1.簡単な概要
この記事では、ラーメン屋の食べログ評価を口コミから予測するために、取り組んだことを書きます。
ユーザーの口コミから食べログ評価の予測ができれば、仮に食べログに掲載されていないお店があったときに、口コミさえあれば、食べログ換算するとざっくり○点ぐらいだろうことがわかれば嬉しいなと思いやってみました。
今回は、「お店の評価」ではなく、**「ユーザーが付けた評価」**を当てにいきます!
手順としては、
①口コミデータの取得
②基礎分析
③特徴量の選定
④予測モデル構築
となります。
最終的なイメージはこんな感じです!

では早速やってみたいと思います。
まずは、口コミデータの取得から。
2.口コミデータの取得
詳しくはこちら↓↓で説明しています。
第1弾:【Python】ラーメンガチ勢によるガチ勢のための食べログスクレイピング
口コミを1件ずつ取得した後に、データフレームにまとめました。
※食べログ規約にもとづき口コミに関する箇所にはモザイクをいれております。ご了承ください。
3.仮説
口コミにおいて、どのような口コミが点数が高くなるか、ないし低くなるかを仮説を立ててみます。
高評価の口コミ
・口コミの文章量が多い。
・「美味しい」や「絶妙」などラーメンを賞賛する単語が多い
・「丁寧」「感じが良い」など店員のサービスを賞賛する単語が多い
低評価の口コミ
・口コミの文章量が少ない
・不味い、普通、微妙等、ネガティブな単語が多い
実際の高評価の口コミ(評価3.8)
2019年ミシュランガイドに
東京エリアで掲載されているラーメン店は24、ここまで食べたお店は23店。
最後の1店は世界で初めてラーメン店で☆取ったこの店です。
この日現在、ランチは整理券方式。
夜の部(17:00~20:00)は整理券無しで案内。
JR巣鴨駅南口から徒歩2分、
16:30頃に行ってみると...誰も並んでいませんでした。
さすがに17時オープン間際には、10人ぐらいの並びになっていました。
17時オープン♪
入口の券売機でチャーシュー味玉醤油Sobaを購入。
お値段は1,400円!WoW!
店内はL字型カウンターで全9席、開店してすぐに満席となりました。
まずはスープ、トリュフの香りが最高です♪
上品なスープは、鶏のスープ、貝のスープ、節系のスープのトリプルスープとのこと。
さすがに旨味がたっぷりです♪
麺は細麺でストレート、小麦の風味が良いですねー。
また、とっても滑らかで舌触りでちょっと柔らかめな感じです。
具の2種類のチャーシュー、地鶏の味玉は
どれも高級食材を使っていて、どれも満足いくもの。
最後はスープをしっかりと飲み干してご馳走さまでした!
流石、ミシュラン1つ星のラーメンでした!
実際の低評価の口コミ(評価2.8)
何年か前にミシュラン1つ星ということで期待大で11時半くらいに行きました。
整理券配布のお店ですが30分くらいで入店できました。
味は醤油・塩・味噌ラーメン・サーモン白湯の4種類
気分的に塩だったのでチャーシュー味玉塩ラーメン1400円と肉飯350円
券売機で食券を購入!
券売機自体にもあえて大きなボタンでチャーシュー味玉塩ラーメン1400円を購入させる工夫が施されています。私の確認不足なので全然大丈夫です。
塩ラーメンは美味しかったですが正直普通でした。
ん~このお店は何かと売り方や見せ方がうまいだけで
接客・味自体はミシュラン相当ではないのでは・・・
個人的には期待値より低かったので残念ですね。
愚痴になってしまいました。
すみません。
4.基礎分析
取得した口コミ数と口コミ評価の出現頻度です。
また、お店の評価と個々のユーザーの評価の平均値や中央値等も見てみます。
import numpy as np
import matplotlib as plt
# 点数がない口コミを除去
df2 = df[df.Individual_rating_score != '-']
# ユニーク店舗数
print('ユニーク店舗数は'+str(df2["store_name"].nunique())+'件')
# 口コミ数
print('口コミ数は'+str(len(df2))+'件')
# 出現頻度をプロット
vc = df2['Individual_rating_score'].value_counts().reset_index().sort_values('index', ascending=False)
vc.plot.bar(x='index', y='Individual_rating_score')

df2['score'].describe()
df2['Individual_rating_score'].astype(np.float).describe()

今回は都内食べログランキングの上から1016店舗から21811件の口コミを取得しました。
数字が中途半端なのはスクレイピングの都合です。
食べログ評価上位(3.5〜4.1)のお店の口コミをスクレイピングしたため、ユーザーの評価も3.5以上に偏っていますね。
つまり、割と点数が高めの学習データなので、予測する際にその影響を受けることは念頭におきながら進めます。
5.特徴量の選定(その1)
口コミデータからどうしたら食べログ評価を予測できるか調べるために、点数に効きそうなことを要素を探します。
①口コミの長さとの相関
②感情スコアとの相関
感情スコアとは、例えば、「美味しい」、「良い」などpositiveなワードには正の値,「不味い」、「悪い」などはnegativeなワードには負の値を与えスコア化します。このスコアは-1〜+1の範囲ですが「単語感情極性対応表」によって規定されています。
詳しくはこちら↓
http://www.lr.pi.titech.ac.jp/~takamura/pndic_ja.html
https://ohke.hateblo.jp/entry/2017/10/27/230000
①口コミの長さとの相関
私の経験則ですが、美味しかったお店の口コミを書くときは、意気揚々として長文になります。
一方で微妙だったお店の口コミ短く済ませてしまうことの多いので、口コミの長さはある程度は関係していると思われます。
# sklearn.linear_model.LinearRegression クラスを読み込み
from sklearn import linear_model
# matplotlib パッケージを読み込み
import matplotlib.pyplot as plt
# カラムに文字数を追加します。
df2['word_cnt'] = df2['review'].apply(lambda x : len(x))
# 線形回帰モデル
clf = linear_model.LinearRegression()
# 説明変数に "word_cnt (文字数)" を利用
X = df2.loc[:, ['word_cnt']].as_matrix()
# 目的変数に "Individual_rating_score (ユーザー評価)" を利用
Y = df2['Individual_rating_score'].as_matrix()
# 予測モデルを作成
clf.fit(X, Y)
# 回帰係数
print('回帰係数:'+str(clf.coef_[0]))
# 切片 (誤差)
print('切片:'+str(clf.intercept_))
# 決定係数
print('決定係数:'+str(clf.score(X, Y)))
# 相関係数
corr = np.corrcoef(df2['word_cnt'], df2['Individual_rating_score'])
print('相関係数:'+str(corr[1][0]))
# Figureを設定
fig = plt.figure()
# Axesを追加
ax = fig.add_subplot(111)
ax.set_ylim(1, 5)
# 散布図
plt.scatter(X, Y)
# 回帰直線
plt.plot(X, clf.predict(X))

相関係数0.079・・・ということで相関はかなり弱いということがわかりました。当然ですが、口コミの文字数だけで点数が決まるほど単純な話ではありませんでした。
②感情スコアとの相関
感情スコアは-1~+1の範囲で表しますので、口コミにpositiveな単語が多ければ多いほどユーザーが付けた評価も高くなりそうですよね!
f = open('../work/kanjo_dict.txt', 'r')
kanjo_dict = {}
for line in f:
kanjo_list = line.replace('\n','').split(":")
kanji = kanjo_list[0]
kanjo_dict[kanji] = kanjo_list[3]
f.close()
kanjo_dict

import MeCab
tagger = MeCab.Tagger('-Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')#タグはMeCab.Tagger(neologd辞書)を使用
tagger.parse('')
# 分かち書きで取得する品詞を指定
def tokenize_ja(text, lower):
node = tagger.parseToNode(str(text))
while node:
if (lower and node.feature.split(',')[0] in ["名詞","形容詞"]) and lower and node.feature.split(',')[1] !='代名詞':
yield node.surface.lower()
node = node.next
# 分かち書きする関数を定義
def tokenize(content, token_min_len, token_max_len, lower):
return [
str(token) for token in tokenize_ja(content, lower)
if token_min_len <= len(token) <= token_max_len and not token.startswith('_')
]
from statistics import mean
# 感情スコアを合計する関数を定義
def kanjo_score_total(x):
txt = tokenize(x, 1, 10000, True)
total = 0
for i in txt:
try:
total += float(kanjo_dict[i])
except:
continue
return total
# 感情スコアを平均する関数を定義
def kanjo_score_avg(x):
txt = tokenize(x, 1, 10000, True)
score_list =[]
for i in txt:
try:
score_list.append(float(kanjo_dict[i]))
except:
continue
try:
mean(score_list)
return mean(score_list)
except:
return np.nan
df2['kanjo_score_total'] = df2.review.apply(kanjo_score_total)
df2['kanjo_score_avg'] = df2.review.apply(kanjo_score_avg)
*プロットする部分のコードは省略

なんと、意外なことに「感情スコアの合計」では相関がみられない・・・というかむしろ負になってしまっている。
これは、特徴量としては使えなさそうですね。
次に「感情スコアの平均」は、相関係数0.15ということで弱い相関がみられることがわかりました。
とりあえず「感情スコアの平均」は特徴量の候補に入れます。
「感情スコア」を使っても上記のような結果となった要因としては、
①「濃厚」や「淡い」などラーメン用語としてはポジティブそうな単語も「単語感情極性対応表」ではネガティブという判定になっている
②「醤油」や「豚骨」といったポジティブともネガティブとも取れなそうな単語もネガティブになっていたりと、そもそも「単語感情極性対応表」があてにならないケースが多くありました。
6.特徴量の選定(その2)
・口コミ出現した全単語をOne-Hotベクトルで表し、corr(相関係数)で寄与度を確認
例えば、単純に「美味しい」という単語が口コミにあったら、その単語が点数に寄与しているか調べます。まずは、出現する単語全てに対して点数と相関があるか調べてみました。
# 口コミを分かち書き
for i in df2['review']:
txt = tokenize(i, 2, 10000, True)
wakati_ramen_text.append(txt)
# 分かち書きされた単語リストをカラムに追加
df2['wakati_ramen_text'] = wakati_ramen_text
df2_words = df2
# 出現頻度の高い単語に絞る※上位10単語は頻出単語のためstopwordとして除外
target_words = df_cnt2.loc[10:1000,'index'].values.tolist()
for add_col in target_words:
df2_words[add_col] = df2_words['wakati_ramen_text'].apply(lambda x : 1 if add_col in x else 0)
# 不要なカラムを除去。
df3 = df2_words.drop(columns=['Unnamed: 0', 'store_id','store_name','score','ward','review_cnt','review','wakati_ramen_text','moji_cnt'])
# 相関係数を算出
corr_mat = df3.corr()
# 点数と単語の相関だけに絞る
corr_Individual_rating_score = corr_mat.loc['Individual_rating_score',:].reset_index()
# 相関係数に閾値を決め、絶対値が大きい単語のみに絞る
corr_Individual_rating_score2 = corr_Individual_rating_score[(corr_Individual_rating_score["Individual_rating_score"] > 0.04) | (corr_Individual_rating_score["Individual_rating_score"] < -0.02)].sort_values('Individual_rating_score', ascending=False).reset_index()
# 絶対値が大きい単語以外のカラムは除去。
target_columns_list = corr_Individual_rating_score2['index'].values.tolist()
columns_list = df3.columns.values.tolist()
target_df = df3
for col in columns_list:
if col not in target_columns_list:
target_df = target_df.drop(columns=col)
target_df

corr_Individual_rating_score.sort_values('Individual_rating_score', ascending=False).reset_index()
corr_Individual_rating_score.sort_values('Individual_rating_score', ascending=True).reset_index()

相関係数が高い単語と低い単語をみると、ポジティブそうな単語はプラスになり、ネガティブそうな単語はマイナスになっています。肌感覚的に信用できそうなので特徴量候補にします。
全単語を特徴量にしてしまうと変数が限りなく増えてしまうので、出現頻度の高い単語上位1000件に絞り、さらにその中から相関係数の絶対値が大きい単語に絞りました。
点数への寄与度が高い単語数を○○つに絞りましたが、説明変数にする際は、クラスタリングで○個の単語を10個の単語群にグルーピングします。
7.特徴量の選定(その3)
先ほど分かち書きした単語を使いword2vecで単語をベクトル化します。
その後、クラスタリングをして、各単語を10個にグループ分けします。
# word2vecモデル作成
model = word2vec.Word2Vec(wakati_ramen_text, sg=1, size=100, window=5, min_count=5, iter=100, workers=3)
# sg(0: CBOW, 1: skip-gram),size(ベクトルの次元数),window(学習に使う前後の単語数),min_count(n回未満登場する単語を破棄),iter(トレーニング反復回数)
# 参考 https://hironsan.hatenablog.com/entry/clustering-word-vectors
from collections import defaultdict
from gensim.models.keyedvectors import KeyedVectors
from sklearn.cluster import KMeans
max_vocab = 30000
vocab = list(model.wv.vocab.keys())[:max_vocab]
vectors = [model.wv[word] for word in vocab]
# クラスター数はこちらで任意の値を定める
n_clusters = 10
kmeans_model = KMeans(n_clusters=n_clusters, verbose=0, random_state=42, n_jobs=-1)
kmeans_model.fit(vectors)
cluster_labels = kmeans_model.labels_
cluster_to_words = defaultdict(list)
for cluster_id, word in zip(cluster_labels, vocab):
cluster_to_words[cluster_id].append(word)
# 参考 https://note.nkmk.me/python-dict-change-key/
# 辞書のキー名を変更する関数を定義
def change_dict_key(d, old_key, new_key, default_value=None):
d[new_key] = d.pop(old_key, default_value)
change_dict_key(cluster_to_words, 0, 'ラーメンの感想に関するするワード')
change_dict_key(cluster_to_words, 1, '店内に関するワード')
change_dict_key(cluster_to_words, 2, '時系に関するワード')
change_dict_key(cluster_to_words, 3, '評判や地理的なワード')
change_dict_key(cluster_to_words, 4, 'ネット用語ワード')
change_dict_key(cluster_to_words, 5, '券売機や食券に関するワード')
change_dict_key(cluster_to_words, 6, '周辺の環境や地理的なワード')
change_dict_key(cluster_to_words, 7, '具材に関するワード')
change_dict_key(cluster_to_words, 8, 'スープや調味料に関するワード')
change_dict_key(cluster_to_words, 9, 'その他ワード')
df_dict = pd.DataFrame.from_dict(cluster_to_words, orient="index").T
df_dict
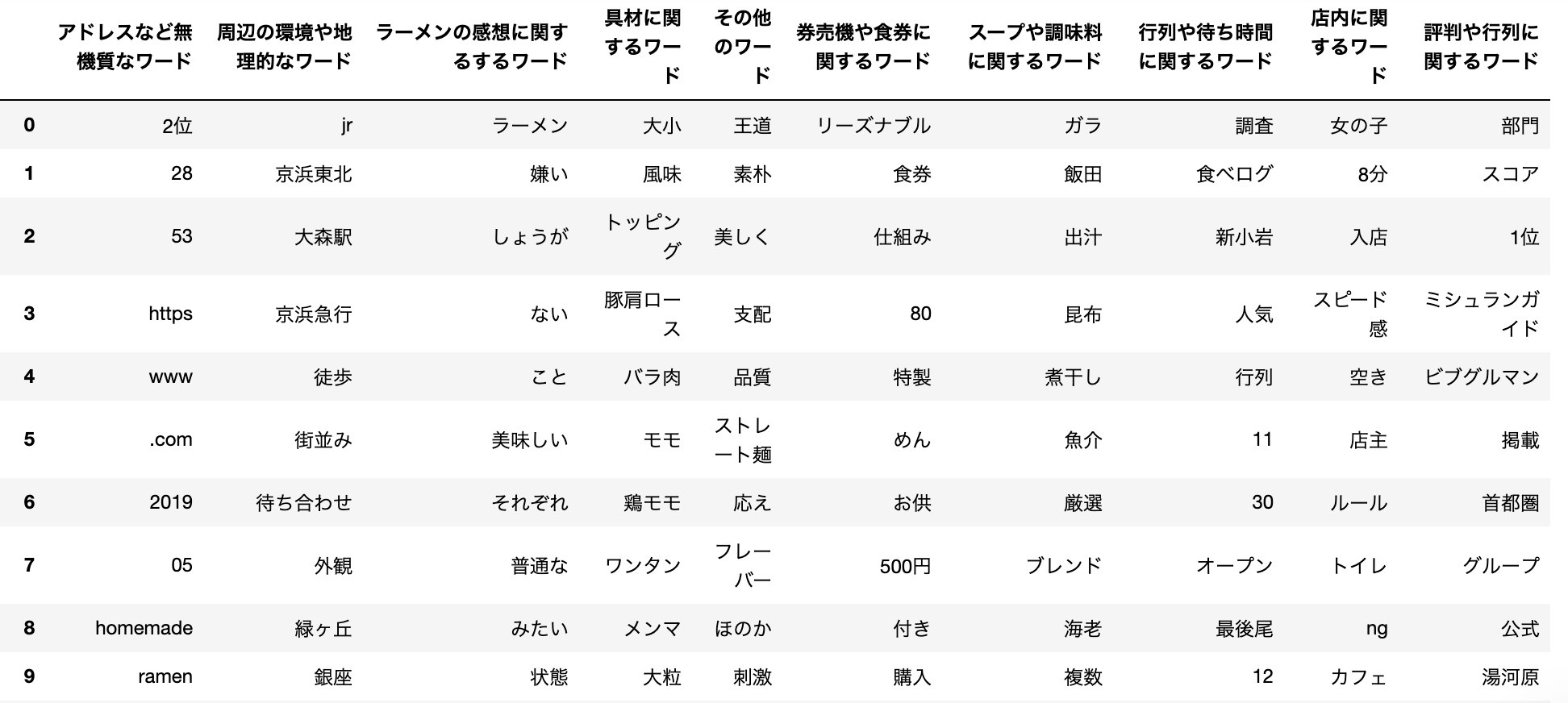
↑のデータに対して、
df2_over_1000['wakati_ramen_text'] = wakati_ramen_text
cluster_list = df_dict.columns.tolist()
plus_master_dict = {}
minus_master_dict = {}
plus_score_list = []
minus_score_list = []
# 単語の相関係数を正の相関と負の相関に分けてグループ内で足し合わせていく
for word_list in df2['wakati_ramen_text'].values.tolist():
plus_master_dict = {}
minus_master_dict = {}
for cl in cluster_list:
plus_master_dict[cl] = 0
minus_master_dict[cl] = 0
for word in word_list:
try:
columns_word = cluster_list[df_dict_pair[word]]
if corr_dict[word] >0:
plus_master_dict[columns_word] += corr_dict[word]
elif corr_dict[word] <0:
minus_master_dict[columns_word] += corr_dict[word]
else:
continue
except:
continue
plus_score_list.append(plus_master_dict)
minus_score_list.append(minus_master_dict)
df2['kanjo_score_avg'] = df2.review.apply(kanjo_score_avg)
df2['plus_score_list'] = plus_score_list
df2['minus_score_list'] = minus_score_list
for add_col in cluster_list:
df2['+'+str(add_col)] = df2_2['plus_score_list'].apply(lambda x : x[add_col])
df2['-'+str(add_col)] = df2_2['minus_score_list'].apply(lambda x : -1*x[add_col])
target_df = df2.drop(columns=['Unnamed: 0', 'store_id','store_name','score','ward','review_cnt','review','plus_score_list','minus_score_list','kanjo_score_avg'])
target_df

8.重回帰分析
import statsmodels.api as sm
X = target_df.drop('Individual_rating_score', 1)
X = sm.add_constant(X)
Y = target_df['Individual_rating_score']
model = sm.OLS(Y, X)
result = model.fit()
result.summary()
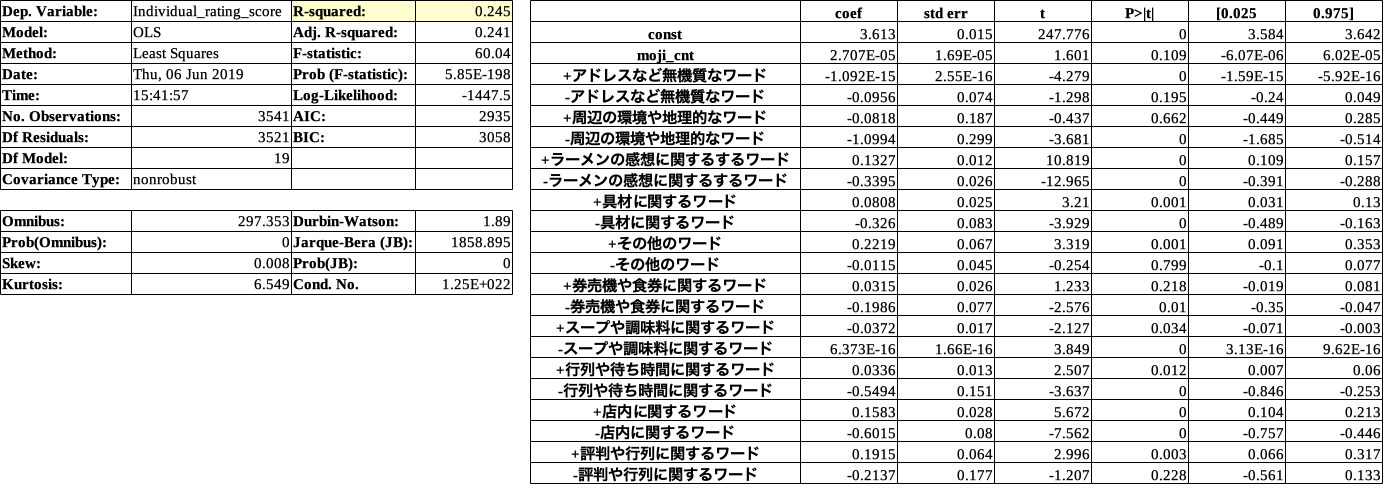
黄色で示した決定係数(R-Squared)は、回帰式によって説明できる割合を表わします。
そして、決定係数の値は0から1の間で、値が大きいほど分析精度は良いといえます。
**プラス**に効いている説明変数TOP3は、(p値0.5以下)
1位その他のワード
2位評判や行列に関するワード
3位店内に関するワード
**マイナス**に効いている説明変数ワースト3は、(p値0.5以下)
1位店内に関するワード
2位行列や待ち時間に関するワード
3位ラーメンの感想に関するワード
この結果から考察すると、
・評判や行列が点数と高くする要因となっている。(食べる前の印象が大事ということでしょうか)
・店内に関するワードがプラスにもマイナスにも効いているので、店内の雰囲気や接客が良くも悪くも点数に響いている。
・ラーメンの感想はネガティブの場合に点数を低くする。(美味しいのはあたりまえで、そのでないと点数がガクッと下がる)
ラーメンの感想に関するワードが、どちらも1位でなかったのが意外でした。
さらに、数値予測問題における精度評価指標の手法である**MAE(Mean Absolute Error)**を計算します。
MAEは正解から平均的にどの程度の乖離があるかを示します。
モデルの予測精度の"悪さ"を表すため、0 に近い値であるほど優れています。
# MAEを算出
from sklearn.metrics import mean_absolute_error
testX = X
testX['const'] = 1.0 # 切片を追加
# testX = testX.ix[:,X.columns]
# 重回帰式で得られた予測値をテストデータに代入させる
pred = result.predict(testX)
testX ['pred'] = pred
target_df['pred'] = pred
y_true = target_df['Individual_rating_score']
y_pred = target_df['pred']
mean_absolute_error(y_true, y_pred)
MAE:0.2606560766702907
今回の重回帰分析の結果
決定係数:0.245
MAE:0.260
この結果から何がわかるかというと、
まず、決定係数は、説明変数がどれだけ目的変数(食べログ点数)を説明できているかを表しています。今回の結果では0.245なので寄与率が**約25%**ということです。
そして、MAEは誤差の絶対値を平均したものです。今回の結果では実際の点数に対して予測値が平均0.26点ずれていたということになります。
決定係数が低いためMAE(予測値のずれ)が大きくなったといえます。
他の手法(決定木やランダムフォレスト)も試してみましたが、大きく改善することがなかったので、口コミデータだけから食べログ評価の予測には限界があるのかもしれません。
9.ロジスティック回帰
何かしら成果になる結果を出したかったので、
ロジスティック回帰で、**口コミが3.5以上or3.5未満**か予測してみました。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
target_df['score_class']=target_df['Individual_rating_score'].apply(lambda x : '3.5以上' if
x >=3.5 else '3.5未満')
X = target_df.drop(['Individual_rating_score','score_class'], 1)
X = sm.add_constant(X)
Y = target_df['score_class']
logreg = LogisticRegression()
# データを分割します。テストが全体の40%になるようにします。
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.4,random_state=None)
# データを使って学習します。
result = logreg.fit(X_train, Y_train)
# テストデータを予測します。
Y_pred = logreg.predict(X_test)
# 精度を計算してみましょう。
print(metrics.accuracy_score(Y_test,Y_pred))
print('confusion matrix = \n', confusion_matrix(y_true=Y_test, y_pred=Y_pred))
print('accuracy = ', accuracy_score(y_true=Y_test, y_pred=Y_pred))
print('precision = ', precision_score(y_true=Y_test, y_pred=Y_pred))
print('recall = ', recall_score(y_true=Y_test, y_pred=Y_pred))
print('f1 score = ', f1_score(y_true=Y_test, y_pred=Y_pred))
accuracy = 0.76287932251235
confusion matrix =
[[1010 38]
[ 298 71]]
正解率は76.3%でした。
まあまあ良さげな結果になりました!
10.結論
口コミから正確に点数を予測することができませんでしたが、ロジスティック回帰のモデルを使えば、食べログに掲載のないお店に対して、ざっくり**「3.5以上or3.5未満」**かを予測して、一般的に美味しいお店かそうじゃないかを判断することができそうです!
11.課題
口コミは、様々な表現があり特徴量の作成が難しいことがわかりました。
例えば、淡麗系のラーメン屋と濃厚系のラーメン屋では、口コミに使う言葉の表現が異なるので一概に「○○のような口コミなら点数が高い」とは言い切れないのです。
試しに、データセットを醤油ラーメンだけに限定してモデルを作ると精度が良くなりました。
ですので、口コミからスープの種類を判別したのちにスープごとのモデルを作るとより、実用的な予測ができるのではないかと思います。
もっとこうしたらいいんじゃないかというアドバイスがありましたら是非コメントしてください!
🍜本記事が少しでも参考になりましたら是非「いいね」をお願いします!🍜