0. 概要
RNNの理解のための記事です。その題材として、ポケモンの名前からタイプを識別するRNNベースの機械学習モデルを作成します。
"p" "i" "k" "a" "c" "h" "u" → 機械学習モデル → electric
モデルには1文字ずつポケモンの名前を与えます。最後の u を入力したあとの出力がポケモンタイプを表すことになります。
1. 機械学習モデルへの入出力
1.1. pikachuの入力例
完全な文字列を入力する。
"p" "i" "k" "a" "c" "h" "u"
途中までしか入力しない。
"p" "i" "k" "a" "c" "h" "u"
間を抜いて入力する。
"p" "i" "k" "a" "c" "h" "u"
最初をとばして入力する。
"p" "i" "k" "a" "c" "h" "u"
2つの名前を合体させる
pikachu + mewtwo
"p" "i" "k" "a" "t" "w" "o"
RNNは時系列データやを取り扱うことができるため、ポケモンの名前を文字の流れとしてみたときに上のようなバリエーションの入力をモデルに与えることができます。このそれぞれのタイプの識別結果を見ていきます。
1.2. 出力例
electric:0.76, fire:0.11, water:0.062, ....
ポケモンのタイプが推定されて確率付きで、でんき76%、ほのお11%、みず6.2%のように出力されます。
2. ポケモンデータセット
ポケモンデータは、上記のサイトのものを利用させてもらっています。英語バージョンしかないのでこの記事においてもポケモン名やポケモンタイプの表記はすべて英語となっています。
ちなみにポケモンの英語名と日本語名の対応は ↑ のサイトで記述されています。
3. RNN (Recurrent Neural Network)
3.1. RNNとは?時系列データとは?
RNNはモデルに何度も入力値を与えて出力を得る方法の機械学習モデルです。例えば画像認識などでよく利用される畳み込みニューラルネットワークは1つの入力に対して1つの出力をして、次に2つ目の入力を与えたときに1つ目の入力や出力のことは忘れて、2つ目の出力を行います。1枚の画像に何が映っているかなどの画像認識ではそれでよいのですが、(1)「私の好きな食べ物は〇〇です」(2)「あなたは?」という文章で(2)の「あなたは?」に答えるためには(1)の言葉を理解している必要があります。このように前のデータの質問内容やモデルが出力した回答を覚えつつ、入力に対する出力をするような機械学習モデルをRNNと呼びます。(1)(2)のようにデータが続いていくものを時系列データやシーケンスデータと呼びます。
\def\textsmall#1{%
{\rm\scriptsize #1}
}
\textsmall{"electric" = CNN("pikachu")} \\
\textsmall{"electric" = RNN(RNN(RNN(RNN(RNN(RNN(RNN(h,"p"),"i"),"k"),"a"),"c"),"h"),"u")}
畳み込みニューラルネットワークのように1回の入力で1つの出力を得るのは↑のCNNのように最終的には1つの関数のようにみえます。一方RNNは、再帰関数です。ピカチュウの最初の文字のpと一緒に与えられている h という引数は、RNNが保持する内部状態の初期値です。このRNNは内部状態を出力します。pの内部状態が次の文字のiの引数となります。
3.2. ポケモンの名前が時系列データとは?
pikachu → "p" "i" "k" "a" "c" "h" "u"
名前を1文字ごとに分割して時系列データとしてこの記事では扱います。1文字ごとに分割せずに"pikachu"という1つの単語を1つの数値に変換することとの違いは、ポケモンの名前を途中まで打って判定や2つのポケモン名を足して架空のポケモン名でタイプを判定するということができることです。
もちろん架空のポケモン名の場合は、何が正解かは分からないのであくまでもこういうことができる、という例です。
3.3. RNNの計算例
RNNには内部状態と呼ばれる数値があります。この内部状態を入力値と1つ前の入力データで計算された出力とで計算して求めます。

この例は、入力は1度に2つのデータ0と1がモデルに入り、内部状態と出力値は5個の数値でできているベクトルです。
まず最初に入力値から出力を計算するときには、内部状態は0で初期化されています。上の図の左上のoutputs[0,0,0,0,0]です。内部状態を5個のベクトルと決めたので0が5個あります。
このoutputsは前回の出力として解釈され、左上のrecurrent_kernelという行列をかけることによって変形します。
同時に入力値も図の中央下のkernelという重みによって変形し、biasという重みが追加されます。
そして変形outputsと、変形inputsが足し合わさって内部状態を作ります。図ではinputs... * outputs...と書かれている5つの数字のところです。
最後に内部状態はtanhという活性化関数を通って出力されます。
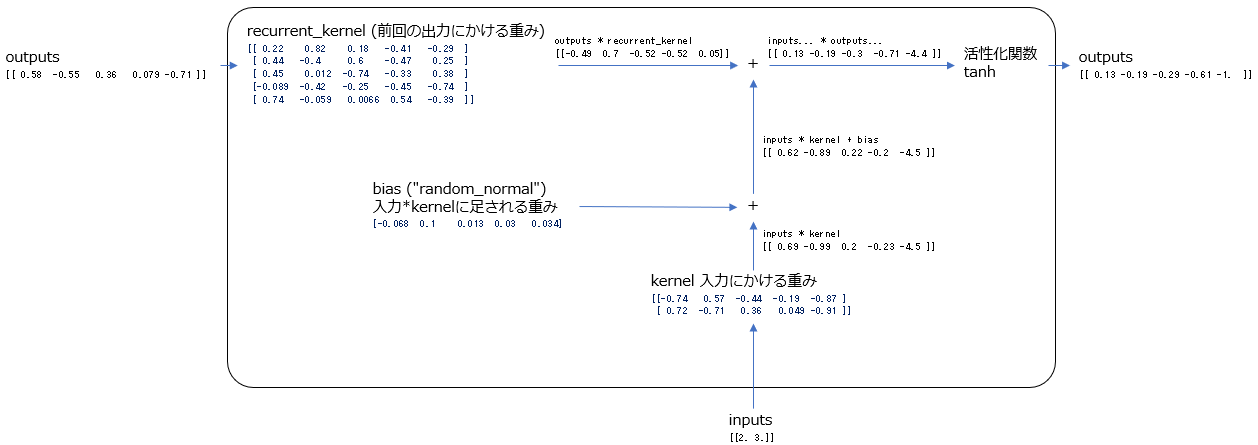
次に2つ目の入力として2,3がモデルに入ると、その入力はkernelによって変形されbiasが足され、またrecurrent_kernelで変形された前回の出力と足し合わさって内部状態が作られます。そして活性化関数を通って出力値が決定されます。
3つ目の入力がモデルに入ると、2つ目の入力と同じように計算されます。そして入力が無くなるまでこの計算を繰り返し、最終的にでてきた出力値を見ていろいろな判定をしたりします。
3.4. RNNは何を計算しているのか?
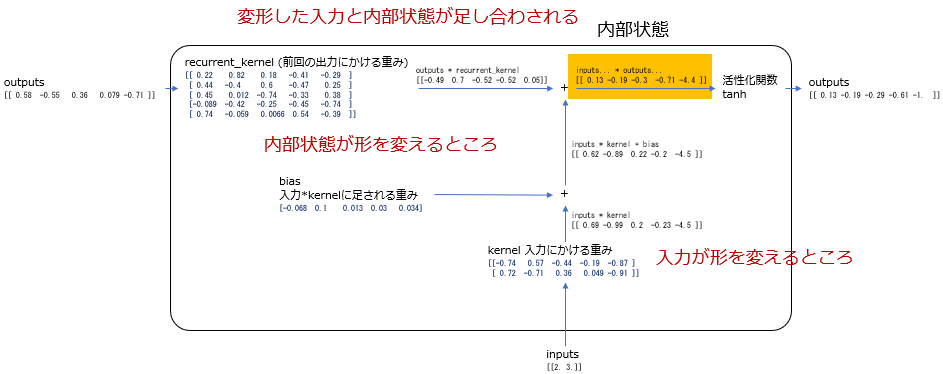
入力と前回の出力をそれぞれの重みで変形して、足し合わさって、内部状態を計算します。ここでいう変形とは、ポケモンタイプの判別にとって重要なところの数値が大きくなり、そうではないところは小さくなるイメージです。
内部状態は、モデルの学習がよく進めば、文脈のようなものを表すようになります。先の「私の好きな食べ物は〇〇です」「あなたは?」という質問の例では、最初にモデルに「私の好きな食べ物は〇〇です」が入るとして、ここで「好きな食べ物に関する話題」という文脈がモデルによって理解され、その理解したという文脈に「あなたは?」という質問がくることによって好きな食べ物を回答すればよいとなるわけです。
ポケモンタイプの場合、例えば1回目、2回目の入力に "p" "i" とくるとすると、内部状態はpikachu(ピカチュウ)のタイプである「でんき」やpiplup(ポッチャマ)のタイプである「みず」を想定しているイメージです。そしてそのときに3文字目である "k" が入力されると「でんき」と判定するという感じです。同じ "k" でも1文字目にだったらkakuna(コクーン)のタイプである「さなぎ」が出力候補に挙がるとかです。
ただ実際には、piで始まるポケモン名は他にもありますし、また他の言葉で始まるポケモン名と一緒に学習するのでごちゃまぜになって上手くいかないこともあります。
3.5. RNNの学習
"p" "i" "k" "a" "c" "h" "u" → 機械学習モデル → psychic (間違いです)
損失 = f( electric(正解) - psychic(出力) )
入力を与えてから最後に得られる出力と、正解データとを比較してその差からRNNの各重みの値を更新します。この差のことを損失と呼びます。損失を計算する関数fには様々な計算方法が提案されています。また重みとは、計算例で示した図の青い数値のことです。計算例では2回分の入力を計算しましたが、重みが2回分あるわけではありません。1回分の同じ数値の重みで1つ目も2つ目の入力や内部状態も計算されます。
損失から重みを計算する方法は、イメージだけをここで述べると、重みの数値を少しだけプラスしたりマイナスして、どちらが損失が減るかを求めます。そして減る方に重みを変更するということをします。実際には少しだけプラスマイナスする部分は行わず微分を用いて同じことを実現しています。
4. 実行環境の準備
Google Colaboratoryを使用します。
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from functools import reduce
import random
import math
実行したときの出力は特にありません。
5. ポケモンデータセットの読み込み
from google.colab import files
'''
ポケモンデータセットは、https://www.kaggle.com/datasets/abcsds/pokemon?select=Pokemon.csv から取得する。
'''
# アップロードしたファイル名を取得する。
filename = list(files.upload().keys())[0]
# pandas.DataFrameとして読み込む
df0 = pd.read_csv(filename)
print(df0)
実行すると「ファイル選択」のボタンが表示されるので、予めダウンロードしておいたポケモンデータセットを選択します。
出力例
Pokemon.csv(text/csv) - 44028 bytes, last modified: 2023/2/13 - 100% done
Saving Pokemon.csv to Pokemon (3).csv
# Name Type 1 Type 2 Total HP Attack Defense
0 1 Bulbasaur Grass Poison 318 45 49 49
1 2 Ivysaur Grass Poison 405 60 62 63
2 3 Venusaur Grass Poison 525 80 82 83
3 3 VenusaurMega Venusaur Grass Poison 625 80 100 123
4 4 Charmander Fire NaN 309 39 52 43
.. ... ... ... ... ... .. ... ...
(以下省略)
csvファイルを読み込んでpandas.DataFrame形式で保存しています。
6. 入力、出力の文字列データを作成する。
# ポケモンタイプ一覧を作成する。
types = list(set(df0.loc[:,"Type 1"]))
print(f"types({len(types)}):{types}")
# ポケモンの名前とタイプのセットを作成する。
train_x_str = df0.loc[:,"Name"].to_list()
train_y_str = df0.loc[:,"Type 1"].to_list()
# 名前とタイプはすべて小文字にする。
train_x_str = [*map(lambda x:x.lower(),train_x_str)]
train_y_str = [*map(lambda x:x.lower(),train_y_str)]
# 文字データとしての入出力データを表示する。この後でこの文字データは数値化される。
print(f"train_x strings({len(train_x_str)}):{train_x_str}")
print(f"train_y strings({len(train_y_str)}):{train_y_str}")
出力例
types(18):['Bug', 'Fighting', 'Fairy', 'Steel', 'Psychic'
train_x strings(800):['bulbasaur', 'ivysaur', 'venusaur',
train_y strings(800):['grass', 'grass', 'grass', 'grass',
(右側が省略されています)
train_x_strは、モデルへの入力となるポケモンの名前です。train_y_strはtrain_x_strの名前に対するタイプです。この2つはまだ文字なので、数値化されてからモデルへの入出力となります。
7. ポケモン名、タイプの数値化
from operator import itemgetter
# 文字を数値化するための関数を作成する関数
def get_word_identifier_funcs(inputs,outputs):
# 入力データのポケモン名は1文字ずつ分解する。
input_set = sorted(list(set(list("".join(inputs)))))
# 出力データのポケモンタイプは単語ごとに分解する。
output_set = sorted(list(set(outputs)))
# 入力データの総文字数と、名前の最大長を取得する。
input_dim_max = reduce(lambda a,e:a if a>len(e) else len(e),inputs,0)
input_ch_dim = len(input_set)
print(f"input_dim_max:{input_dim_max}, input_ch_dim:{input_ch_dim}")
# 入力の文字から数値への変換関数
def w2i_inp(ch):
return (input_set.index(ch) if ch in input_set else -1)+1
# 出力の単語から数値への変換関数
def w2i_out(wd):
return output_set.index(wd)
# 出力の数値から単語への変換関数
def i2w_out(id):
return output_set[id]
# numpy用のone-hotベクトルの作成関数
def np_one_hot(x,dim):
return np.eye(dim)[x]
# 入力文字シーケンスの数値化
def encode_inp(wd,padding=True):
return [[w2i_inp(wd[i]) if i < len(wd) else 0] for i in range(input_dim_max if padding else len(wd))]
# 出力単語のベクトル化
def encode_out(wd):
return np_one_hot(w2i_out(wd),len(output_set))
# 出力ベクトルから各ポケモンタイプの所属確率を取得する。ポケモンタイプは所属する確率の高い順にソートされる。
def decode_out(vec):
return sorted([*map(lambda iv:(output_set[iv[0]],iv[1]),enumerate(vec))],key=itemgetter(1),reverse=True)
# 関数を返す。
return (encode_inp,encode_out,decode_out,input_ch_dim,input_dim_max,len(output_set))
# エンコード、デコード関数の作成
encode_inp,encode_out,decode_out,input_ch_dim,input_dim_max,output_dim = get_word_identifier_funcs(train_x_str,train_y_str)
# 入力の文字から数値への変換
train_x = [*map(encode_inp,train_x_str)]
train_x = np.array(train_x)
print(f"train_x.shape:{train_x.shape}")
# 出力の単語から数値への変換
train_y = [*map(encode_out,train_y_str)]
train_y = np.array(train_y)
print(f"train_y.shape{train_y.shape}")
出力例
input_dim_max:25, input_ch_dim:37
train_x.shape:(800, 25, 1)
train_y.shape(800, 18)
入力のポケモン名は1文字ずつに分割し、順番に文字を数字に入れ替えていきます。
"pikachu" = [[24], [17], [19], [9], [11], [16], [29], [0], [0], ...(以下省略)
pが37,iが4と数値化されます。[ ] が付いているのは、この後で記述する機械学習モデルの入力の次元と合わせるためです。
数字0は対応する文字が存在しないという特殊な番号としています。これは、モデルの学習時にポケモン名の長さを統一する必要があるためです。よって最大の文字数のポケモン名に合わせてベクトルを作成し、その文字に満たないポケモン名は残った数値を0で埋めるということを行います。
"electric" → [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
出力は単語を1つの括りとし1文字ごとには分割しません。そしてone-hotと呼ばれる1つの要素だけが1でそれ以外が0のベクトルに変換されます。例えば上の例では electric(でんき) は9番目の要素が対応することになっています。ポケモンデータセットの中のポケモンタイプは全部で18個あるため、ベクトルの要素数は18となっています。
出力をこのようなone-hotで表す理由は、最終的に出力を所属するポケモンタイプの「確率」で求めたいからです。one-hotではない例えば electric → 1, psychic → 2 のように文字と数値の1対1対応にしてしまうと electric 〇%, psychic ×% のような計算をすることはできません。
8. 機械学習モデルの作成
inputs = keras.layers.Input(shape=(None,1))
x = inputs
x = keras.layers.Embedding(input_dim=input_ch_dim+1,output_dim=4,mask_zero=True)(x)
x = keras.layers.Reshape((-1,x.shape[-1]))(x)
x = keras.layers.SimpleRNN(
units=output_dim*3,
return_state=False,
return_sequences=False,
use_bias=True,
)(x)
x = keras.layers.Dense(output_dim,activation="softmax")(x)
# x = keras.layers.Softmax()(x)
model = keras.models.Model(inputs=[inputs],outputs=[x])
# 学習効率はadamのデフォルト(0.001)から下げて0.00005とする。デフォルトの数値だと損失が振動ことがある。
model.compile(optimizer=keras.optimizers.Adam(learning_rate=0.00005),loss="categorical_crossentropy")
model.summary()
出力例
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, None, 1)] 0embedding (Embedding) (None, None, 1, 4) 152
reshape (Reshape) (None, None, 4) 0
simple_rnn (SimpleRNN) (None, 54) 3186
dense (Dense) (None, 18) 990
=================================================================
Total params: 4,328
Trainable params: 4,328
Non-trainable params: 0
_________________________________________________________________
入力は Embedding を使用して一度one-hotにしてから次元圧縮された4次元のベクトルに変換されます。次の Reshape で不要な次元を削除してから SimpleRNN に渡されます。SimpleRNN の主要な引数は次のようです。
- units: 内部状態のベクトルの次元数
今回の例では、ポケモンの総タイプ数の18を3倍した54という数値にしています。この数値は、いろいろと試してみて今回の例で必要最小限と思われる数値となっています。基本的には内部状態のベクトルは多いほうがモデルの表現力が高く、学習が上手くいきます。ただ多すぎると学習時間がかかることや過学習の懸念もあります。
9. モデルの学習
# モデルの学習
history = model.fit(train_x,train_y,epochs=10000)
出力例
Epoch 1/10000
25/25 [==============================] - 2s 10ms/step - loss: 2.8002
(途中省略)
Epoch 10000/10000
25/25 [==============================] - 1s 12ms/step - loss: 0.0026
fit関数にポケモン名称を数値化した train_x, タイプを数値化した train_y, そして学習回数になるepochsを与えています。学習回数を1万回としています。学習時間は2時間ぐらいはかかります。ただ次の損失のグラフを見る限り、5千回ぐらいでモデルの性能は出る気がします。
10. 損失の描画
import matplotlib.pyplot as plt
# 描画領域を作成します。
fig,ax = plt.subplots()
# model.fitの戻り値のうち、lossの部分を描画します。
ax.plot(history.history["loss"])
# タイトル、x軸y軸のラベルを設定します。
ax.set_title("Training Loss")
ax.set_xlabel("epochs")
ax.set_ylabel("loss")
plt.show()
出力例

学習回数の1,001回目から10,000までの損失です。損失なので値が小さいほうが良いです。グラフの4,000回、最初からの回数だと5,000回あたりからグラフが跳ねています。これは学習ごとに損失が増えたり減ったりしているわけです。学習率をデフォルト値より下げて実行していますが、まだそれでも最後の方は損失が振動しています。
このポケモンデータの例での損失は、機械学習モデルの作成のところで示したプログラムの compile 関数の引数の loss="categorical_crossentropy" で計算方法を指定しています。この categorical_crossentropy とは正解データのone-hotベクトルの1の部分に相当する予測したone-hotベクトルの数値が1に近づくほど損失が減るという計算方法です。
11. モデルの実行
# 文字列sをprintするときに色つきの文字に変更する。
def colored(s,color_name):
header = {
"black":"30","red":"31","green":"32","yellow":"33","blue":"34","magenta":"35","cyan":"36","white":"37",
"reset":"0"
}
assert color_name in header.keys()
return f"\033[{header[color_name]}m{s}\033[{header['reset']}m"
# k桁の有効数字を求めます。
def sg(x,k=2):
# print(f"sig({x}),{np.isscalar(x)}")
def _sg(x,k):
# print(f"_sig({x})")
return round(float(x),k-math.floor(math.log10(abs(x)))-1) if x!=0 else 0
if np.isscalar(x):
return _sg(x,k)
else:
return np.apply_along_axis(func1d=lambda xi:[*map(lambda xii:_sg(xii,k),xi)],axis=-1,arr=x)
# 文字がかけているところを抽出する。
def find_lost_ch(s,cmp):
ret = []
si = 0
losting = False
for ci,cs in enumerate(cmp):
# print(f"si:{si},s:{s[si] if si<len(s) else ''},ci:{ci},cs:{cs}")
if si<len(s) and cs == s[si]:
if len(ret)==0 or losting:
ret.append({"type":"not lost","ch":""})
ret[-1]["ch"] += cs
losting = False
si+=1
else:
if len(ret)==0 or losting==False:
ret.append({"type":"lost","ch":""})
ret[-1]["ch"] += cs
losting = True
return ret
# 文字がかけているところを白文字に変換する
def colored_lost_ch(s,cmp):
ar = find_lost_ch(s,cmp)
return "".join(list(reduce(lambda a,e:a+colored(e["ch"],"black" if e["type"]=="not lost" else "white"),ar,"")))
これらは、モデルを実行したときの結果を装飾したりする関数です。RNNの仕組みとは直接的には関係が無いです。
# 正解データ
corrects = ["electric","psychic","rock","normal","fairy"]*4+["unknown"]*4
# データタイプのラベル
name_types = ["完全な名前","後ろがかける","途中がかける","前がかける","名前の合成(正解なし)"]
# 評価する名前一覧
names = ["pikachu","mewtwo","golem","jigglypuff","clefairy", # 完全な名前
"pika", "mewtw", "gole", "jigg", "clefai", # 後ろがかける
"pikchu", "metwo", "goem", "jiggpuff", "cleiry", # 途中がかける
"ikachu", "ewtwo", "olem", "igglypuff", "lefairy", # 前がかける
"pikatwo","mewchu","pikalem","gochu"] # 名前の合成(正解は不明)
# モデルの実行、ポケモンの日本語名 ピカチュウ、ミュウツー、ゴローニャ、プリン、ピッピ
for i,name in enumerate(names):
pred = model.predict([encode_inp(name)],verbose=0)[0]
pred_str = ", ".join([*map(lambda x:colored(x[0],"green" if x[0]==corrects[i] else "black")+":"+str(sg(x[1])),decode_out(pred))])
if i%5 == 0:
print(f"\n{name_types[i//5]}")
print(f"'{colored_lost_ch(name,names[i%5] if i//5<4 else name)}' → {pred_str}")
出力例

入力文字 → 予測されたポケモンタイプ:その確率,... と出力されています。予測は確率の高いものから順に書かれています。緑色は正解データです。
文字がかけて入力される場合は、ポケモンタイプが正解できるギリギリのところまで後ろ、中間、前から1文字ずつ消しています。ただ1文字目で間違える場合は、そのまま表示しています。
最後の名前の合成は正解はないのであくまでも、こういうこともできるという例です。
12. LSTMとGRUについて
RNNの拡張版としてLSTM(Long Short Term Memory networks)、GRU(gated recurrent unit)などが提案されています。ここでは、RNNの何を拡張したのかをイメージだけで説明してみます。

RNNは内部状態を、前回の内部状態が重みによって変形したもの、入力が重みによって変形したものの2つで更新されます。このときに内部状態のどの数値であっても均等に値が変わっていくことができます。上の図の左側です。
一方、LSTMやGRUでは上図の右のように内部状態に濃淡をつけて、大きく変わるところとあまり変わらないところを作り出すようなことができます。これは何をしているかというと、RNNは入力の時系列分だけ何度も内部状態を更新していくわけですが、後の方の入力データまで残しておきたい内部状態の数値はあまり変更せず、今現在の入力データに強く反応したときにはその内部状態を大きく変更する、といったことができるようになるということです。つまり、内部状態が記憶のようなものを持つようになります。この記憶によって「私の好きな食べ物は〇〇です」から入力が始まったとして、質問文までの間にいろいろな言葉が入力されたとしても、最後の「ところであなたの好きなのは?」とモデルに問うたときに「食べ物ことだ」と分かるようにできるようになります。RNNの場合にはこの記憶の部分がないので「私の好きな食べ物は〇〇です」から「ところであなたの好きなのは?」までの間が長いと何の話をしていたのか覚えていられず、間違えた回答をしてしまうことがあります。
内部状態は有限の長さのベクトルなので、覚えることを単純に増やすことはできません。新しいことを覚えるためには逆に忘れる部分を作る必要があります。そしてその忘れた部分に新しい情報をセットします。LSTMやGRUではこれらの機能をゲートと呼ばれるフィルターのようなもので実装しています。内部状態をまずフィルターにかけて消す部分と残る部分を作るというイメージです。このフィルターは入力値や出力値にも適用されます。内部状態に反映した入力の部分、内部状態から出力したい部分という感じです。そしてそのゲート自体は1つの小さなニューラルネットワークでできているので、RNNの重みと同様に正解データから学習されます。
LSTMとGRUには次のようなゲートがRNNに付加されたものということができます。
- LSTM
- 忘却ゲート(内部状態をフィルタリングして残すところを消えるとことを決定する)
- 入力ゲート(入力データで内部状態に反映したいところを決定する)
- 出力ゲート(内部状態のどこを出力するかを決定する)
- GRU
- リセットゲート(LSTMの忘却ゲートのようなもの)
- 更新ゲート(LSTMの入力ゲートとのようなもの)
GRUはLSTMの簡略化で出力ゲートがありません。その分だけ重みの総数が少ないので早く学習できるというものです。
今回のポケモンタイプの判別例の場合、モデルの作成で示した keras.layers.SimpleRNN を keras.layers.LSTM や keras.layers.GRU に変更すると、それぞれのモデルを使用することができます。
13. 機械学習モデルの検討
ここでは、モデル作成についていろいろと試したことを書き留めておきます。
13.1. 内部状態のニューロン数について
RNNの内部状態のニューロン数をポケモンタイプ数の18としてRNNを学習したところ、損失が高止まりして学習が上手くいきませんでした。この18という数字は、SimpleRNN層のあとで全結合層を外してkeras.layers.Softmaxのような重みのない層を入れれば、内部状態がポケモンのタイプ識別をそのまま保持していることになります。このようなシンプルなモデルでは、ポケモンデータは学習できなかったということになります。
そこでタイプ数18の2倍の36を試し、それでもイマイチ損失が減らないので最終的に3倍の54としました。内部状態の次元がポケモンタイプの次元よりも大きいということは、内部状態が直接的にポケモンタイプを記憶しているのではなく、ポケモンタイプにつながる特徴を保持しているといえます。その特徴から最終的にポケモンタイプを抽出するのは、54個のニューロンがポケモンタイプ数の18に全結合する層で実現しています。
ポケモンタイプをそのまま記憶するのと、特徴を記憶するのの違い
y = RNN(x)
という感じになります。これがRNNが内部状態としてそのままポケモンタイプを記憶しているイメージです。一方RNNが特徴を保持しているとは、
y = f(RNN(x))
となります。fはある関数です。RNNが出力するものはある関数の引数となり、その関数を通すとポケモンタイプが求められる、というイメージです。
13.2. 学習率(learning rate)について
学習率とは、正解データと予測データの差である損失から重みを更新するときに、どれぐらい損失を重みに反映するのかを決定する数値です。例えば学習率を 1.0 とすると、損失が10ならばその10という数値を使って重みの更新をします。ただこうすると重みの数値が行ったり来たりして学習が進みません。そこで、0.01などの学習率を指定して損失が10であっても重みの更新には10の1%の0.1という小さな数値で計算をするようにします。
このような学習率を含めて重みの更新に関する戦略は、モデルのcompile関数の引数で指定した optimizer="adam"で決定されます。adamという名前の戦略を取っていることになるのですが、このadamの学習率はデフォルトで 0.001 です。この学習率でポケモンデータの学習を行った場合、損失が振動する現象が起こりました。損失が振動するとは、この記事の損失の描画の箇所で示したグラフでいうと、右下の学習の終わりのころのグラフが跳ねているところです。これは学習回数ごとに損失が減ったり増えたりが大きく起こっていることになります。このような振動をできるだけ抑えるために学習率を下げて 0.00005 として学習を実行しています。
13.3. 入力文字のEmbeddingについて
ポケモン名に使われる文字は、37種類でした。これを今回は4次元のベクトルに押し込めています。この4次元という数値は適当です。これよりも小さい数字は検討していません。次元の最大は、ポケモン名の長さを統一するための文字が存在しないところを表す1つの数字を加えて38次元になるわけですが、それを試したところ4次元とあまり変わりは見られませんでした。
14. 補足:1次元畳み込みニューラルネットワークと時系列データ
ポケモンの名前を1文字ずつに分解して時系列データ(シーケンスデータ)として扱いました。ただ近年では、ポケモン名を文字の時系列データではなくただの1次元配列のデータとみて1次元の畳み込みニューラルネットワークでモデルを作成する方が良いという例もあります。
Convolutional Sequence to Sequence Learningという論文では文章を単語に分解した入力から、データセットごとに与えられた例えばポジティブ意見、ネガティブ意見などの文章に付けられたラベルを学習するというタスクにおいて、RNNのようなモデルを含む既存モデルよりも1次元畳み込みニューラルネットワークの方が良い精度を達成したと報告しています。
また、Convolutional Neural Networks for Sentence Classificationでは、シーケンスデータを入力としてモデルに与え、シーケンスデータを出力するタスクにおいても1次元畳み込みニューラルネットワークがRNN系のモデルより良いと述べています。
畳み込みニューラルネットワークは、画像認識で注目されるようになってきて、その特徴の1つは隣り合うピクセルの関係を学習に取り入れたことです。畳み込みではないニューラルネットワークのときは、ピクセルごとが独立していて、「あるピクセルは別のあるピクセルの隣にある」などの位置情報が考慮されていませんでした。畳み込みのアイディアはピクセルの位置情報を考慮するようにしたともいえます。言い換えると画像データをピクセルの順番が決まったシーケンスデータのように扱っているともみれます。よって従来はRNNのようなモデルを適用してきた文字列データのようなものにも、畳み込みニューラルネットワークならば対応できるというわけです。
今回のポケモンデータの例でもこの1次元の畳み込みニューラルネットワークでモデルを実装することもできるわけですが、今回はrecurrentなモデルを試すという目的で、SimpleRNN, LSTM, GRUで実装してみました。
参考
Understanding LSTM Networks
LSTM: Understanding the Number of Parameters
Kerasの再帰型ニューラルネットワーク(RNN)
A Visual Guide to Recurrent Layers in Keras
直感で理解するLSTM・GRU入門 - 機械学習の基礎をマスターしよう!
農学情報科学 RNN
Convolutional Sequence to Sequence Learning
Convolutional Neural Networks for Sentence Classification