報告の概略
Transformer を使った TensorFlow の音声認識の紹介ページ
に掲載されたプログラムを、音響特徴量 PCEN で日本語対応にしました。音声認識したデータと正解率、学習について、プログラムの改修した箇所とプログラムを掲載します。
音声認識の結果
学習中にモニターしている音声認識結果です。100 Epoch 学習を行う予定のうち 87 Epoch 目です。
Epoch 87/100
train target: <こんなのプライバシーの侵害だ。>
train prediction: <こんなのプライバシーの侵害だ。>
train target: <筆者の知人に、サンタのおじさんがいる。>
train prediction: <筆者の知人に、サンタのおじさんがいる。>
train target: <この作文はとてもよく書けました。>
train prediction: <この作文はとてもよく書けました。>
train target: <毎日、学校へ行きます。>
train prediction: <毎日、学校へ行きます。>
val target: <既に学問は一通り終えてしまったらしく、療の代わりに症例を解説して、人を諭すことと発明が得意。>
val prediction: <セカンドムーンにおいても、マーズレイによる影響を完全に防げていないためか、病を煩う者が少なくない。>
val target: <おみやげの温泉卵だよ。>
val prediction: <おみやげの温泉卵だよ。>
val target: <きょうはもう家へ帰ります。>
val prediction: <きょうはもう家へ帰ります。>
val target: <れい>
val prediction: <れい>
1856/1856 [==============================] - 4237s 2s/step - loss: 0.1365 - val_loss: 0.4067
train target が、訓練用教師データで、train prediction が訓練用データについて予測を行った結果です。val target がテスト用教師データで val prediction がテスト用データについて予測を行った結果です。訓練用データについては、4/4 の正解率。テスト用データについても 3/4 の正解率です。
学習について
学習用データは、JSUT 1.1 BASIC 5000発話と Mozilla Common Voice Japanese 11 の 30000発話のうち早い方の 10000 発話です。JSUT は、wav ファイルを 16000Hz に、 Common Voice は mp3 を wav ファイルに変換して 16000 Hz に変換しました。合計 15000発話、約21時間です。
次に損失の学習曲線を掲載します。
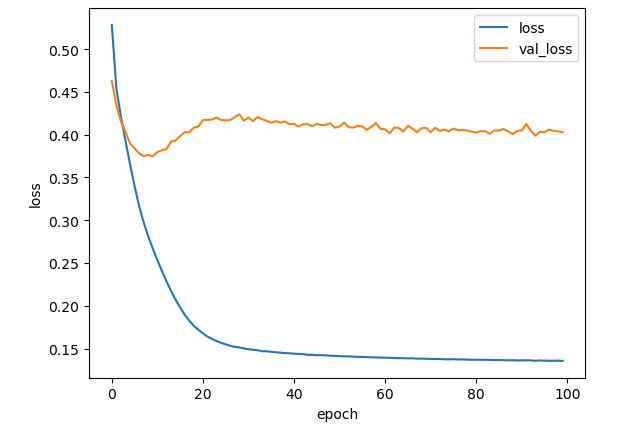
このグラフから、訓練データの損失が順調に減少していることが分かります。また、テストデータの損失は、epoch 10 くらいまで一度減少し、そののち少し上昇してそのあと、コンスタントに減少していることが分かります。
改修した箇所
上記 URL のプログラムを改修して学習させたのですが、主な改修個所は、英語対応だったところを、日本語1文字(分かち書きしていない)の辞書を使ったプログラムに改修した。音響特徴量として短時間フーリエ変換の結果を使っていたところを PCEN にしました。同時に、ログメルスペクトログラムにした学習も行いましたが、同様の学習ができました。音響特徴量の処理は、30秒の音声データを 3000 * 80 としているので、1次元 convolution 3層において、convolution の kernel size は 3としました。stride は 1層目と 2層目が2 で、3層目が1です。Transformer Encoder 4層と Transformer Decoder 4 層です。Transformer の隠れ層の次元は 256、point wise feed foward network の次元は 2048 。Transformer の number of head は 2 としました。
プログラム
ライブラリーの読み込み
import os
import random
from glob import glob
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
import librosa
import tensorflow_addons as tfa
import json
import gc
keras.initializers.Initializer()
#initializer = tf.keras.initializers.GlorotUniform()
#keras.initializers.lecun_uniform(seed=None)
#keras.initializers.he_uniform(seed=None)
#keras.initializers.lecun_nromal(seed=None)
#initializer = tf.keras.initializers.he_normal(seed=None)
initializer = tf.keras.initializers.GlorotNormal()
num_data = 15000
Encoder と Decoder への入力の前処理ルーチン
class TokenEmbedding(layers.Layer):
def __init__(self, num_vocab=1000, maxlen=100, num_hid=64):
super().__init__()
self.emb = tf.keras.layers.Embedding(num_vocab, num_hid)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=num_hid)
self.num_hid = num_hid
def call(self, x):
#maxlen = tf.shape(x)[-1]
maxlen = tf.shape(x)[1]
x = self.emb(x)
x *= tf.math.sqrt(tf.cast(self.num_hid, tf.float32)) # 後付け
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
return x + positions
class SpeechFeatureEmbedding(layers.Layer):
def __init__(self, num_hid=64, maxlen=100):
super().__init__()
self.conv1 = tf.keras.layers.Conv1D(
#num_hid, 3, strides=2, padding="same", activation="relu"
num_hid, 3, strides=2, padding="same"
)
self.batchnorm1 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv1D(
#num_hid, 3, strides=2, padding="same", activation="relu"
num_hid, 3, strides=2, padding="same"
)
self.batchnorm2 = tf.keras.layers.BatchNormalization()
self.conv3 = tf.keras.layers.Conv1D(
#num_hid, 3, strides=2, padding="same", activation="relu"
num_hid, 3, strides=1, padding="same"
)
self.batchnorm3 = tf.keras.layers.BatchNormalization()
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=num_hid)
self.num_hid = num_hid
#元のモデルでは、pos_emb を使っていない。batchnorm と relu はない。
def call(self, x):
x = self.conv1(x)
x = self.batchnorm1(x)
x = tf.nn.relu(x)
x = self.conv2(x)
x = self.batchnorm2(x)
x = tf.nn.relu(x)
#return self.conv3(x)
x = self.conv3(x)
x = self.batchnorm3(x)
x = tf.nn.relu(x)
x *= tf.math.sqrt(tf.cast(self.num_hid, tf.float32)) # 後付け
maxlen = tf.shape(x)[1]
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
return x + positions
TransformerEncoder
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, num_heads, feed_forward_dim, rate=0.1):
super().__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential(
[
layers.Dense(feed_forward_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
#self.dropout1 = layers.Dropout(rate)
self.dropout1 = layers.Dropout(0.1)
#self.dropout2 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(0.1)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
TransformerDecoder
class TransformerDecoder(layers.Layer):
def __init__(self, embed_dim, num_heads, feed_forward_dim, dropout_rate=0.1):
super().__init__()
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = layers.LayerNormalization(epsilon=1e-6)
self.self_att = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.enc_att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.self_dropout = layers.Dropout(0.5)
self.enc_dropout = layers.Dropout(0.1)
self.ffn_dropout = layers.Dropout(0.1)
self.ffn = keras.Sequential(
[
layers.Dense(feed_forward_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
def causal_attention_mask(self, batch_size, n_dest, n_src, dtype):
"""Masks the upper half of the dot product matrix in self attention.
This prevents flow of information from future tokens to current token.
1's in the lower triangle, counting from the lower right corner.
"""
i = tf.range(n_dest)[:, None]
j = tf.range(n_src)
m = i >= j - n_src + n_dest
mask = tf.cast(m, dtype)
mask = tf.reshape(mask, [1, n_dest, n_src])
mult = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)], 0
)
return tf.tile(mask, mult)
def call(self, enc_out, target):
input_shape = tf.shape(target)
batch_size = input_shape[0]
seq_len = input_shape[1]
causal_mask = self.causal_attention_mask(batch_size, seq_len, seq_len, tf.bool)
target_att = self.self_att(target, target, attention_mask=causal_mask)
target_norm = self.layernorm1(target + self.self_dropout(target_att))
enc_out = self.enc_att(target_norm, enc_out)
enc_out_norm = self.layernorm2(self.enc_dropout(enc_out) + target_norm)
ffn_out = self.ffn(enc_out_norm)
ffn_out_norm = self.layernorm3(enc_out_norm + self.ffn_dropout(ffn_out))
return ffn_out_norm
Transformer
class Transformer(keras.Model):
def __init__(
self,
num_hid=64,
num_head=2,
num_feed_forward=128,
source_maxlen=100,
target_maxlen=100,
num_layers_enc=4,
num_layers_dec=1,
num_classes=10,
):
super().__init__()
self.loss_metric = keras.metrics.Mean(name="loss")
self.num_layers_enc = num_layers_enc
self.num_layers_dec = num_layers_dec
self.source_maxlen = source_maxlen
self.target_maxlen = target_maxlen
self.num_classes = num_classes
self.enc_input = SpeechFeatureEmbedding(num_hid=num_hid, maxlen=source_maxlen)
self.dec_input = TokenEmbedding(
num_vocab=num_classes, maxlen=target_maxlen, num_hid=num_hid
)
self.encoder = keras.Sequential(
[self.enc_input]
+ [
TransformerEncoder(num_hid, num_head, num_feed_forward)
for _ in range(num_layers_enc)
]
)
self.ema = tf.train.ExponentialMovingAverage(decay=0.9999)
for i in range(num_layers_dec):
setattr(
self,
f"dec_layer_{i}",
TransformerDecoder(num_hid, num_head, num_feed_forward),
)
self.classifier = layers.Dense(num_classes)
def decode(self, enc_out, target):
y = self.dec_input(target)
for i in range(self.num_layers_dec):
y = getattr(self, f"dec_layer_{i}")(enc_out, y)
return y
def call(self, inputs):
source = inputs[0]
target = inputs[1]
x = self.encoder(source)
y = self.decode(x, target)
return self.classifier(y)
@property
def metrics(self):
return [self.loss_metric]
def train_step(self, batch):
"""Processes one batch inside model.fit()."""
source = batch["source"]
target = batch["target"]
dec_input = target[:, :-1]
dec_target = target[:, 1:]
with tf.GradientTape() as tape:
preds = self([source, dec_input])
one_hot = tf.one_hot(dec_target, depth=self.num_classes)
mask = tf.math.logical_not(tf.math.equal(dec_target, 0))
loss = self.compiled_loss(one_hot, preds, sample_weight=mask)
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
self.ema.apply(trainable_vars)
self.loss_metric.update_state(loss)
return {"loss": self.loss_metric.result()}
def test_step(self, batch):
source = batch["source"]
target = batch["target"]
dec_input = target[:, :-1]
dec_target = target[:, 1:]
preds = self([source, dec_input])
one_hot = tf.one_hot(dec_target, depth=self.num_classes)
mask = tf.math.logical_not(tf.math.equal(dec_target, 0))
loss = self.compiled_loss(one_hot, preds, sample_weight=mask)
self.loss_metric.update_state(loss)
return {"loss": self.loss_metric.result()}
def generate(self, source, target_start_token_idx):
"""Performs inference over one batch of inputs using greedy decoding."""
bs = tf.shape(source)[0]
enc = self.encoder(source)
dec_input = tf.ones((bs, 1), dtype=tf.int32) * target_start_token_idx
dec_logits = []
for i in range(self.target_maxlen - 1):
dec_out = self.decode(enc, dec_input)
logits = self.classifier(dec_out)
logits = tf.argmax(logits, axis=-1, output_type=tf.int32)
last_logit = tf.expand_dims(logits[:, -1], axis=-1)
dec_logits.append(last_logit)
dec_input = tf.concat([dec_input, last_logit], axis=-1)
return dec_input
データ関連
metadata.csv と wav データは、
current dir/datasets/fusion2/
|
|-metadata.csv
|
|--wavs-|-basename1.wav
|-basename2.wav
|-basename3.wav
|・・・
のように置いています。matadata.csv の中の wav ファイル名の列は、「.wav」のない、basename を記入しています。
basename1|音声ファイル1に対応した文章(教師データ)
basename2|音声ファイル2に対応した文章(教師データ)
basename3|音声ファイル3に対応した文章(教師データ)
・・・
のようです。
saveto = "./datasets/fusion2"
wavs = glob("{}/**/*.wav".format(saveto), recursive=True)
id_to_text = {}
with open(os.path.join(saveto, "metadata.csv"), encoding="utf-8") as f:
for line in f:
id = line.strip().split("|")[0]
text = line.strip().split("|")[1]
id_to_text[id] = text
def get_data(wavs, id_to_text, maxlen=50):
""" returns mapping of audio paths and transcription texts """
data = []
i2 = 0
for i, w in enumerate( wavs ):
#print(" w:{}".format( w ))
#id = w.split("/")[-1].split(".")[0]
id = w.split("\\")[-1].split(".")[0]
#print( "i:{}, id:{}".format( i, id ))
# wavファイルが metadata.csv にリストアップされていて、教師データが maxlen 文字以下だったら。
if id in id_to_text and len(id_to_text[id]) < maxlen:
i2 += 1
if i2 > num_data:
break
print( "get_data i:{}".format( i ))
data.append({"audio": w, "text": id_to_text[id]})
print( "get_data len of data:{}".format( len( data )))
return data
#アルファベット用
class VectorizeChar:
def __init__(self, max_len=50):
self.vocab = (
["-", "#", "<", ">"]
+ [chr(i + 96) for i in range(1, 27)]
+ [" ", ".", ",", "?"]
)
self.max_len = max_len
self.char_to_idx = {}
for i, ch in enumerate(self.vocab):
#print( "ch:{}".format( ch ))
self.char_to_idx[ch] = i
def __call__(self, text):
text = text.lower()
text = text[: self.max_len - 2]
text = "<" + text + ">"
pad_len = self.max_len - len(text)
return [self.char_to_idx.get(ch, 1) for ch in text] + [0] * pad_len
def get_vocabulary(self):
return self.vocab
#日本語の一文字用。
blank = 0
target_start_token_idx = 1
target_end_token_idx = 2
class VectorizeChar2:# token_list に blank 0, < 1, > 2 を加えている。
def __init__(self, max_len = 50 ):
self.max_len = max_len
self.char_index = {' ':blank,'<':target_start_token_idx,'>':target_end_token_idx}
self.index_char = {blank:' ',target_start_token_idx:'<',target_end_token_idx:'>'}
def __call__(self, text):
self.make_dict( text )
text = text[: self.max_len - 2]
text = "<" + text + ">"
pad_len = self.max_len - len(text)
return [self.char_index.get(ch, 1 ) for ch in text] + [0] * pad_len
def make_dict(self, texts):
for text in texts:
for data in text:
#print( "data:{}".format( data ))
if data not in self.char_index:
if str(data) != ' ' and str(data) != '<' and str(data) !='>':
tmp_idx = len( self.char_index )
self.char_index[str(data)] = tmp_idx
self.index_char[tmp_idx] = str(data)
json_file = open('char_index.json', mode="w", encoding="utf-8")
json.dump(self.char_index, json_file, indent=2, ensure_ascii=False)
json_file.close()
json_file = open('index_char.json', mode="w", encoding="utf-8")
json.dump(self.index_char, json_file, indent=2, ensure_ascii=False)
json_file.close()
def get_vocabulary(self):
result = [ self.index_char[i] for i in range( len( self.char_index ) ) ]
return result
#テキストデータを作る。
def create_text_ds(data):
#print( "text data:{}".format( data ))
texts = [_["text"] for _ in data]
#print( "texts:{}".format( texts ))
text_ds = [vectorizer(t) for t in texts]
#print( "text_ds:{}".format( text_ds ))
text_ds = tf.data.Dataset.from_tensor_slices(text_ds)
#print( "text_ds:{}".format( text_ds ))
return text_ds
max_target_len = 200 # all transcripts in out data are < 200 characters
max_source_len = 3000 # 30 seconds. sr = 16000 Hz, window shift 160 frame, 1 window shift 0.01 seconds, 30 seconds / 0.01 seconds = 3000 個
data = get_data(wavs, id_to_text, max_target_len)
#print( " data:{}".format( data ))
texts = [_["text"] for _ in data]
#print( " texts:{}".format( texts ))
vectorizer = VectorizeChar2(max_target_len)
vectorizer.make_dict(texts)
print("vocab size", len(vectorizer.get_vocabulary()))
# 特徴量の計算。PCEN 。
def path_to_audio(filename):
# melspectrogram( noemalize, pcen ), mfcc
audio, sr = librosa.load( filename, sr=16000 )
#audio = librosa.resample(audio, orig_sr=sr, target_sr=16000)
window_fn = 'hann'
S = librosa.feature.melspectrogram(y=audio, sr=16000, n_mels=80, fmax=8000,
hop_length = 160, n_fft=512, win_length=400, window=window_fn)
#log_S = librosa.amplitude_to_db(S, ref=np.max) #ログメルの場合コメントを取る。
#mfcc = librosa.feature.mfcc( S=log_S, n_mfcc=13)
#x = librosa.util.normalize(mfcc)
#x = librosa.util.normalize(log_S)#ログメルの場合コメントを取る。
#x = librosa.pcen(S * (2**31), max_size=3)
x = librosa.pcen(S * (2**31), sr=16000) #ログメルの場合コメントアウトする。
x = x.T
#audio_len = tf.shape(x)[0]
# padding to 30 seconds
pad_len = max_source_len
paddings = tf.constant([[0, pad_len], [0, 0]])
x = tf.pad(x, paddings, "CONSTANT")[:pad_len, :]
return x
# 音声データを作る
def create_audio_ds(data):
flist = [_["audio"] for _ in data] # データからファイルリストを作る。
audio_ds = []
for i, filename in enumerate( flist ):
audio_ds.append( path_to_audio( filename ) )
print( "i :{}".format(i))
gc.collect()
audio_ds = tf.data.Dataset.from_tensor_slices(audio_ds)
return audio_ds
#訓練用データを作る関数
def create_train_dataset(data, bs=4):
audio_ds = create_audio_ds(data)
text_ds = create_text_ds(data)
ds = tf.data.Dataset.zip((audio_ds, text_ds))
ds = ds.map(lambda x, y: {"source": x, "target": y})
ds = ds.shuffle(1000)
ds = ds.batch(bs, drop_remainder=True)
ds = ds.prefetch(tf.data.AUTOTUNE)
return ds
# 評価用データを作る関数
def create_test_dataset(data, bs=4):
audio_ds = create_audio_ds(data)
text_ds = create_text_ds(data)
ds = tf.data.Dataset.zip((audio_ds, text_ds))
ds = ds.map(lambda x, y: {"source": x, "target": y})
ds = ds.batch(bs, drop_remainder=False)
ds = ds.prefetch(tf.data.AUTOTUNE)
return ds
#split = int(len(data) * 0.99)
#train_data = data[:split]
#test_data = data[split:]
#データを訓練用と評価用に分ける。
train_data, test_data = train_test_split(data, test_size=0.01)
train_data2 = train_data[:16]
#print( train_data )
#sys.exit()
# バッチに分ける
ds = create_train_dataset(train_data, bs=8)
ds2 = create_test_dataset(train_data2, bs=4)
val_ds = create_test_dataset(test_data, bs=4)
print("vocab size", len(vectorizer.get_vocabulary()))
学習中に音声認識結果を表示するルーチン
#1エポックごとに訓練用データと評価用データのターゲットと予測を表示する。
class DisplayOutputs(keras.callbacks.Callback):
def __init__(
self, batch, batch2, idx_to_token, target_start_token_idx=target_start_token_idx, target_end_token_idx=target_end_token_idx
):
"""Displays a batch of outputs after every epoch
Args:
batch: A test batch containing the keys "source" and "target"
idx_to_token: A List containing the vocabulary tokens corresponding to their indices
target_start_token_idx: A start token index in the target vocabulary
target_end_token_idx: An end token index in the target vocabulary
"""
self.batch = batch
self.batch2 = batch2
self.target_start_token_idx = target_start_token_idx
self.target_end_token_idx = target_end_token_idx
self.idx_to_char = idx_to_token
def on_epoch_end(self, epoch, logs=None):
#if epoch % 5 != 0:
if epoch % 1 != 0:
return
source = self.batch2["source"]
target = self.batch2["target"].numpy()
bs = tf.shape(source)[0]
preds = self.model.generate(source, self.target_start_token_idx)
preds = preds.numpy()
for i in range(bs):
target_text = "".join([self.idx_to_char[_] for _ in target[i, :]])
prediction = ""
for idx in preds[i, :]:
prediction += self.idx_to_char[idx]
if idx == self.target_end_token_idx:
break
print(f"\ntrain target: {target_text.replace('-','')}")
print(f"train prediction: {prediction}\n")
source = self.batch["source"]
target = self.batch["target"].numpy()
bs = tf.shape(source)[0]
preds = self.model.generate(source, self.target_start_token_idx)
preds = preds.numpy()
for i in range(bs):
target_text = "".join([self.idx_to_char[_] for _ in target[i, :]])
prediction = ""
for idx in preds[i, :]:
prediction += self.idx_to_char[idx]
if idx == self.target_end_token_idx:
break
print(f"\nval target: {target_text.replace('-','')}")
print(f"val prediction: {prediction}\n")
return
モデル定義と学習率スケジューラー
batch = next(iter(val_ds))
batch2 = next(iter(ds2))
# The vocabulary to convert predicted indices into characters
idx_to_char = vectorizer.get_vocabulary()
display_cb = DisplayOutputs(
#batch, idx_to_char, target_start_token_idx=2, target_end_token_idx=3
batch, batch2, idx_to_char, target_start_token_idx=1, target_end_token_idx=2
) # set the arguments as per vocabulary index for '<' and '>'
# ここは < > の番号に合わせて変更しなければならない。
model = Transformer(
#num_hid=200,
num_hid=256,
num_head=2,
#num_feed_forward=400,
num_feed_forward=2048,
source_maxlen=max_source_len,
target_maxlen=max_target_len,
#num_layers_enc=4,
num_layers_enc=4,
#num_layers_dec=1,
num_layers_dec=4,
#num_classes=34,
num_classes=len(vectorizer.get_vocabulary()) + 1,
)
loss_fn = tf.keras.losses.CategoricalCrossentropy(
from_logits=True, label_smoothing=0.1,
)
#簡単な学習率のスケジュール
step = tf.Variable(0, trainable=False)
step1 = len(ds) * 10 # 0 ~ step1 (10epcoch)まで、1e-4。 len(ds) は、steps_per_epoch
step2 = len(ds) * 30 #step1(10epoch)~step2(30epoch) まで、1e-3。step2 から 1e-4
step3 = len(ds) * 60
schedule = tf.optimizers.schedules.PiecewiseConstantDecay([ step1, step2, step3 ], [1e-4, 1e-3, 1e-4, 2e-5])
lr = schedule( step )
#optimizer = keras.optimizers.Adam(learning_rate)
optimizer = keras.optimizers.Adam(learning_rate=lr)
model.compile(optimizer=optimizer, loss=loss_fn)
学習
#学習
epochs = 100
history = model.fit(ds, validation_data=val_ds, callbacks=[display_cb,EarlyStopping(monitor='loss', patience=5, verbose=1, mode='auto')],
epochs=epochs)
モデルと history のセーブ
import pandas as pd
import matplotlib.pyplot as plt
model.save( "model/foldername/")
hist_df = pd.DataFrame(history.history)
hist_df.to_csv('basename.csv', header=False, index=False)
plt.figure()
hist_df[['loss', 'val_loss']].plot()
plt.ylabel('loss')
plt.xlabel('epoch')
plt.savefig(os.path.join("./", 'loss.png'))
よろしくお願いいたします。