報告の概要
TensorFlow
のページの機械学習プログラムを改修し、日本語学習させてみました。結果は訓練用データの正解率が 4/4 で、評価用データの正解率が 3/4 になりました。結果の要点とプログラムをご報告させていただきます。
学習させたデータと改修点
学習に使用したデータは、JSUT ver 1.1 の BASIC 5000発話と、Mozila Common Voice Japanese 11 をダウンロードして、mp3 ファイルを wav に変換した約30000発話のうち10000発話です。合わせて、15000発話(約21時間)で 100 epochs 学習させました。機械学習プログラムは前出のページから改修しました。改修したプログラムは結果の説明のあとに掲載します。大きな改修点は、アルファベットの文字ベースだった vocablary を、読み込んだ教師データから作った日本語1文字にしたことと、音響特徴量として、短時間 fft を使っていたところを mfcc (メル周波数ケプストラム係数)にしたことです。あとは、modelパラメータに ema (指数移動平均)を使いました。
学習途中での予測結果
最初に、Epoch 1/100 での、学習状態を見るための訓練用データと評価用データの予測結果です。train target が訓練用教師データです。train prediction が訓練用データについての予測です。val target は、評価用教師データ、val prediction が評価用データの予測です。ご覧の通り、ほとんど学習できていません。
Epoch 1/100
1856/1856 [==============================] - ETA: 0s - loss: 0.5245
train target: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train prediction: <このから、そのおもしいいいいいいです。>
train target: <お茶とコーヒーそれが1日のスタートを助ける>
train prediction: <このからはとてもういいいいいいいです。>
train target: <わたしはバスを待っています。>
train prediction: <このからはいですか。>
train target: <雪が降っても、学校に行きます。>
train prediction: <このから、お金をします。>
val target: <きのう木を切りました。>
val prediction: <きょうはとてもいです。>
val target: <はい>
val prediction: <いえ>
val target: <説明書がないと半額って、下げ過ぎじゃない?>
val prediction: <このから、おもしいいいいいいです。>
val target: <しち>
val prediction: <しち>
次に、Epochs 98/100, 99/100, 100/100 のデータです。
Epoch 98/100
train target: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train prediction: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train target: <お茶とコーヒーそれが1日のスタートを助ける>
train prediction: <お茶とコーヒーそれが1日のスタートを助ける>
train target: <わたしはバスを待っています。>
train prediction: <わたしはバスを待っています。>
train target: <雪が降っても、学校に行きます。>
train prediction: <雪が降っても、学校に行きます。>
val target: <きのう木を切りました。>
val prediction: <きのう木を切りました。>
val target: <はい>
val prediction: <はい>
val target: <説明書がないと半額って、下げ過ぎじゃない?>
val prediction: <電話口の前で散々泣かれた。>
val target: <しち>
val prediction: <しち>
1856/1856 [==============================] - 2301s 1s/step - loss: 0.1335 - val_loss: 0.3385
Epoch 99/100
train target: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train prediction: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train target: <お茶とコーヒーそれが1日のスタートを助ける>
train prediction: <お茶とコーヒーそれが1日のスタートを助ける>
train target: <わたしはバスを待っています。>
train prediction: <わたしはバスを待っています。>
train target: <雪が降っても、学校に行きます。>
train prediction: <雪が降っても、学校に行きます。>
val target: <きのう木を切りました。>
val prediction: <きのう木を切りました。>
val target: <はい>
val prediction: <はい>
val target: <説明書がないと半額って、下げ過ぎじゃない?>
val prediction: <けさは時間があるので、新聞を読んでから、家を出ます。>
val target: <しち>
val prediction: <しち>
1856/1856 [==============================] - 2243s 1s/step - loss: 0.1338 - val_loss: 0.3410
Epoch 100/100
train target: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train prediction: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train target: <お茶とコーヒーそれが1日のスタートを助ける>
train prediction: <お茶とコーヒーそれが1日のスタートを助ける>
train target: <わたしはバスを待っています。>
train prediction: <わたしはバスを待っています。>
train target: <雪が降っても、学校に行きます。>
train prediction: <雪が降っても、学校に行きます。>
val target: <きのう木を切りました。>
val prediction: <きのう木を切りました。>
val target: <はい>
val prediction: <はい>
val target: <説明書がないと半額って、下げ過ぎじゃない?>
val prediction: <うちに電話をかけましたが、誰もいませんでした。>
val target: <しち>
val prediction: <はち>
1856/1856 [==============================] - 2267s 1s/step - loss: 0.1333 - val_loss: 0.3411
データを見ると、訓練用データについては、98, 99, 100 epochs については、4/4の正解率です。また、評価用データについては、98,99 は 3/4 の正解率、100 については、2/4 の正解率です。学習していることが分かります。
損失のグラフ
それでは、損失のグラフを見てみます。
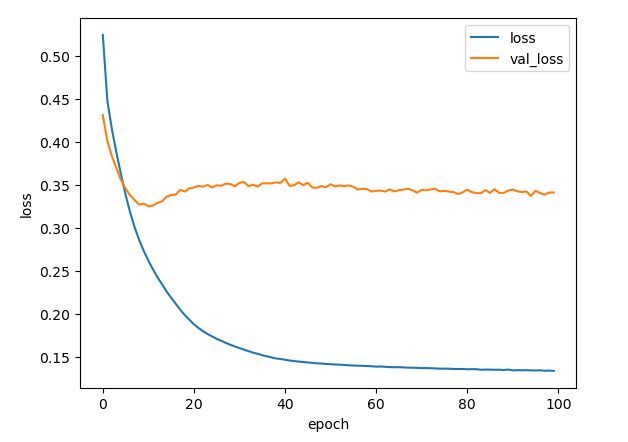
訓練データについての損失は順調に減少しています。しかし、評価用データについての損失は、一度減少して極小になってから、増加して、また、微減しています。極小の 10 epochs 程度でのデータは
Epoch 9/100
train target: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train prediction: <この本はとてもおもしろいと思います。>
train target: <お茶とコーヒーそれが1日のスタートを助ける>
train prediction: <一方で彼女はその結果はあれことを見ている>
train target: <わたしはバスを待っています。>
train prediction: <わたしはきのうかぎです。>
train target: <雪が降っても、学校に行きます。>
train prediction: <わたしは日本中旅行したいです。>
val target: <きのう木を切りました。>
val prediction: <この雑誌は厚くて、重いです。>
val target: <はい>
val prediction: <く>
val target: <説明書がないと半額って、下げ過ぎじゃない?>
val prediction: <わたしは日本語の辞書が欲しいです。>
val target: <しち>
val prediction: <いち>
1856/1856 [==============================] - 2145s 1s/step - loss: 0.2855 - val_loss: 0.3269
Epoch 10/100
train target: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train prediction: <この時計はきっと高いにちがいありません。>
train target: <お茶とコーヒーそれが1日のスタートを助ける>
train prediction: <彼はとても私は私をふりあいに来たという>
train target: <わたしはバスを待っています。>
train prediction: <あしたの朝洗濯をしなければなりません。>
train target: <雪が降っても、学校に行きます。>
train prediction: <このかばんは外側にポケットがあります。>
val target: <きのう木を切りました。>
val prediction: <これはわたしのかばんとてもきれいです。>
val target: <はい>
val prediction: <く>
val target: <説明書がないと半額って、下げ過ぎじゃない?>
val prediction: <わたしは毎朝パンと卵を食べます。>
val target: <しち>
val prediction: <いち>
1856/1856 [==============================] - 2143s 1s/step - loss: 0.2729 - val_loss: 0.3281
Epoch 11/100
train target: <あそこのレストランは、オムライスが好き。子供の頃から変わらないんだよ!>
train prediction: <きのうは疲れていたので、すぐ寝てしまいました。>
train target: <お茶とコーヒーそれが1日のスタートを助ける>
train prediction: <彼はとても私は私をするのではない>
train target: <わたしはバスを待っています。>
train prediction: <あしただれと会いますか。>
train target: <雪が降っても、学校に行きます。>
train prediction: <このかばんは外側にポケットがあります。>
val target: <きのう木を切りました。>
val prediction: <この雑誌は厚くて、重いです。>
val target: <はい>
val prediction: <はい>
val target: <説明書がないと半額って、下げ過ぎじゃない?>
val prediction: <きのうは疲れていたので、すぐ寝てしまいました。>
val target: <しち>
val prediction: <はち>
1856/1856 [==============================] - 2157s 1s/step - loss: 0.2617 - val_loss: 0.3249
です。10 epochs 程度では、ほとんど学習ができていないことが分かります。
今まで、TensorFlow のモデルについてはモデルを改修しながら、メルスペクトルで同様の実験を行ってきましたが、良い結果がでませんでした。val-loss が大きくなったら Early Stopping という条件を課していました。これが、災いして、validation データの予測文章が、教師データに近くならなかったのではないかと考えられます。
また、OpenAI の Whisper のモデルパラメータを初期化して、メルスペクトルで学習させましたが、訓練用データの学習が進み過学習の状態で、評価用データの val-loss が増加し、評価用データの教師データと予測文章が一致しないという現象が起きていました。
プログラム
それでは、学習に使ったプログラムを掲載します。
ライブラリー
import os
import random
from glob import glob
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
import librosa
import tensorflow_addons as tfa
import json
import gc
keras.initializers.Initializer()
#initializer = tf.keras.initializers.GlorotUniform()
#keras.initializers.lecun_uniform(seed=None)
#keras.initializers.he_uniform(seed=None)
#keras.initializers.lecun_nromal(seed=None)
#initializer = tf.keras.initializers.he_normal(seed=None)
initializer = tf.keras.initializers.GlorotNormal()
num_data = 15000
音声とデコーダーインプットの前処理のクラス
class TokenEmbedding(layers.Layer):
def __init__(self, num_vocab=1000, maxlen=100, num_hid=64):
super().__init__()
self.emb = tf.keras.layers.Embedding(num_vocab, num_hid)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=num_hid)
self.num_hid = num_hid
def call(self, x):
#maxlen = tf.shape(x)[-1]
maxlen = tf.shape(x)[1]
x = self.emb(x)
x *= tf.math.sqrt(tf.cast(self.num_hid, tf.float32)) # 後付け
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
return x + positions
class SpeechFeatureEmbedding(layers.Layer):
def __init__(self, num_hid=64, maxlen=100):
super().__init__()
self.conv1 = tf.keras.layers.Conv1D(
#num_hid, 3, strides=2, padding="same", activation="relu"
num_hid, 3, strides=2, padding="same"
)
self.batchnorm1 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv1D(
#num_hid, 3, strides=2, padding="same", activation="relu"
num_hid, 3, strides=2, padding="same"
)
self.batchnorm2 = tf.keras.layers.BatchNormalization()
self.conv3 = tf.keras.layers.Conv1D(
#num_hid, 3, strides=2, padding="same", activation="relu"
num_hid, 3, strides=2, padding="same"
)
self.batchnorm3 = tf.keras.layers.BatchNormalization()
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=num_hid)
self.num_hid = num_hid
#元のモデルでは、pos_emb を使っていない。batchnorm と relu はない。
def call(self, x):
x = self.conv1(x)
x = self.batchnorm1(x)
x = tf.nn.relu(x)
x = self.conv2(x)
x = self.batchnorm2(x)
x = tf.nn.relu(x)
#return self.conv3(x)
x = self.conv3(x)
x = self.batchnorm3(x)
x = tf.nn.relu(x)
x *= tf.math.sqrt(tf.cast(self.num_hid, tf.float32)) # 後付け
maxlen = tf.shape(x)[1]
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
return x + positions
TransformerEncoderクラス
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, num_heads, feed_forward_dim, rate=0.1):
super().__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential(
[
layers.Dense(feed_forward_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
#self.dropout1 = layers.Dropout(rate)
self.dropout1 = layers.Dropout(0.1)
#self.dropout2 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(0.1)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
TrasnformerDecoderクラス
class TransformerDecoder(layers.Layer):
def __init__(self, embed_dim, num_heads, feed_forward_dim, dropout_rate=0.1):
super().__init__()
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = layers.LayerNormalization(epsilon=1e-6)
self.self_att = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.enc_att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.self_dropout = layers.Dropout(0.5)
self.enc_dropout = layers.Dropout(0.1)
self.ffn_dropout = layers.Dropout(0.1)
self.ffn = keras.Sequential(
[
layers.Dense(feed_forward_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
def causal_attention_mask(self, batch_size, n_dest, n_src, dtype):
"""Masks the upper half of the dot product matrix in self attention.
This prevents flow of information from future tokens to current token.
1's in the lower triangle, counting from the lower right corner.
"""
i = tf.range(n_dest)[:, None]
j = tf.range(n_src)
m = i >= j - n_src + n_dest
mask = tf.cast(m, dtype)
mask = tf.reshape(mask, [1, n_dest, n_src])
mult = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)], 0
)
return tf.tile(mask, mult)
def call(self, enc_out, target):
input_shape = tf.shape(target)
batch_size = input_shape[0]
seq_len = input_shape[1]
causal_mask = self.causal_attention_mask(batch_size, seq_len, seq_len, tf.bool)
target_att = self.self_att(target, target, attention_mask=causal_mask)
target_norm = self.layernorm1(target + self.self_dropout(target_att))
enc_out = self.enc_att(target_norm, enc_out)
enc_out_norm = self.layernorm2(self.enc_dropout(enc_out) + target_norm)
ffn_out = self.ffn(enc_out_norm)
ffn_out_norm = self.layernorm3(enc_out_norm + self.ffn_dropout(ffn_out))
return ffn_out_norm
Transformer クラス
class Transformer(keras.Model):
def __init__(
self,
num_hid=64,
num_head=2,
num_feed_forward=128,
source_maxlen=100,
target_maxlen=100,
num_layers_enc=4,
num_layers_dec=1,
num_classes=10,
):
super().__init__()
self.loss_metric = keras.metrics.Mean(name="loss")
self.num_layers_enc = num_layers_enc
self.num_layers_dec = num_layers_dec
self.source_maxlen = source_maxlen
self.target_maxlen = target_maxlen
self.num_classes = num_classes
self.enc_input = SpeechFeatureEmbedding(num_hid=num_hid, maxlen=source_maxlen)
self.dec_input = TokenEmbedding(
num_vocab=num_classes, maxlen=target_maxlen, num_hid=num_hid
)
self.encoder = keras.Sequential(
[self.enc_input]
+ [
TransformerEncoder(num_hid, num_head, num_feed_forward)
for _ in range(num_layers_enc)
]
)
self.ema = tf.train.ExponentialMovingAverage(decay=0.9999)
for i in range(num_layers_dec):
setattr(
self,
f"dec_layer_{i}",
TransformerDecoder(num_hid, num_head, num_feed_forward),
)
self.classifier = layers.Dense(num_classes)
def decode(self, enc_out, target):
y = self.dec_input(target)
for i in range(self.num_layers_dec):
y = getattr(self, f"dec_layer_{i}")(enc_out, y)
return y
def call(self, inputs):
source = inputs[0]
target = inputs[1]
x = self.encoder(source)
y = self.decode(x, target)
return self.classifier(y)
@property
def metrics(self):
return [self.loss_metric]
def train_step(self, batch):
"""Processes one batch inside model.fit()."""
source = batch["source"]
target = batch["target"]
dec_input = target[:, :-1]
dec_target = target[:, 1:]
with tf.GradientTape() as tape:
preds = self([source, dec_input])
one_hot = tf.one_hot(dec_target, depth=self.num_classes)
mask = tf.math.logical_not(tf.math.equal(dec_target, 0))
loss = self.compiled_loss(one_hot, preds, sample_weight=mask)
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
self.ema.apply(trainable_vars)
self.loss_metric.update_state(loss)
return {"loss": self.loss_metric.result()}
def test_step(self, batch):
source = batch["source"]
target = batch["target"]
dec_input = target[:, :-1]
dec_target = target[:, 1:]
preds = self([source, dec_input])
one_hot = tf.one_hot(dec_target, depth=self.num_classes)
mask = tf.math.logical_not(tf.math.equal(dec_target, 0))
loss = self.compiled_loss(one_hot, preds, sample_weight=mask)
self.loss_metric.update_state(loss)
return {"loss": self.loss_metric.result()}
def generate(self, source, target_start_token_idx):
"""Performs inference over one batch of inputs using greedy decoding."""
bs = tf.shape(source)[0]
enc = self.encoder(source)
dec_input = tf.ones((bs, 1), dtype=tf.int32) * target_start_token_idx
dec_logits = []
for i in range(self.target_maxlen - 1):
dec_out = self.decode(enc, dec_input)
logits = self.classifier(dec_out)
logits = tf.argmax(logits, axis=-1, output_type=tf.int32)
last_logit = tf.expand_dims(logits[:, -1], axis=-1)
dec_logits.append(last_logit)
dec_input = tf.concat([dec_input, last_logit], axis=-1)
return dec_input
TensorFlow にあった LJspeech のダウンロードプログラム
#keras.utils.get_file(
# os.path.join(os.getcwd(), "data.tar.gz"),
# "https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2",
# extract=True,
# archive_format="tar",
# cache_dir=".",
#)
wav ファイルのファイル名取得
saveto = "./datasets/fusion2"
wavs = glob("{}/**/*.wav".format(saveto), recursive=True)
metadata.csv と wav データは、
current dir/datasets/fusion2/
|
|-metadata.csv
|
|--wavs-|-basename1.wav
|-basename2.wav
|-basename3.wav
|・・・
のように置いています。matadata.csv の中の wav ファイル名の列は、「.wav」のない、basename を記入しています。
basename1|音声ファイル1に対応した文章(教師データ)
basename2|音声ファイル2に対応した文章(教師データ)
basename3|音声ファイル3に対応した文章(教師データ)
・・・
のようです。ここで、あとで分かったことですが、JSUT の文章データは句読点を削除し、Common Voice の文章データは句読点を削除しませんでした。
metadata の読み込みと、音声ファイル名の確保
id_to_text = {}
with open(os.path.join(saveto, "metadata.csv"), encoding="utf-8") as f:
for line in f:
id = line.strip().split("|")[0]
text = line.strip().split("|")[2]
id_to_text[id] = text
def get_data(wavs, id_to_text, maxlen=50):
""" returns mapping of audio paths and transcription texts """
data = []
i2 = 0
for i, w in enumerate( wavs ):
#print(" w:{}".format( w ))
#id = w.split("/")[-1].split(".")[0] #Linux
id = w.split("\\")[-1].split(".")[0] #Windows
#print( "i:{}, id:{}".format( i, id ))
# wavファイルが metadata.csv にリストアップされていて、教師データが maxlen 文字以下だったら。
if id in id_to_text and len(id_to_text[id]) < maxlen:
i2 += 1
if i2 > num_data:
break
print( "get_data i:{}".format( i ))
data.append({"audio": w, "text": id_to_text[id]})
print( "get_data len of data:{}".format( len( data )))
return data
学習データの作成
#アルファベット用
class VectorizeChar:
def __init__(self, max_len=50):
self.vocab = (
["-", "#", "<", ">"]
+ [chr(i + 96) for i in range(1, 27)]
+ [" ", ".", ",", "?"]
)
self.max_len = max_len
self.char_to_idx = {}
for i, ch in enumerate(self.vocab):
#print( "ch:{}".format( ch ))
self.char_to_idx[ch] = i
def __call__(self, text):
text = text.lower()
text = text[: self.max_len - 2]
text = "<" + text + ">"
pad_len = self.max_len - len(text)
return [self.char_to_idx.get(ch, 1) for ch in text] + [0] * pad_len
def get_vocabulary(self):
return self.vocab
#日本語の一文字用。
blank = 0
target_start_token_idx = 1
target_end_token_idx = 2
class VectorizeChar2:# token_list に blank 0, < 1, > 2 を加えている。
def __init__(self, max_len = 50 ):
self.max_len = max_len
self.char_index = {' ':blank,'<':target_start_token_idx,'>':target_end_token_idx}
self.index_char = {blank:' ',target_start_token_idx:'<',target_end_token_idx:'>'}
def __call__(self, text):
self.make_dict( text )
text = text[: self.max_len - 2]
text = "<" + text + ">"
pad_len = self.max_len - len(text)
return [self.char_index.get(ch, 1 ) for ch in text] + [0] * pad_len
def make_dict(self, texts):
for text in texts:
for data in text:
#print( "data:{}".format( data ))
if data not in self.char_index:
if str(data) != ' ' and str(data) != '<' and str(data) !='>':
tmp_idx = len( self.char_index )
self.char_index[str(data)] = tmp_idx
self.index_char[tmp_idx] = str(data)
json_file = open('char_index.json', mode="w", encoding="utf-8")
json.dump(self.char_index, json_file, indent=2, ensure_ascii=False)
json_file.close()
json_file = open('index_char.json', mode="w", encoding="utf-8")
json.dump(self.index_char, json_file, indent=2, ensure_ascii=False)
json_file.close()
def get_vocabulary(self):
result = [ self.index_char[i] for i in range( len( self.char_index ) ) ]
return result
#テキストデータを作る。
def create_text_ds(data):
#print( "text data:{}".format( data ))
texts = [_["text"] for _ in data]
#print( "texts:{}".format( texts ))
text_ds = [vectorizer(t) for t in texts]
#print( "text_ds:{}".format( text_ds ))
text_ds = tf.data.Dataset.from_tensor_slices(text_ds)
#print( "text_ds:{}".format( text_ds ))
return text_ds
max_target_len = 200 # all transcripts in out data are < 200 characters
max_source_len = 3000 # 30 seconds. sr = 16000 Hz, window shift 160 frame, 1 window shift 0.01 seconds, 30 seconds / 0.01 seconds = 3000 個
data = get_data(wavs, id_to_text, max_target_len)
#print( " data:{}".format( data ))
texts = [_["text"] for _ in data]
#print( " texts:{}".format( texts ))
vectorizer = VectorizeChar2(max_target_len)
vectorizer.make_dict(texts)
print("vocab size", len(vectorizer.get_vocabulary()))
# 特徴量の計算。mfcc を normalize して特徴量としている。
def path_to_audio(filename):
# melspectrogram( noemalize, pcen ), mfcc
audio, sr = librosa.load( filename, sr=16000 )
#audio = librosa.resample(audio, orig_sr=sr, target_sr=16000)
window_fn = 'hann'
S = librosa.feature.melspectrogram(y=audio, sr=16000, n_mels=80, fmax=8000,
hop_length = 160, n_fft=512, win_length=400, window=window_fn)
log_S = librosa.amplitude_to_db(S, ref=np.max)
mfcc = librosa.feature.mfcc( S=log_S, n_mfcc=13)
x = librosa.util.normalize(mfcc)
#x = librosa.util.normalize(log_S)
#x = librosa.pcen(S * (2**31), max_size=3)
#x = librosa.pcen(S * (2**31), sr=16000)
x = x.T
#audio_len = tf.shape(x)[0]
# padding to 30 seconds
pad_len = max_source_len
paddings = tf.constant([[0, pad_len], [0, 0]])
x = tf.pad(x, paddings, "CONSTANT")[:pad_len, :]
return x
# 音声データを作る
def create_audio_ds(data):
flist = [_["audio"] for _ in data] # データからファイルリストを作る。
audio_ds = []
for i, filename in enumerate( flist ):
audio_ds.append( path_to_audio( filename ) )
print( "i :{}".format(i))
gc.collect()
audio_ds = tf.data.Dataset.from_tensor_slices(audio_ds)
return audio_ds
#訓練用データを作る関数
def create_train_dataset(data, bs=4):
audio_ds = create_audio_ds(data)
text_ds = create_text_ds(data)
ds = tf.data.Dataset.zip((audio_ds, text_ds))
ds = ds.map(lambda x, y: {"source": x, "target": y})
ds = ds.shuffle(1000)
ds = ds.batch(bs, drop_remainder=True)
ds = ds.prefetch(tf.data.AUTOTUNE)
return ds
# 評価用データを作る関数
def create_test_dataset(data, bs=4):
audio_ds = create_audio_ds(data)
text_ds = create_text_ds(data)
ds = tf.data.Dataset.zip((audio_ds, text_ds))
ds = ds.map(lambda x, y: {"source": x, "target": y})
ds = ds.batch(bs, drop_remainder=False)
ds = ds.prefetch(tf.data.AUTOTUNE)
return ds
#split = int(len(data) * 0.99)
#train_data = data[:split]
#test_data = data[split:]
#データを訓練用と評価用に分ける。
train_data, test_data = train_test_split(data, test_size=0.01)
train_data2 = train_data[:16]
#print( train_data )
#sys.exit()
# バッチに分ける
ds = create_train_dataset(train_data, bs=8)
ds2 = create_test_dataset(train_data2, bs=4)
val_ds = create_test_dataset(test_data, bs=4)
print("vocab size", len(vectorizer.get_vocabulary()))
学習途中に教師データと予測文章を表示
#1エポックごとに訓練用データと評価用データのターゲットと予測を表示する。
class DisplayOutputs(keras.callbacks.Callback):
def __init__(
self, batch, batch2, idx_to_token, target_start_token_idx=target_start_token_idx, target_end_token_idx=target_end_token_idx
):
"""Displays a batch of outputs after every epoch
Args:
batch: A test batch containing the keys "source" and "target"
idx_to_token: A List containing the vocabulary tokens corresponding to their indices
target_start_token_idx: A start token index in the target vocabulary
target_end_token_idx: An end token index in the target vocabulary
"""
self.batch = batch
self.batch2 = batch2
self.target_start_token_idx = target_start_token_idx
self.target_end_token_idx = target_end_token_idx
self.idx_to_char = idx_to_token
def on_epoch_end(self, epoch, logs=None):
#if epoch % 5 != 0:
if epoch % 1 != 0:
return
source = self.batch2["source"]
target = self.batch2["target"].numpy()
bs = tf.shape(source)[0]
preds = self.model.generate(source, self.target_start_token_idx)
preds = preds.numpy()
for i in range(bs):
target_text = "".join([self.idx_to_char[_] for _ in target[i, :]])
prediction = ""
for idx in preds[i, :]:
prediction += self.idx_to_char[idx]
if idx == self.target_end_token_idx:
break
print(f"\ntrain target: {target_text.replace('-','')}")
print(f"train prediction: {prediction}\n")
source = self.batch["source"]
target = self.batch["target"].numpy()
bs = tf.shape(source)[0]
preds = self.model.generate(source, self.target_start_token_idx)
preds = preds.numpy()
for i in range(bs):
target_text = "".join([self.idx_to_char[_] for _ in target[i, :]])
prediction = ""
for idx in preds[i, :]:
prediction += self.idx_to_char[idx]
if idx == self.target_end_token_idx:
break
print(f"\nval target: {target_text.replace('-','')}")
print(f"val prediction: {prediction}\n")
return
モデル定義など
batch = next(iter(val_ds))
batch2 = next(iter(ds2))
# The vocabulary to convert predicted indices into characters
idx_to_char = vectorizer.get_vocabulary()
display_cb = DisplayOutputs(
#batch, idx_to_char, target_start_token_idx=2, target_end_token_idx=3
batch, batch2, idx_to_char, target_start_token_idx=1, target_end_token_idx=2
) # set the arguments as per vocabulary index for '<' and '>'
# ここは < > の番号に合わせて変更しなければならない。
model = Transformer(
#num_hid=200,
num_hid=256,
num_head=2,
#num_feed_forward=400,
num_feed_forward=1024,
source_maxlen=max_source_len,
target_maxlen=max_target_len,
#num_layers_enc=4,
num_layers_enc=4,
#num_layers_dec=1,
num_layers_dec=4,
#num_classes=34,
num_classes=len(vectorizer.get_vocabulary()) + 1,
)
loss_fn = tf.keras.losses.CategoricalCrossentropy(
from_logits=True, label_smoothing=0.1,
)
#簡単な学習率のスケジュール
step = tf.Variable(0, trainable=False)
step1 = len(ds) * 10 # 0 ~ step1 (10epcoch)まで、1e-4。 len(ds) は、steps_per_epoch
step2 = len(ds) * 30 #step1(10epoch)~step2(30epoch) まで、1e-3。step2 から 1e-4
schedule = tf.optimizers.schedules.PiecewiseConstantDecay([ step1, step2 ], [1e-4, 1e-3, 1e-4])
lr = schedule( step )
#optimizer = keras.optimizers.Adam(learning_rate)
optimizer = keras.optimizers.Adam(learning_rate=lr)
model.compile(optimizer=optimizer, loss=loss_fn)
学習
#学習
epochs = 100
history = model.fit(ds, validation_data=val_ds, callbacks=[display_cb,EarlyStopping(monitor='loss', patience=5, verbose=1, mode='auto')],
epochs=epochs)
これらが、学習に使用したプログラムです。