はじめに
Dependency Injection (以下 "DI" と略す) とは、コンポーネントの依存関係にまつわる諸問題をいい感じに解決してくれる機構である。「コンポーネントの依存関係」とは、例えば一般的なレイヤードアーキテクチャでの Controller → Service → Repository といった上位層から下位層につながるような関係のことを指す。「いい感じに解決」とは、開発者が手動で頑張らなくてもフレームワークが良きに計らってくれることを意味する。
モダンな Java アプリケーション開発において、DI はほぼ必須の機構である。筆者は主にバックエンドを主戦場としてアプリケーションの開発と運用に携わっているが、Web アプリケーションであろうがコマンドラインから起動するバッチであろうが、Java でアプリケーションを開発するのであれば使い捨てを除くほとんどの場合で DI を活用している。DI 概念の登場から 15 年以上が経過した現在、フレームワークは十分に成熟している。また、DI の利用にあたってコードレビュー等で致命的な問題が発覚することは少ない (いまだに問題を頻発させる例外処理とは対照的である)。
だが、世の DI をめぐる言説には不可解な混乱が見られる。例えば、DI の最初の一歩だけを取り上げて、実用上の利点をほとんど説明しきれていない記事が検索上位に散見される。また、ソーシャルメディア等では Java における DI の要否に関して (筆者に言わせれば) 周回遅れの議論が繰り返されている場面も観察される。
この記事では、DI をめぐる言説の混乱を少しでも是正できるよう、DI の必要性がどのような技術的課題の上に発生するのかを段階的に示す。さらに、段階を上って DI に到達した後で利用できる重要な機能や、DI を活用する上で注意すべき諸論点についてもあわせて解説する。
説明の題材
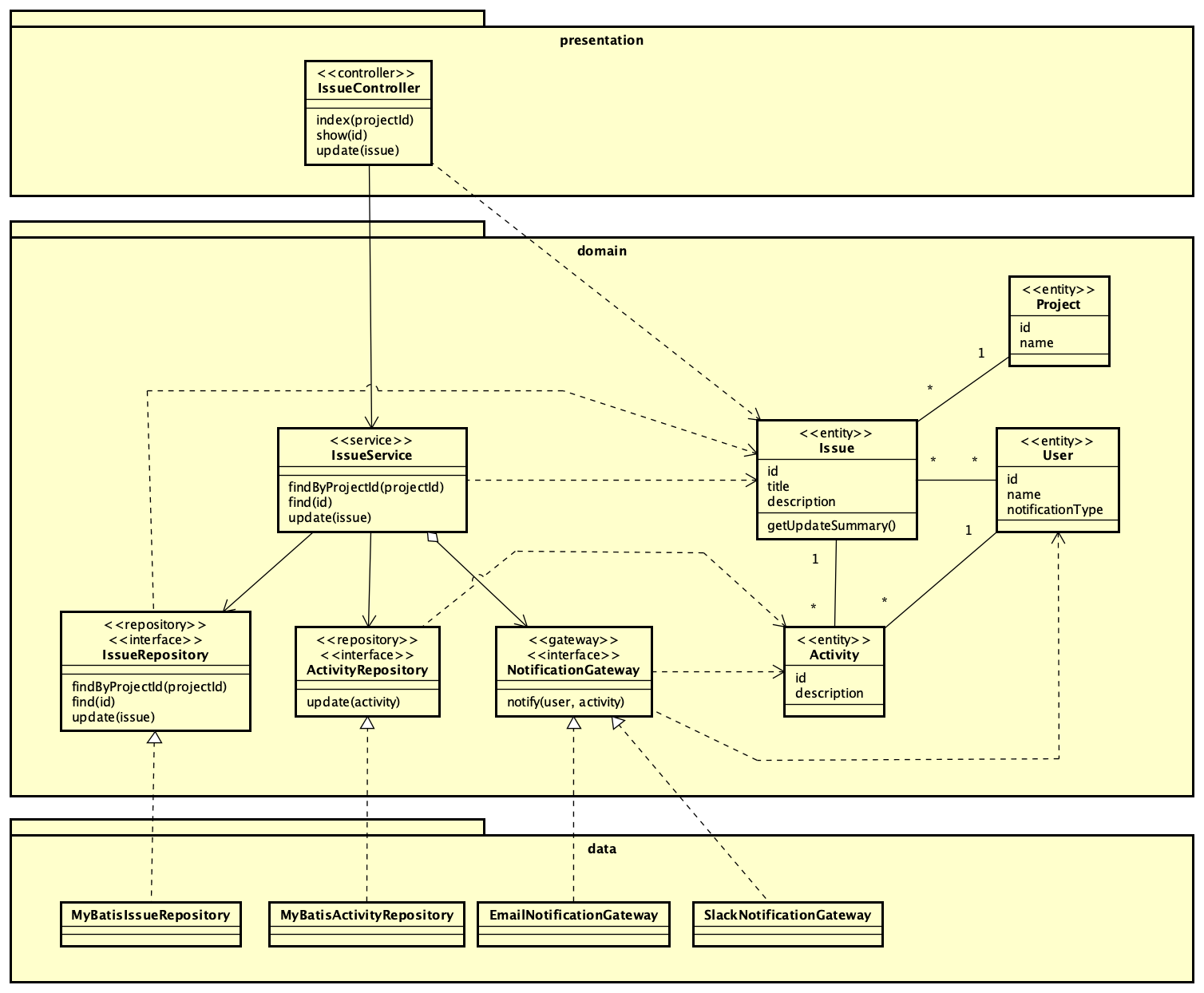
説明の題材として、シンプルな課題管理システムにおける課題更新のユースケースを考える。
- ユーザは、プロジェクトの課題一覧ページを開く
- システムは、プロジェクトに紐付く課題のリストを返す
- ユーザは、課題を選択して属性 (説明など) を更新する
- システムは、更新された課題を上書き方式で記録する
- システムは、課題の更新履歴を追記方式で記録する
- システムは、課題に紐付く全関係者について、7 を繰り返す
- システムは、設定された方式 (メールと Slack のいずれか) で通知を送信する
このユースケースを実現するためのクラス構造は、一般的な 3 層のレイヤードアーキテクチャに基づくと以下のようなものになるだろう。
DI に到達するまでの 6 レベル
この章では、DI に到達するまでの課題解決の道のりを 6 レベルに分けて解説する。
- レベル 1: static メソッド
- レベル 2: 自前の依存先インスタンス生成
- レベル 3: 自前のオブジェクトグラフ構築
- レベル 4: 自前の Factory
- レベル 5: Service Locator
- レベル 6: Dependency Injection
レベル 1: static メソッド
まず最もシンプルな方式として、Service・Repository・Gateway の処理を static メソッドで実装してみよう。以下にユースケースのステップ 4-7 に対応する Service 処理の実装を示す。
public class IssueService {
public static void update(Issue issue) {
// 課題を上書きで記録する
IssueRepository.update(issue);
// 課題の更新履歴を追記で記録する
Activity activity = new Activity();
activity.setIssue(issue);
String description = "Issue updated: " + issue.getUpdateSummary();
activity.setDescription(description);
ActivityRepository.update(activity);
// 課題に紐付く全関係者について、設定された方式で通知を送信する
issue.getWatchers().forEach(user -> {
switch (user.getNotificationType()) {
case Email:
EmailNotificationGateway.send(user, activity);
break;
case Slack:
SlackNotificationGateway.send(user, activity);
break;
default:
throw new IllegalStateException("This could not happen");
}
});
}
}
この方式にはいくつもの問題がある。実業務で真似をしてはならない。
- インタフェースが利用できない
- クラス図で意図された依存性逆転の原則が完全に無視されている
- ポリモーフィズムが利用できない
- 例えばメールと Slack 以外の通知方法が増えると、利用側で分岐を追加しなければならない
- 単体テストが難しい
- 本来は Mockito のようなライブラリで依存先を mock に差し替えれば容易にコンポーネントの単体テストに対応できるが、static メソッドの差し替えには技術的な困難がある (不可能ではないが、副作用が大きいため多くの場合やるべきではない)
- static メソッドや static フィールドの多用により設計の全体に悪い影響がもたらされる
- そもそもこうした設計は Java においてきわめて初歩的な誤りであるため、詳細な説明は省略する (さらに説明が必要な場合は「static おじさん」の検索結果を参照してほしい)
レベル 2: 自前の依存先インスタンス生成
次に、依存元が依存先を直接生成する方式で実装してみよう。
public class IssueService {
private final IssueRepository issueRepository = new MyBatisIssueRepository();
private final ActivityRepository activityRepository = new MyBatisActivityRepository();
private final Map<NotificationType, NotificationGateway> notificationGateways = Map
.of(NotificationType.Slack, new SlackNotificationGateway(),
NotificationType.Email, new EmailNotificationGateway());
public void update(Issue issue) {
// 課題を上書きで記録する
issueRepository.update(issue);
// 課題の更新履歴を追記で記録する
Activity activity = new Activity();
activity.setIssue(issue);
String description = "Issue updated: " + issue.getUpdateSummary();
activity.setDescription(description);
activityRepository.update(activity);
// 課題に紐付く全関係者について、設定された方式で通知を送信する
issue.getWatchers().forEach(user -> notificationGateways
.get(user.getNotificationType()).send(user, activity));
}
}
これでレベル 1 の問題は解決するが、以下の問題は残る。
- 依存先の実装が隠蔽されない
- Repository や Gateway のインタフェースを切り出して下位層を隠蔽したはずが、依存元で実装クラスを意識している
- 依存元が依存先のライフサイクルを手動で管理しなければならない
- 本来、状態を持たない Service・Repository・Gateway 等を都度インスタンス化するのは非効率である
- 依存先の生成にパラメータが必要な場合、似た初期化コードが複数箇所で重複する
- 上記例ではコンストラクタパラメータを省略しているが、本来 Repository や Gateway のようなコンポーネントは通信に関する環境依存設定を持つはずである
レベル 3: 自前のオブジェクトグラフ構築
依存先の直接生成に問題があるのであれば、それらの責務をクラスの外側に追い出してみよう。IssueService は全ての依存先をコンストラクタで受け取ることにする。
public class IssueService {
private final IssueRepository issueRepository;
private final ActivityRepository activityRepository;
private final Map<NotificationType, NotificationGateway> notificationGateways;
public IssueService(IssueRepository issueRepository,
ActivityRepository activityRepository,
Map<NotificationType, NotificationGateway> notificationGateways) {
this.issueRepository = issueRepository;
this.activityRepository = activityRepository;
this.notificationGateways = notificationGateways;
}
public void update(Issue issue) {
// 課題を上書きで記録する
issueRepository.update(issue);
// 課題の更新履歴を追記で記録する
Activity activity = new Activity();
activity.setIssue(issue);
String description = "Issue updated: " + issue.getUpdateSummary();
activity.setDescription(description);
activityRepository.update(activity);
// 課題に紐付く全関係者について、設定された方式で通知を送信する
issue.getWatchers().forEach(user -> notificationGateways
.get(user.getNotificationType()).send(user, activity));
}
}
依存関係を構築する責務は最上位の IssueController に持たせる。
public class IssueController {
private final IssueService issueService = new IssueService(
new MyBatisIssueRepository(), new MyBatisActivityRepository(),
Map.of(NotificationType.Slack, new SlackNotificationGateway(),
NotificationType.Email, new EmailNotificationGateway()));
public void update(Issue issue) {
issueService.update(issue);
}
}
この方式にも問題が多い。
- 依存先の実装が部分的にしか隠蔽されない
- 最上位層では依存先の実装を意識する必要がある
- 類似したオブジェクトグラフ構築処理を重複して実装しなければならない
- 下位層のコンポーネントは上位層の複数コンポーネントで少しずつ違った形で共用されるため、各所で似て非なるオブジェクトグラフを構築する重複実装が強いられる
- 最上位層でフレームワークを利用する場合、コンポーネントの生成を自由に制御できない
- 例えば、一般的な Web アプリケーションにおいて Controller の生成は開発者のコードではなくフレームワークの責務である
なお、冒頭で簡単に触れた通り、レベル 3 までの説明をもって DI の解説を終わらせる記事が散見されるが、筆者はそうした取り上げ方に賛同しない。理由は三つある。まず、原典の Assembler 要素が不当に軽視されているため、パターンの祖述としては片手落ちであるからである。次に、この節で問題点を挙げた通り、自動化された Assembler なしの自前オブジェクトグラフ構築は手法として現実的でないからである。最後に、この記事で後述する「さらなる利点」まで考慮しない限り、利用の要否が正しく判断できないからである。
レベル 4: 自前の Factory
依存先の生成に個別対応することが問題なのであれば、その責務を担う専用のコンポーネントを作ってみよう。まず、Repository の生成を担うクラスである。
public class RepositoryFactory {
private static final RepositoryFactory INSTANCE = new RepositoryFactory();
private final Map<Class<?>, Object> repositories = Map.of(
IssueRepository.class, new MyBatisIssueRepository(),
ActivityRepository.class, new MyBatisActivityRepository());
private RepositoryFactory() {
}
public static RepositoryFactory getInstance() {
return INSTANCE;
}
@SuppressWarnings("unchecked")
public <T> T get(Class<T> clazz) {
return (T) repositories.get(clazz);
}
}
また、Gateway の生成を担うクラスも作る。こちらは実行時に実装クラスを差し替える要件があるため、Repository の生成とは少々ロジックが異なる。
public class NotificationGatewayFactory {
private static final NotificationGatewayFactory INSTANCE = new NotificationGatewayFactory();
private final Map<NotificationType, NotificationGateway> notificationGateways = Map
.of(NotificationType.Slack, new SlackNotificationGateway(),
NotificationType.Email, new EmailNotificationGateway());
private NotificationGatewayFactory() {
}
public static NotificationGatewayFactory getInstance() {
return INSTANCE;
}
public NotificationGateway get(NotificationType type) {
return notificationGateways.get(type);
}
}
これらを利用すると、IssueService の処理は以下のように書き換えられる。
public class IssueService {
private final IssueRepository issueRepository = RepositoryFactory
.getInstance().get(IssueRepository.class);
private final ActivityRepository activityRepository = RepositoryFactory
.getInstance().get(ActivityRepository.class);
private final NotificationGatewayFactory notificationGatewayFactory = NotificationGatewayFactory
.getInstance();
public void update(Issue issue) {
// 課題を上書きで記録する
issueRepository.update(issue);
// 課題の更新履歴を追記で記録する
Activity activity = new Activity();
activity.setIssue(issue);
String description = "Issue updated: " + issue.getUpdateSummary();
activity.setDescription(description);
activityRepository.update(activity);
// 課題に紐付く全関係者について、設定された方式で通知を送信する
issue.getWatchers().forEach(user -> notificationGatewayFactory
.get(user.getNotificationType()).send(user, activity));
}
}
これでレベル 2-3 の問題は解決するが、以下の問題は残る。
- Factory の実装が煩雑になる
- アプリケーションの規模が拡大するにつれて、Factory のコードを手動で書く手間が増えていく
- ライフサイクルの手動管理が残る
- 各 Factory は自前で Singleton パターンを実装している
レベル 5: Service Locator
自前での対応に限界があるのであれば、それらを自動で解決してくれる仕組みを導入しよう。原典でも DI と対比されている Service Locator パターンである。
public class IssueService {
private final IssueRepository issueRepository = ServiceLocator.getInstance()
.get(IssueRepository.class);
private final ActivityRepository activityRepository = ServiceLocator
.getInstance().get(ActivityRepository.class);
@SuppressWarnings("serial")
private final Map<NotificationType, NotificationGateway> notificationGateways = ServiceLocator
.getInstance()
.get(new TypeToken<Map<NotificationType, NotificationGateway>>() {
});
public void update(Issue issue) {
// 課題を上書きで記録する
issueRepository.update(issue);
// 課題の更新履歴を追記で記録する
Activity activity = new Activity();
activity.setIssue(issue);
String description = "Issue updated: " + issue.getUpdateSummary();
activity.setDescription(description);
activityRepository.update(activity);
// 課題に紐付く全関係者について、設定された方式で通知を送信する
issue.getWatchers().forEach(user -> notificationGateways
.get(user.getNotificationType()).send(user, activity));
}
}
上記コードに登場する ServiceLocator クラスは、インタフェースから実装クラスを検索したり、コンポーネントのライフサイクルを適切に管理したり、特殊なコンポーネントのためのカスタム初期化コードを差し込めたり、といった様々な便利機能を持つはずの架空のクラスである。
これで自前実装に伴う諸問題は解決するが、以下の問題は残る。
- 依存先を検索する定型的なコードがやや煩雑になる
- 後述の DI を利用したコードと比較すれば差は一目瞭然である
- 単体テストがやや煩雑になる
- 単体テストで依存先を mock に差し替える場合、Service Locator への登録が必要になる
- コンポーネントのポータビリティが損なわれる
- 全ての依存関係の解決が Service Locator に依存するため、Service Locator を利用しない他プロジェクトとコンポーネントを共用できない
- 実用的なフレームワークが存在しない
- 2020 年現在、Service Locator に特化した有力な Java フレームワークはない (実は DI フレームワークのコアなクラスは Service Locator としても利用できるが、そうした使い方を正当化する利点ほとんどない)
なお、原典からは Service Locator を DI より手軽な手段として使い分けるべきとの主張が読み取れるが、DI フレームワークが十分に手軽に使えるようになった 2020 年現在においてもはやその妥当性は小さいと筆者は考える。
レベル 6: Dependency Injection
自前であろうがなかろうが、依存関係の明示的な集中管理には無理があるようだ。では、暗黙的な手法を使うよう方針転換しよう。
ここで、この記事の主題である DI がようやく登場する。コンポーネントのコード自体はレベル 3 とほぼ同じだが、DI 用のアノテーション (JSR-330 の @Inject) が付与されている点だけが異なる (DI フレームワークによってはアノテーションすら不要な場合もある)。このコンポーネントを DI フレームワーク管理下で利用すると、よろしく生成された依存先コンポーネントがコンストラクタに自動的に注入される。
public class IssueService {
private final IssueRepository issueRepository;
private final ActivityRepository activityRepository;
private final Map<NotificationType, NotificationGateway> notificationGateways;
@Inject
public IssueService(IssueRepository issueRepository,
ActivityRepository activityRepository,
Map<NotificationType, NotificationGateway> notificationGateways) {
this.issueRepository = issueRepository;
this.activityRepository = activityRepository;
this.notificationGateways = notificationGateways;
}
public void update(Issue issue) {
// 課題を上書きで記録する
issueRepository.update(issue);
// 課題の更新履歴を追記で記録する
Activity activity = new Activity();
activity.setIssue(issue);
String description = "Issue updated: " + issue.getUpdateSummary();
activity.setDescription(description);
activityRepository.update(activity);
// 課題に紐付く全関係者について、設定された方式で通知を送信する
issue.getWatchers().forEach(user -> notificationGateways
.get(user.getNotificationType()).send(user, activity));
}
}
インタフェースから実装クラスを検索したり、コンポーネントのライフサイクルを適切に管理したり、特殊なコンポーネントのためのカスタム初期化コードを差し込めたり、といった機能を持つ点は DI フレームワークと Service Locator で共通である。
これでレベル 5 の問題は解決する。依存先の明示的な検索は不要になり、単体テストで mock を使いたければ単にコンストラクタから差し込めば良く、コンポーネントは (アノテーションを無視すれば) ポータブルで、実用的なフレームワークとしてはいくつかの選択肢がある。
DI フレームワークの導入自体にも特に大きな障壁はない。モダンな Web フレームワークであれば DI フレームワークとの連携機能があり、Controller 以下全てのコンポーネントは DI フレームワークによって管理できる。また、コマンドラインアプリケーションでも例えばこんな簡単な初期化コードを main メソッドに組み込むだけで良い。
ここまでで DI によって実現できた利点
ここまでで DI によって実現できた利点を簡単にまとめておこう。
- オブジェクトグラフの自動構築
- 下位層の実装の完全な隠蔽
- コンポーネントの単体テスト容易性
- コンポーネントのポータビリティ
- コンポーネントのライフサイクル管理
DI のさらなる利点
DI の導入によって、さらに以下のような利点も享受できる。特に環境依存設定の管理は上述の諸利点に劣らず重要である (なお、これらの利点は Service Locator でも技術的には同様に実現できる)。
環境依存設定の管理
DI フレームワークは、依存先コンポーネントだけではなく、いわゆる環境依存設定の値もコンポーネントに注入できる。例えば、本来 Gateway 実装にはエンドポイント URL・リトライ回数・タイムアウト秒数といった外部通信用パラメータがあり、値は開発・テスト・ステージング・本番といった環境によって異なるだろう。DI フレームワークの環境依存設定に関する機構を使えば、これらの値もコンポーネントに注入できる。
具体的なコード例については、Spring Boot の Externalized Configuration や Guice の Names.bindProperties のサンプルを参照してほしい。
宣言的なライフサイクル管理
DI フレームワークは、コンポーネントのライフサイクルを宣言的に管理する機構を提供する。コンポーネントのライフサイクルについては、リクエスト単位でインスタンスを生成したい、状態を持たない共通の 1 インスタンスがあれば十分、ある手続きの間に複数リクエストにわたってインスタンスを持続させたい、といったさまざまな要件がありうる。DI フレームワークを利用すると、こうした要件に簡単に対応できる。
具体的なコード例については、Spring のスコープや、Guice のスコープのサンプルを参照してほしい。
前後処理の差し込み (AOP)
AOP とは、簡単に言うと、本来関係のない複数の機能に対して横串で共通の前後処理を差し込む仕組みである (厳密な説明は省略する)。AOP については、過去に過大な期待を受けた反動もあってか、未だに「ロギングにしか使えない」といった悪口が聞こえてくることもある。が、実際はロギング以外にもキャッシュやトランザクション制御を水面下で支える機構として利用されている。また、例外処理についても AOP の出番はありうるだろう。
具体的なコード例については、Spring の AOP や Guice の AOP のサンプルを参照してほしい。
DI を利用する上での諸論点
DI を実際の開発に利用する上で問題になりがちな点についてもまとめておこう。
フレームワークの選定
Java における Dependency Injection の標準規格 JSR-330 をサポートするフレームワークは複数ある。例えば GitHub の JSR-330 プロジェクト にはマイナーなものも含めてテストにパスしたフレームワークのリストがある。また、JSR-330 implementation で検索すれば、それら以外の選択肢もいくつか見つかるだろう。
だが、実際のアプリケーション開発において、DI フレームワークの選定それ自体が問題になることは少ない。多くの場合、以下のような外部要因で身も蓋もなく選択肢は決まってしまう。
- Spring のエコシステムを活用する場合、Spring Framework
- Jakarta EE のエコシステムを活用する場合、アプリケーションサーバにバンドルされた CDI 実装 (Weld など)
- 上記のようなエコシステムが必要ないシンプルなアプリケーションの場合、Guice
- Android アプリケーションの場合、Guice か Dagger
Injection 方式
DI フレームワークがアプリケーションに依存先を注入するやりかたには主に以下の 3 種類がある。上述のサンプルコードは 1 番目のコンストラクタから注入する方式である。
- コンストラクタから注入する
- Setter などのメソッドから注入する
- フィールドに直接注入する
一般的には、オブジェクトの不変性を保てる点でコンストラクタから注入する方式が推奨されている。が、コードが最も簡潔になる点でフィールドに直接注入する方式が好まれる現場もあるだろう。
具体的なコード例については Guice の Injection 方式解説を参照してほしい。
コンポーネント設定方式
DI の黎明期には全てのコンポーネントを xml の設定ファイルに列挙する方式が主流だったが、現在ではアノテーションを使用する方式にほぼ取って代わられている。
また、設定ファイルやアノテーションでの宣言的な設定では表現しきれない依存関係については、コードで書ける拡張ポイントが用意されている。
拡張ポイントの具体的なコード例については、Guice の @Provides や Multibindings のサンプルを参照してほしい。
コンポーネントスキャン
コンポーネントスキャンとは、アプリケーション起動時にクラスパス中のコンポーネントを解析し、DI に必要なメタデータを自動的に取得する処理である。これにより、例えば設定に明示することなくインタフェースと実装クラスを紐付けたり、起動前に設定の問題を発見したりといった要件に対応できる。一方で、スキャン範囲が広くなればなるほど、当然のことながら起動パフォーマンスの面では明確な弱点を抱えることになる。
コンポーネントスキャンの扱いはフレームワークによって異なる。Spring Framework や CDI はコンポーネントスキャンの手軽さを重視する。対して Guice はコンポーネントスキャンを排除して動作をシンプルかつ高速に保っている。
Java 以外の言語と DI
ここまで Java アプリケーション開発における DI の利点を述べてきたが、これらの議論は Java 以外の言語に対して無条件には適用できない。より柔軟な動的型付き言語 (Ruby など) であれば、この記事でいうレベル 1 の手段であっても Java のような制約は受けないだろう。また、より表現力の高い静的型付き言語 (Scala など) であれば、DI と類似した機構を言語仕様レベルのサポートに基づいてより安全に実現する選択肢もあるだろう。
おわりに
以上、Java アプリケーション開発における DI の利点と諸論点についてまとめた。背景を理解した上での DI 活用や生産的な DI 談義に役立てば幸いである。