はじめに
「ChatGPTって実際どうやって動いているんだろう?」「AWSのサービスを組み合わせて何か作ってみたい」そんな興味から、AIチャットアプリをゼロから作ってみました。
作成した動機は主に3つです。
- チャット機能の仕組みを理解したい : 普段何気なく使っているチャットUIが、バックエンドでどう実現されているかを実装を通して学びたかった
- AWS CDKを使ってみたい : インフラをコードで管理するIaC(Infrastructure as Code)の概念を、実際のプロジェクトで体感したかった
- DBの設計を学びたい : NoSQLであるDynamoDBで、チャットアプリのようなデータをどう設計するかを考えたかった
この記事では、完成したアプリの構成と実装のポイントを紹介します。
今回のコードは下記です。
完成したアプリの概要
こんなチャットアプリができました。
- 会話のCRUD処理 : 複数の会話スレッドを作成・切り替え・削除できる
- 会話履歴の保持 : 過去のやりとりを記憶してAIが返答する
- マークダウン表示 : AIの返答をマークダウン形式で表示(コードブロックのシンタックスハイライトも対応)
- ユーザー認証 : Cognitoによるログイン機能
技術スタック
| カテゴリ | 技術 |
|---|---|
| フロントエンド | Next.js (TypeScript) + Tailwind CSS |
| バックエンド | AWS Lambda (Python) |
| AI | Amazon Bedrock (Claude Haiku 4.5) |
| DB | Amazon DynamoDB |
| 認証 | Amazon Cognito |
| API | Amazon API Gateway |
| IaC | AWS CDK (Python) |
すべてサーバーレス構成のため、サーバー管理が不要です。
アーキテクチャ
下記のようなアーキテクチャとなります。
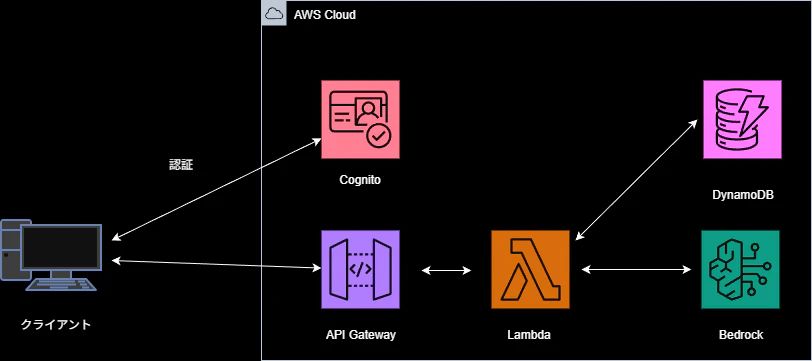
1. AWS CDKでインフラをコード管理する
AWSのリソースは手動でコンソールから作成するのではなく、AWS CDK(Cloud Development Kit) を使いPythonコードで定義しました。
CDKとは
インフラの構成(サーバー・DB・API等)をプログラムコードで記述し、自動でAWSにデプロイできるツールです。コードで管理することで、設定の再現性が高まり、チームでの共有も容易になります。
スタック構成
インフラは4つのスタックに分割しています。
# cdk/app.py
from aws_cdk import App
from stacks.database_stack import DatabaseStack
from stacks.auth_stack import AuthStack
from stacks.lambda_stack import LambdaStack
from stacks.api_stack import ApiStack
app = App()
db_stack = DatabaseStack(app, "DatabaseStack")
auth_stack = AuthStack(app, "AuthStack")
lambda_stack = LambdaStack(app, "LambdaStack",
conversations_table=db_stack.conversations_table,
messages_table=db_stack.messages_table,
)
api_stack = ApiStack(app, "ApiStack",
lambda_function=lambda_stack.lambda_function,
user_pool=auth_stack.user_pool,
)
スタックを分割することで、それぞれの役割が明確になり、変更の影響範囲を限定できます。
デプロイコマンド
cd cdk
cdk deploy --all
たったこれだけで、DynamoDB・Cognito・Lambda・API Gatewayの4つのAWSリソースが一括作成されます。
2. DynamoDBのテーブル設計
チャットアプリのデータをDynamoDBでどう表現するかは、最も頭を使った部分です。
ER図は下記です。
テーブル構成
今回は 会話テーブル と メッセージテーブル の2つに分けました。
ConversationsTable(会話一覧)
| 属性 | 型 | キー | 説明 |
|---|---|---|---|
userId |
String | パーティションキー | Cognitoのユーザーid |
conversationId |
String | ソートキー | UUID |
title |
String | - | メッセージの先頭50文字 |
createdAt |
Number | - | 作成日時(Unixタイムスタンプ) |
updatedAt |
Number | - | 最終更新日時 |
messageCount |
Number | - | メッセージ数 |
MessagesTable(メッセージ一覧)
| 属性 | 型 | キー | 説明 |
|---|---|---|---|
conversationId |
String | パーティションキー | 会話id |
timestamp |
Number | ソートキー | 送信日時(Unixタイムスタンプ) |
messageId |
String | - | UUID |
role |
String | - |
user または assistant
|
content |
String | - | メッセージ本文 |
GSI(グローバルセカンダリインデックス)について
サイドバーには「最近更新された会話が上に来る」ソート順で会話一覧を表示したいです。
DynamoDBはデフォルトではパーティションキーでしか検索できないため、GSI(グローバルセカンダリインデックス) を使います。
# cdk/stacks/database_stack.py
from aws_cdk import aws_dynamodb as dynamodb, RemovalPolicy
conversations_table = dynamodb.Table(
self, "ConversationsTable",
partition_key=dynamodb.Attribute(
name="userId",
type=dynamodb.AttributeType.STRING
),
sort_key=dynamodb.Attribute(
name="conversationId",
type=dynamodb.AttributeType.STRING
),
billing_mode=dynamodb.BillingMode.PAY_PER_REQUEST,
removal_policy=RemovalPolicy.DESTROY,
)
# 「userId + updatedAt」でクエリできるGSIを追加
conversations_table.add_global_secondary_index(
index_name="userId-updatedAt-index",
partition_key=dynamodb.Attribute(
name="userId",
type=dynamodb.AttributeType.STRING
),
sort_key=dynamodb.Attribute(
name="updatedAt",
type=dynamodb.AttributeType.NUMBER
),
projection_type=dynamodb.ProjectionType.ALL,
)
このGSIを使うことで、userIdで絞り込みながらupdatedAtの降順(最新順)で会話一覧を取得できます。
# 会話一覧を最新順で取得
response = conversations_table.query(
IndexName="userId-updatedAt-index",
KeyConditionExpression=Key("userId").eq(user_id),
ScanIndexForward=False, # 降順(最新が先頭)
Limit=20,
)
3. Cognito認証
Cognitoとは
AWS提供のユーザー認証サービスです。ユーザー登録・ログイン・トークン管理などの機能が揃っており、自前で認証サーバーを実装する必要がありません。
ユーザープールの設定
# cdk/stacks/auth_stack.py
from aws_cdk import aws_cognito as cognito
user_pool = cognito.UserPool(
self, "ChatUserPool",
user_pool_name="bedrock-chat-users",
self_sign_up_enabled=True,
sign_in_aliases=cognito.SignInAliases(username=True),
password_policy=cognito.PasswordPolicy(
min_length=8,
require_uppercase=True,
require_lowercase=True,
require_digits=True,
require_symbols=False,
),
)
user_pool_client = user_pool.add_client(
"ChatAppClient",
auth_flows=cognito.AuthFlow(
user_password=True, # ユーザー名+パスワード認証
user_srp=True, # SRP(安全なリモートパスワード)認証
),
access_token_validity=Duration.hours(1),
id_token_validity=Duration.hours(1),
refresh_token_validity=Duration.days(30),
)
認証フロー
- ユーザーがNext.jsのログイン画面でユーザー名・パスワードを入力
-
amazon-cognito-identity-jsライブラリがCognitoへ認証リクエスト送信 - 認証成功 → IdToken を取得
- APIリクエスト時に
Authorization: Bearer {IdToken}ヘッダーを付与 - API GatewayがCognito Authorizerでトークンを検証
- 検証OK → Lambdaへリクエスト転送
// frontend/src/lib/cognito.ts(抜粋)
export const login = (username: string, password: string): Promise<string> => {
return new Promise((resolve, reject) => {
const cognitoUser = new CognitoUser({ Username: username, Pool: getUserPool() });
const authDetails = new AuthenticationDetails({ Username: username, Password: password });
cognitoUser.authenticateUser(authDetails, {
onSuccess: (result) => {
resolve(result.getIdToken().getJwtToken());
},
onFailure: (err) => {
// エラーメッセージを統一(ユーザー列挙攻撃対策)
reject(new Error("ユーザー名またはパスワードが正しくありません"));
},
});
});
};
ポイントは エラーメッセージを統一している点 です。「ユーザー名が存在しない」「パスワードが違う」を区別せず同じメッセージを返すことで、存在するユーザー名を特定する攻撃(ユーザー列挙攻撃)を防ぎます。
4. Bedrock × Lambdaでチャット機能を実装
Amazon Bedrockとは
AWSが提供するAI基盤モデルの利用サービスです。Anthropic・Amazon・Metaなどが開発したLLMをAPI経由で呼び出せます。今回は Claude Haiku 4.5 を使用しています。
Lambdaのバックエンド構成
lambda/
├── handler.py # エントリーポイント・ルーティング
└── services/
├── bedrock_service.py # Bedrock呼び出し
└── dynamodb_service.py # DynamoDB操作
Bedrockへのメッセージ送信
# lambda/services/bedrock_service.py
import boto3, os
class BedrockService:
def __init__(self):
self.client = boto3.client("bedrock-runtime", region_name="us-east-1")
self.model_id = os.environ.get("BEDROCK_MODEL_ID")
def generate_response_with_history(self, messages: list) -> str:
"""会話履歴を含めてBedrockに問い合わせる"""
# DynamoDB形式 → Bedrock Converse API形式に変換
bedrock_messages = [
{
"role": msg["role"], # "user" or "assistant"
"content": [{"text": msg["content"]}],
}
for msg in messages
]
response = self.client.converse(
modelId=self.model_id,
messages=bedrock_messages,
inferenceConfig={
"maxTokens": 2048,
"temperature": 1.0,
},
)
return response["output"]["message"]["content"][0]["text"]
Bedrockの Converse API を使うことで、会話履歴をそのまま渡してマルチターン会話を実現できます。
メッセージ送受信の全体フロー
# lambda/handler.py(handle_chat関数・抜粋)
def handle_chat(user_id, body):
message = body["message"]
conversation_id = body.get("conversationId") # 新規の場合はNone
# 1. 新規会話なら作成
if not conversation_id:
conversation_id = str(uuid4())
dynamodb_service.create_conversation(
user_id=user_id,
conversation_id=conversation_id,
title=message[:50], # メッセージ先頭50文字をタイトルに
)
# 2. ユーザーメッセージを保存
dynamodb_service.save_message(conversation_id, "user", message)
# 3. 会話履歴をすべて取得(古い順)
history = dynamodb_service.get_conversation_history(conversation_id)
# 4. Bedrockで応答生成
ai_response = bedrock_service.generate_response_with_history(history)
# 5. AI応答を保存
dynamodb_service.save_message(conversation_id, "assistant", ai_response)
# 6. 会話メタデータ更新(updatedAt, messageCount)
dynamodb_service.update_conversation_metadata(conversation_id)
return {
"conversationId": conversation_id,
"response": ai_response,
}
会話履歴を 古い順にDynamoDBから取得してBedrockに渡す ことで、「前のやりとりを覚えているAI」を実現しています。
APIエンドポイント一覧
| メソッド | パス | 説明 |
|---|---|---|
| POST | /chat |
メッセージ送信・AI応答取得 |
| GET | /conversations |
会話一覧取得 |
| GET | /conversations/{id} |
特定会話のメッセージ取得 |
| DELETE | /conversations/{id} |
会話削除 |
スロットリングの設定
API Gatewayにはスロットリング(レート制限)を設定しています。
# cdk/stacks/api_stack.py(抜粋)
deployment_stage = api.add_stage(
"prod",
throttling_rate_limit=25, # 全体: 25 req/秒
throttling_burst_limit=50,
)
# /chat は特に厳しく制限(Bedrockのコスト対策)
chat_method = chat_resource.add_method("POST", ...)
chat_method.add_method_throttling(
throttling_rate_limit=2, # /chat: 2 req/秒
throttling_burst_limit=5,
)
Bedrockの呼び出しはコストが発生するため、/chatエンドポイントは特に厳しく制限しています。
5. フロントエンド(Next.js)
フロントエンドはNext.js(App Router)とTailwind CSSで構築しています。コンポーネント構成は以下の通りです。
src/
├── app/
│ ├── page.tsx # メインチャット画面
│ └── login/
│ └── page.tsx # ログイン画面
├── components/
│ ├── Sidebar.tsx # 会話一覧サイドバー
│ ├── ChatArea.tsx # メッセージ表示エリア
│ ├── MessageBubble.tsx # 個別メッセージ(マークダウン対応)
│ ├── MessageInput.tsx # 入力フォーム
│ └── ConversationItem.tsx # サイドバーの会話アイテム
├── contexts/
│ └── AuthContext.tsx # 認証状態管理
└── lib/
├── api.ts # バックエンドAPI呼び出し
└── cognito.ts # Cognito操作
マークダウンレンダリング
AIの返答にはコードや表が含まれることが多いため、react-markdownとreact-syntax-highlighterを使ってマークダウンを整形表示しています。
実装を通じて学んだこと
DynamoDBはアクセスパターンから設計する
RDBと異なり、DynamoDBは**「どう検索するか(アクセスパターン)」を先に決めてからテーブルを設計する** 必要があります。
今回は以下2つのアクセスパターンを満たす設計にしました。
- あるユーザーの会話一覧を「最新順」で取得する → GSIにより解決
- ある会話のメッセージを「送信順」で取得する → ソートキーに
timestampを設定
CDKを使用すると楽
CDKを使用すると慣れた言語で実装することが出来るのでツール固有の文法などに悩まされずに済むので開発体験がよかったです。
会話履歴の扱いが会話の肝
Bedrockに**「ユーザーとアシスタントが交互に話した履歴」をすべて渡す**ことで、文脈を踏まえた返答が得られます。逆に言えば、履歴を渡さなければAIは毎回初対面扱いになります。
おわりに
AWSのサービスを組み合わせることで、本格的なAIチャットアプリをサーバーレスで構築できました。
特にCDKは「インフラ構成をコードで残せる」点が非常に便利で、cdk deploy --all 一発でリソースが再現できるのは快感です。
次は Knowledge Basesを使用したRAGあたりの実装にも挑戦してみたいと思っています。
この記事が同じようにAWSやAI開発に挑戦したい方の参考になれば幸いです。