はじめに
マルチモーダル・ディープラーニングについて自身の学習のためにmmbtの論文の翻訳にチャレンジしてみました。
基本的にはDeepLで翻訳した上で私の解釈で意訳をしていますが、至らない点も多々あるかと思いますので、その際にはご指摘頂けますと幸いです。
引用:Supervised Multimodal Bitransformers for Classifying Images and Text
概要
BERTのような自己教師付きの双方向性変換モデルは、多種多様なテキスト分類タスクにおいて劇的な改善をもたらしました。
しかし、現代のデジタル世界はますますマルチモーダル化しており、テキスト情報には、画像などの他のモダリティが付随していることがよくあります。本論文ではマルチモーダルのためのシンプルで効果的なベースラインを紹介します。
本論文では、マルチモーダル BERT ライクなアーキテクチャのためのシンプルかつ効果的なベースラインとして、教師付きのマルチモーダル・バイトランスフォーマーを紹介します。
MMBTは、テキストを多用するマルチモーダル分類タスクにおいて、標準的な精度に近づき、あるいはそれに匹敵する精度を得ることができました。
マルチモーダル性能を測定するために特別に設計されたハードなテストセットを含めて、強力なベースラインを上回る精度を達成しました。我々の手法は、自己教師付きマルチモーダル「視覚と言語のためのBERT」アプローチであるViLBERTと競合する一方で、驚くべきことに、よりシンプルで拡張性が高く簡単に拡張することができます。
1 Introduction
現代のデジタル世界で直面する分類問題の多くは、マルチモーダルな性質を持っています。
ウェブ上のテキスト情報が単独で存在することはほとんどなく、多くの場合、画像、音声、動画、その他のモダリティを伴っています。
BERT(Devlin et al., 2019)など、自然言語処理のための表現学習の最近の進歩によりテキストのみの分類問題は劇的に改善しました。
そして、BERTの成功を受けて、下記のような様々なマルチモーダル・アーキテクチャが提案されています。
・ViLBERT(Lu et al., 2019)
・VisualBERT(Li et al., 2019)
・LXMERT(Tan andBansal, 2019)
・VL-BERT(Su et al., 2019)
これらは、目前のマルチモーダルタスクでのファインチューニングの前に、中間または代理のマルチモーダルタスクでのプレトレーニングを提唱しています。
本論文では、BERT のようなマルチモーダル・アーキテクチャのためのシンプルかつ非常に効果的なベースライン・ アーキテクチャについて説明します。
マルチモーダル融合に優れており、様々な代替融合技術よりも優れていることを実証します。
また、その性能は、様々なマルチモーダル融合技術において、マルチモーダルに事前学習されたViLBERTモデルを凌駕することができます。
我々の提案するアプローチにはいくつかのメリットがあります。
・ユニモーダルに事前学習されたモデルは、よりシンプルで単峰性の進歩に適応するのが容易です。
・テキストや画像のエンコーダーをより良いものに置き換え、直接fine-tuningすることが簡単にできます。
・マルチモーダルな再トレーニングを必要としません。
・特定の特徴抽出パイプラインに依存せず、モダリティにもとらわれません。
したがって,生の画像の特徴を計算するために特徴を事前に抽出するのではなく,生の画像の特徴を計算して,エンコーダ全体にバックプロパゲートするために使用することができます。
※原論文から転載しています
具体的には、我々のモデルは BERTを前提にしており 、高密度のマルチモーダル特徴を BERT のトークン埋め込み空間にマッピングすることを学習します。
これを学習して、高密度のマルチモーダル特徴を BERT のトークン埋め込み空間にマッピングします。
このアプローチはテキストを多用する3つのマルチモーダル分類タスクでうまく機能することを示しています。
・MM-IMDB (Arevalo et al., 2017),
・Food101 (Wang et al., 2015)
・V-SNLI (Vu et al,2018).
これらのタスクで評価すると、いくつかのメリットがあります。インターネット上の多くの実世界のマルチモーダルタスクテキストが明らかに優位なモダリティであることが多く、目標はインターネットデータの質問に答えるのではなく、単一の分類ラベルを予測することです。
重要なのは、例えば以下のような場合です。
VQA (Antol et al., 2015) とは対照的に、これらのタスクはマルチモダリティではまだ広く研究されていません。
マルチモーダル変換の文献では、これらのタスクはまだ広く研究されていません。私たちの研究では、このようにしてVQAのマルチモーダルな進歩がこれらのようなタスクにも及ぶかどうかを確認することができます。
最後に、マルチモーダル・モデルに求められる特性としてマルチモーダル・モデルに求められる特性は高品質のマルチモーダル情報が得られる場合マルチモーダル・モデルの望ましい特性は、高品質のマルチモーダル情報が利用可能な場合に性能が向上することです。すなわち、全体が部分の和を厳密に上回ることである。我々はこれらの課題を用いてマルチモーダル性能を測定するために特別に設計された新しいハードテストセットを構築しました。
その結果、提案された教師付きマルチモーダル・バイトランスフォーマーモデルは、他の様々な競合融合技術に比べて提案された教師付きマルチモーダルバイトランスフォーマーは、他の様々な競合する融合技術をより多くのパラメータを与えても、他の競合する融合技術を上回ることがわかりました。我々はこれは、マルチモーダル・バイトランスフォーマーが、両方のモダリティに対して同時にSelf-Attentionを働かせることができることによるものです。
これは、マルチモーダルバイトランスフォーマーモデルが、両方のモダリティに同時にSelf-Attentionを働かせ、より早く、より細かいマルチモーダル、より早く、より細かいマルチモーダルフュージョンが可能になるからです。その結果、私たちの簡単な手法はマルチモーダルに事前学習されたViLBERTモデルに近づき、肩を並べることがわかった。
タスクにおいて、マルチモーダルに事前学習されたViLBERTモデルに近づき、肩を並べるということがわかりました。別の言い方をすれば、**「マルチモーダルな事前学習をしなくても、マルチモーダルな事前学習をしたモデルの性能に匹敵する」**と言えます。
もしくは、「マルチモーダルな事前学習を行わなくても、マルチモーダルな事前学習を行ったモデルと同等の性能を得ることができる」とも言えます。
これらの結果から、mmbtは、実装が簡単で、拡張(異なるモダリティへの拡張)が容易であるため、マルチモーダル分類における将来の研究のための強力なベースラインとなることがわかります。
mmbtは異なるモダリティやエンコーダーへの拡張が容易であり,より洗練された手法と比較しても遜色のない性能を発揮します。
2 Multimodal Bitransformers
自然言語処理やコンピュータビジョンの分野では、事前に学習された表現からの伝達学習が長い歴史を持っています。
事前に学習された表現からの伝達学習には長い歴史があります。自己教師付きの単語や文の埋め込み(Collobert and Weston, 2008; Mikolov et al., 2013; Kiros et al., 2015
は、自然言語処理においてユビキタスになっています。コンピュータビジョンでは、教師付きImageNet特徴量からの転送がデファクトスタンダードになっているin computer vision (Oquab et al., 2014; Razavianet al., 2014)。)
自然言語処理においても教師付きデータが有用であることが証明されており、普遍的な文の表現に有用であることが証明されていますが(Conneau et al.2017)、この分野に革命をもたらしたのは自己教師付き言語モデリングシステムをファインチューニングするというモデリングシステムです(Dai and Le, 2015)。
言語モデリングは、システムが文脈に応じてEmbeddingを学習し文脈に応じた方法で学習することができ、さまざまなタスクのパフォーマンス向上につながります(Peters et al;Howard and Ruder, 2018)。) トランスフォーマー学習(Vaswani et al., 2017)で膨大なデータを学習させると、さらに優れた結果になりました(Radfordら、2018)。
BERT (Devlin et al., 2019) はこれをさらに改良し、トランスフォーマーを双方向にトレーニングすることで(これをバイトランスフォーマーと呼ぶ)、対象をマスキングに変更することで、さらに改良しました。
対象をマスキングに変更したことで、多くのタスクで最先端の性能を発揮しています。
本研究では、自然言語処理によるテキストのみの自己教師付き表現と、マルチモーダルなバイトランスフォーマーを組み合わせた、分かりやすくかつ効果の高いモデルを紹介します。
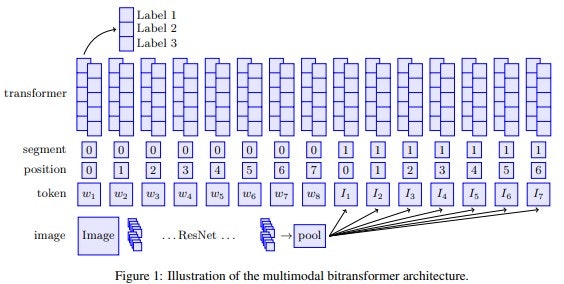
自然言語処理の自己教師付き表現とこのモデルは、自然言語処理から得られるテキストのみの自己教師付き表現と、コンピュータビジョンから得られる最新の畳み込みニューラルネットワークアーキテクチャを組み合わせたものです。図1をご覧ください。
以下では、各コンポーネントの詳細を説明します。
2.1 Image Encoder

※原論文から転載しています
コンピュータビジョンでは、事前学習された畳み込みアルゴリズムの最後の全連結層(事前学習された畳み込みニューラルネットワークのニューラルネットワークの最後の全連結層を転送するのが一般的です(Razavian et al, 2014))の結果として出力されます。しかし,マルチモーダル・バイトランスファーでは,このプーリングは必要ありません。
マルチモーダルバイトランスファーでは、任意の数の密な入力を扱うことができるため、このプーリングは必要ありません。
そこで、プーリングの結果、1つの出力ベクトルではなく、N個の出力ベクトルが得られるようにしてみました。
一つの出力ベクトルではなく、N個の別々の画像を埋め込むことができます。この場合、ResNet-152(He
et al., 2016)を用いて、画像中のK×M個のグリッドに対するアベレージプーリングを行いました。
画像中のK×M個のグリッドをアベレージプーリングして、N=KM個の出力ベクトルが得られます。画像は,リサイズ,センタークロップ,正規化されています。
2.2 Multimodal Transformer Input Layer
事前に学習されたBERTの重みで初期化された双方向変換モデルを使用しています。このアーキテクチャは,文脈上の埋め込みを入力とし,その際に各コンテクストエンベッディングは、D次元のセグメント、位置、および各コンテキストエンベッディングは、独立したD次元のセグメント、位置、トークンエンベッディングのトークンエンベッディングの合計として計算されます。我々は、重みWn∈R^P×Dを学習し、N個の画像埋め込みのそれぞれをD次元のトークン入力埋め込み空間に投影します。
I_{n} = W_nf(img,n)
f(-, n)は、画像エンコーダーの最終プーリング操作のn番目の出力です。
1つのテキストと1つの画像の入力で構成されるタスクの場合、テキストと画像埋め込みにはそれぞれ別のセグメントIDを割り当てます。
私たちは、0から数え始めるポジションコーディングを採用しています。これを各セグメントに割り当てます。このアーキテクチャは、任意の数のモダリティに簡単に一般化できます。
3つの入力からなるV-SNLIタスクで示すように、このアーキテクチャは任意の数のモダリティに簡単に一般化できます。
事前に訓練されたBERT自体は2つのセグメントエンベッディングしか持っていないため、追加のセグメントエンベッディングを初期化します。
S_i = \frac{1}{2}(S_0+S_1)+ ε
この時のSiは、下記の範囲を取ります。
i >= 2 \quad\cap\quadε~N(0,1e^{-2})
なお我々の手法は,モダリティが欠損している場合(すなわち,テキストのみ,あるいは画像のみの場合)にも対応できることも着目すべき点です。
2.3 Classification
最終層の最初の出力を分類層の入力として使用します。
clf(x) = W_x + b\quad W∈R^{D×C}
Dは変換次元,Cはクラスの数です。マルチラベルの場合複数の正解があるようなタスクの場合はロジットにシグモイドを適用して推論時には、閾値を0.5に設定します。
マルチクラスのタスクでは、ロジットにソフトマックスを適用して通常のクロス・エントロピー損失で学習します。
2.4 Pre-training
画像エンコーダは,ImageNetを使用しています。我々は、ResNet-152の実装と、PyTorchで利用できるウェイトを介してtorchvisionを使用しています。我々は、事前に訓練された12層の768次元ベースのBERT用モデル、英語版Wikipediaで学習したものを使用しています。
2.5 Fine-tuning
私たちのアーキテクチャは、事前に学習されたコンポーネントと、ランダムに初期化されたコンポーネントが混在しています。
NLPではBERTは全体的にFine-tuningされるのが一般的であり固定パラメータを持つエンコーダとして転送されません。
例えば、SkipThought(Kiroset al., 2015)やInferSent(Conneau et al., 2017)などで使用されていました。
コンピュータビジョンでは、コンボリューショナルネットワークは固定されていることが多いのですが畳み込みネットワークのフリーズを解除すると
例えば、
・画像キャプション検索(Faghri et al., 2017)
・マルチモーダルの最適化は些細なことではない(Wanget al., 2019)
我々のモデルでは、画像エンベディングはランダムに初期化されたマッピング W~n のセットを使用してBERTのトークン空間にマッピングされます。
ここでは、複数のモダリティにまたがる最適化のためのシンプルな解決策を検討します。
すなわち、「異なる段階での符号化コンポーネントのフリーズとフリーズ解除」をハイパーパラメータとして扱うこと検討します。
まず、画像の埋め込みをテキストエンコーダの入力空間の適切な部分空間にマッピングすることを最初に学習すれば、ネットワークが視覚情報をより多く利用することが期待できます。テキストモダリティが支配的になる可能性が高いため、視覚的モダリティにチャンスを与えたいと考えています。

※原論文から転載しています
3 Approach
このセクションでは、データセット、ベースライン、その他の実験の詳細について説明します。
3.1 Evaluation
マルチモーダルな分類タスクの多様なセットで評価します。同じく2つのタスクと比較します。
(Kiela et al., 2018)で使用されているMM-IMDB(Arevaloet al., 2017)とFOOD101(Wang et al., 2015)です。
このアーキテクチャが2つの入力タイプを超えて一般化することを説明するためにさらに、(premise.hypothesis, image)トリプレットで構成されるVSNLI(Vu et al., 2018)で評価します。
hypothesis, image)のトリプレットで構成されています。データセットについては表1、例題については表2の統計情報と、表2の例を参照してください。
MM-IMDB
MM-IMDBデータセット(Arevaloet al, 2017)は、映画のプロットのアウトラインと映画ポスターです。各映画をジャンル別に分類することが目的ですがこれはマルチラベルの予測問題であり,1つの映画が複数のジャンルを持つこともあります。
このデータセットは、特に(Arevaloet al., 2017)が、高品質なマルチモーダル分類データセットの相対的な希少性に対処するために導入したものです。
FOOD101
UPMCのFOOD101データセット(Wanget al, 2015)には、101の食品ラベルのテキストによるレシピ説明が含まれています。
レシピはWebページからスクレイピングされ、ウェブページからスクレイピングし,その後,テキストデータを抽出するためにクリーニングを行いました。
各ページは,1枚の画像と照合され,画像は,Google Image Search で,指定されたカテゴリを検索して得られたもの(ノイズが多いかもしれない)です。目的はレシピと画像の組み合わせに対応する食品ラベルを見つけることです。
V-SNLI
V-SNLIデータセットは、以下のものをベースにしています。
SNLIデータセット(Bowman et al., 2015)を使用し、目的は,前提条件と仮説を,関連する画像とともに分類することです。
関連する画像と一緒に、3つのカテゴリー、すなわち、内包、中立、矛盾のいずれかに分類することです。
SNLIデータセットは,キャプションから得られた前提条件に対して,ターカーが仮説を提供することで作成されました。
Flickr30kデータセット(Young et al., 2014)(Vu et al,2018)は、元の画像と前提・仮説のペアを元に戻して、以下のようなV-SNLIと呼ばれる根拠のあるエンテイルメントタスクを開発しました。V-SNLIは、もともとSNLI用に作成されたテストセットのハードサブセットも用意されており、仮説のみの分類器が失敗します(Gururangan et al.2018)。
3.2 Baselines
強力なユニモーダル・ベースラインとの比較、およびより洗練されたマルチモーダル融合手法との比較も行っています。
マルチモーダル融合手法との比較を行いました。いずれの場合も,単一の線形分類器を使用し,モデル全体をエンドツーエンドでfine-tuningします。
それでは、次にそれぞれのベースラインについて説明します。
Bag of words (Bow)
300次元の合計を行うGloVe embeddings (Pennington et al., 2014) (Common Crawl) をテキスト中のすべての単語について、視覚的特徴を無視して合計します。
視覚的特徴を無視して、分類器に与えます。
Text-only BERT (Bert)
事前に訓練されたベース・アンクセスドの最終層の最初の出力を
の最終層の最初の出力を分類器に与えます。
BERTモデルの最終層の最初の出力を分類器に与えます。
Image-only (Img)
ここでは, average-poolingを行った標準的な事前学習済みのResNet-152を出力としました。
各画像に対して2048次元のベクトルを生成し、これを他のシステムと同様に分類します。
Concat Bow + Img (ConcatBow)
BowベースラインとImgベースラインの出力を連結しています。
連結は、マルチモーダル手法の強力なベースラインとしてよく使われます。
マルチモーダルな手法では、強力なベースラインとして使われることがあります。この場合、分類器への入力は分類器の入力は2048+300次元です。
Late Fusion
最高のBert分類器とImg分類器のスコアを平均して、最終的な予測値を求めます。
FiLMBert
私たちは、FiLM(Perez et al,2018)とBERTを組み合わせて、BERTモデルが予測する
ConvNet分類器の特徴ごとのゲインとバイアスを予測します。固定されたResNet-152の特徴を入力として使用します。
Perezら(2018)と同様に、ConvNetの入力として固定のResNet-152の特徴を使用しています。
Concat BERT + Img (ConcatBert)
BertベースラインとImgベースラインの出力を連結しました。この場合,分類器への入力は
2048+768-dimensions. このベースラインは、各モダリティに最適なエンコーダを組み合わせ、分類器が直接アクセスできるようにしているため、競争力があります。
各モダリティに最適なエンコーダを組み合わせ、分類器がエンコーダの出力を直接エンコーダーの出力に直接アクセスできるようになっています。
3.3 Making the Problem Harder
多様なマルチモーダル分類タスクで評価していますが、この種の高品質なタスクは意外と少ないです。
多くの場合、テキストモダリティが過度に支配的であり(これはVQA[Goyal et al.,2019]においても問題になっていますが、)
マルチモーダルな手法の違いを明確にすることが難しく、また、マルチモーダルな手法を取り入れることが、そもそもマルチモーダルな情報を取り入れる価値があるのかどうかを見極めることも難しいのです。先ほど観察したようにGururanganら(2018)は、SNLIデータセットのハードサブセットを作成しました。
SNLIデータセットでは、仮説のみのベースラインでは正しく分類できなかったことを修正しています。
ここでは、同様のアプローチに従い、ハードなマルチモーダルテストセットを作成しました。
ハードテストセットは,テストセット内のBertおよびImg分類器の予測値がグランドトゥルースのクラスと最も異なる例を取ることで構築します。
つまり、
p(a \neq t|I)p(a \neq t|T)
を最大化する例を選び、ハードテストセットを構築します。
ここで,IとTはそれぞれ画像とテキストの情報であり,aは予測された答え,tは正解である.我々は 最も差のある例の上位10%を新しいテストセットのハードケースとして 新しいテストセットのハードケースとします。これは、次のような考え方に基づいています。
これらの例は,より高度なマルチモーダル推論を必要とする例であり,マルチモーダルに特化した性能をよりよく調べることができると考えています。
マルチモーダルに特化したパフォーマンスを検証することができます。
3.4 Other Implementation Details
すべてのモデルにおいて、マルチクラスデータセットでは学習率と検証精度の early-stopで掃討し、マルチラベルデータセットではMicro-F1は、マルチラベルデータセットに対して行いました。さらに、テキストエンコーダーと画像エンコーダーを固定するためのエポック数と、入力として使用する画像エンベディングの数を変更します。Bertモデルには、ウォームアップ率0.1のBertAdam(Devlin et al.2019)を使用し、その他のモデルには通常のAdam(Kingma and Ba, 2014)を使用します。すべてのデータセットがバランスされているわけではないのでクラスラベルをその逆の頻度で重み付けしています。コードとモデルはオンライン(github)で入手可能です。
4 Results
主な結果を表3に示します。
各ケースにおいてそれぞれのケースで,ランダムな種を使って5回実行したときの平均性能を標準偏差を示しています。
MM-IMDBとFOOD101に関する(Kiela et al,2018)のMM-IMDBとFOOD101の結果と比較し、次のことがわかりました。
2つの入力モダリティの一方をシグモイド化し、もう一方の入力をバイリニアにゲートする、つまり外積を取ることで、バイリニアゲートモデルが最もうまくいくことがわかりました。なお、このモデルは2048次元のResNet出力と768次元のBert出力を持つ我々のケースでは
と768次元のBert出力がある場合、バイリニアにゲートされたの場合、2048×768×101次元の出力層(上の分類器のパラメータだけで約158Mのパラメータが)が必要になるため、実用的ではありません。
MM-IMDBでは、Gatedマルチモーダルユニット(Arevalo et al., 2017)との比較も行っています。
それは、マルチモーダルフュージョンのために特別に設計されたリカレントユニット(これも同様に、1つのmodality gate over the other)と比較しています。加えて、我々は
CentralNet (Vielzeuf et al., 2018)と比較します。
マルチモーダルフュージョンのための多層アプローチで、現在このデータセットで最先端を保っています。それについては、以下の通りです。
FOOD101については、オリジナルの結果を含む論文(Wang et al., 2015)から得られたものです。
word2vecとVGGNetの特徴量を連結してして分類しています。V-SNLIについては、以下のように比較しています。
最先端のVisual Bilateral Multi-Perspective(Vu et al., 2018)のV-BiMPM(Matching)モデルを使用しています。
その結果、マルチモーダル・バイトランスフォーマー(MMBT)がベースラインを大幅に上回ることがわかりました。後期融合では、FiLMBertとConcatBertが同程度の性能を示した。我々は、MMBTがベースラインよりも向上した要因は、また、MMBTがConcatBertを上回った要因は、異なるモダリティからの情報を、最終層だけでなく、self-attentionを介して
最終層だけではなく、様々なレベルで異なるモダリティの情報を相互作用させることができるからだと推測しています。改良の一部は、Bertの優れた性能から来ています(これは
しかし、それにしてもMMBTはBertに比べて、例えば、MM-IMDB Macro-F1とMM-IMDB Macro-F2で約3%向上しました。
MM-IMDB Macro-F1では約3%、Food101では約6%の改善が見られました。
Food101では約6%の改善が見られました(例:1300例の追加)。
つまり、すべてのケースでマルチモーダルモデルは、ユニモーダルモデルよりも優れていました。
※原論文から転載しています
4.1 Hard Testsets
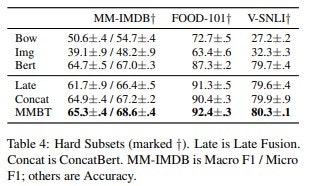
表4は,ハードテストセットの結果を示している.これらのテストセットは,
これらのテストセットは,単一モーダル(BertとImg)の分類器がグランドトゥルースから最も乖離した例を選んで作成されたことを思い出してください.
つまり,これらの結果は,真のマルチモーダル性能に関する洞察を提供するものです。また、VSNLIhard(Gururangan et al.2018)の結果も報告します。
主要な結果と同様のパターンが観察され、MMBTが代替案を上回る結果となりました。
なお、V-SNLIhardでは、Vuら(2018)の報告によるとスコアは73.75で、我々の80.4と比較して、彼らの最高性能のアーキテクチャです。また、興味深いことにそのハードなテストセットでは、画像のみの分類器がテキストのみの分類器をすでに上回っていました。
これは、通常の(ハードではない)V-SNLIではあり得ないことです。
(V-SNLIテストセットではそうではありません。)
4.2 Freezing Strategy
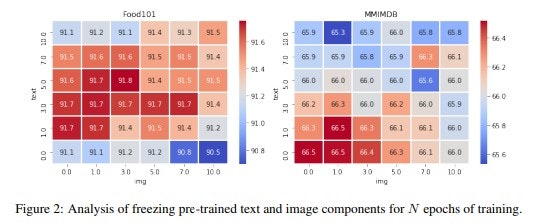
最初に異なる事前学習済みのコンポーネントをフリーズさせることが有効かどうかを分析します。
フリーズは、画像空間からトランスフォーマーの期待されるトークン入力空間へのマッピングを学習する際に役立ちます。
言い換えれば、ランダムに初期化されたコンポーネントを最初に学習することができます。次に画像エンコーダをフリーズ解除して、画像情報を最大限に利用できるようにしてから、バイトランスファーをフリーズ解除して、システム全体をタスクに合わせて調整します。
タスクに合わせてシステム全体を調整します。図2はその結果を示したもので、コンポーネントを組み合わせることを最初に学び、次にそれを解除することが有用であるという直感を裏付けています。
コンポーネントの組み合わせを学び、次に画像エンコーダをアンフリーズして、その後で、事前に学習されたbitransformerのフリーズを解除することが有効であるという直感を裏付けています。
最適なエポック数はタスクに依存しますが、画像エンコーダのフリーズ解除を早期に行うことが最も効果的です。
4.3 Number of Parameters
マルチモーダル・バイトランスファーがConcatBertよりも優れた性能を発揮した理由としては、パラメータの数が若干多いことが考えられます(すなわち、2048×Dを追加したのに対し、2048×Nを追加したことになります)。
ここで、Dは埋め込み次元数、Nはクラスの数)、その差はわずかですがパラメータ数は168M対170Mとわずかな差です。これを調べるために、ConcatBert2層および3層のマルチレイヤー・パーセプトロン
(MMBTの単層のロジスティック回帰ではなく、2層および3層の多層パーセプトロン(MLP)分類器を搭載したConcatBertとの比較も行いました。
MMBTでは単層のロジスティック回帰を用いています。MM-IMDBの場合。
ConcatBert-2とConcatBert-3は、Macro-F1
が60.21±0.5と59.71±0.4、Micro-F1が65.08±0.3と64.82±0.2でした。
Food101では、91.13±.2と90.27±.2となりました。
このことから(表3参照)、すでに高い競争力を持つベースラインにさらにパラメータを与えた場合でも、MMBTがConcatBertよりも優れていることが明らかになりました。
これは、すでに高い競争力を持つベースラインに、さらに多くのパラメータ
より深い分類器を使用した場合でも、MMBTがConcatBertよりも優れているということです(表3参照)。この結果から、**「ConcatBertはオーバーフィッティングの傾向が強い」**ということを示唆しています。
4.4 Robustness to Missing Modalities
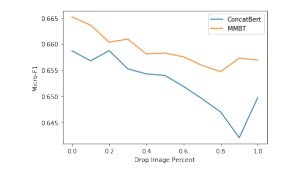
ConcatBertとMMBTを、データセットのサブセットのみに画像があるという設定で比較します。
データセットのサブセットにしか画像がない場合に、ConcatBertとMMBTを比較します。
我々の知る限り「先験的には2つのモデルのうちどちらがこのようなデータ環境に強いのか」については文献で十分に検討されていませんでした。
今回の実験では、中間レベルの融合と、MMBTが提供するより洗練されたタイプの融合を比較するための有用な一面を提供します。
この実験は、中間レベルの融合とMMBTが提供するより洗練された融合を比較するための有用な材料となります。図3は、画像数が少ないほど性能が低下することを示しています。
MMBTが画像の欠落に対してConcatBertよりもはるかに強いことが興味深いです。
※原論文から転載しています
4.5 Comparison to ViLBERT
ユニモーダルに学習されたコンポーネントを融合させることの有効性を前もって学習されたコンポーネントを融合することの有効性を、自己教師付きのマルチモーダル前もって学習されたモデルと比較することで検証します。我々はViLBERT (Lu et al., 2019) をそのクラスのモデルの典型的な例とします。
そのクラスのモデルの典型的な例として取り上げます。ViLBERTは画像とキャプションに対してマルチモーダルに学習されており「視覚と言語のBERT」であることを意味しています。
このモデルは、Faster RCNNで抽出されたバウンディングボックスを使用していますが、学習中は固定されています。このような、やや非日常的なタスクに焦点を当てたことは、実りあるものとなりました。
これらのモデルを同じ土俵で比較することができるからです。
表5にその結果を示します。比較対象は様々なViLBertモデルと比較していますが、標準的な事前学習済みバージョンと、VQAのような特定のタスクのためにfine-tuningされたバージョンの両方があります。
VQAのような特定のタスクのためにfine-tuningされたバージョンがあります。
後者のアプローチは、ViLBertのオリジナル論文では提案されていませんが、同様の「2段階の事前学習」アプローチは、ユニモーダル・タスクのBERTのfine-tuningに有効であることが証明されています。
(Phang et al., 2018)があります。その論文で使われているハイパーパラメータセットを使ってチューニングします。(バッチサイズ、学習率)∈{(64, 2e-5),(256, 4e-5)}。
我々の素直なMMBTモデルは、驚くほど競争力があることがわかります。MM-IMDBではMacro-F1については、タスク固有のViLBERTモデルに匹敵します。
マルチモーダル性能をより正確に測定するデータセットのHardサブセットにおいて、MMBTは
はViLBertのパフォーマンスと一致しました。また、FOOD-101,FOOD-101でも同様の結果となりました。
特にHardサブセットでは、タスクに特化したモデルを凌駕することもありました。
今回の結果から、マルチモーダルの自己学習には改善の余地があること、そしてコンポーネントの教師あり融合は、非常に競争力があることを示唆しています。
制約条件によっては、我々の方法がより好ましいかもしれません。
アーキテクチャに組み込むのは簡単です。この点を説明するために(明らかに公正な比較ではありませんが
この点を説明するために(明らかに公正な比較ではありません)、代わりにBERT-Largeモデルを使用して、MMBTがViLBERTを上回るようにしています。
これは、我々の設定では些細なことですが、ViLBERTの場合は、ゼロからの再学習が必要です。
5 Related Work
トランスフォーマー(Vaswani et al, 2017)を用いて分類のためにシーケンシャルデータをエンコードするために言語モデリングまたは言語マスキングのために事前に訓練し、その後にfine-tuningすると大きな成功を収めます(Radford et al.
マルチモーダルフュージョンをどのように効果的に行うかという問題には長い歴史があります(Baltrusaitis et al,2019).
コンカチネーションがデフォルトと考えられますがしかし、他の融合方法も検討されています。
例えば、語彙表現学習のために(Bruniet al., 2014; Lazaridou et al., 2015)。
分類では、Kielaら(2018)が様々な融合を検討しています。
事前に学習した固定表現に対する融合手法を検討しは、ゲーティングを用いたデータの双線形結合が最も効果的であることを見出した。私たちの教師付きマルチモーダルバイトランスフォーマーは、モダリティ間の融合を介して融合しています。
マルチモーダルNLPの用途は以下の通りです。
マルチモーダルNLPの応用は、分類からクロスモーダル検索まで多岐にわたります(Westoneet al., 2011; Frome et al., 2013; Socher et al., 2013)から、画像キャプション(Bernardi et al., 2016)、視覚的な質問応答(Antol et al., 2015)、マルチモーダル機械翻訳(Elliott et al., 2017)などがあります。
マルチモーダルな情報は、学習にも役立つ人間らしい意味表現(Baroni, 2016;Kiela, 2017)。) マルチモーダル・バイランスフォーマーが提供する効果的に深い融合手法となるもの。関連する深層融合法には、マルチモーダルトランスフォーマー(Tsai et al., 2019)、CentralNet(Vielzeuf et al,2018)、MFAS(Perez-R ´ ua et al. ´ , 2019)、TensorFusion Networks(Zadeh et al.、2017年)があります。
これまでにも多数の自己教師付きマルチモーダルアーキテクチャーが最近発表されており、例えばViLBERT(Lu et al., 2019)、VisualBERT(Li et al,2019)、LXMERT(Tan and Bansal, 2019)、VLBERT(Su et al., 2019)、VideoBERT(Sun et al,2019)などがあります。私たちのモデルは、これらとは異なります。
我々のモデルは、これらの自己教師付きアーキテクチャーとは異なり、個々のコンポーネントはユニモーダルにのみ事前学習されます。これにはこれには長所と短所があります:我々の方法は単純で直感的で、既存の自己監視型エンコーダにも簡単に実装できます。既存の自己教師付きエンコーダにも簡単に実装でき、素晴らしい改善が得られます。向上します。新しい優れたテキストやビジョンモデルが出てきたらモデルが出てくれば、コンポーネントを簡単に交換することができます。
一方で、自己学習時にマルチモーダルな情報を十分に活用することはできません。
マルチモーダルな情報を活用することはできません。とはいえ、潜在的には膨大な数のユニモーダルデータにアクセスできる可能性があります。つまり言い換えれば、これらの教師付きマルチモーダル・バイランスフォーマーは、自己教師付きマルチモーダル事前トレーニングが実際にどの程度行われているかを評価するための強力なベースラインとなるはずです。
マルチモーダルの事前トレーニングが実際に役立つかどうかを評価するための強力なベースラインとなるはずです。
6 Conclusion
本論文では、教師付きのマルチモーダル・バイトランスフォーマー・モデルを導入しました。このモデルを用いて様々なタスクにおいて,いくつかのベースラインと比較しました。
マルチモーダル性能を検証するために特別に作成されたハードテストセット(ユニモーダル性能では失敗するような場合)で性能が発揮できない場合)を含め,さまざまなタスクでベースラインと比較しました。) その結果、提案したアーキテクチャ(mmbt)は、既存の技術を大幅に上回る性能を発揮しました。
既存の技術や強力なベースラインを大幅に上回ることがわかりました。我々は次に、マルチモーダル最適化の分析を行い、フリーズ/フリーズ解除戦略を模索し、パラメータ数を調べました。
パラメータの数を調べたところ、以下のことがわかりました。
より多くのパラメータを持ち、より深い分類器を持つ強力なベースラインがより深い分類器を用いた強力なベースラインが依然として凌駕していることがわかりました。
我々のアーキテクチャは、以下のコンポーネントで構成されています。それはユニモーダルなタスクとして個別に事前学習されたものです。
これらのコンポーネントに比べて大きな改善が見られました。マルチモーダルな自習モデルが一般的に有用であるかどうかはまだ不明です。しかしながら、ViLBERTとの比較では、MMBTは競争力のある性能を発揮することがわかりよりシンプルであることを示しました。
ここで紹介した手法は、自己教師付きマルチモーダルモデルの性能を評価するための有用で強力なベースラインとして役立つはずです。
そして、マルチモーダルモデルの性能を評価するための強力なベースラインとなるでしょう。
まとめると、簡単で直感的であり、また、既存の自己教師付きエンコーダにも簡単に実装できることがMMBTの最大の特長といえます。