0. 概要
↑の記事では、RNNによって作成した機械学習モデルをTransformerのEncoderによって作り直します。
作成する機械学習モデルは、ポケモンの名前からタイプを識別するものです。
"p" "i" "k" "a" "c" "h" "u" → 機械学習モデル → electric
モデルには1文字ずつポケモンの名前を与えます。最後の u を入力したあとの出力がポケモンタイプを表すことになります。
1. 実行環境
Google Colaboratoryを使用します。
RNN版のmodel変数をこれから示すモデルに入れ替えて、train_x変数をreshape(train_x.shape[0],train_x.shape[1])で変形すれば動作します。
この記事では、RNN版からの変更点だけを記述いたします。
モデルはまず TokenAndPositionEmbedding で入力データに何文字目かという位置情報が付加されて次元圧縮されたベクトルが作成されます。
次に TransformerBlock によって処理が行われます。
そして最後に GlobalAveragePooling1D によって入力シーケンスの次元で平均化されてから全結合層を通ってポケモンタイプの総数分の次元であるベクトルが出力されます。
2. TokenAndPositionEmbedding
Text classification with transformerを元に作成しています。このレイヤーもサンプルと同じです。
class TokenAndPositionEmbedding(layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super().__init__()
self.token_emb = layers.Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, x):
maxlen = tf.shape(x)[-1]
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
x = self.token_emb(x)
return x + positions
このセルの出力はとくにありません。
3. TransformerBlock
kerasのcode examplesの1つであるText classification with transformerを元に作成しています。このレイヤーはサンプルと同じです。
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super().__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential(
[layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
このセルの出力はとくにありません。
4. モデルの生成
# ユニークな文字数
vocab_size = input_ch_dim+1
# ポケモン名の最大文字数
maxlen = input_dim_max
embed_dim = 32 # Embedding size for each token
num_heads = 2 # Number of attention heads
ff_dim = 32 # Hidden layer size in feed forward network inside transformer
inputs = layers.Input(shape=(maxlen,))
embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
x = embedding_layer(inputs)
print(f"embedding_layer:{x.shape}")
transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
x = transformer_block(x)
x = layers.GlobalAveragePooling1D()(x)
x = layers.Dropout(0.1)(x)
x = layers.Dense(20, activation="relu")(x)
x = layers.Dropout(0.1)(x)
outputs = layers.Dense(output_dim, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="adam", loss="categorical_crossentropy")
model.summary()
出力例
embedding_layer:(None, 25, 32)
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 25)] 0token_and_position_embeddin (None, 25, 32) 2016
g (TokenAndPositionEmbeddin
g)transformer_block (Transfor (None, 25, 32) 10656
merBlock)global_average_pooling1d (G (None, 32) 0
lobalAveragePooling1D)dropout_2 (Dropout) (None, 32) 0
dense_2 (Dense) (None, 20) 660
dropout_3 (Dropout) (None, 20) 0
dense_3 (Dense) (None, 18) 378
=================================================================
Total params: 13,710
Trainable params: 13,710
Non-trainable params: 0
_________________________________________________________________
Text classification with transformerのvocab_size, maxlenの変数をポケモンのデータに合わせます。また出力層はサンプルでは2要素となっているところを、ポケモンタイプの総数のoutput_dim(18)に変えます。出力が整数表現からone-hotに変わったので損失がsparse_categorical_crossentropyからcategorical_crossentropyに変えています。
5. モデルの学習
# (None,25,1)から(None,25)に変更します。
train_x1 = train_x.reshape(train_x.shape[0],train_x.shape[1])
history = model.fit(train_x1, train_y, batch_size=32, epochs=5_000,)
出力例
(... 省略 ...)
Epoch 5000/5000
25/25 [==============================] - 1s 21ms/step - loss: 0.1108
学習時間は30分ぐらいはかかると思います。
6. 損失の表示
表示するためのプログラムは、RNN版と同じです。
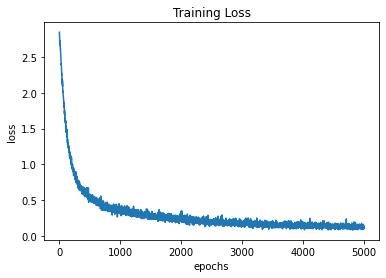
7. 結果の表示

RNN版と同じように結果を表示します。
ちなみにRNN版の結果は次のようでした。

8. 評価
結果の「後ろがかける」はロバストになっているようにも見えます。しかしこのモデルは文字がかけても分類できるというロバスト性を目的としているのではないので、あくまでも感想です。
学習時間はRNN版より早くなりました。