概要
ディープラーニングを勉強していて、知識の定着も含めてアウトプットを作ってみたので記事にしました。
コード全文はGitHubに挙げています。
今回は容易にモデル構築できるディープラーニングフレームワークのKerasを用いてCNNモデルで有名なVGG16を実装してCIFAR10の画像識別をしました。
実装環境
実行環境
Google Colaboratory
バージョン
- Python 3.6.9
- TensorFlow 1.15.0
- Keras 2.2.5
ライブラリインポート
import numpy as np
import sys
%matplotlib inline
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
まず、必要なライブラリをインポートします。Keras(公式ドキュメント)はTensorFlowなどをバックエンドとする高水準のディープラーニングフレームワークで、複雑なモデルを容易に設計、拡張することができます。
また、CIFAR10はトロント大学で提供されているカラー画像のデータセットで、飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船、トラックの10種類の画像が32×32ピクセルで格納されています。CIFAR10は手書き数字データのMNISTと同様にkeras.dataパッケージにデフォルトで用意されています。
データセットの準備
'''データセットの読み込み'''
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
'''バッチサイズ、クラス数、エポック数の設定'''
batch_size=64
num_classes=10
epochs=20
'''one-hotベクトル化'''
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
'''shape表示'''
print("x_train : ", x_train.shape)
print("y_train : ", y_train.shape)
print("x_test : ", x_test.shape)
print("y_test : ", y_test.shape)
次に訓練データとテストデータをload_data()で読み込みます。
バッチサイズとエポック数は上記のように定義しました。
また、softmaxで扱えるようにするためラベルデータはone-hotベクトル化(1つの成分のみが1で他が全て0のベクトル)します。これらのシェイプは次のようになります。
x_train : (50000, 32, 32, 3)
y_train : (50000, 10)
x_test : (10000, 32, 32, 3)
y_test : (10000, 10)
訓練データ数が50000、テストデータ数が10000です。
VGG16モデルの実装
それではいよいよVGG16モデルを作っていきます。
VGGシリーズに関してはこちらの記事で詳しく説明されています。
ざっくりまとめると、VGG16はVGGチームが作ったCNNモデルで、物体検出や画像分類を競う大会ILSVRC(IMAGENET Large Scale Visulal Recognition Challenge)で上位になったモデルといった感じでしょうか。
比較的シンプルな設計ながら高いパフォーマンスを得られることから、ディープラーニングの紹介で頻繁に名前が出てきます。なお、16の由来は全部で16層からなるからのようです。
VGG16の構造は下図のようになります。(原論文より引用。VGG16はモデルD。)

フィルタサイズ3×3の畳み込み層が13層、全結合層が3層になっています。
上図を参考に、VGG16を実装してみました。
'''VGG16'''
input_shape=x_train.shape[1:]
model = Sequential()
model.add(Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), padding='same', input_shape=input_shape, name='block1_conv1'))
model.add(BatchNormalization(name='bn1'))
model.add(Activation('relu'))
model.add(Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), padding='same', name='block1_conv2'))
model.add(BatchNormalization(name='bn2'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same', name='block1_pool'))
model.add(Conv2D(filters=128, kernel_size=(3,3), strides=(1,1), padding='same', name='block2_conv1'))
model.add(BatchNormalization(name='bn3'))
model.add(Activation('relu'))
model.add(Conv2D(filters=128, kernel_size=(3,3), strides=(1,1), padding='same', name='block2_conv2'))
model.add(BatchNormalization(name='bn4'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same', name='block2_pool'))
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='same', name='block3_conv1'))
model.add(BatchNormalization(name='bn5'))
model.add(Activation('relu'))
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='same', name='block3_conv2'))
model.add(BatchNormalization(name='bn6'))
model.add(Activation('relu'))
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='same', name='block3_conv3'))
model.add(BatchNormalization(name='bn7'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same', name='block3_pool'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), padding='same', name='block4_conv1'))
model.add(BatchNormalization(name='bn8'))
model.add(Activation('relu'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), padding='same', name='block4_conv2'))
model.add(BatchNormalization(name='bn9'))
model.add(Activation('relu'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), padding='same', name='block4_conv3'))
model.add(BatchNormalization(name='bn10'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same', name='block4_pool'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), padding='same', name='block5_conv1'))
model.add(BatchNormalization(name='bn11'))
model.add(Activation('relu'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), padding='same', name='block5_conv2'))
model.add(BatchNormalization(name='bn12'))
model.add(Activation('relu'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), padding='same', name='block5_conv3'))
model.add(BatchNormalization(name='bn13'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same', name='block5_pool'))
model.add(Flatten(name='flatten'))
model.add(Dense(units=4096, activation='relu', name='fc1'))
model.add(Dense(units=4096, activation='relu', name='fc2'))
model.add(Dense(units=num_classes, activation='softmax', name='predictions'))
model.summary()
Kerasのモデル構築方法にはSequentialモデルとFunctional APIモデルの2種類がありますが、今回はよりシンプルなSequentialモデルを使いました。上記のようにmodelにaddしていくことで直列にモデルを組んでいます。
注意事項として、VGGモデルは本来ILSVRCを対象としているため、入力サイズと出力サイズが今回のデータと一致しません。したがって、入出力サイズを次のように変更しています。今回はずっとシンプルなCIFAR10を使っているため、実際にはこんな複雑なモデルを使う必要はないかもしれません。
| 変更前 | 変更後 | |
|---|---|---|
| 入力サイズ | 224×224 | 32×32 |
| 出力サイズ | 1000 | 10 |
また、現在では訓練データの過学習を防ぐ手法としてBatchNormalizationが使われていますが、VGGが発表された当時はこの手法が確立されていなかったため、使用されていません。今回はそちらも取り入れました。
モデルの出力結果は下記のようになります。
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
bn1 (BatchNormalization) (None, 32, 32, 64) 256
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 64) 0
_________________________________________________________________
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
bn2 (BatchNormalization) (None, 32, 32, 64) 256
_________________________________________________________________
activation_2 (Activation) (None, 32, 32, 64) 0
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
bn3 (BatchNormalization) (None, 16, 16, 128) 512
_________________________________________________________________
activation_3 (Activation) (None, 16, 16, 128) 0
_________________________________________________________________
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
bn4 (BatchNormalization) (None, 16, 16, 128) 512
_________________________________________________________________
activation_4 (Activation) (None, 16, 16, 128) 0
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
bn5 (BatchNormalization) (None, 8, 8, 256) 1024
_________________________________________________________________
activation_5 (Activation) (None, 8, 8, 256) 0
_________________________________________________________________
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
bn6 (BatchNormalization) (None, 8, 8, 256) 1024
_________________________________________________________________
activation_6 (Activation) (None, 8, 8, 256) 0
_________________________________________________________________
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
bn7 (BatchNormalization) (None, 8, 8, 256) 1024
_________________________________________________________________
activation_7 (Activation) (None, 8, 8, 256) 0
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
bn8 (BatchNormalization) (None, 4, 4, 512) 2048
_________________________________________________________________
activation_8 (Activation) (None, 4, 4, 512) 0
_________________________________________________________________
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
bn9 (BatchNormalization) (None, 4, 4, 512) 2048
_________________________________________________________________
activation_9 (Activation) (None, 4, 4, 512) 0
_________________________________________________________________
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
bn10 (BatchNormalization) (None, 4, 4, 512) 2048
_________________________________________________________________
activation_10 (Activation) (None, 4, 4, 512) 0
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
bn11 (BatchNormalization) (None, 2, 2, 512) 2048
_________________________________________________________________
activation_11 (Activation) (None, 2, 2, 512) 0
_________________________________________________________________
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
bn12 (BatchNormalization) (None, 2, 2, 512) 2048
_________________________________________________________________
activation_12 (Activation) (None, 2, 2, 512) 0
_________________________________________________________________
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
bn13 (BatchNormalization) (None, 2, 2, 512) 2048
_________________________________________________________________
activation_13 (Activation) (None, 2, 2, 512) 0
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 512) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 2101248
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 10) 40970
=================================================================
Total params: 33,655,114
Trainable params: 33,646,666
Non-trainable params: 8,448
_________________________________________________________________
モデルの学習
作成したモデルを学習していきます。
'''optimizer定義'''
optimizer=keras.optimizers.adam()
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
'''データ正規化'''
x_train=x_train.astype('float32')
x_train/=255
x_test=x_test.astype('float32')
x_test/=255
'''fit'''
history=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test))
最適化手法はよく使われているAdamを用いました。今回ハイパーパラメータのチューニングは行わないのでパラメータはデフォルト値としました。
loss関数は(1)式で表される多クラス分類問題で用いられるカテゴリカル・クロスエントロピーです。
$$
\begin{equation}
L = -\sum_{i=1}^{N} y_i \log{\hat{y_i}} \qquad (N : クラス数 \quad y_i : 正解ラベル \quad \hat{y_i} : 予測ラベル) \tag{1}
\end{equation}
$$
最適化する計量は正解率です。(metricsで指定)
これらをmodel.compileすることで設定します。
最後に画像データを正規化し、model.fitして学習できます。
historyに学習のログを記録します。
以上の設定で学習結果は下記のようになりました。
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 38s 755us/step - loss: 2.0505 - acc: 0.1912 - val_loss: 2.1730 - val_acc: 0.2345
Epoch 2/20
50000/50000 [==============================] - 33s 667us/step - loss: 1.5810 - acc: 0.3763 - val_loss: 1.8167 - val_acc: 0.3522
Epoch 3/20
50000/50000 [==============================] - 33s 663us/step - loss: 1.2352 - acc: 0.5354 - val_loss: 1.4491 - val_acc: 0.5108
Epoch 4/20
50000/50000 [==============================] - 34s 674us/step - loss: 0.9415 - acc: 0.6714 - val_loss: 1.1408 - val_acc: 0.6202
Epoch 5/20
50000/50000 [==============================] - 34s 670us/step - loss: 0.7780 - acc: 0.7347 - val_loss: 0.8930 - val_acc: 0.6974
Epoch 6/20
50000/50000 [==============================] - 34s 675us/step - loss: 0.6525 - acc: 0.7803 - val_loss: 0.9603 - val_acc: 0.6942
Epoch 7/20
50000/50000 [==============================] - 34s 673us/step - loss: 0.5637 - acc: 0.8129 - val_loss: 0.9188 - val_acc: 0.7184
Epoch 8/20
50000/50000 [==============================] - 34s 679us/step - loss: 0.4869 - acc: 0.8405 - val_loss: 1.0963 - val_acc: 0.7069
Epoch 9/20
50000/50000 [==============================] - 34s 677us/step - loss: 0.4268 - acc: 0.8594 - val_loss: 0.6283 - val_acc: 0.8064
Epoch 10/20
50000/50000 [==============================] - 33s 668us/step - loss: 0.3710 - acc: 0.8785 - val_loss: 0.6944 - val_acc: 0.7826
Epoch 11/20
50000/50000 [==============================] - 34s 670us/step - loss: 0.3498 - acc: 0.8871 - val_loss: 0.6534 - val_acc: 0.8024
Epoch 12/20
50000/50000 [==============================] - 33s 663us/step - loss: 0.2751 - acc: 0.9113 - val_loss: 0.6253 - val_acc: 0.8163
Epoch 13/20
50000/50000 [==============================] - 34s 670us/step - loss: 0.2388 - acc: 0.9225 - val_loss: 1.1404 - val_acc: 0.7384
Epoch 14/20
50000/50000 [==============================] - 33s 667us/step - loss: 0.2127 - acc: 0.9323 - val_loss: 0.9577 - val_acc: 0.7503
Epoch 15/20
50000/50000 [==============================] - 33s 667us/step - loss: 0.1790 - acc: 0.9421 - val_loss: 0.7820 - val_acc: 0.7915
Epoch 16/20
50000/50000 [==============================] - 33s 666us/step - loss: 0.1559 - acc: 0.9509 - val_loss: 0.7138 - val_acc: 0.8223
Epoch 17/20
50000/50000 [==============================] - 34s 671us/step - loss: 0.1361 - acc: 0.9570 - val_loss: 0.8909 - val_acc: 0.7814
Epoch 18/20
50000/50000 [==============================] - 33s 669us/step - loss: 0.1272 - acc: 0.9606 - val_loss: 0.7006 - val_acc: 0.8246
Epoch 19/20
50000/50000 [==============================] - 33s 666us/step - loss: 0.1130 - acc: 0.9647 - val_loss: 0.7523 - val_acc: 0.8177
Epoch 20/20
50000/50000 [==============================] - 34s 671us/step - loss: 0.0986 - acc: 0.9689 - val_loss: 0.7233 - val_acc: 0.8350
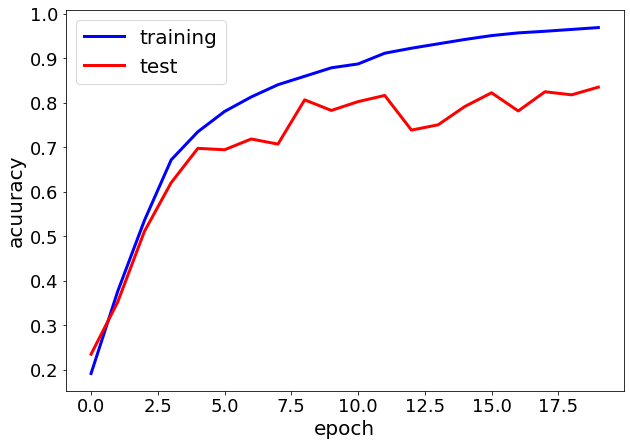
20エポック完了後の正解率は訓練データが約97%、テストデータが約84%となりました。
エポックごとのlossと正解率をplotしてみます。
'''結果の可視化'''
plt.figure(figsize=(10,7))
plt.plot(history.history['acc'], color='b', linewidth=3)
plt.plot(history.history['val_acc'], color='r', linewidth=3)
plt.tick_params(labelsize=18)
plt.ylabel('acuuracy', fontsize=20)
plt.xlabel('epoch', fontsize=20)
plt.legend(['training', 'test'], loc='best', fontsize=20)
plt.figure(figsize=(10,7))
plt.plot(history.history['loss'], color='b', linewidth=3)
plt.plot(history.history['val_loss'], color='r', linewidth=3)
plt.tick_params(labelsize=18)
plt.ylabel('loss', fontsize=20)
plt.xlabel('epoch', fontsize=20)
plt.legend(['training', 'test'], loc='best', fontsize=20)
plt.show()
正解率の遷移は下図のようになりました。
loss関数の遷移は下図のようになりました。
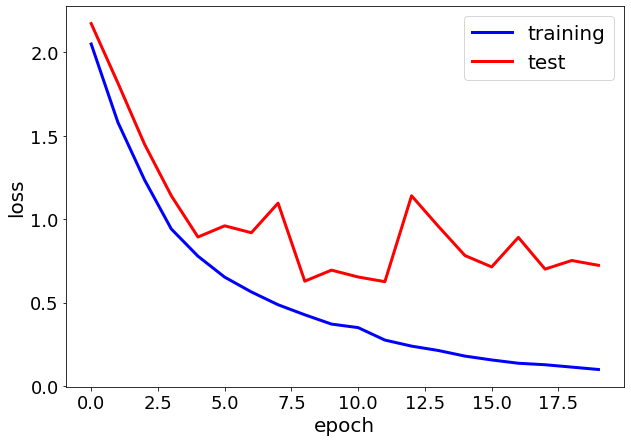
うーん・・・。4エポック目あたりからテストデータのlossが不安定になっていますね。
BatchNormalizationをしましたがOver tariningしているように見えます。
データ保存
今回の学習はそんなに時間がかかっていませんが長時間訓練したモデルは保存しておくことで再利用できます。
下記のようにモデルと重みを保存します。
'''データ保存'''
model.save('cifar10-CNN.h5')
model.save_weights('cifar10-CNN-weights.h5')
まとめ
今回はチュートリアルということでKerasを用いてCIFAR10の画像を有名なVGG16モデルで識別してみました。
VGG16は元々1000クラス分類のために使用されたモデルなので、入出力サイズを変えてBatchNormalizationを使いましたが、Over trainingしてしまいました。入出力サイズが小さすぎるのかもしれません。
また、改善手法としてDropoutやL2正則化の実装や最適化手法のチューニングが考えられます。
参考文献
本コードの実装は以下の書籍を参考にしました。
- 『Kerasによるディープラーニング 実践テクニック&チューニング技法』 青野 雅樹、森北出版株式会社発行、2019