はじめに
プロダクトチームでは、Speeda AI Agentを開発していますが、端々でベクトル検索を用いています。また、ベクトル検索するためのモデル開発や、そのホスティングも自前でおこなっています。
ベクトル検索用のモデルは社内ファインチューニングしているため、社内のベンチマークデータでは、Geminiのベクトルを精度で大きく上回っており、ユーザー体験に貢献していると考えています。また、基盤も安定しており、ニュースのような頻繁かつ断続的に追加されるデータも安定してさばけるような基盤を構築しています。
本シリーズではここに至るまでの以下の技術的な工夫を紹介して行きたいと思います。
- HPAでスケールできるインフラの構築
- vLLM化による速度と安定性の向上
- Sentence Transformersで省計算資源で学習を行う工夫
今回は上記のイントロにある「HPAでスケールできるインフラの構築」を紹介します。
概要
この記事では、自己学習させた 自社LLM (大規模言語モデル)をGoogle Kubernetes Engine (GKE) 上でデプロイする際、ボトルネックとなっていた初期ロード時間を劇的に短縮した方法について、具体的な計測結果と対策を交えてご紹介します。
背景
課題:自己学習モデルのデプロイ時の長い待ち時間
自己学習を終えた自社LLMモデルは、その精度は高いものの、モデルサイズが非常に大きく、サービスインフラへデプロイする際の初期ロードに時間がかかるという大きな課題がありました。
具体的な課題として、Nodeの定期的な再起動・入れ替えが発生するたびに、ユーザーからの推論リクエストを受け付けるまでの時間が長くなり、サービスレベルの維持が難しい状況でした。
⏱️ 計測:どこが遅かったのか?ボトルネックの特定
まずは、デプロイからサービス開始までの時間を計測し、ボトルネックとなっている箇所を特定しました。
| ステップ | 改善前 (計測時間) |
|---|---|
| 1. コンテナイメージのダウンロード (Image Pull) | 約20分 |
| 2. モデルの読み込みと初期化 (Model Load) | 約10分 |
| 合計 | 約30分 |
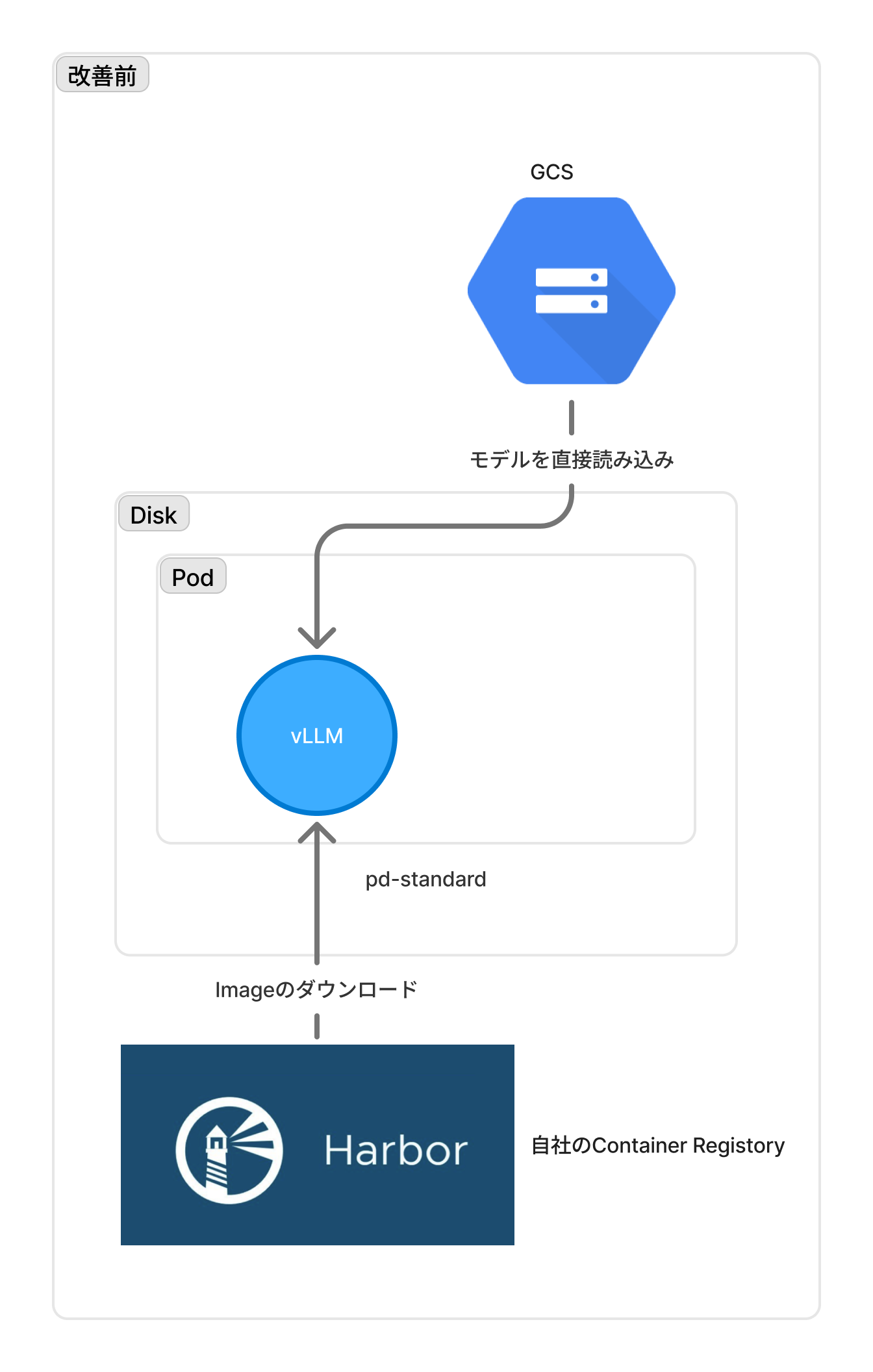
元の構成
高速化方法:ボトルネック解消のための3つの施策
この40分の待ち時間を短縮するため、以下の3つの施策を講じました。
1. 💨 Image Streaming (イメージプルストリーミング) によるイメージDLの劇的な高速化
従来は、自社Registry(Harbor)からの巨大なvLLMイメージ(30GB)とGCSからのモデルデータ(12GB)の転送に膨大な時間を要し、Node入れ替え時のPod起動に約30分かかっていました。この課題に対し、GKEのイメージプルストリーミング機能を導入。イメージをオンデマンドで高速ロードする構成へ変更しました。
| 改善効果 | 30分 → 3秒に短縮! |
有効化手順
以下の gcloud コマンドを実行するだけで、簡単にImage Streamingを有効化できます。
gcloud container clusters update CLUSTER_NAME \
--location=CONTROL_PLANE_LOCATION \
--enable-image-streaming
terraformでは google_container_cluster リソースか、 google_container_node_pool で有効化できます。
gcfs_config {
enabled = true
}
想像以上にイメージが高速DLできるようになったことで、GCSからのModelのDLもInit Container化してしまうことで、GCSからのモデルDLも一瞬で終わるようになりました。
2. ⚡️ モデル読み込みの高速化:ディスクI/Oの改善
vLLMのログから、モデルの読み込みは以下の流れで実行されており、特にディスクからの読み込み速度がボトルネックとなっていました。
- モデルの重みの読み込みと量子化
- モデルの初期化とGPUへの設定
- vLLM (推論エンジン) による最適化とコンパイル
遅かった主な原因は、単純なディスクのI/O速度でした。
解決策:高速なSSDストレージへの切り替え
モデル読み込みのI/Oを改善するため、以下の2箇所でストレージを変更しました。
- GKEのGPU Node自体のブートディスクをSSDに変更
- モデルの一時的な格納先をNVMeインタフェースのSSDに変更
特にモデルの重みファイルを一時的に格納する領域として、ローカル一時ディスク (エフェメラルストレージ) を使用しました。このローカル一時ディスクは、Kubernetesで使用されるemptyDirの一時領域として、ノードに物理的に接続された高速なストレージを利用できます。
emptyDirによるローカル一時ディスクの活用例
ローカルSSDをエフェメラルストレージとして使用するためには、以下のドキュメントを参考に、Pod定義でemptyDirを使用します。
💡 参考: Google Cloudドキュメント「ローカル SSD を使用した高速な一時ストレージ」
apiVersion: v1
kind: Pod
metadata:
name: sample
spec:
containers:
- name: sample
image: <image file name>
volumeMounts:
- name: model-volume
mountPath: /model
volumes:
- name: model-volume
emptyDir: {} # emptyDirによりノードのローカルストレージが利用される
| 改善効果 | 10分 → 3分に短縮! |
📌 補足:セカンダリブートディスクを見送った理由
Image Streamingや本施策と同列で、AIワークロードの改善策としてセカンダリブートディスクの利用も検討しました。しかし、イメージ更新のたびにGKEの再起動が必要であったり、変更時にGKEにイメージのパスを渡す運用作業が必要であったりと、運用を考えた際にサステナブルでなかったため採用を見送っています。
3. 🎯 HPAの適切な設定と連携
モデルの高速ロードが可能になったことで、**HPA (Horizontal Pod Autoscaler)**によるスケールアウトも実用的な時間内で行えるようになりました。推論遅延の傾向をモニタリングし、トラフィック増加に先立って迅速にPodをスケールアウトできるよう、HPAの設定(CPU/GPU使用率、カスタムメトリクスなど)を最適化しました。
📝 まとめと今後の展望
高速化の成果
| ステップ | 改善前 | 改善後 | 削減時間 |
|---|---|---|---|
| 1. イメージDL | 約20分 | 約3秒 | 約20分 |
| 2. モデル読み込み | 約10分 | 約3分 | 約7分 |
| 合計 | 約30分 | 約3分3秒 | 約27分 |
今回の施策により、初期ロード時間を約40分からわずか3分強まで短縮することができました!これにより、Nodeの再起動やHPAによるスケールアウトが発生しても、ユーザーへの影響を最小限に抑えることが可能となりました。
最終的な構成のイメージ
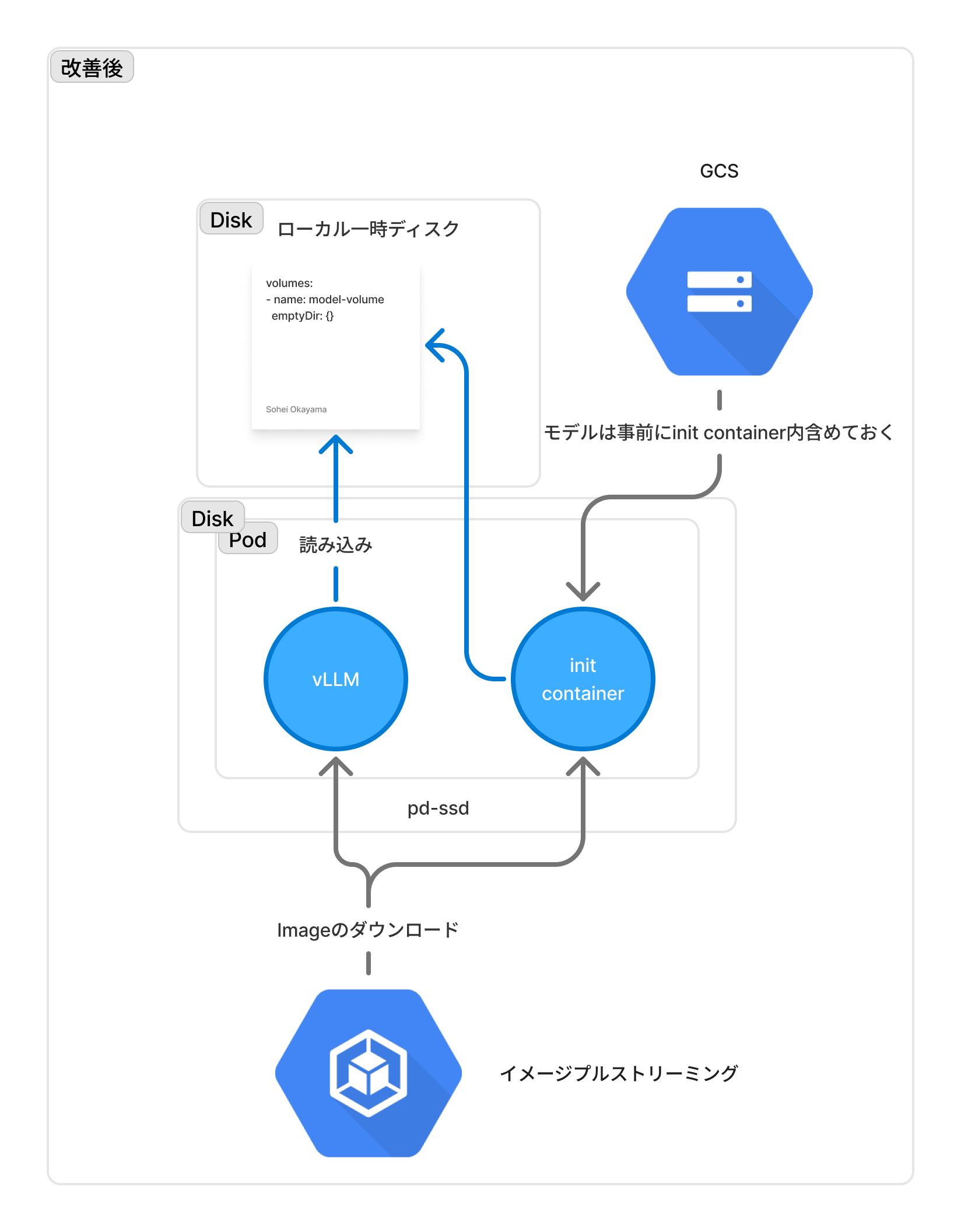
図にすると、Image StreamingやローカルSSDの利用といった要素が加わり、少し複雑な構成になりましたが、GKEやIstioのアップデートといった2〜3ヶ月おきに発生するNodeの再起動にも耐えうる、堅牢で高速なLLM推論インフラを構築することができました。
今後の展望
今回は、イメージプルストリーミングといったGCPが提供している強力な機能を活用して高速化を実現しましたが、弊社はオンプレミスのGPU k8sノードも保有しています。今後は、オンプレミス環境においても同様の高速化、特にディスクI/Oやイメージ配布の最適化を施せるよう、技術検証を進めていきたいと考えています。
※この記事を書き終え、Advent Calendarへの投稿を待っている間にGCSからのModel DLを約5倍高速化可能なrunai_streamerという機能が発表されました。これでvLLMを利用してるユーザはお手軽にロードの高速化ができるようになったようです。素晴らしいですね!
- 有効化オプション
vllm serve gs://your-gcs-bucket/path/to/your/model
--load-format=runai_streamer```