過去にインターン先で Apache Kafka という OSS プロジェクトに触れる機会がありました。今回はその時に理解したことをまとめようと思います。
読者対象
Apache Kafka に触れたことがない方が対象です。何をするもので、どう使うのか、ということに関して書きます。内部でどのようにデータが管理されているか、他の OSS との比較などについては記述しません。すでに概要を知っていて、パフォーマンスのチューニング、細かい挙動の詳細などを必要としている方には不要な内容かもしれません。そのような場合は、脳内のキャッシュを利用しながら適宜読み飛ばしていただくことでパフォーマンスの低下を避けていただければと思います。
内容
- Kafka の紹介
- 起動・設定方法
- メッセージの送受信 ( Python クライアント利用 )
- trifecta を用いて UI から確認
(詳細に関しては省略か、インデントを下げて記述します)
Apache Kafka とは
Linked-In が開発した分散メッセージングシステム。下図参考。
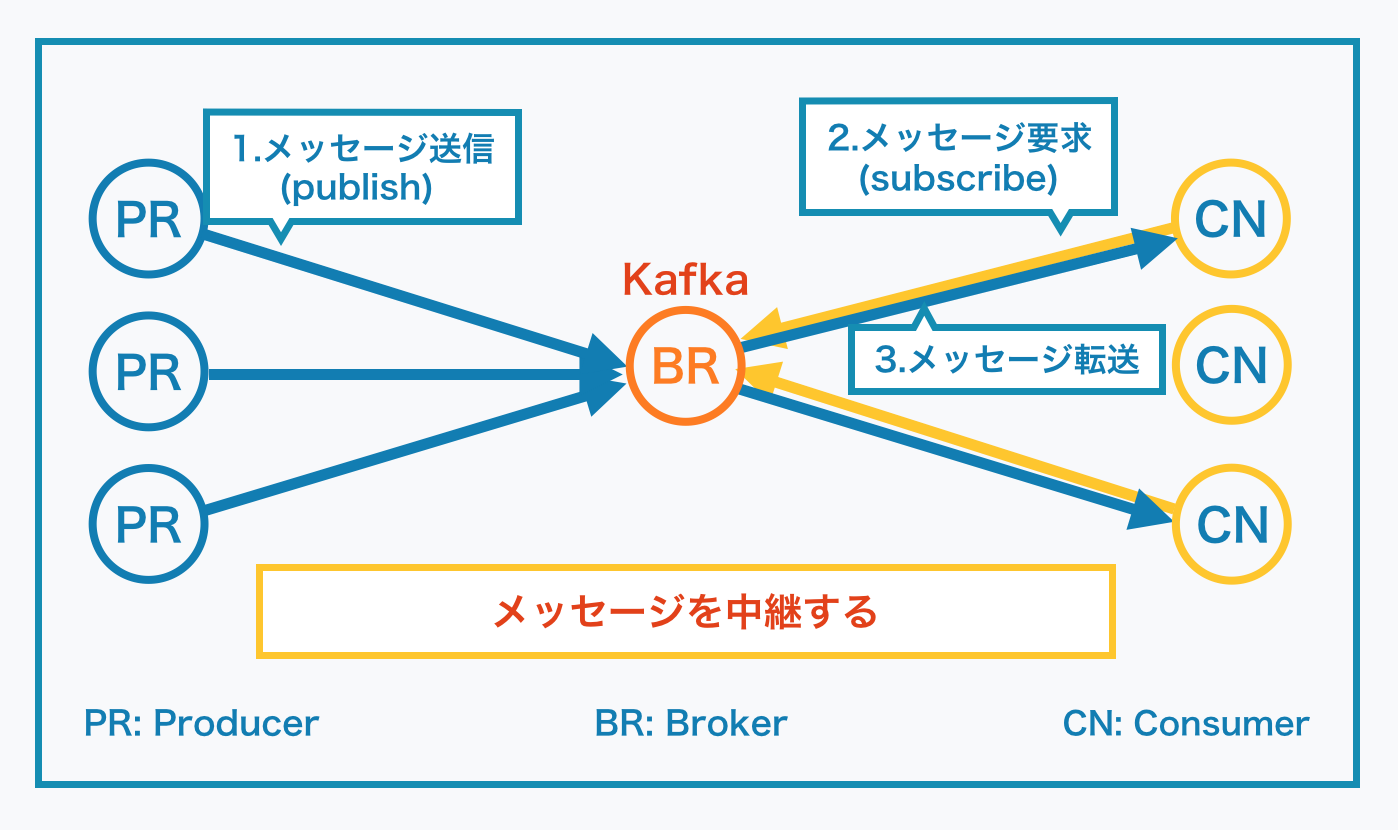
やることはメッセージの中継。
図では BR(Broker: 仲介者) が一つしかないですが、実際は Zookeeper というOSSが裏で動いていて、複数のKafkaが連携してクラスターとなります。クライアントは PR(Producer/Publisher) と CN(Consumer/Subscriber) の二種類存在。
**こんなもん何に使うのさ?**と思う訳ですが、例えばサーバーから出てくるログを機械学習にかけてなんかしようぜ、という時に機械学習の処理時間が長いので一気にログを送ると処理できない、というケースで間に挟んだりします(という例を今思いつきました)。Consumer 側がデータを要求することでデータの取得をするモデルは Publish-Subscribe モデル なんて言われていて、Consumer 側でスループットの調整ができるなどのメリットがあります。複数のサーバ (Producer) が生成するログを一箇所にまとめてからの取得 (Subscribe) できたりするのも便利だったりします。
個人的に感じた一番のメリットはプロジェクト間の連携を楽にすることでした。スループットが要求される複数のプロジェクト間で連携を取る際に、Kafka のクライアントのみ実装し、他のプロジェクト(一つでない)に対するクライアントを実装する部分のコストが減ったのが楽でした。
Kafka を起動させてみる
Ubuntu 動作環境を Ubuntu 14.04 として試しています。
Scala なのでMacでも動作すると思います(試してたことないですが)
公式のHP からダウンロード
使用している Scala のバージョンによってダウンロードするものが違う点に注意
scala -version # Scala のバージョン確認
Github のコードから clone したりしてはいけない (初めて触ることになったときに github のコードから入り、動いてくれなくて時間がぁぁぁあ、ってなったので...)。
tar -xvzf kafka_[SCALA_VERSION]-[KAFKA_VERSION].tgz # ダウンロードしたものを解凍
kafka
├── bin
│ ├── kafka-server-start.sh # Kafka 起動用シェルスクリプト
│ ├── kafka-server-stop.sh
│ ├── kafka-topics.sh
│ ├── zookeeper-server-start.sh # Zookeeper 起動用シェルスクリプト
│ └── zookeeper-server-stop.sh
├── config
│ ├── server.properties # Kafka の設定ファイル
│ └── zookeeper.properties # Zookeeper の設定ファイル
├── libs
├── LICENSE
...
kafka/bin/zookeeper-server-start.sh -daemon kafka/config/zookeeper.properties
bin/zookeeper-server-stop.sh
dataDir=/tmp/zookeeper
clientPort=2181 # Zookeeper がサービス提供するポート番号
maxClientCnxns=0
# -daemon option がなければブロッキングモードで起動される
kafka/bin/kafka-server-start.sh -daemon kafka/config/server.properties
bin/kafka-server-stop.sh
broker.id=0 # 複数のKafkaをクラスタリングするときの識別子
port=9092 # Kafka がサービス提供するポート番号
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
>
num.partitions=1
num.recovery.threads.per.data.dir=1
>
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
>
zookeeper.connect=localhost:2181 # 利用する Zookeeper
zookeeper.connection.timeout.ms=6000
以上で Apache Kafka のプロセスが立っていると思います。
ps aux | grep zookeeper
ps aux | grep kafka
ここからは公式のドキュメントにあるように(1)トピックを作成、Kafkaをダウンロードした時に一緒についてきた(2) Producer と Consumer のサンプルコードを走らせるというのもいいのですが、その辺のやりかたは公式のチュートリアルやその翻訳を参考にしていただいて、今回は Python のクライアントを利用して見たいと思います。
Python のクライアントを用いて実際にデータをやりとりしてみる
kafka-python という Python のクライアントを用いてメッセージの送信、受信を行ってみる.
pip install kafka-python
$ python
>
import kafka
kafka_client = kafka.KafkaClient('localhost:9092')
# 送信用のクライアントを作成
producer = kafka.SimpleProducer(kafka_client)
# 'my-topic' というトピックにいくつかメッセージを送ってみる
producer.send_messages('my-topic', 'message1')
producer.send_messages('my-topic', 'message2')
producer.send_messages('my-topic', 'message3')
# この段階で Kafka のサーバには my-topic というトピックができていて、
# message[1|2|3] が保存されている
# my-topic に対してデータを取りに行く
consumer = kafka.KafkaConsumer(
'my-topic', group_id='my_group',
bootstrap_servers=['localhost:9092'])
# メッセージの subscribe (for文をいきなり回せば勝手にリクエストしてくれる)
for message in consumer:
print("topic: %s message=%s" % (message.topic, message.value))
# => 'topic: my-topic message1'
# => 'topic: my-topic message2'
# => 'topic: my-topic message3'
これで Python を用いて実際に Kafka にメッセージの送受信を行った。
Python に限らず他のプログラミング言語でも Kafka に対するメッセージの送受信は簡単に行うことができる。
Trifecta を用いて可視化してみる
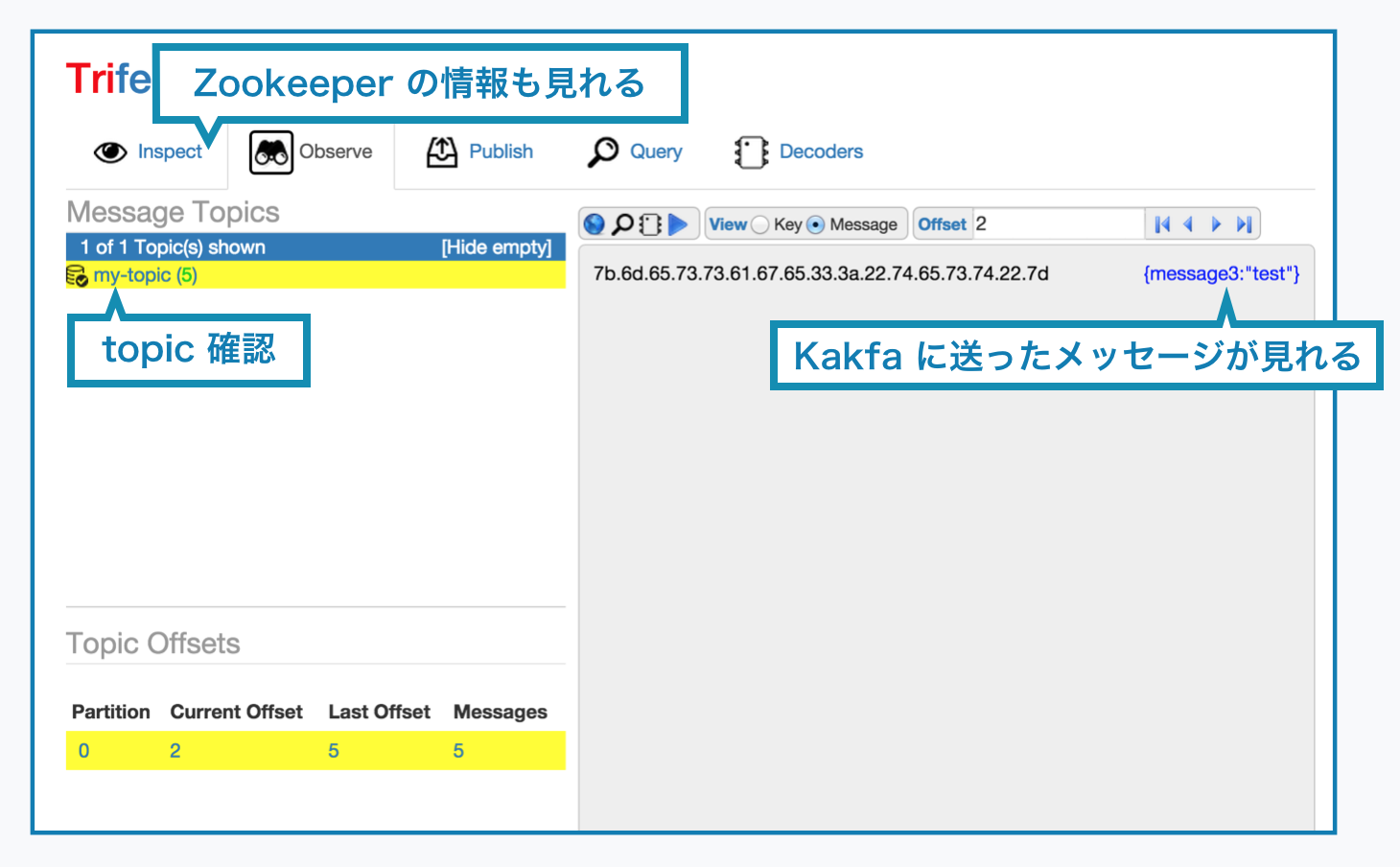
Trifecta を用いることで Kafka の可視化をすることが出来ます。
これによって保存されているメッセージやトピック(メッセージはトピックで分けて管理されます)の種類をUIから見ることが出来ます。
git clone https://github.com/ldaniels528/trifecta.git
echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 642AC823
sudo apt-get update
sudo apt-get install sbt
Ubuntu以外の場合も 公式に書いてあります
sbt clean assembly
trifecta/target/scala-2.11/trifecta_0.18.19.bin.jar
java -jar target/scala-2.11/trifecta_0.18.19.bin.jar --http-start --http-start
http://localhost:8888
以上で上の写真のようなUIが表示され、Kafka が実際にどのようなメッセージを持っているかなどを確認することが出来ます。
まとめ
以上で、Kafka の用途と使い方の説明、及び Trifecta を用いた可視化を行ないました。更に深い理解をするためには他のメッセージングシステムとの比較や、Kafka の Replication や Partition, Topic がどのように管理されているかを知る必要があります。この辺に関しては今後のトピックになるかもしれませんし、ググれば日本語でわかりやすく解説されている記事もありそうでした。
また、実際に Kafka をサービスとして提供する際には supervisord などで起動/停止の自動化をしておくと楽にできるかもしれません(デプロイ関係はいろいろなやり方があると思うので一概には言えませんが)。
最後になりますが、参考にしたサイトを下に記述するのでそちらも参考にしていただければと思います。ありがとうございました。
参考
-
Kafka オフィシャルHP
-
kafkaのコマンドに関して
-
trifecta のREADME