1. はじめに
本記事は、2025年9月に開催されたJAWS-UG山梨での登壇内容を記事としてまとめたものです。
画像認識AIの世界では、すでに多くの学習済みモデルが提供されており、誰でも簡単に「それが何か」を判別できるようになりました。しかし、実ビジネスや特定のプロジェクトにおいて、汎用モデルが提供する情報の粒度が、必ずしも自分の使いたいユースケースに合致しているとは限りません。
例えば「お寿司」を判別したい場合、汎用的なモデルであれば、それが「食べ物」であることや「お寿司」であることまでは正しく認識できるでしょう。しかし、実際にやりたいことが「どのネタがいくつあるかを管理したい」というレベルだった場合、それが「マグロ」なのか「サーモン」なのか、あるいは「ビンチョウマグロ」なのかという細かな種類の違いまでは判別できないという壁にぶつかります。
このように、 「対象物は認識できるが、目的とする粒度には達していない」 という課題を解決するのが、Amazon Rekognition Custom Labelsによる独自モデルの構築です。
本プロジェクトでは、この「寿司ネタの識別」を題材に、学習データの量やモデルの規模が識別精度にどのような影響を与えるのかを定量的に検証しました。そのプロセスと知見を詳しく共有します。
2. Amazon Rekognition 標準機能における課題
検証の第一歩として、まずはAmazon Rekognitionの標準機能である「ラベル検出(Label Detection)」を使い、お寿司の画像をどこまで詳細に識別できるかをテストしました。
しかし、結果は「実用的な粒度」には程遠いものでした。

標準機能での検証結果
- 誤認識の発生: 寿司が「Pork(豚肉)」と判定される。
- 情報不足: 認識される物体の数が少なく、詳細なネタの種類までは特定できない。
この結果から、特定の専門ドメインにおいて高精度な識別を実現するには、独自のデータセットによる再学習(Custom Labels)が必要であるという結論に至りました。
3. カスタムラベルを用いた独自モデルの構築
「マグロ」を「マグロ」として正しく識別できる専用モデル「Amazon Rekognition ver.sushi」を構築しました。
データセットの準備とアノテーション
著作権や利用規約などの権利関係で問題にならないよう、学習データはすべて実写で用意しました。
- 分類対象: 寿司ネタ12種類(まぐろ、サーモン、えび等)
- 撮影データ: すべて独自に撮影した画像を使用し、実環境に近い条件を揃えました。
- アノテーション: 各画像に対してバウンディングボックスを設定し、正確なラベル付けを行いました。
精度検証パターンの設計
学習パラメーターの変化が精度に与える影響を測定するため、以下の変数でモデルを複数パターン作成しました。
| 項目 | 設定内容 |
|---|---|
| モデルサイズ | small / medium / large の3種類 |
| トレーニングデータ数 | 60枚(各5枚) / 120枚(各10枚) / 240枚(各20枚) |
| テストデータ数 | 36枚(全モデル共通) |
4. 性能評価による検証
各モデル学習後の性能評価(F1スコア、適合率、再現率等)を比較した結果、以下の知見が得られました。
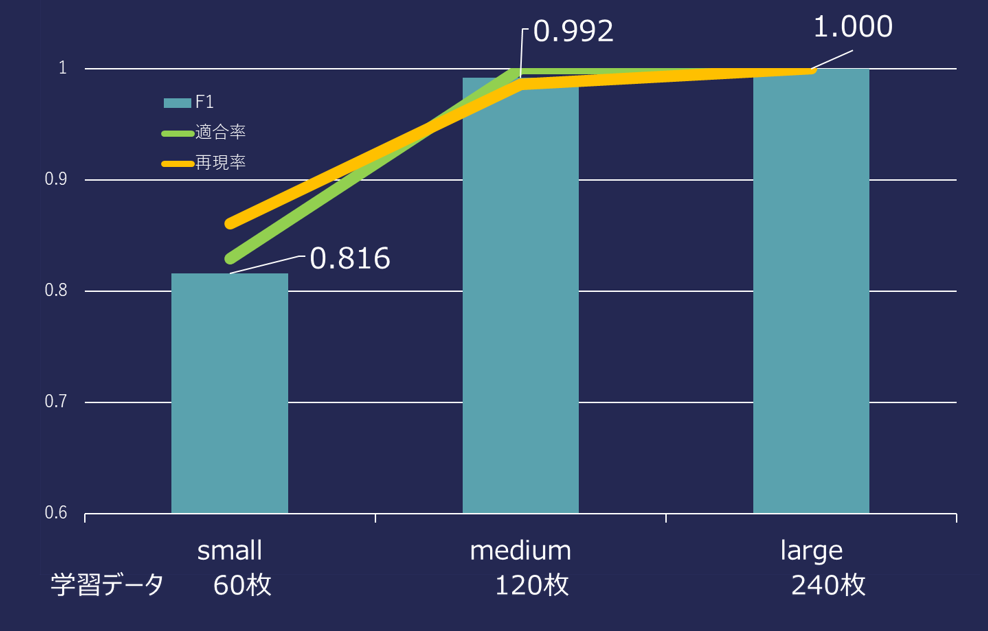
データ量と精度の関係
-
学習データ量の重要性:
データ量を増やすほど、各ラベルの再現率が安定し、モデルの信頼性が着実に向上することを確認しました。 -
少枚数での高パフォーマンス:
Mediumモデルにおいて、各ネタ10〜20枚程度の学習で、適合率・再現率ともに98%超という極めて高い数値を記録。 少量の特化データでも、即戦力となるモデルを構築できる ポテンシャルの高さが証明されました。
5. 推論テストによる検証
定量的な評価に加え、トレーニング・テストのいずれにも含まれない 「未知の検証用データ」 を用いて、モデルごとの推論結果を比較しました。
検証用データによる比較結果

モデルの規模(Small / Medium / Large)が上がるにつれて、以下の傾向が顕著に見られました。
-
検出枠の正確性と信頼度の向上:
モデルが大きくなるにつれ、対象物を囲むバウンディングボックスの精度が向上し、推論の「信頼度」も全体的に高くなる傾向を確認しました。
「Pork」誤認画像への再チャレンジ
標準機能で「Pork(豚肉)」と誤認された難易度の高い画像に対し、構築したLargeモデルで改めて推論を検証しました。

-
挙動の変化:
標準機能に比べて検出される枠(バウンディングボックス)の数が増え、AIがより多くの特徴を捉えようとする姿勢が見て取れました。 -
精度の限界:
一方で、検出された枠の位置にはズレが生じており、信頼度も依然として低い数値に留まりました。
6. 考察:
今回の検証から、以下の技術的知見が得られました。
-
モデルの「賢さ」の限界:
モデルサイズを上げることで検出の感度は高まりますが、難易度の高い(特徴が捉えにくい)画像に対しては、モデルの規模だけで解決するのは難しいことが分かりました。 -
データの多様性の重要性:
枠がズレる、あるいは信頼度が低い原因として、特定の角度や照明条件のデータがまだ不足している可能性が考えられました。「えび」のように形状が独特なものは少ない枚数でも学習が進みますが、色味や質感が似たネタを完璧に識別するには、さらなる データのバリエーション(質の管理) が不可欠だと思われます。
6. まとめ
Amazon Rekognition Custom Labels を活用することで、汎用AIでは到達できない特定領域の識別モデルを、 短期間かつ少量のデータセットから構築可能 であることを確認できました。
今回の検証を通じて得られた主要な結論は以下の通りです。
-
「データ量」は精度向上の最短ルート:
モデルの規模を追うよりも、まずは1種類あたり10〜20枚程度の良質なデータを揃えることで、適合率・再現率ともに98%超という実用的なラインに到達できます。 -
モデルサイズと検出能力の特性:
モデルサイズを上げることで検出の感度(枠の数や信頼度)は向上しますが、必ずしも「位置の正確さ」に直結するわけではありません。難易度の高い画像には、モデルの大型化だけでなくデータの多様性が不可欠でした。
今後の展望
今回の検証で、特定の条件下ではまだ「枠のズレ」や「信頼度の低さ」が見られるという改善ポイントも明確になりました。今後は、エッジケース(似た色味のネタや特殊な照明環境)のデータを重点的に補強し、APIとしてアプリケーションへ統合などもしていけたらいいなと思っています。