1. はじめに
2026年2月24日にQwen3.5のミドルサイズのシリーズとして、
- Qwen3.5-122B-A10B
- Qwen3.5-35B-A3B
- Qwen3.5-27B
が公開されました(公式ページ)。
2026年2月16日に公開されたQwen3.5-397B-A17Bと比較するとコンシューマー向けのGPUでも動作させやすいサイズ帯だと思います。
今回の記事では、
Qwen3.5-27Bをllama.cppで動作させ、Claude Codeのバックエンドとして使用してみたという内容の記事
となります。
コードは、下記です。
2. Qwen3.5について
Qwen3.5は、Alibaba Cloudが開発したQwen3の後続モデルとなります。
特徴としては、
- ミドルサイズのシリーズは、サイズ感と比較して性能が高い
公式ページのベンチマークやその他のモデルとの比較ページ からわかるように、GPT-OSS-120BやQwen3-235B-A22B, DeepSeekV3.2(685B)などと比較しても27B級のサイズにもかかわらずほとんど差がないような性能です。
- 全てのサイズで画像を入力として採用している
27B ~ 397B全てのサイズで画像入力をサポートしているようです。Qwen3系では画像入力のサポートがなかったので地味にうれしいと感じています
Qwen3 VLはサポートしていますが、デフォルトのQwen3ではサポートしていないという認識です。
3. 動作環境
動作環境は下記です。
- CPU: Intel Core i9-14900KF
- GPU: NVIDIA GeForce RTX 4090
- メモリ: 64 GB
- OS: Windows 11 Pro
4. llama.cppによるインストール
今回は、Dockerを使用してインストールを実施しました。
ルートディレクトリで docker compose upを実施するとサーバーが起動します。
ディレクトリ構成
./
|- llamma_cpp
| |- Dockerfile
| |_ entrypoint.sh # モデルのダウンロードとサーバーの起動
|- .env
|_ compose.yml
compose.yml
services:
llama-server:
build:
context: ./llamma_cpp
dockerfile: Dockerfile
container_name: llama-server
restart: unless-stopped
ports:
- "${LLAMA_ARG_PORT:-8080}:${LLAMA_ARG_PORT:-8080}"
volumes:
# モデルをホスト側にキャッシュ(コンテナ再作成後も再ダウンロード不要)
- ./models:/models
env_file:
- .env
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:${LLAMA_ARG_PORT:-8080}/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 120s
Dockerfile
FROM ghcr.io/ggml-org/llama.cpp:server-cuda
# Python + huggingface-hub をインストール(モデルダウンロード用)
RUN apt-get update && apt-get install -y --no-install-recommends \
python3 \
python3-pip \
curl \
&& pip3 install --no-cache-dir huggingface-hub \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# モデル保存先ディレクトリ
RUN mkdir -p /models
# エントリーポイントスクリプトをコピー
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]
entrypoint.sh
#!/bin/bash
set -e
MODEL_PATH="/models/${MODEL_FILE}"
MMPROJ_PATH="/models/${MMPROJ_FILE}"
echo "======================================"
echo " llama.cpp server - starting up"
echo "======================================"
# --- 必須パラメータチェック ---
if [ -z "${HF_REPO}" ] || [ -z "${MODEL_FILE}" ]; then
echo "[ERROR] HF_REPO と MODEL_FILE を .env に設定してください"
exit 1
fi
# --- ダウンロード共通関数 ---
download_file() {
local repo="$1"
local file="$2"
if [ -n "${HF_TOKEN}" ]; then
hf download "${repo}" "${file}" \
--local-dir /models \
--token "${HF_TOKEN}"
else
hf download "${repo}" "${file}" \
--local-dir /models
fi
}
# --- メインモデルのダウンロード ---
if [ -f "${MODEL_PATH}" ]; then
echo "[INFO] モデルは既にキャッシュ済みです: ${MODEL_PATH}"
else
echo "[INFO] メインモデルをダウンロードします..."
echo " HF_REPO : ${HF_REPO}"
echo " MODEL_FILE : ${MODEL_FILE}"
download_file "${HF_REPO}" "${MODEL_FILE}"
echo "[INFO] ダウンロード完了: ${MODEL_PATH}"
fi
# --- mmproj(VLM用マルチモーダルプロジェクター)のダウンロード ---
if [ -n "${MMPROJ_FILE}" ]; then
if [ -f "${MMPROJ_PATH}" ]; then
echo "[INFO] mmproj は既にキャッシュ済みです: ${MMPROJ_PATH}"
else
echo "[INFO] mmproj をダウンロードします..."
echo " MMPROJ_FILE: ${MMPROJ_FILE}"
# mmproj は同じリポジトリからダウンロード
download_file "${HF_REPO}" "${MMPROJ_FILE}"
echo "[INFO] ダウンロード完了: ${MMPROJ_PATH}"
fi
fi
echo "======================================"
echo " llama-server を起動します"
echo " モデル : ${MODEL_PATH}"
echo " ホスト : 0.0.0.0:${LLAMA_ARG_PORT:-8080}"
echo " GPU層数 : ${LLAMA_ARG_N_GPU_LAYERS:-999}"
if [ -n "${MMPROJ_FILE}" ]; then
echo " mmproj : ${MMPROJ_PATH}"
fi
echo "======================================"
# --- サーバー起動(mmproj が指定されていれば --mmproj オプションを追加)---
MMPROJ_OPT=""
if [ -n "${MMPROJ_FILE}" ]; then
MMPROJ_OPT="--mmproj ${MMPROJ_PATH}"
fi
exec /app/llama-server \
--model "${MODEL_PATH}" \
--host 0.0.0.0 \
${MMPROJ_OPT} \
--port "${LLAMA_ARG_PORT:-8080}" \
--ctx-size "${LLAMA_ARG_CTX_SIZE:-4096}" \
--temp ${TEMPERATURE} \
--top-p ${TOP_P} \
--top-k ${TOP_K} \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}" \
--n-gpu-layers "${LLAMA_ARG_N_GPU_LAYERS:-999}" \
--parallel "${LLAMA_ARG_PARALLEL:-4}" \
--jinja
なお、MMPROJ_OPTについてはVLM用の画像エンコーダモデルです。Claude Code実験前に画像を与えるとどのような結果になるかを実験もしていた際のものなので今回は不要です。
5. Claude Codeとの連携方法
こちらを参考にしました。
やることしては、基本的に環境変数を設定するだけです。
Windows(PowerShell)
$env:ANTHROPIC_BASE_URL="http://localhost:8080"
$env:ANTHROPIC_API_KEY="sk-no-key-required"
Windows(CMD)
set ANTHROPIC_BASE_URL=http://localhost:8080
set ANTHROPIC_API_KEY=sk-no-key-required
Mac/Linux
export ANTHROPIC_BASE_URL="http://localhost:8080"
export ANTHROPIC_API_KEY="sk-no-key-required"
上記を実施したあとに、下記を入力してClaude Codeを起動させます。
claude --model unsloth/Qwen3.5-27B
6. 使用例
ローカルLLMの用途として、機密性の高いコードを読ませてドキュメントを作成するなどが挙げられると思います。そのため、今回は作成したコードのREADME.mdを作成してもらうことにしました。
6.1 ディレクトリ配下のファイル類を読み込んでもらう
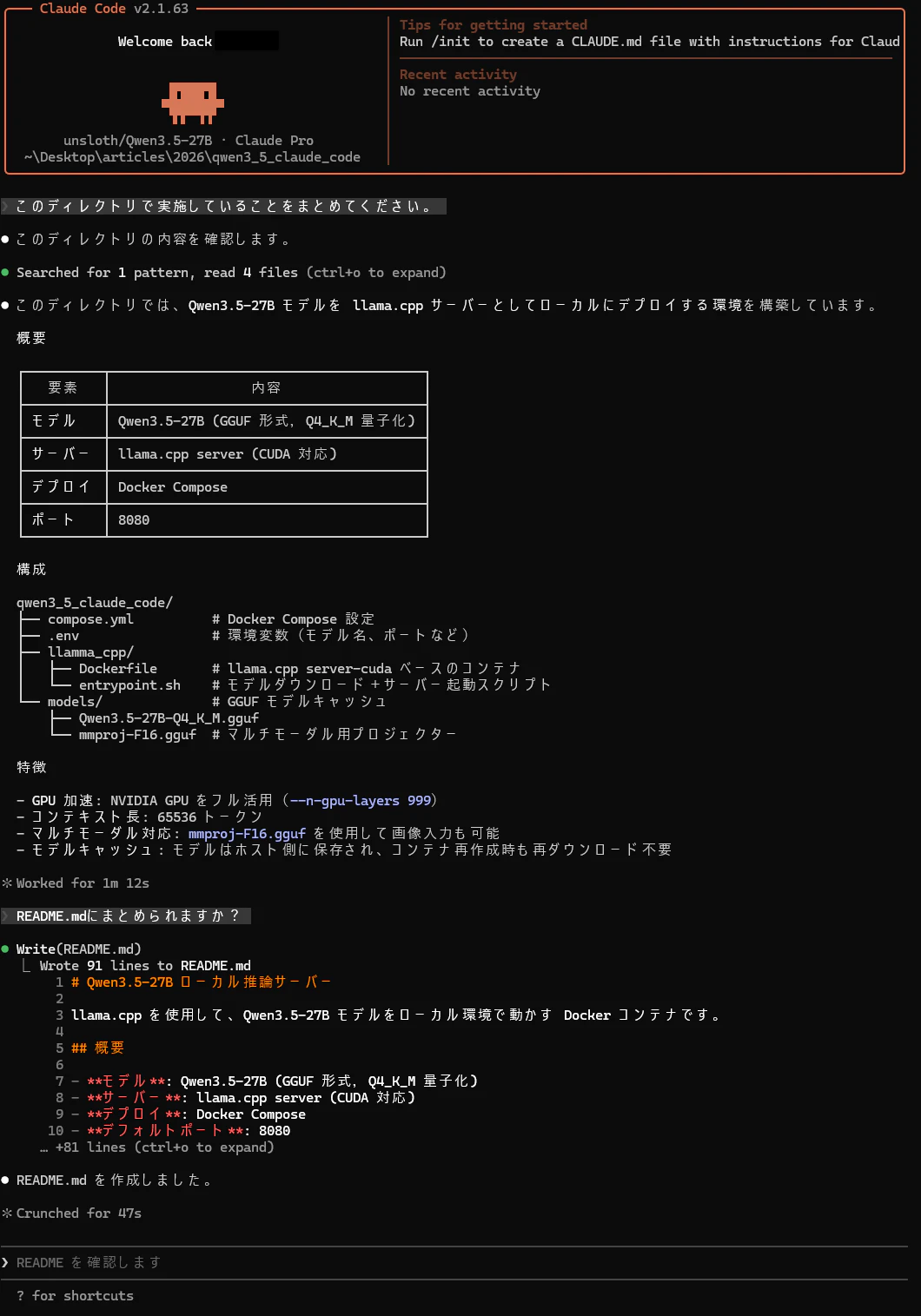
起動画面を下図に示します。
画像から
- 使用されているモデルが
unsloth/Qwen3.5-27Bとなっていること - ディレクトリ配下を読み込んで内容をまとめることに成功している
ことが分かります。
6.2 Claude Codeの連携方法をURL経由でREADMEに追加してもらう
ディレクトリ配下で何をしているかをREADME.mdに記載してもらうことに成功したので、今度は公式のWebサイトからClaude Codeとの連携方法を調べて追加してもらいました。
概ね機能していることが分かります。
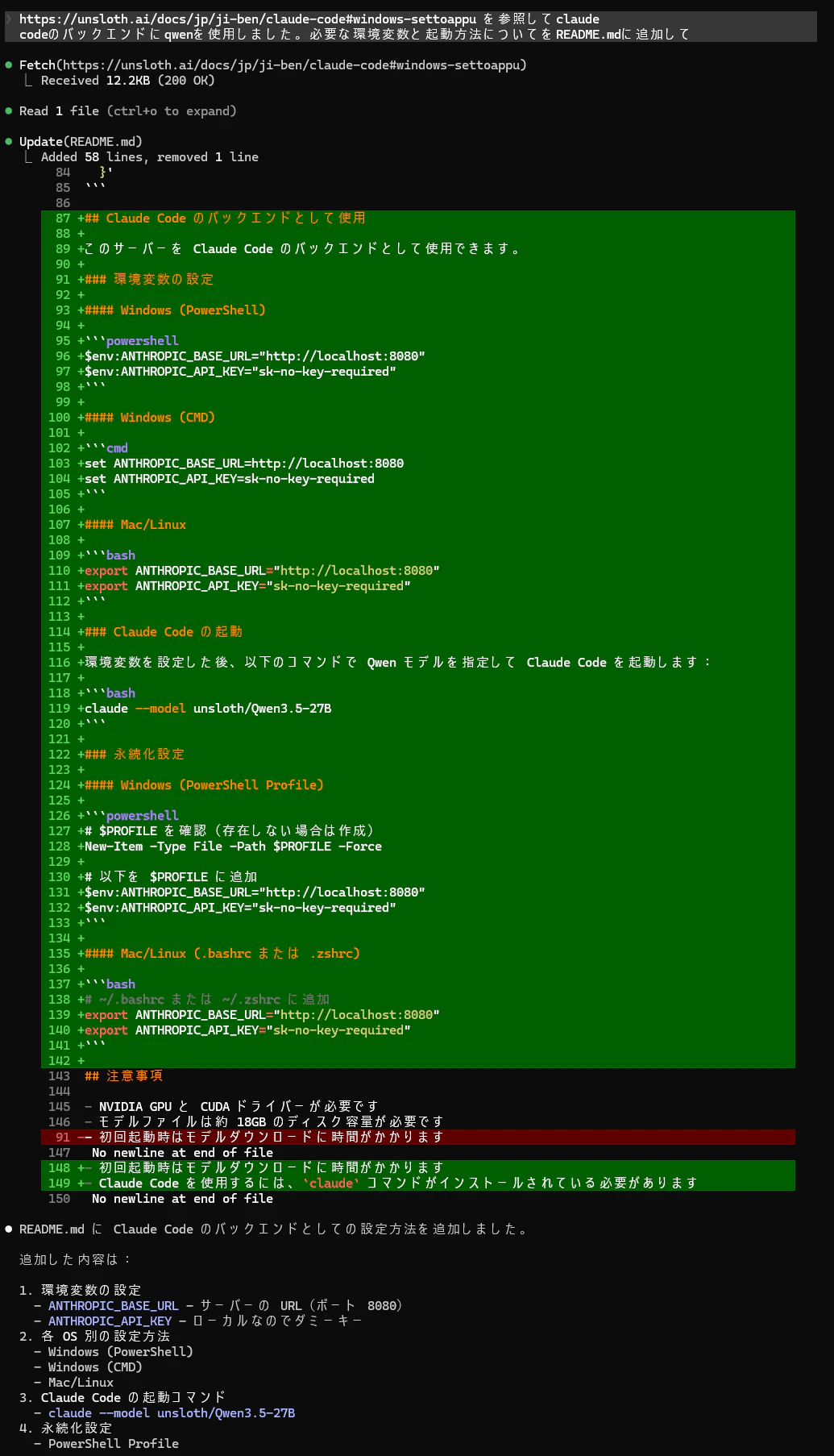
上記のことから分かることをまとめたいと思います。
- ツールの呼び出しが比較的出来ている
今回は、ファイルの読み書き, Web検索といったClaude Codeでよく使われるツールの呼び出しをしてもらいました。両方とも上手く実施できていましたのでツールの呼び出しは問題ないようです。恐らくMCPなどについても実施出来ると思います(試してみたいですね)。
- 複数ファイルにまたがった情報のまとめも可能
比較的小規模ではありますが、複数ファイルにまたがった情報をまとめることが出来ていると思います。機密ファイルなどの扱いなども安心して任せることが出来そうな気もしました。
余談ですが、今回のREADME.mdの作成は全てバックエンドがQwen3.5-27BのClaude Codeにやってもらっています。
7. 感想
今回は、Qwen3.5-27BをClaude Codeのバックエンドとして使用するという試みを実施してみました。
今回の実施内容から、下記のようなことを感じました。
-
想像以上に使えそう:27 Bという比較的小型モデルなのにも関わらず、「ツール呼び出しのミス」や「よくわからない日本語」などの性能が低めのモデルによくある現象が起きないのですごいなと思いました(Claude Codeのほうが優れている可能性はあると思います)
-
よりマシンスペックがあれば機密情報を扱うプロジェクトでも活用できそう:27 Bで満足感がある使用感でしたので、
Qwen3.5-397B-A17Bを扱えるようなマシンがあれば外部に出すとまずい情報を扱うプロジェクトでも十分に使えそうな感じがしました -
ローカルモデルの進化への期待:今まではローカルモデルは「Claude, Gemini, GPTよりかは見劣りして現実のプロジェクトなどでは使えない」というのが自分の評価でした。今回の実施内容からもう少し希望をもっても良いのではないか?という評価に変わりました
8. 最後に
最後まで読んでくださり、ありがとうございました。
余裕があれば今回の構成を使用してコード生成などもやってみたいと思います。