こんにちは!toyohamaです。
何気に動画編集なんかも仕事でやったりしてるのですが、いざ作るとなると時間と手間がかかっちゃう……というか、どうしてもこだわっちゃって気がつくと日が暮れてた、なんてことがよくあります。
今回はそんな動画編集を少しでも楽にして、自分も周りもハッピーにできないか? と思って試してみたことを書いてみたいとおもいます。
環境
- MacBook Pro (Retina, 13-inch, Early 2015)
- Open Jtalk Version 1.10
- Microsoft PowerPoint fot Mac Version 16.18
今回の要件
- 動画を作る
- ゼロから作り込むものではない
- パワーポイント(パワポ)の元資料があり、それに沿って動画に落とし込む
- そこにナレーションを付け加えていく
というものでした。
まずはパワポを動画にする
実はパワーポイントには標準で動画として出力できる機能がついています。
僕の周りだけかもしれませんが意外と知られていませんでした(画像で出力するのはみんな知ってましたが)。たしかにパワポを動画にするシチュエーションって限られてる気がしますが、うまくやればパワポだけでもそれなりの動画作れちゃうのかなと思ったりしました。そしたらこの記事意味なくなっちゃうな……。
横道にそれました(笑)
 パワポの「ファイル」から「エクスポート…」を開き
パワポの「ファイル」から「エクスポート…」を開き
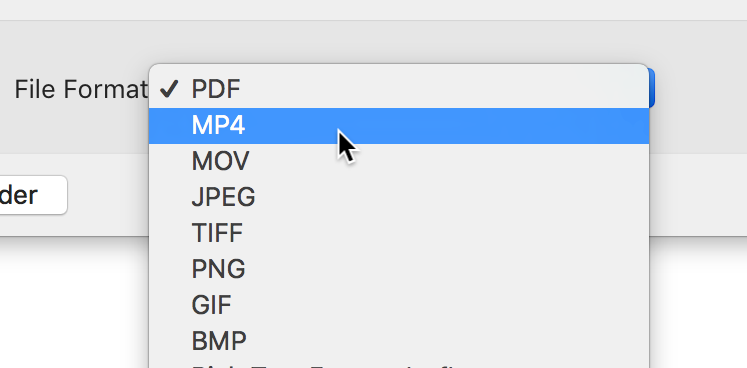 「MP4」や「MOV」を選択します(お好みで)
「MP4」や「MOV」を選択します(お好みで)
 モックなんで最低画質でいいでしょう。デフォルトはページめくりが5秒になってますが、10秒ぐらいで一度作ってみます。
モックなんで最低画質でいいでしょう。デフォルトはページめくりが5秒になってますが、10秒ぐらいで一度作ってみます。
あとは待つのみです。
音声を合成する
最初考えていたのは、母音・子音の音声データを用意し合成するみたいな形でしたが、めんどくさすぎるもっと簡単な解決策があるのでそちらを活用することにしました。
Open Jtalk
こちらを使えば難しいことなしに日本語のテキストから音声を合成してWAVファイルにしてくれます。ほんと便利な世の中になったものです。
インストール
brewが動かないとかいろいろありましたが、普通はこれだけでインストールが完了するはずです。
bash $ brew install open-jtalk
テキストから音声を合成してみる
bash $ echo "ほげほげふーばー" > t2stest.txt
bash $ open_jtalk -x /usr/local/Cellar/open-jtalk/1.10_1/dic -m /usr/local/Cellar/open-jtalk/1.10_1/voice/mei/mei_normal.htsvoice -ow out.wav t2stest.txt
-x : 辞書ファイルの指定(デフォルトのものなら上記で)
-m : 音声ファイルの指定(デフォルトのものなら上記で)
-ow : アウトプットする音声ファイル名
さいご : infile。元テキストを指定
これでout.wavに「ほげほげふーばー」と喋ってるファイルができるはずです。
.htsvoiceという音声ファイルはいろんな大学や個人がフリーで公開しているものがあります。お好みで使ってみてはいかがでしょうか。
パワポからテキストを抽出する
それでは、元テキストをパワポから作っていきましょう。
今回はスライド1枚1枚に設定できる「ノート」を使います。スライドの下のメモ欄みたいなところですね。
ノートの内容をさぐる
以前も書きましたが、Office 2007からはXMLやその他情報をZipで固めた「Office オープン XML」という形式になっています。ですので普通にunzipで解凍できます。
bash $ unzip test.pptx
解凍したディレクトリにppt/notesSlidesがあり、その下にnotesSlideで始まるファイルがずらーっと並んでいます。こいつをテキストにおとしていけばよさそうです。
toyohama@mac:~/Desktop/test/ppt/notesSlides
bash $ ls -1
_rels
notesSlide1.xml
notesSlide10.xml
notesSlide11.xml
notesSlide12.xml
notesSlide13.xml
notesSlide14.xml
notesSlide15.xml
:
:
テキストに落としていく
ここからは難しくないですね。
1つ注意点としては、Open Jtalkにテキストを渡す際、改行があるとその先のテキストを読み込んでくれなかったので、テキスト化する際に改行を取り除いておきましょう。
bash $ for i in `ls notesSlide*.xml` ; do cat $i | perl -ne 'while( m|<a:t>([^<]+)</a:t>|g ) {print $1."。";}' > out/$i.txt ; done
ちゃんとXML解析しろよ、という話ですが、うまく改行を含むことなく落とし込めました。
."。"をつけているのは、ノートの文章のなかで改行ごとにきちんと句点が着いていない部分があったので、文章がつながらないように挿入しています。。。と続いてしまう場合もありますが、音声にする際には問題にならないので気にしません。
ちょっと余談
このファイル名をみると、いかにもスライド番号とノートの番号がリンクしてるように見えますが、実はそうではありません。スライドはスライドで番号が振られ、ノートはまたノートだけで振られていく仕様になっているようで、notesSlide3.xmlと書かれていてもスライド6のものだったりします。わかりづらい……。
関係性を表すXMLは以下の場所にあります。
bash $ cat slides/_rels/slide6.xml.rels
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"><Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/slideLayout" Target="../slideLayouts/slideLayout6.xml"/><Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/notesSlide" Target="../notesSlides/notesSlide3.xml"/></Relationships>
bash $ cat notesSlides/_rels/notesSlide3.xml.rels
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"><Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/notesMaster" Target="../notesMasters/notesMaster1.xml"/><Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/slide" Target="../slides/slide6.xml"/></Relationships>
前者はスライド側からみたノートXMLの紐付け、後者はその逆になっていますね。どっちか一つでもいい気がするんですが、なにか理由があるんでしょうか……番号合わせてくれたほうがわかりやすいのに。
Open Jtalkに食わせて音声ファイルを作っていく
こちらもXMLからテキスト抽出するときと同じですね。ただ、さきほど抽出したテキストファイルは中身が無いものもあるので、findでゼロバイト以上のファイルのみ対象にしています。
bash $ for i in `find . -name '*.xml.txt' -size +1c` ; do echo "[$i]" ; open_jtalk -x /usr/local/Cellar/open-jtalk/1.10_1/dic -m /usr/local/Cellar/open-jtalk/1.10_1/voice/mei/mei_normal.htsvoice -ow wavout/$i.wav $i ; done
[./notesSlide10.xml.txt]
[./notesSlide11.xml.txt]
[./notesSlide14.xml.txt]
[./notesSlide16.xml.txt]
[./notesSlide17.xml.txt]
[./notesSlide18.xml.txt]
[./notesSlide19.xml.txt]
[./notesSlide2.xml.txt]
[./notesSlide20.xml.txt]
:
:
あとは煮るなり焼くなり
最初に作ったパワポ動画と音声ファイルをお好きな動画編集ツールにペタペタ貼っていけば終了です。
まとめ
もっとこだわるのであれば、文章の長さによってしゃべるスピードを変えたり、出力した音声ファイルを全部つなげ、動画編集ツールに一発でおけるように、とかするとさらに楽になると思います。
実は変換するときにちょっとしたトラブルがあったんですが、長くなりすぎたんで別途まとめようと思います。
最後まで読んでいただき、ありがとうございました!