はじめに
このページで記述する例はすべてpythonを用いています。また筆者の知識が未熟な部分もあると思いますので、間違い等ありましたら、コメントよろしくお願いします。
jsonファイルを用いたデータ保存
jsonを知るまで
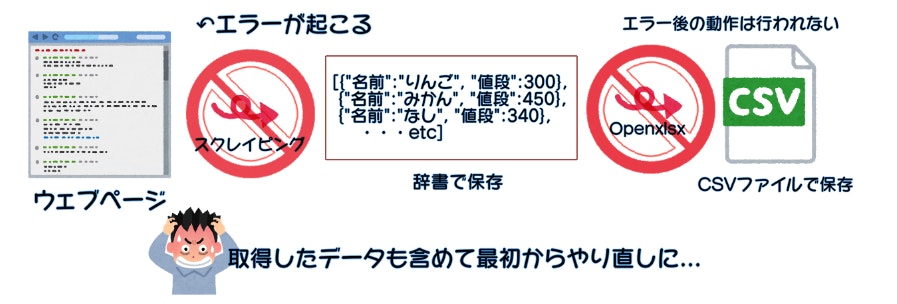
jsonファイルを知るまで、スクレイピングしたデータは直接Openxlsxを用いてCSVファイルに
保存していました。

この方法だと、
1.すべてのデータスクレイピングの作業が終了
2.Openxlsxによる書き込み作業
という作業手順なのでスクレイピング中にエラーが起きた場合に
実行していたコードが途中で止まり、辞書のデータも削除されます。
そのためデータの収集はまた最初からやり直しになり、収集するデータ量が多いとウェブページのサーバーに無駄な負担をかけてしまったり時間の浪費に繋がります。
jsonを知ったあと
そこでjsonファイルを用いたデータ保存を行います。
まず、一連の動作を2つのコードに分けます。
1つ目のコードでは、各ウェブページごとに
1.スクレイピング
2.jsonファイルに追記
の動作を繰り返し、
2つ目のコードでは、jsonファイルを読み込みCSVファイルを作成します。
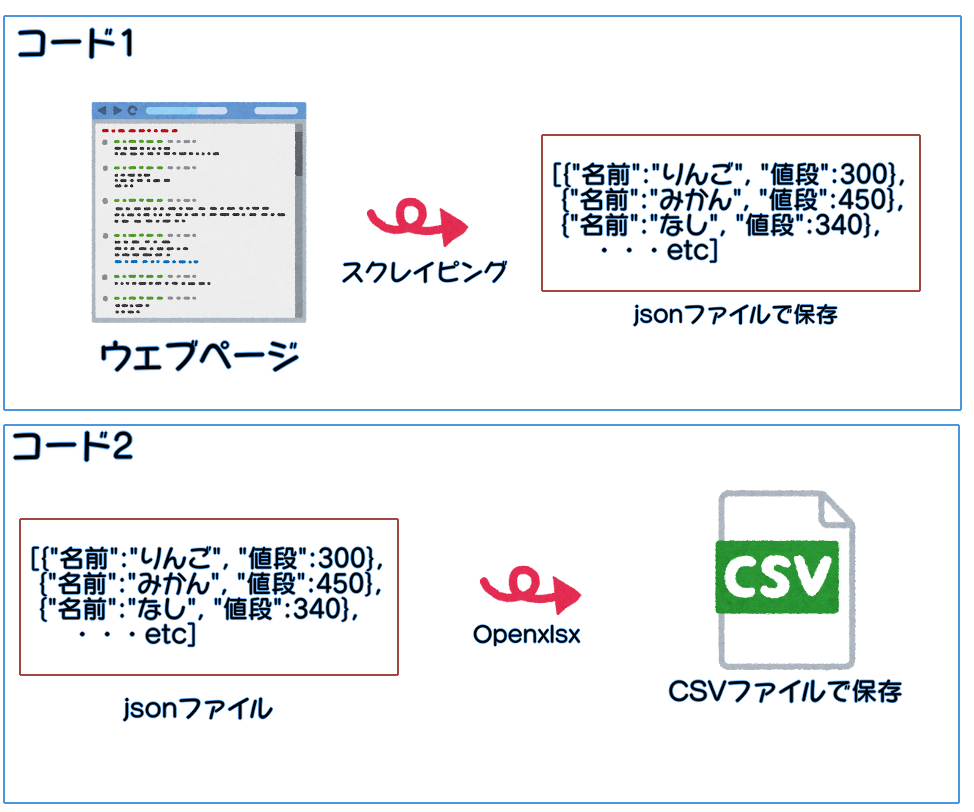
もし、スクレイピング中にエラーが発生してもjsonファイルを用いれば、各ウェブページごとに追記を行うので、途中から再開が可能です。

具体例
それでは、例として以下のようなウェブページがあるとします。
link:...../apple.html
<p>りんご</p>
<p>300</p>
link:...../orange.html
<p>みかん</p>
<p>450</p>
link:...../pear.html
<p>なし</p>
<p>340</p>
...etc
動作手順
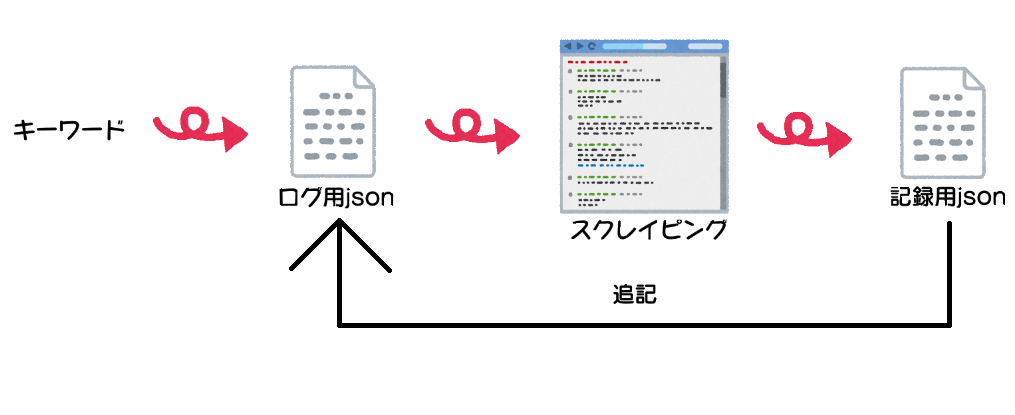
jsonファイルは「ログ用」と「記録用」に分けます。キーワードごとにこの動作を繰り返し、ログ用jsonにすでにキーワードが登録されている場合はスクレイピングが行われないようにします。
キーワードがログ用jsonにないとき

キーワードがログ用jsonにあるとき

また、スクレイピングを行ったら、キーワードをログ用jsonに追記します。
実際のコード
実際のコードは以下の通りになります。
import json
import codecs
def load_log_json():
with codecs.open("log.json", 'r','utf-8') as fr:
log = json.loads(fr.read())
return log
def write_log_json(key):
logs = load_log_json()
logs.append(key)
with codecs.open("log.json", 'w','utf-8') as fw:
json.dump(logs,fw,indent=4,ensure_ascii=False)
def write_inform(item):
with codecs.open("record.json", 'a','utf-8') as fw:
if(len(item) != 0):
json.dump(item,fw,indent=4,ensure_ascii=False)
def test():
keys = ["apple","orange","pear"]
logs = load_log_json()
imforms = []
for key in keys:
if key in logs:
print('{0}は取得済み'.format(key))
else:
try:
inform = fruits(key)
'''fruits()関数は{"名前":〇〇〇,"値段":□□□}
のような辞書型のデータを返します
'''
print('果物の名前は{0}、値段は{1}円です'.format(inform["名前"],inform["値段"]))
write_log_json(key)
informs.append(imform)
except:
print('{0}は存在しないようです。'.format(key))
return 'error'
write_inform(informs)
ざっくりと説明すると、 load_log_json()関数でログ用jsonを読み込み、write_log_json()関数でログ用jsonに追記、write_inform()関数で記録用jsonファイルに書き込みを行っています。
こちらのコードを実行すると1回目は
果物の名前はりんご、値段は300円です
果物の名前はみかん、値段は450円です
果物の名前はなし、値段は340円です
と出力され、各ファイルの内容は
[
"りんご",
"みかん",
"なし"
]
[
{
"名前": "りんご",
"値段": 300
},
{
"名前": "みかん",
"値段": 450
},
{
"名前": "なし",
"値段": 340
}
]
となります。
同じコードを実行すると、出力結果は以下のようになります。
取得済みのデータなのでスクレイピングは行われません。
りんごは取得済み
みかんは取得済み
なしは取得済み
では次はウェブページには存在しないキーワードを含み、実行します。
keys = ["apple","orange","gum gum fruit","pear"]
実行結果は当然エラーが出力されます。
果物の名前はりんご、値段は300円です
果物の名前はなし、値段は340円です
ゴムゴムの実は存在しないようです。
記録用jsonを確認するとりんごとなしのデータがちゃんと取得できています。
[
{
"名前": "りんご",
"値段": 300
},
{
"名前": "なし",
"値段": 340
}
]
またログ用jsonにもりんごとなしが記録されているので再度実行した際に、りんごとなしのページはスクレイピングされることはありません。
[
"りんご",
"なし"
]
最後に
スクレイピングという技術を知るに当たりいくつかの技術書を読みましたが、多くの技術書でMongoDBやMySQLといったデータベースを紹介していました。データベースを使えばこういった面倒な作業を避けられるようですが、私自身のまだまだ知識面で未熟な部分が多く、データベースという得体の知れない技術をうまく扱うことができる自信がなかったので、今回のようなjsonファイルを使ったデータ保存法を選びました。
最後の最後に、初投稿なのでレイアウト面などでおかしな部分があるかもしれないです...よかったら教えてください。閲覧ありがとうございました。