東洋経済オンラインのデータを利用して、クエリーを作り直しました。
GitHubに公開しました。
2020/03/11からのデータになります。
そのため、Bubble Chartなどは欠損データを直近の値で埋めています。
![]() NHKのデータって公開利用するのにお断りとかどうすればいいのだろ。
NHKのデータって公開利用するのにお断りとかどうすればいいのだろ。
また、いつの間にかデータの形が変更になっていたので、本文及びgithubも修正しました(2020/05/29)
データの取得
pythonによる取得
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import json
headers={'accept': 'application/json', 'content-type': 'application/json'}
response = json.loads(requests.get('https://raw.githubusercontent.com/kaz-ogiwara/covid19/master/data/data.json', headers=headers).text)
print(json.dumps(response))
単純にgithubからデータを取得したものを表示するだけの単純なスクリプト
今回は検索時に加工してみた。 ![]() 結果大変なことに
結果大変なことに
inputs.conf
[script://$SPLUNK_HOME/etc/apps/covid19_japan/bin/dl_toyo.py]
disabled = false
python.version = python3
interval = 43200
sourcetype = toyo_json
source = toyodata.json
今回は12時間に1回
CRONも使えるはず
実行したかの確認は
index=_internal dl_toyo.py sourcetype=splunkd
04-26-2020 06:38:33.161 +0900 INFO ExecProcessor - New scheduled exec process: /Applications/Splunk/bin/python3.7 /Applications/Splunk/etc/apps/covid19_japan/bin/dl_toyo.py
props.conf
[toyo_json]
TIME_PREFIX = Last\supdated:\s
TIME_FORMAT = %d %B %Y
INDEXED_EXTRACTIONS = json
KV_MODE = none
LINE_BREAKER = ([\r\n]+)
NO_BINARY_CHECK = true
category = Structured
description = json
disabled = false
pulldown_type = true
SHOULD_LINEMERGE = false
TRUNCATE = 0
時間については取得日次ではなく、データの更新日にしてみた。
ただ、そのため検索する時「全時間」を使用しなければならなくなったので良し悪し。
DATETIME_CONFIG = CURRENT とかでもいいと思います。
INDEXED_EXTRACTIONSは入れてはみたものの、結局使わないのでKV_MODEと共にnoneで問題ないです。
ChroplethMap用データの入手及び加工
前回の記事を参考に準備してください。
ダッシュボードの作成(5/29修正)
<dashboard theme="dark">
<label>COVID-19 in Japan</label>
<search id="base">
<query>sourcetype=toyo_json
| head 1</query>
<earliest>0</earliest>
<latest></latest>
</search>
<search base="base" id="base1">
<query>
| rex "prefectures-data.*?(?<data>{.*?})"
| rex field=data "carriers.*?\[(?<carriers>\[.*?\])\]"
| rex max_match=0 field=carriers "(?<daily>\[[^\[\]]+\])"
| spath prefectures-map{} output=prefectures_map
| eval sorter=mvrange(0,mvcount(daily))
| eval daily=mvzip(sorter,daily)
| stats list(prefectures_map) as prefectures_map by daily
| mvexpand prefectures_map
| spath input=prefectures_map
| table daily code ja
| eval ja=code."_".ja
| xyseries daily ja code
| foreach *_* [ eval <<FIELD>> = mvindex(split(daily,","),'<<FIELD>>')]
| untable daily pref count
| eval daily=mvindex(split(daily,","),0)
| sort daily pref
| eval _time = if(daily=0,strptime("2020-03-11","%F"),relative_time(strptime("2020-03-11","%F"),("+".daily."d@d")))
| rex field=count "(?<count>\d+)"
| xyseries _time pref count
| rename COMMENT as "ここでいったん県名のフィールドで作成している。ここから北海道からの順番に並び替えている"
</query>
</search>
<row>
<panel>
<html>このダッシュボードは東洋経済オンライン(<a href="https://toyokeizai.net/sp/visual/tko/covid19/">https://toyokeizai.net/sp/visual/tko/covid19/</a>)のデータを利用しています。</html>
</panel>
</row>
<row>
<panel>
<title>最終更新日: $lastUpdate$</title>
<single>
<title>感染者数</title>
<search base="base1" id="base2">
<query>
| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| transpose 0 header_field=pref column_name=_time
| rename COMMENT as "ここで時間+県名の表"
| addtotals
| eventstats max(_time) as time
| eval time=strftime(time,"%F")
| fields _time Total time</query>
<done>
<set token="lastUpdate">$result.time$</set>
</done>
</search>
<option name="drilldown">none</option>
</single>
<table>
<title>感染者数増加率</title>
<search base="base1">
<query>| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| rename COMMENT as "ここまでが県名と日次累計データの作成、ここでやっとNHKのクエリーが使える"
| rename pref as _pref
| transpose 0 header_field=_pref column_name=_time
| sort _time
| tail 2
| reverse
| eval _time=strftime(_time,"%F")
| transpose 0 header_field=_time column_name=_pref
| foreach * [eval tmp=mvappend(tmp,'<<FIELD>>'), first = max(tmp) , second = min(tmp)
| eval daily_incr = if(isnull(nullif(second,0)), round(first * 100.00,2), round((first -second) / second * 100,2))]
| eval daily_count = first - second
| sort - daily_incr
| fields - first second tmp
| rename _pref as "都道府県", daily_incr as "増加率", daily_count as "日次感染者数"
| table 都道府県 * 日次感染者数 増加率</query>
</search>
<option name="drilldown">none</option>
<option name="refresh.display">progressbar</option>
<format type="number" field="増加率">
<option name="unit">%</option>
</format>
</table>
</panel>
<panel>
<map>
<search>
<query>sourcetype=toyo_json
| head 1
| spath prefectures-map{} output=prefectures_map
| stats count by prefectures_map
| spath input=prefectures_map
| table code ja en value
| sort - value
| geom japansimple featureIdField=en
| fields - code ja</query>
<earliest>0</earliest>
<latest></latest>
<sampleRatio>1</sampleRatio>
</search>
<option name="drilldown">none</option>
<option name="height">600</option>
<option name="mapping.choroplethLayer.colorMode">categorical</option>
<option name="mapping.map.center">(38.62,137.55)</option>
<option name="mapping.map.zoom">5</option>
<option name="mapping.type">choropleth</option>
</map>
</panel>
</row>
<row>
<panel>
<chart>
<title>日次感染率</title>
<search base="base2">
<query>
| streamstats count(_time) as days
| fields _time Total days
| rename "Total" as "Total Cases"
| eval "Overall Infection Rate"='Total Cases'/days
| eventstats max("Overall Infection Rate") as "Maximum Infection Rate"
| rename "Total Cases" as "TotalCases"
| streamstats current=f window=2 last(TotalCases) as last
| eval perc_incr=((TotalCases-last)/last)*100
| rename TotalCases as "Total Cases", perc_incr as "Daily Infection Rate"
| fields - last
| fields _time "Total Cases" "Daily Infection Rate"</query>
</search>
<option name="charting.axisY2.enabled">1</option>
<option name="charting.chart">area</option>
<option name="charting.chart.overlayFields">"Total Cases"</option>
<option name="charting.drilldown">none</option>
<option name="charting.legend.placement">bottom</option>
<option name="height">600</option>
</chart>
</panel>
<panel>
<chart>
<title>感染者数上位10都道府県日次感染者数 ※2020/3/11以前は3/11の数で補間</title>
<search base="base1">
<query>| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| rename COMMENT as "ここまでが県名と日次累計データの作成、ここでやっとNHKのクエリーが使える"
| rename pref as _pref
| foreach * [eval Check=max('<<FIELD>>')]
| sort 10 - Check
| fields - Check
| transpose 0 header_field=_pref column_name=_time
| rename COMMENT as "最初の感染者が出た日からにしている。"
| append [|makeresults
| eval _time = strptime("2020-01-16","%F")]
| makecontinuous _time span=1d
| reverse
| streamstats count(eval(isnull('東京都'))) as _count
| filldown
| foreach * [eval <<FIELD>> = if(_count=0,'<<FIELD>>', round('<<FIELD>>' / _count))]
| reverse
| rename COMMENT as "空白は最初の値、2020/3/11の値からの計算値で埋めている。"
| untable _time pref count
| sort _time
| streamstats count as days by pref
| streamstats current=f max(count) as prev by pref
| eval daily_count = count - prev
| table pref days count daily_count
| sort 0 - count</query>
</search>
<option name="charting.chart">bubble</option>
<option name="charting.chart.bubbleMaximumSize">30</option>
<option name="charting.chart.bubbleMinimumSize">5</option>
<option name="charting.drilldown">none</option>
<option name="charting.legend.placement">bottom</option>
<option name="height">600</option>
<option name="refresh.display">progressbar</option>
</chart>
</panel>
</row>
</dashboard>
データの形式が変更されていたため、修正した。以前のSimpleXmlはこちら
```xml:covid19_in_japan.xml COVID-19 in Japan sourcetype=toyo_json | head 1 0 | rex "prefectures-data.*?(?<data>{.*?})" | rex field=data "carriers.*?\[(?<carriers>\[.*?\])\]" | rex max_match=0 field=carriers "(?<daily>\[[^\[\]]+\])" | spath prefectures-map{} output=prefectures_map | stats count list(prefectures_map) as pref by daily | eval date=mvindex(split(trim(daily,"[]"),","),0,2) , data=mvindex(split(trim(daily,"[]"),","),3,-1) | eval _time=strptime(mvjoin(date,""),"%Y%m%d") | mvexpand data | table _time data count pref | streamstats count | eval count = nullif(count % 47,0) | fillnull count value=47 | eval data=trim(data) ,pref=mvindex(pref,count-1) | spath input=pref | eval ja=code."_".ja | table _time ja data | sort 0 - _time data | xyseries _time ja data | rename COMMENT as "ここでいったん県名のフィールドで作成している。ここから北海道からの順番に並び替えている" このダッシュボードは東洋経済オンライン(https://toyokeizai.net/sp/visual/tko/covid19/)のデータを利用しています。 最終更新日: $lastUpdate$ 感染者数 | transpose 0 header_field=_time column_name=pref | sort pref | eval pref = mvindex(split(pref,"_"),1) | transpose 0 header_field=pref column_name=_time | rename COMMENT as "ここで時間+県名の表" | addtotals | eventstats max(_time) as time | eval time=strftime(time,"%F") | fields _time Total time $result.time$ none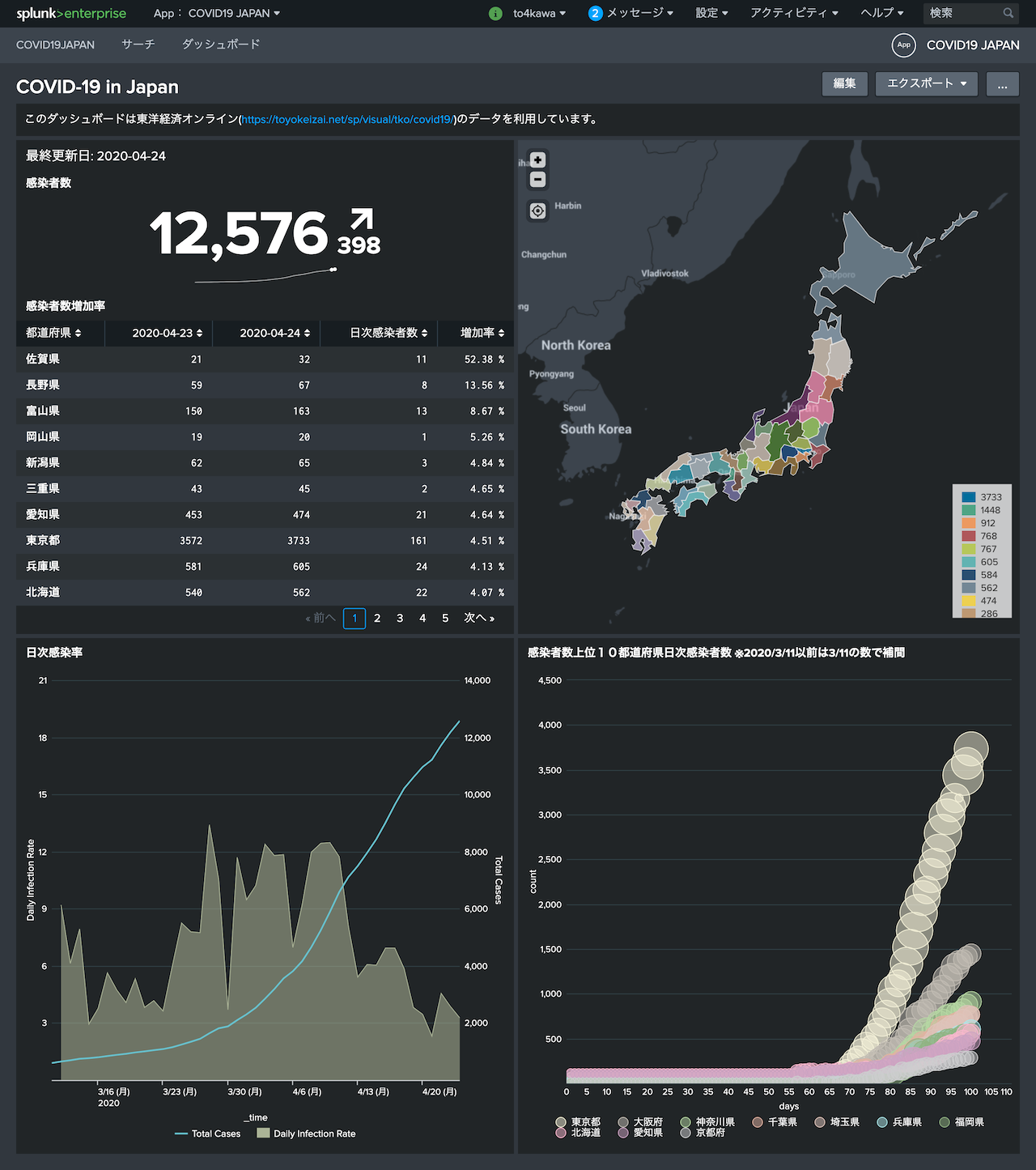
データについて
Splunkからすると階層が深いJSON。
配列を使って取り出すjavascriptの世界だと扱いやすいのだろうが、Splunkからするとほとんど悪夢です。
sourcetype=toyo_json
| head 1
| spath prefectures-map{} output=prefectures_map
| stats count by prefectures_map
| spath input=prefectures_map
| table code ja en
| sort code
とかはまだ素直に取り出せます。
その他のデータはかなり大変です。
一応NHKのデータを使用したものと同じ形までもっていったクエリーがこちら
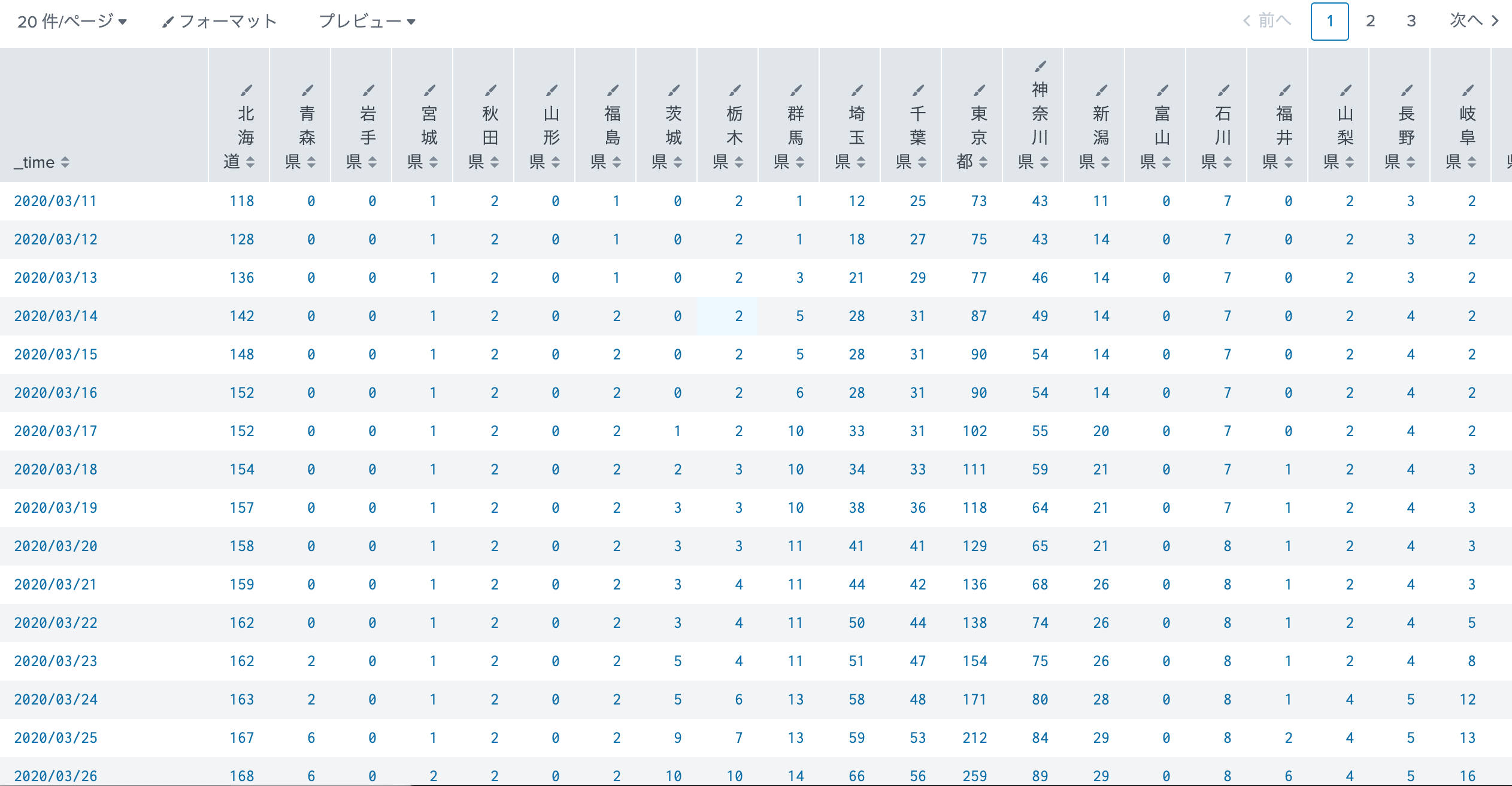
日次統計(累計値)
sourcetype=toyo_json
| head 1 | rex "prefectures-data.*?(?<data>{.*?})"
| rex field=data "carriers.*?\[(?<carriers>\[.*?\])\]"
| rex max_match=0 field=carriers "(?<daily>\[[^\[\]]+\])"
| spath prefectures-map{} output=prefectures_map
| eval sorter=mvrange(0,mvcount(daily))
| eval daily=mvzip(sorter,daily)
| stats list(prefectures_map) as prefectures_map by daily
| mvexpand prefectures_map
| spath input=prefectures_map
| table daily code ja
| eval ja=code."_".ja
| xyseries daily ja code
| foreach *_* [ eval <<FIELD>> = mvindex(split(daily,","),'<<FIELD>>')]
| untable daily pref count
| eval daily=mvindex(split(daily,","),0)
| sort daily pref
| eval _time = if(daily=0,strptime("2020-03-11","%F"),relative_time(strptime("2020-03-11","%F"),("+".daily."d@d")))
| rex field=count "(?<count>\d+)"
| xyseries _time pref count
| rename COMMENT as "ここでいったん県名のフィールドで作成している。ここから北海道からの順番に並び替えている"
| rename COMMENT as "ここまでがその他のパネルのベースとなる検索 「base1」"
| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| transpose 0 header_field=pref column_name=_time
解説
-
head 1で最新のデータのみを指定 - 感染者数を抽出するために、いったん_prefectures-data_を抽出したあと、_carriers_を正規表現で抽出している。
データの形式は日付が最初の3つ、あとは都道府県の累計値データ
[118, 0, 0, 1, 2, 0, 1, 0, 2, 1, 12, 25, 73, 43, 11, 0, 7, 0, 2, 3, 2, 2, 104, 2, 1, 15, 81, 35, 8, 14, 0, 0, 0, 1, 3, 1, 0, 2, 12, 3, 0, 0, 6, 1, 1, 0, 3]
- このデータと
spathで切り出した県名をstatsで抽出している。 - 日付のデータがなくなってしまったので、ソート用の数字を付加している。
-
statsで必要なフィールドだけを抽出 - この段階で_pref_はmultivalueになっているので
mvexpandした後、xyseriesで47都道府県のデータにしている。。 - _pref_もJSONなので
spathして、あとでソートするために番号を付けてあげる -
xyseriesの段階で形はできている。ただし、順番がばらばら -
transposeを繰り返して、北海道からの順番にしてあげている。
とりあえずベースとなるクエリーになる。
ダッシュボードの構成要素の解説
ここからはダッシュボードの各パネルについて解説
ベースとなる検索は省略します。
感染者数及び更新日
<panel>
<title>最終更新日: $lastUpdate$</title>
<single>
<title>感染者数</title>
<search base="base1" id="base2">
<query>
| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| transpose 0 header_field=pref column_name=_time
| rename COMMENT as "ここで時間+県名の表"
| addtotals
| eventstats max(_time) as time
| eval time=strftime(time,"%F")
| fields _time Total time</query>
<done>
<set token="lastUpdate">$result.time$</set>
</done>
</search>
<option name="drilldown">none</option>
</single>
表示しているのは_Total_の値
_time_をパネル表示するために他のフィールドを作ってみた。
epoch時間を扱うときearliest latestを使わずmax minを使うのは動作が安定しているからです。以前確認してみました。
感染者数増加率
<table>
<title>感染者数増加率</title>
<search base="base1">
<query>| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| rename COMMENT as "ここまでが県名と日次累計データの作成、ここでやっとNHKのクエリーが使える"
| rename pref as _pref
| transpose 0 header_field=_pref column_name=_time
| sort _time
| tail 2
| reverse
| eval _time=strftime(_time,"%F")
| transpose 0 header_field=_time column_name=_pref
| foreach * [eval tmp=mvappend(tmp,'<<FIELD>>'), first = max(tmp) , second = min(tmp)
| eval daily_incr = if(isnull(nullif(second,0)), round(first * 100.00,2), round((first -second) / second * 100,2))]
| eval daily_count = first - second
| sort - daily_incr
| fields - first second tmp
| rename _pref as "都道府県", daily_incr as "増加率", daily_count as "日次感染者数"
| table 都道府県 * 日次感染者数 増加率</query>
</search>
<option name="drilldown">none</option>
<option name="refresh.display">progressbar</option>
<format type="number" field="増加率">
<option name="unit">%</option>
</format>
</table>
感染者数増加率の解説
![]() コメントは残しました。
コメントは残しました。
詳細は前回の記事を確認ください。
日本語のフィールド名と%を単位としたので表示が綺麗になっています。
Cholopreth Map
sourcetype=toyo_json
| head 1
| spath prefectures-map{} output=prefectures_map
| stats count by prefectures_map
| spath input=prefectures_map
| table code ja en value
| sort - value
| geom japansimple featureIdField=en
| fields - code ja
これはデータに英語・日本語の都道府県名が入っているのですっきり表示ができる。
Daily Infection Rate
<panel>
<chart>
<title>日次感染率</title>
<search base="base2">
<query>
| streamstats count(_time) as days
| fields _time Total days
| rename "Total" as "Total Cases"
| eval "Overall Infection Rate"='Total Cases'/days
| eventstats max("Overall Infection Rate") as "Maximum Infection Rate"
| rename "Total Cases" as "TotalCases"
| streamstats current=f window=2 last(TotalCases) as last
| eval perc_incr=((TotalCases-last)/last)*100
| rename TotalCases as "Total Cases", perc_incr as "Daily Infection Rate"
| fields - last
| fields _time "Total Cases" "Daily Infection Rate"</query>
</search>
<option name="charting.axisY2.enabled">1</option>
<option name="charting.chart">area</option>
<option name="charting.chart.overlayFields">"Total Cases"</option>
<option name="charting.drilldown">none</option>
<option name="charting.legend.placement">bottom</option>
<option name="height">600</option>
</chart>
</panel>
本家で表示している日次感染率
基本は_Area Chart_でTotal Casesの値を_Line Chart_をオーバーレイしている。
Bubble Chart
<chart>
<title>感染者数上位10都道府県日次感染者数 ※2020/3/11以前は3/11の数で補間</title>
<search base="base1">
<query>| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| rename COMMENT as "ここまでが県名と日次累計データの作成、ここでやっとNHKのクエリーが使える"
| rename pref as _pref
| foreach * [eval Check=max('<<FIELD>>')]
| sort 10 - Check
| fields - Check
| transpose 0 header_field=_pref column_name=_time
| rename COMMENT as "最初の感染者が出た日からにしている。"
| append [|makeresults
| eval _time = strptime("2020-01-16","%F")]
| makecontinuous _time span=1d
| reverse
| streamstats count(eval(isnull('東京都'))) as _count
| filldown
| foreach * [eval <<FIELD>> = if(_count=0,'<<FIELD>>', round('<<FIELD>>' / _count))]
| reverse
| rename COMMENT as "空白は最初の値、2020/3/11の値からの計算値で埋めている。"
| untable _time pref count
| sort _time
| streamstats count as days by pref
| streamstats current=f max(count) as prev by pref
| eval daily_count = count - prev
| table pref days count daily_count
| sort 0 - count</query>
</search>
<option name="charting.chart">bubble</option>
<option name="charting.chart.bubbleMaximumSize">30</option>
<option name="charting.chart.bubbleMinimumSize">5</option>
<option name="charting.drilldown">none</option>
<option name="charting.legend.placement">bottom</option>
<option name="height">600</option>
<option name="refresh.display">progressbar</option>
</chart>
いったんあるデータだけでつくったら、いきなり上がってきた感がなくなってしまっている。
そのため感染者数が確認された2020/01/16からの日付をつくって、空白を直近の値から徐々に(![]() でもないですね)下げている。
でもないですね)下げている。
円の大きさは、一日の感染者数にしました。
その他
つくってはみたもののレイアウト的にやめたもの
Area Chart
sourcetype=toyo_json
| head 1
| rex "prefectures-data.*?(?<data>{.*?})"
| rex field=data "carriers.*?\[(?<carriers>\[.*?\])\]"
| rex max_match=0 field=carriers "(?<daily>\[[^\[\]]+\])"
| spath prefectures-map{} output=prefectures_map
| stats count list(prefectures_map) as pref by daily
| eval date=mvindex(split(trim(daily,"[]"),","),0,2) , data=mvindex(split(trim(daily,"[]"),","),3,-1)
| eval _time=strptime(mvjoin(date,""),"%Y%m%d")
| mvexpand data
| table _time data count pref
| streamstats count
| eval count = nullif(count % 47,0) | fillnull count value=47
| eval data=trim(data) ,pref=mvindex(pref,count-1)
| spath input=pref
| eval ja=code."_".ja
| table _time ja data
| sort 0 - _time data
| xyseries _time ja data
| rename COMMENT as "ここでいったん県名のフィールドで作成している。ここから北海道からの順番に並び替えている"
| transpose 0 header_field=_time column_name=pref
| sort pref
| eval pref = mvindex(split(pref,"_"),1)
| rename COMMENT as "ここまでが県名と日次累計データの作成、ここでやっとNHKのクエリーが使える"
| rename pref as _pref
| foreach * [eval Check=max('<<FIELD>>')]
| sort 10 - Check
| fields - Check
| transpose 0 header_field=_pref column_name=_time
| sort _time
Area ChartのStack modeで表示するといい感じです。
GitHubへ掲示
ディレクトリ構成は以下の通り
.
├── bin
│ ├── README
│ └── dl_toyo.py
├── default
│ ├── app.conf
│ └── data
│ └── ui
│ ├── nav
│ │ └── default.xml
│ └── views
│ └── README
├── local
│ ├── app.conf
│ ├── data
│ │ └── ui
│ │ └── views
│ │ └── covid19_in_japan.xml
│ ├── inputs.conf
│ ├── props.conf
│ └── transforms.conf
├── lookups
│ ├── japansimple
│ │ ├── grid.key
│ │ ├── grid.val
│ │ ├── ray.key
│ │ ├── ray.t.key
│ │ ├── ray.t.val
│ │ ├── ray.val
│ │ ├── seg.key
│ │ ├── seg.t.key
│ │ ├── seg.t.val
│ │ └── seg.val
│ └── japansimple.kml
└── metadata
├── default.meta
└── local.meta
https://github.com/to4kawa/Covid19_in_japan
にリポジトリを作成、すべてのファイルをPushしてREADME.mdを作成した。
![]() 問題なくうごいてくれるといいな。
問題なくうごいてくれるといいな。
まとめ
とりあえずできました。
Appsを作ってlookupsフォルダを作って
| フォルダ | ファイル |
|---|---|
| $SPLUNK_HOME/etc/apps/{app_name}/local/ |
inputs.conf props.conf |
| $SPLUNK_HOME/etc/apps/{app_name}/bin | dl_toyo.py |
| $SPLUNK_HOME/etc/apps/{app_name}/lookups | prefecture.csv |
| $SPLUNK_HOME/etc/apps/{app_name}/local/data/ui/views |
covid19_in_japan.xml (ダッシュボードのファイル) |
を配置すると動くはずです。なお、japansimple.kmlは先に入れておいてください。
JSONについてはこれまでSplunkでやってきたのでなんとかなりましたが、Python側で加工した方が、楽のような気がしてます。
GitHubに掲載したものはjapansimple.kmlを同封しました。
自分がmacosxということもあり、Windowsでの動作に自身がないです。
少なくともinputs.confのディレクトリの記述は修正する必要があるでしょう。
![]() ここら辺どうすればいいのでしょうかね
ここら辺どうすればいいのでしょうかね