google Colab 上での実行を想定しています。 ! 付きです。
2.1. 依存ライブラリのインストール
!git clone https://github.com/jaywalnut310/vits
!apt-get install espeak-ng
!cd vits/; pip install -r requirements.txt
!cd vits/monotonic_align/; python setup.py build_ext --inplace
jaywalnut310/vits の README に従って、ライブラリをインストールします。
2.2. preprocess
VCTK コーパス を利用した場合の入力サンプルを参考に、メタデータを 100 行ぐらいの metadata_val.csv と残りの metadata_train.csv に分割しました。その後
!cd vits/; python preprocess.py --text_index 2 --filelists /content/metadata_train.csv /content/metadata_val.csv --text_cleaners basic_cleaners
と preprocess.py を実行すると、metadata_train.csv.cleaned と metadata_val.csv.cleaned ができます。
README の例そのままを実行すると、音素変換を行う --text_cleaners english_cleaners2 が実行されてローマ字を英語読みしてしまうため、何もしない --text_cleaners basic_cleaners を指定しています。というか何もしてないので大文字小文字混合などがなければ *.cleaned は全く同じファイルになります。別にやらなくて良さそうですが処理の流れを掴むためだけに実施しました。
2.3. 設定の修正
複数話者用の設定の、vctk_base.json を修正して、hoge.json を作りました。
"batch_size": 64,
~~~
"training_files":"filelists/vctk_audio_sid_text_train_filelist.txt.cleaned",
"validation_files":"filelists/vctk_audio_sid_text_val_filelist.txt.cleaned",
"text_cleaners":["english_cleaners2"],
↓コピーして修正
"batch_size": 32,
~~~
"training_files":"/content/metadata_train.csv.cleaned",
"validation_files":"/content/metadata_val.csv.cleaned",
"text_cleaners":["basic_cleaners"],
入力ファイルを指定している training_files validation_files を、作成したメタデータファイルにします。また、余計な変換をしないよう text_cleaners を basic_cleaners を変えています("cleaned_text": true なので学習時には利用されないと思いますが、後述する TTS 音声合成時に音素変換がかかってしまい変な音声になります)。"batch_size": 64, は、Google Colab でメモリ確保できずに落ちて 32 に減らしただけなので、環境に依っては 64 のままで問題なさそうです。
2.4. symbols.py の修正
!cp -n vits/text/symbols.py{,.org}
!cp vits/text/symbols.py{.org,}
!perl -i -pe 's{;:,\.}{-;:,.}' vits/text/symbols.py
!diff -u vits/text/symbols.py{.org,}
symbols.py には _punctuation = ';:,.!?¡¿—…"«»“” ' とあり、一見ハイフン - は問題ないようなのですが、これは U+2014 の EM DASH なので ASCII のハイフンではありませんでした… ので U+002D の HYPHEN-MINUS を追加しています。
注意点として、この symbols.py の数でモデル定義が変わってくるため、inference のモデルロード前にも学習時と同様の修正が必要になります。なので、学習途中での symbols.py の修正は厳しそうです。
2.5. 学習
!mkdir -p /content/drive/MyDrive/vits_logs/
!ln -nvs /content/drive/MyDrive/vits_logs vits/logs
!cd vits/; python train_ms.py -c configs/hoge.json -m hoge
カレントの logs にチェックポイントを保存するので、Google Drive 上に保存するようにして学習します。
Google Colab で実行すると一定時間でセッションが切れるのですが、再実行時に logs 以下の最新のチェックポイントから継続してくれるので便利でした。
2.5.1. loss
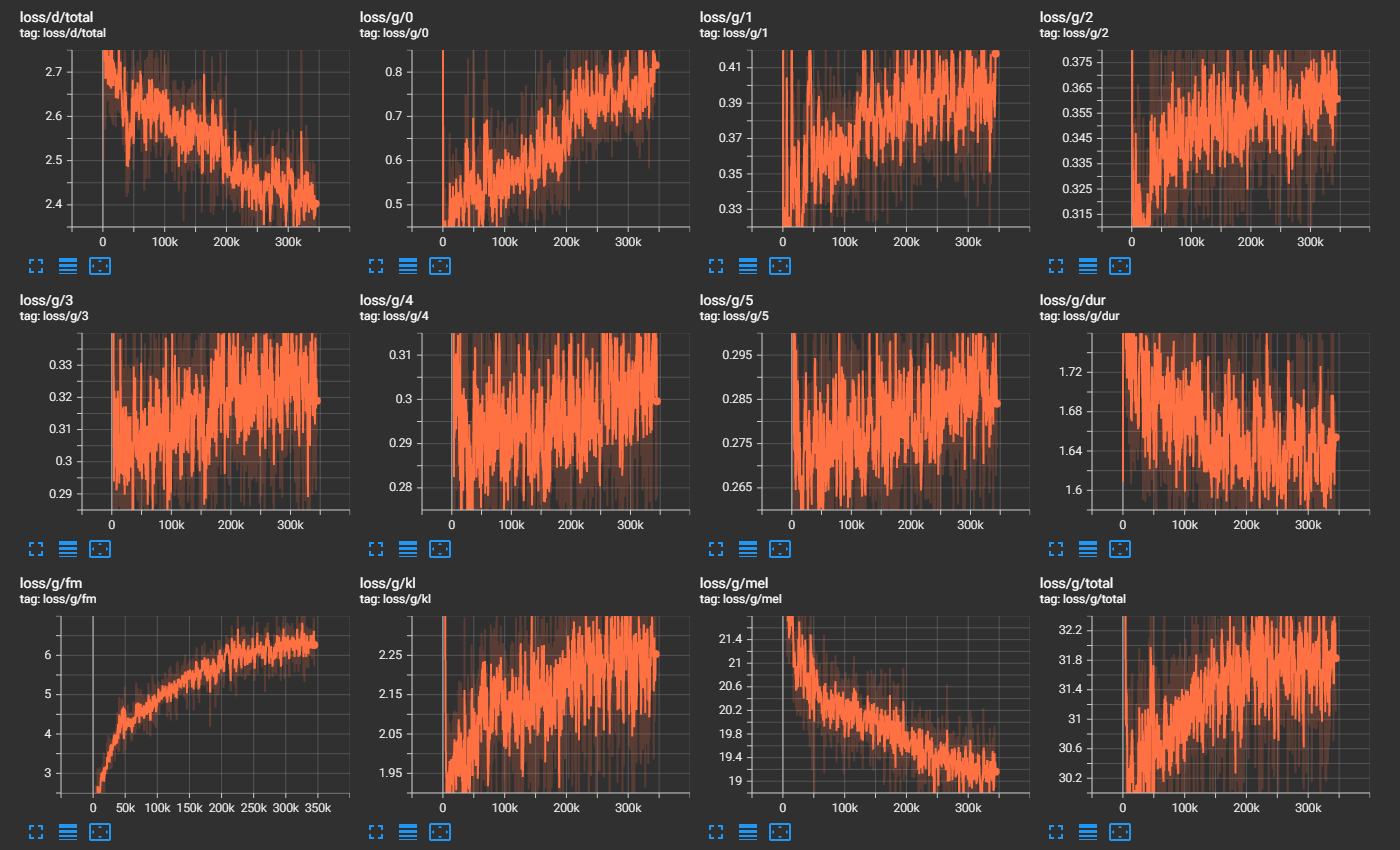
筆者はloss が小さけりゃ良いと思っていたので、どのあたりのモデルが良い塩梅なのか全然わかっていないのですが、とりあえず 300k steps ほど回してみて(Colab Pro で 1 週間弱)、loss/g/mel が最小になったモデルを使いました。
3. inference.ipynb を参考に inference
jaywalnut310/vits にある inference.ipynb を利用して音声合成・音声変換しました。
3.1. 前準備
2.4. で行った symbols.py の修正を先に行った上で、inference.ipynb 同様下記を定義します。
%cd /content/vits/
%matplotlib inline
import matplotlib.pyplot as plt
import IPython.display as ipd
import os
import json
import math
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
import commons
import utils
from data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate
from models import SynthesizerTrn
from text.symbols import symbols
from text import text_to_sequence
from scipy.io.wavfile import write
def get_text(text, hps):
text_norm = text_to_sequence(text, hps.data.text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
inference.ipynb そのままです。import 等を行っています。
hps = utils.get_hparams_from_file("./configs/hoge.json")
学習に使った hoge.json をそのまま利用します。
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model).cuda()
_ = net_g.eval()
_ = utils.load_checkpoint("./logs/hoge/G_60000.pth", net_g, None)
logs 下の、学習時に指定したディレクトリにチェックポイントがあるので、良い塩梅の generator (G_*.pth) をロードします。
3.2. TTS 音声合成
目的ではないのですが、テキストから音声合成もできました。
stn_tst = get_text("tasukete kudasai hennna hitoga araware mashita.", hps)
with torch.no_grad():
x_tst = stn_tst.cuda().unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()
sid = torch.LongTensor([2]).cuda()
audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()
ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate, normalize=False))
TTS の入力テキストは学習時と同じにする必要があるので、学習時同様のローマ字入力です。cleaners をまず何もしない basic_cleaners 以外にしている場合は、この入力に対して cleaners 処理がかかるはずです。
上記の例だと torch.LongTensor([2]).cuda() なので sid が 2 の話者の TTS になります。[2] を [1] にすれば sid が 1 の話者の TTS になりました。
3.3. VC 音声変換
dataset = TextAudioSpeakerLoader('/content/converttarget.csv', hps.data)
collate_fn = TextAudioSpeakerCollate()
loader = DataLoader(dataset, num_workers=8, shuffle=False,
batch_size=1, pin_memory=True,
drop_last=True, collate_fn=collate_fn)
data_list = list(loader)
VC 用の入力に使う音声ファイルは、学習同様 3 カラムフォーマット (wav パス、sid、テキストのパイプ区切り) のファイルから読み込むようです。inference.ipynb で指定しているように hps.data.validation_files から入力音声を読み込んでも良いですが、学習に使っていない、SofTalk で新録した音声での変換を試したかったので、上記では直接指定しています。
with torch.no_grad():
x, x_lengths, spec, spec_lengths, y, y_lengths, sid_src = [x.cuda() for x in data_list[0]]
sid_tgt1 = torch.LongTensor([1]).cuda()
sid_tgt2 = torch.LongTensor([2]).cuda()
audio1 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt1)[0][0,0].data.cpu().float().numpy()
audio2 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt2)[0][0,0].data.cpu().float().numpy()
print("Original SID: %d" % sid_src.item())
ipd.display(ipd.Audio(y[0].cpu().numpy(), rate=hps.data.sampling_rate))
print("Converted SID: %d" % sid_tgt1.item())
ipd.display(ipd.Audio(audio1, rate=hps.data.sampling_rate))
print("Converted SID: %d" % sid_tgt2.item())
ipd.display(ipd.Audio(audio2, rate=hps.data.sampling_rate))
オリジナルの inference.ipynb では、指定したファイルの 1 行目のデータ (data_list[0]) を入力として、sid が 1, 2, 4 torch.LongTensor([1]).cuda(), torch.LongTensor([2]).cuda(), torch.LongTensor([4]).cuda() の話者に変換していましたが、今回 sid が 1, 2 だけだったので削っています。また、ipd.Audio に対する normalize=False の指定がエラーになったので削りました。
3.4. inference 結果
4. まとめ
ゆっくり音声 (SofTalk) は動画での利用も多く、その合成っぽさを含めた聞き馴染みのあるイントネーションが、音声変換である程度再現できたので良かったです。