はじめに
実務でECサイトのレコメンド精度改善のために、画像とテキストの両方を用いたマルチモーダル分類モデルを実装しました。
当初社内にマルチモーダル・ディープラーニングについての知見がなく、web記事を片っ端から漁りましたが執筆時点(2021年11月)には参考になるような日本語記事はほとんど見当たりませんでした。
何とかしてマルチモーダルモデルを構築できないものかと調査したところMMBTの論文にたどり着きました。
そして、自社データを用いてモデル構築したところベースラインを上回る精度が出ましたのでここで紹介したいと思います。
これからマルチモーダルモデルに挑戦される方の参考になれば幸いです。
原論文:Supervised Multimodal Bitransformers for Classifying Images and Text
github:MultiModal BiTransformers (MMBT)
想定読者
・マルチモーダル・ディープラーニングに興味がある方
・「BERTやResnetは知ってるけど、マルチモーダルは知らん」という方
・機械学習、ディープラーニング中級者以上
BERTとResnetのマルチモーダル「MMBT」を徹底解説
2020年に登場し、テキストを多用するマルチモーダル分類タスクにおいて、既存のマルチモーダルモデル精度に匹敵、タスクによっては凌駕する結果を得ることができました。精度だけでなくファインチューニングが容易である点で非常に優秀で、今後様々な用途で社会実装されていくことが期待されています。
そもそもマルチモーダルとは
マルチモーダルとは複数のデータ様式を組み合わせることです。
本記事においては画像とテキストを組み合わせたマルチモーダル・ディープラーニングのことを指します。
例えば、ECサイトに出品されている商品の分類タスクを想定した際に、商品タイトル、商品説明文、画像、出品価格、ブランド名等が様々なデータが付与されています。既存の単一モーダルのモデルでは、テキストのみまたは画像のみで学習モデルを構築し分類タスクを処理していました。
しかし、画像またはテキストだけの単一モーダルの分類には精度面で限界があり、マルチモーダル情報を活用することで、複数種類の情報を統合的に処理することで単一モーダルよりも確実で抽象度の高い情報処理をすることができると考えられます。
画像とテキスト組み合わせることによって、より正確に分類できることが期待されます。
そこで今回は、商品タイトルと商品画像という非構造的なデータを組み合わせたマルチモーダルモデルをMMBTを用いて構築しました。
MMBTとは
ここから本題のMMBTについて詳しく触れていきます。
まずはざっくりと概略を掴むイメージでお読みください。
5行まとめると
・MultiModal BiTransformersの略だよ
・画像とテキストを分類するための教師ありマルチモーダル・ディープラーニングモデルだよ
・高精度かつファインチューニングが容易で実装が簡単なのが特徴だよ
・事前学習済のBERTとResNet-152を使ってるけど、BERT単体,ResNet単体のモデルや両方を単純に結合したモデルより高い精度が出るよ
・BERTとResNet-152のベクトルを結合した後にさらにBERTに入力しているのがミソだよ
もう少し詳しく
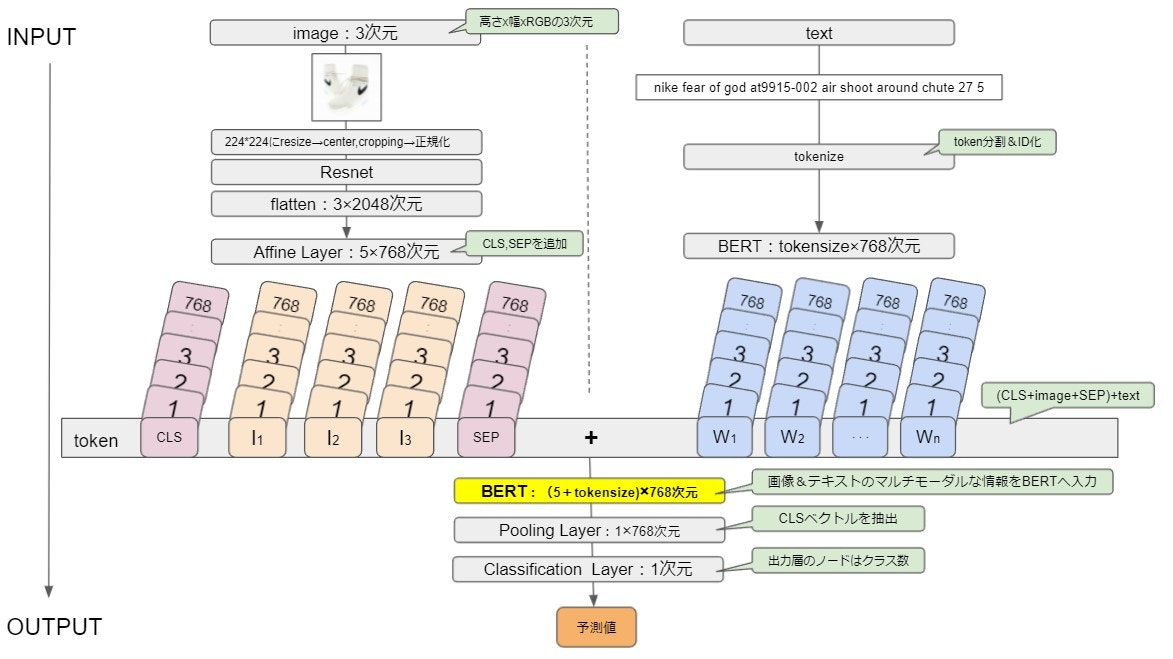
BERTをベースとした画像とテキストのマルチモーダルディープラーニングネットワークです。
画像側はResNet-152を用いて、テキスト側はBERTを用いてそれぞれベクトルに変換し、両方をtokenとして扱い連結します。
画像とテキストを連結したベクトルをさらにBERTに入力します。
BERTに入力しself-attentionを介すことで、様々なレベルで画像とテキストの情報を相互作用させることができるといわれています。
画像とテキストを連結したベクトルはその後BERTの文章ベクトルとして扱われるため、出力は入力文の各トークン毎に文脈を踏まえたベクトルが出てきます。
つまり、MMBTでは「画像&テキスト」の文脈が考慮されたベクトルが生成されると考えられます。
そして、分類の際はBERT同様に最終層の入力トークン[CLS]ベクトル(0番目のtoken)を用いて分類します。
参考:Supervised Multimodal Bitransformers for Classifying Images and Textを読んだ
よって、BERT単体,ResNet単体の分類モデルや単純に画像とテキストを連結したベクトルを用いたモデルよりも高い精度が出ると考えられます。論文では下記のような精度比較がされています。
精度比較
論文によると単一モーダル(BertとImg)の分類器よりも精度が高く、MMBT同様のマルチモーダルモデルであるConcatBertより高い精度が出ていることがわかります。
その結果、**マルチモーダル・バイトランスフォーマー(MMBT)**がベースラインを上回っています。
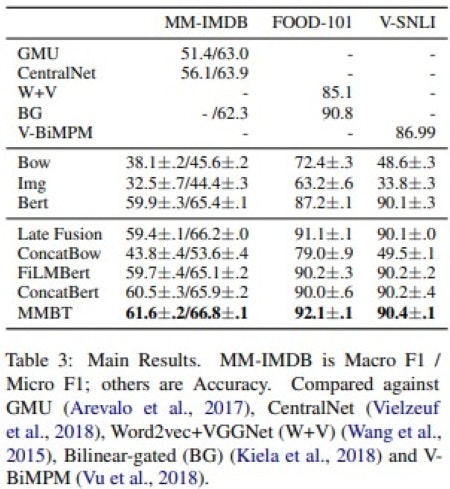
Table 3. Supervised Multimodal Bitransformers for Classifying Images and Textより引用
それでは実際にMMBTのモデル構築部分のコードを詳しく見ていきましょう
MMBTモデル構築部分のコード解説
実際にコードを実行しなくてもMMBTの挙動がわかるよう、あえてprintで出力するコードを残しております。
多少見づらい点もあるかと思いますがご容赦ください。
import torch
import torch.nn as nn
from pytorch_pretrained_bert.modeling import BertModel
from mmbt.models.image import ImageEncoder
class ImageBertEmbeddings(nn.Module):
# 1.CLSをベクトル化 2.SEPをベクトル化 3.画像をベクトル化 4.1~3をcat 4.3を標準化 5.4に対してdropout処理をする
def __init__(self, args, embeddings):
super(ImageBertEmbeddings, self).__init__()
self.args = args
self.img_embeddings = nn.Linear(
args.img_hidden_sz, args.hidden_sz
) # 画像ベクトルサイズ(2048次元)をbertの隠れ層(768次元)に圧縮
self.position_embeddings = (
embeddings.position_embeddings
) # 入力トークンの位置情報を把握するためのベクトル(最大文字数の種類分のベクトル表現)
self.token_type_embeddings = (
embeddings.token_type_embeddings
) # 各単語が1文目なのか2文目なのかn文目なのかを示す位置ベクトル
self.word_embeddings = embeddings.word_embeddings # 単語ベクトル
self.LayerNorm = embeddings.LayerNorm # 標準化
self.dropout = nn.Dropout(p=args.dropout) # ドロップアウト
def forward(self, input_imgs, token_type_ids):
# print(('input_imgs',input_imgs)) # tensor([[[1.7565, 0.3654, 0.0763, ..., 0.0407, 0.4960, 0.6700],
# print(('input_imgs',input_imgs.size())) # torch.Size([32, 3, 2048])
bsz = input_imgs.size(0) # bszはバッチサイズ
# print(('bsz',bsz)) # ('bsz', 32)
seq_length = self.args.num_image_embeds + 2 # +2 for CLS and SEP Token
# print(('self.args.num_image_embeds',self.args.num_image_embeds)) # 3
# print(('seq_length',seq_length)) # 5
# vocab.stoiは単語インデックス辞書
cls_id = torch.LongTensor([self.args.vocab.stoi["[CLS]"]]).cuda()
# print(('cls_id',cls_id)) # ('cls_id', tensor([101], device='cuda:0'))
cls_id = cls_id.unsqueeze(0).expand(bsz, 1)
# print(('cls_id',cls_id)) # ('cls_id', tensor([[101],[101],・・・[101]],device='cuda:0')) 32
# sepを単語ベクトル化
cls_token_embeds = self.word_embeddings(cls_id)
# print(('cls_token_embeds',cls_token_embeds)) # tensor([[[ 0.0136, -0.0265, -0.0235, ...,
# print('cls_token_embeds.shape',cls_token_embeds.shape) # torch.Size([32, 1, 768])
sep_id = torch.LongTensor([self.args.vocab.stoi["[SEP]"]]).cuda()
# print(('sep_id',sep_id)) # ('sep_id', tensor([102], device='cuda:0'))
sep_id = sep_id.unsqueeze(0).expand(bsz, 1)
# print(('sep_id',sep_id)) # ('sep_id', tensor([[102],[102],・・・[102]],device='cuda:0')) 32
# sepを単語ベクトル化
sep_token_embeds = self.word_embeddings(sep_id)
# print(('sep_token_embeds',sep_token_embeds)) # ('sep_token_embeds', tensor([[[-0.0145, -0.0100, 0.0060, ..., -0.0250]], device='cuda:0', grad_fn=<EmbeddingBackward>))
# print('sep_token_embeds.shape',sep_token_embeds.shape) # torch.Size([32, 1, 768])
# 画像ベクトル2048次元を768次元に圧縮
imgs_embeddings = self.img_embeddings(input_imgs)
# print('imgs_embeddings',imgs_embeddings) # imgs_embeddings tensor([[[-0.2272, -0.0792, -0.2961, ..., 0.4226, -0.1053, 0.5139],
# print('imgs_embeddings.shape',imgs_embeddings.shape) # torch.Size([32, 3, 768])
# cls+imgs+sep
token_embeddings = torch.cat(
[cls_token_embeds, imgs_embeddings, sep_token_embeds], dim=1
)
# print('token_embeddings',token_embeddings) # tensor([[[ 0.0136, -0.0265, -0.0235, ..., 0.0087, 0.0071, 0.0151],...]],device='cuda:0', grad_fn=<CatBackward>)
# print('token_embeddings.shape',token_embeddings.shape) # torch.Size([32, 5, 768])
position_ids = torch.arange(seq_length, dtype=torch.long).cuda()
# print('position_ids',position_ids) # tensor([0, 1, 2, 3, 4], device='cuda:0')
# print('position_ids.shape',position_ids.shape) # torch.Size([5])
position_ids = position_ids.unsqueeze(0).expand(bsz, seq_length)
# print('position_ids',position_ids) # tensor([[0, 1, 2, 3, 4],[0, 1, 2, 3, 4],[0, 1, 2, 3, 4],...]], device='cuda:0')
# print('position_ids.shape',position_ids.shape) # torch.Size([32, 5])
position_embeddings = self.position_embeddings(position_ids)
# print('position_embeddings',position_embeddings) # tensor([[[ 1.7505e-02, -2.5631e-02, -3.6642e-02, ..., 3.3437e-05,6.8312e-04, 1.5441e-02],
# print('position_embeddings.shape',position_embeddings.shape) # torch.Size([32, 5, 768])
# print('token_type_ids',token_type_ids) # tensor([[0, 0, 0, 0, 0], [0, 0, 0, 0, 0],...[0, 0, 0, 0, 0]) # 0は0番目の文章という意味
# print('token_type_ids',token_type_ids.shape) # torch.Size([32, 5])
# 文章IDをベクトル化
token_type_embeddings = self.token_type_embeddings(token_type_ids)
# print('token_type_embeddings',token_type_embeddings) # tensor([[[ 0.0004, 0.0110, 0.0037, ..., -0.0066, -0.0034, -0.0086],
# print('token_type_embeddings.shape',token_type_embeddings.shape) # torch.Size([32, 5, 768])
embeddings = token_embeddings + position_embeddings + token_type_embeddings
# print('embeddings',embeddings) # tensor([[[ 0.0316, -0.0411, -0.0564, ..., 0.0021, 0.0044, 0.0219],
# print('embeddings.shape',embeddings.shape) # torch.Size([32, 5, 768])
# 特徴量ごとに平均と分散を計算しデータの平均と分散をそれぞれ0および1にする
embeddings = self.LayerNorm(embeddings)
# print('embeddings(LayerNorm(embeddings))',token_embeddings) # tensor([[[ 0.0136, -0.0265, -0.0235, ..., 0.0087, 0.0071, 0.0151],
# print('embeddings(LayerNorm(embeddings)).shape',token_embeddings.shape) # torch.Size([32, 5, 768])
# ドロップアウト
embeddings = self.dropout(embeddings)
# print('embeddings(dropout(embeddings))',token_embeddings) # tensor([[[ 0.0136, -0.0265, -0.0235, ..., 0.0087, 0.0071, 0.0151],
# print('embeddings(dropout(embeddings)).shape',token_embeddings.shape) # torch.Size([32, 5, 768])
return embeddings
class MultimodalBertEncoder(nn.Module):
def __init__(self, args):
super(MultimodalBertEncoder, self).__init__()
self.args = args
bert = BertModel.from_pretrained(args.bert_model) # bertモデル
self.txt_embeddings = bert.embeddings # 文章ベクトル
self.img_embeddings = ImageBertEmbeddings(
args, self.txt_embeddings
) # 画像ベクトル(bertっぽさをもたせたやつ)
self.img_encoder = ImageEncoder(args) # 画像情報を画像ベクトルに変換するエンコーダー
self.encoder = bert.encoder # 文章ベクトルに変換するエンコーダー
self.pooler = bert.pooler # encoderの後ろの、各タスクに接続する部分
self.clf = nn.Linear(args.hidden_sz, args.n_classes) # クラス分類する全結合層
def forward(self, input_txt, attention_mask, segment, input_img):
"""
input_txt:単語IDのベクトル
attention_mask:Tramsformerと同じ働きのマスキング
segment:文章の区分となるベクトル。1文のみの場合はsegmentは全て0
input_img:画像情報となるRGB3成分の3次元ベクトル
"""
# 1.マスクの整形
## 1.1 マスクの次元数を「テキストのトークン数+画像の次元数(RGBの3次元)」に整える。つまり[batch_size,seq_length]の形
## 1.2 マスクを[batch_size,1,1,seq_length]の形にする
## 1.3 Attentionを掛けない部分はマイナス無限大にするための処理を加える
# 2.画像ベクトルを生成
## 1.1 画像ベクトル[32, 3, 2048]を取得
## 1.2 整形するためのimgテンソルの箱([32, 5])作り
## 1.3 画像ベクトル[32, 3, 2048]を[32, 5, 768]に整形
# 2.テキストベクトルを生成
## 2.1 単語ID化したテキストをbertで768次元に変換し、テキストベクトル[32, 24, 768]を取得
# 3.画像&テキストベクトルを生成
## 3.1 テキストベクトルと画像ベクトルをcat
## 3.2 マスク処理を加える
# 4.画像&テキストベクトルをpooling層にぶっこむ
bsz = input_txt.size(0)
# batch_cnt = self.args.batch_cnt
# print(('batch_cnt',batch_cnt))
# print(('bsz',bsz)) # ('bsz', 32)
# attention_maskはinput_idが存在する箇所に1が立つ
# print(('attention_mask',attention_mask)) # tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# print(('attention_mask',attention_mask.shape)) # torch.Size([32, 24]))
# [32, 24]のattention_maskに[32, 5]のサイズ1のテンソルをcat(画像の次元とテキストの次元の箱に合わせる的な)
attention_mask = torch.cat(
[
torch.ones(bsz, self.args.num_image_embeds + 2)
.long()
.cuda(), # torch.Size([32, 5]))
attention_mask,
],
dim=1,
)
# print(('attention_mask(torch.cat)',attention_mask)) # tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0],
# print(('attention_mask(torch.cat)',attention_mask.shape)) # torch.Size([32, 29])
# マスクの変形。1番目と2番目の次元を1つ増やし、[batch_size,1,1,seq_length]の形にする
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
# print(('extended_attention_mask',extended_attention_mask)) # tensor([[[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0]]],
# print(('extended_attention_mask',extended_attention_mask.shape)) # torch.Size([32, 1, 1, 29])
# torch.float32に型変換(次の処理でfloatが必要になる)
extended_attention_mask = extended_attention_mask.to(
dtype=next(self.parameters()).dtype
)
# print(('extended_attention_mask(dtype)',extended_attention_mask)) # tensor([[[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]],
# print(('extended_attention_mask(dtype)',extended_attention_mask.shape)) # torch.Size([32, 1, 1, 29])
# Attentionを掛けない部分はマイナス無限大にしたいので、代わりに-10000を掛け算する(なぜこの処理をするのか?)
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# print(('extended_attention_mask(引き算)',extended_attention_mask)) # tensor([[[[ -0., -0., -0., -0., -0., -0., -0.,-0., -0.,... -10000., -10000., -10000.,-10000.]]],
# print(('extended_attention_mask(引き算)',extended_attention_mask.shape)) # torch.Size([32, 1, 1, 29])
# [32, 5]のimgテンソルの箱作り。後に32*3*2048次元の画像ベクトルを32*5*768次元に変換する際に使用する。
img_tok = (
torch.LongTensor(input_txt.size(0), self.args.num_image_embeds + 2)
.fill_(0)
.cuda()
)
# print(('img_tok',img_tok)) # tensor([[0, 0, 0, 0, 0],[0, 0, 0, 0, 0],...[0, 0, 0, 0, 0]]
# print(('img_tok',img_tok.shape)) # torch.Size([32, 5])
# 画像をresnet152で画像ベクトルに変換
img = self.img_encoder(input_img) # BxNx3x224x224 -> BxNx2048
# print(('img',img)) # tensor([[[1.8052, 0.4546, 2.8586, ..., 0.0576, 0.3066, 0.3843],
# print(('img',img.shape)) # torch.Size([32, 3, 2048])
# 3*2048次元の画像ベクトルを5*768次元に変換。bertと同様にCLSとSEPベクトルを追加
img_embed_out = self.img_embeddings(img, img_tok)
# print(('img_embed_out',img_embed_out)) # tensor([[[ 0.1873, -0.3175, -0.3624, ..., -0.0306, 0.0425, 0.1822],
# print(('img_embed_out',img_embed_out.shape)) # torch.Size([32, 5, 768])
# print(('input_txt',input_txt)) # tensor([[ 3608, 2100, 2322, 10376, 7530, 3122, 2184, 5898, 15357, 4524,
# print(('input_txt',input_txt.shape)) # torch.Size([32, 24])
# 単語ID化したテキストをbertで768次元に変換
txt_embed_out = self.txt_embeddings(input_txt, segment)
# print(('txt_embed_out',txt_embed_out)) # tensor([[[-0.1270, -0.6901, -0.6514, ..., -0.5027, -0.1357, 0.1038],
# print(('txt_embed_out',txt_embed_out.shape)) # torch.Size([32, 24, 768])
# テキストベクトルと画像ベクトルを連結
encoder_input = torch.cat([img_embed_out, txt_embed_out], 1) # Bx(TEXT+IMG)xHID
# print(('encoder_input',encoder_input)) # tensor([[[ 0.1873, -0.3175, -0.3624, ..., -0.0306, 0.0425, 0.1822],
# print(('encoder_input',encoder_input.shape)) # torch.Size([32, 29, 768])
# catしたBertEncoder処理をする。encoded_layersは配列で返す。output_all_encoded_layers=Falseにすることで、最終1層のみ返ってくるようにする。
## https://github.com/Meelfy/pytorch_pretrained_BERT/blob/1a95f9e3e5ace781623b2a0eb20d758765e61145/pytorch_pretrained_bert/modeling.py#L239
encoded_layers, attention_probs = self.encoder(
encoder_input, extended_attention_mask, output_all_encoded_layers=False
)
# print(('encoded_layers',encoded_layers)) # [tensor([[[-1.2899e-01, 1.9738e-02, 4.5480e-01, ..., -1.0199e-02],...]]],device='cuda:0', grad_fn=<AddBackward0>)
# print(('encoded_layers',len(encoded_layers))) # 1
# print(('encoded_layers[-1]',encoded_layers[-1])) # tensor([[[-1.0737e-01, -2.5804e-01, 3.6498e-01, ..., 1.3026e-01,
# print(('encoded_layers[-1]',encoded_layers[-1].shape)) # torch.Size([32, 29, 768]
return (
self.pooler(encoded_layers[-1]),
attention_probs,
) # clsベクトルを取得
class MultimodalBertClf(nn.Module):
def __init__(self, args):
super(MultimodalBertClf, self).__init__()
self.args = args
self.enc = MultimodalBertEncoder(args)
self.clf = nn.Linear(args.hidden_sz, args.n_classes)
def forward(self, txt, mask, segment, img):
x, attention_probs = self.enc(txt, mask, segment, img)
return self.clf(x), attention_probs
全体コードはgithubを参照ください
- 画像側のベクトル生成の過程でImageBertEmbeddingsクラスで画像ベクトルサイズ(3, 2048)をbertのhiddenサイズ(3, 768)に圧縮。
- 画像側のベクトルにさらにトークン列の先頭に先頭記号[CLS]、最後に最終記号[SEP]を付与してサイズ(5, 768)のベクトルを作成。
- 画像側のベクトルがBERTベクトルと連結できるように次元数を768次元に揃える。
- 画像ベクトルとBERTベクトルと連結。
- 連結したベクトルをBERTに入力。
- 最後にクラス分類の際は最終層の入力トークン[CLS]ベクトル(0番目のtoken)を用いて分類。
(MultimodalBertEncoderクラスの最後のself.pooler(encoded_layers[-1])で[CLS]ベクトルを抽出)
*[CLS]はBERTにおいて、「classification embedding」と呼ばれ分類タスクで利用されるベクトルです。
分類タスク以外の場合はこのトークンは無視されます。
MMBTの判断根拠の可視化
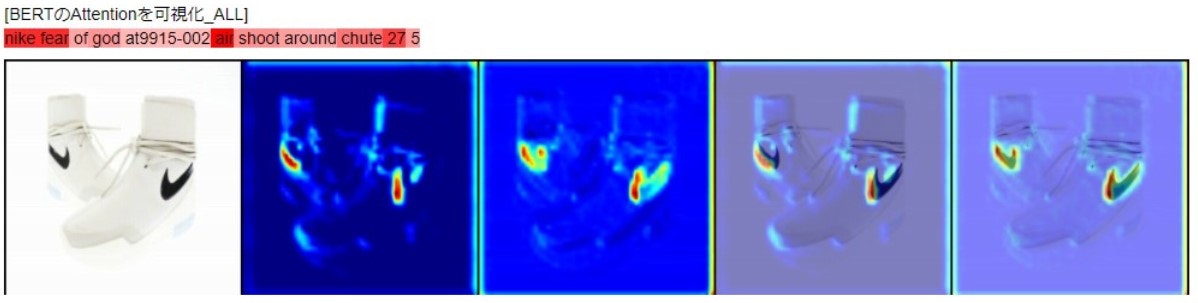
実際のビジネス現場ではモデルの判断に対して一定の説明性が求められます。そこで、MMBTで構築したモデルが分類の際に画像やテキストのどの単語に着目しているか把握するために可視化を行いました。
判断根拠の可視化部分は画像側はGradCam、テキスト側はBERTの12層のAttentionの平均を用いて可視化しています。GradCamやAttention可視化の詳細についてはここでは触れませんが、詳しく知りたい方は下記記事をご覧ください。
※判断根拠の可視化は独自に実装しています。githubにはその機能はありません。
上記の例では、テキスト側のnike,fear,airといった単語が注目され、画像側ではNikeのロゴマークである「スウッシュ(swoosh)」に着目していることがわかります。
このようにMMBTにおいてテキストと画像の双方の特徴を用いて分類していることがわかります。
参考記事リンク
画像分類の際に判断根拠を把握するGrad-CAMをPyTorch(Google Colab)で簡単に使用する
PyTorchによる発展ディープラーニング 8.4 BERTの学習・推論、判定根拠の可視化を実装
苦労した点
BERT理解
自然言語処理の基本はある程度理解していたつもりでしたがBERTの難しさは別格です。しかし、BERTの理解なくしてMMBTを理解することはできませんので気合で勉強しました。
現時点でも自信をもって完璧にBERTの中身を理解しているとはいえませんが、以下の方法である程度は把握できました。
1.歴史的変遷を辿る
まず、BERTとは何かを理解するために歴史的変遷に沿ってword2vec→LSTM→seq2seq→BERTの順にどのような経緯で何が進化していったのか理解するよう努めました。
BERTは従来の言語モデルがベースになっているため、歴史的経緯が分からないとBERTの構造に触れた際に「何でこんなことしてるの?」とその意図が分からず理解が追いつけなくなります。
そのため、BERT以前の過去の言語モデルについても必然的に理解しておく必要がありました。
2.データサイエンスVtuber アイシアさんの自然言語処理シリーズ
歴史的変遷を学んだ後にいよいよBERTの中身に入ります。
私の場合BERTの構造を理解する際に、テキストベースの解説ではなかなかイメージが掴めませんでした。
直感的に理解できるよう動画を探し求めるうちにアイシアさんのyoutubeチャンネルに辿りつき、肝であるTransformerのAttention層におけるQuery-Key-Valueモデル(self-attention)については、Transformer - Multi-Head Attentionを理解してやろうじゃないのを何度もリピート視聴してようやく理解できました。
自然言語処理シリーズでは網羅的に扱ってくれて数学的な解説も豊富なので中級者層にとっては親しみやすいコンテンツだと思います。
3.つくりながら学ぶ!PyTorchによる発展ディープラーニング
その後、コードレベルで理解するためにつくりながら学ぶ!PyTorchによる発展ディープラーニング(以下Pytorch本と略します)のコードで1行1行何をしているのか追っていきました。BERTを勉強をはじめた初期に読んだ際はちんぷんかんぷんでしたが、BERTの全体像がある程度分かった後に改めて読むと意外にすんなりと頭に入っていきました。
Pytorch本でもかみ砕いて解説してくれてありがたいのですが、前提知識があるとサクサク読み進めることができるので学習効率は上がるように思います。
参考記事リンク
RNNからTransformerまでの歴史を辿る ~DNNを使ったNLPを浅く広く勉強~
つくりながら学ぶ!PyTorchによる発展ディープラーニング
[【深層学習】Attention - 全領域に応用され最高精度を叩き出す注意機構の仕組み【ディープラーニングの世界 vol. 24】]
(https://www.youtube.com/watch?v=bPdyuIebXWM)
【深層学習】Transformer - Multi-Head Attentionを理解してやろうじゃないの【ディープラーニングの世界vol.28】
【深層学習】BERT - 実務家必修。実務で超応用されまくっている自然言語処理モデル【ディープラーニングの世界vol.32】
MMBT理解
BERTを理解するだけでお腹いっぱいでしたが、ここからが本番です。
MMBTについても全体像の俯瞰から詳細を理解するのに苦労しました。
1.MMBT論文全文翻訳
MMBTを理解するには論文精読が必須ですが、当然ながら全て英語ですのでDeepLを使って全文翻訳に取り組みました。
丸一日程掛かりましたが、全文翻訳をしたことでいつでも見返すことができとても役立ちました。
翻訳内容は下記qiitaにまとめていますので、お時間に余裕のある方はご参照ください。
【論文翻訳】MMBT(MultiModal BiTransformers)【マルチモーダルDL】
※DeepLを翻訳をベースに必要に応じて意訳しています。
2.元のMMBTのgithubでコードを実行
MMTBが手元で動かないと話にならないのですが、データセットを所定の場所から自分でダウンロードしたり、既存コードのままだと動かなかったりとハマりました。
その後、自社データセットでも通るようにするのですが、データの持ち方が当然異なるため、そこを合わせるためにコードやデータの微調整の必要があり、一定の時間を要しました。
3.MMBTのlayerを出力
MultimodalBertEncoderクラスのforward以下のレイヤーの値と次元(shape)をprintして出力し、コード1行1行についてテンソルがどのように変化する追跡しました。地道な作業でしたが、目の前で数値や次元が変化している様を確認するとコードの意図が理解できるようになるのでやって良かったです。
おわりに
今回は容易に実装可能なマルチモーダルとしてMMBTを紹介いたしました。
今回の記事の執筆に際して、早速実務のECサイトの商品分類活用したところ、論文の通り従来のBERT単体やResnet単体よりも精度が高く、実サービスに採用することが決まりました。
MMTBの細部まで理解するのは大変ですが、各々のデータセットで実験すること自体は容易ですので、気軽に試せるのでは思っております。
本記事をきっかけにMMBTを様々な場面で活用いただけましたら嬉しく思います。最後までお読みいただきありがとうございました。
本記事ではMMBTの解説のメインに扱いましたので、次回は判断根拠の可視化部分も含めた実行コード全体の解説記事を執筆する予定です。