以前の記事が_props.conf_とか消せなくてごちゃっとしてきたのとSPLが間違っていたので、改めて書き直します。
(4/10 100日以上の期間に対応するためSPLを修正しました)
のデータを使用しています。
作成している方々に感謝します。
Appsの作成
とりあえずはlookupや設定を分離したいのでAppsを作成する。
.
├── bin
│ └── README
├── default
│ ├── app.conf
│ └── data
│ └── ui
│ ├── nav
│ │ └── default.xml
│ └── views
│ └── README
├── local
│ └── app.conf
├── lookups
└── metadata
├── default.meta
└── local.meta
_lookups_は本家Splunk corona_virusで作っていたので、同様にmkdirした。
後ほど、地図データ等を格納する。
Choropleth Map
階級区分図
日本の地図はデフォルトではない。国土地理院のデータは大きすぎて扱いづらい。
いろいろ探してみるとRのパッケージのデータがいい感じでした。
解凍したNipponMapの.shpファイルを.kmlに変換する。
CLI
gdalを利用する。
macosxだとbrew install gdalでOK、windowsはAnacondaがいるみたいです。
ogr2ogr -f "KML" -mapFieldType Integer64=Real 'japansimple.kml' jpn.shp
GUI
QGISをインスートールして
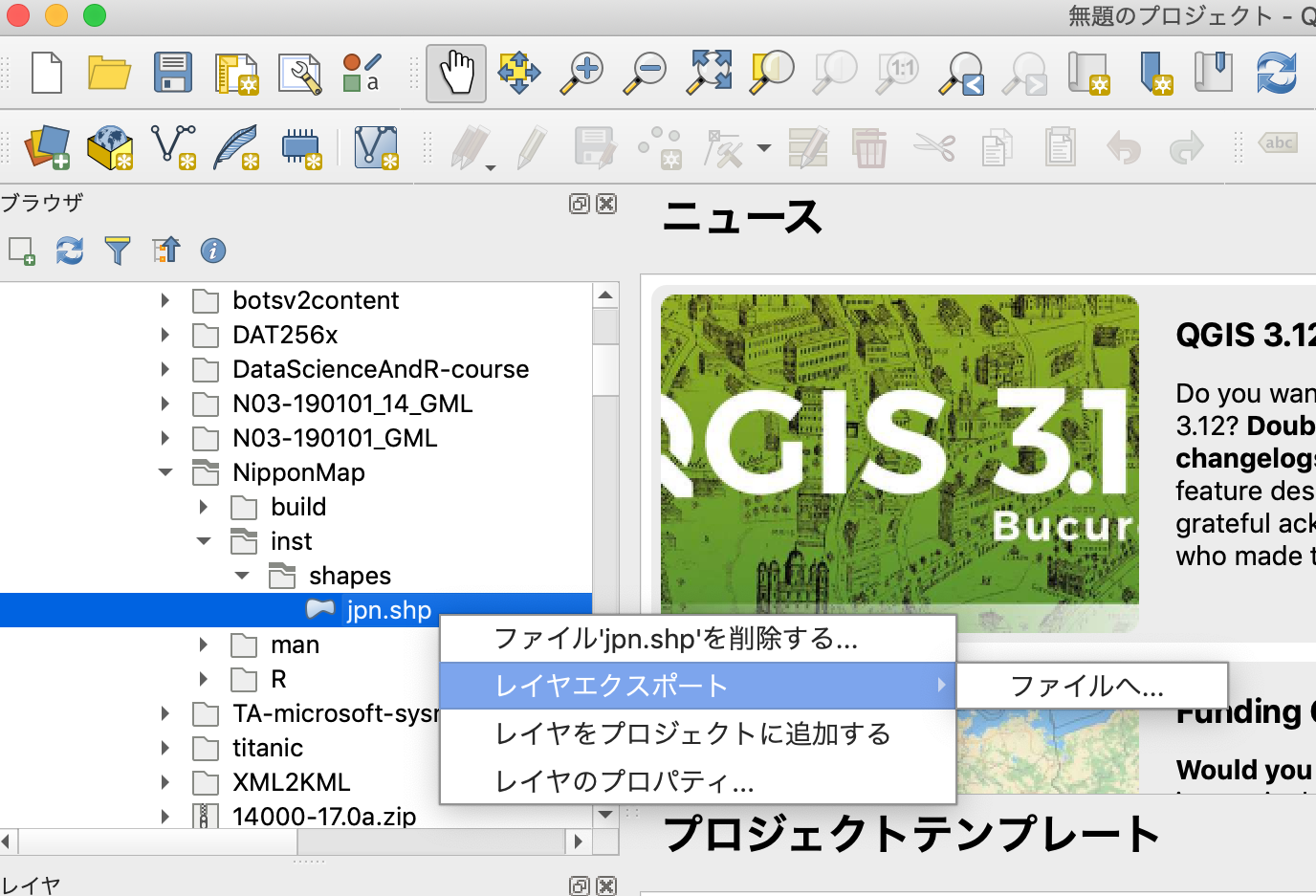
解凍したNipponMapのファイルをKMLにエクスポート
ルックアップの作成
Choroplethで都道府県 市町村に対応!@takashikomatsubの資料をみながら、Splunkに取り込み
このデータだとXPATHの指定は不要
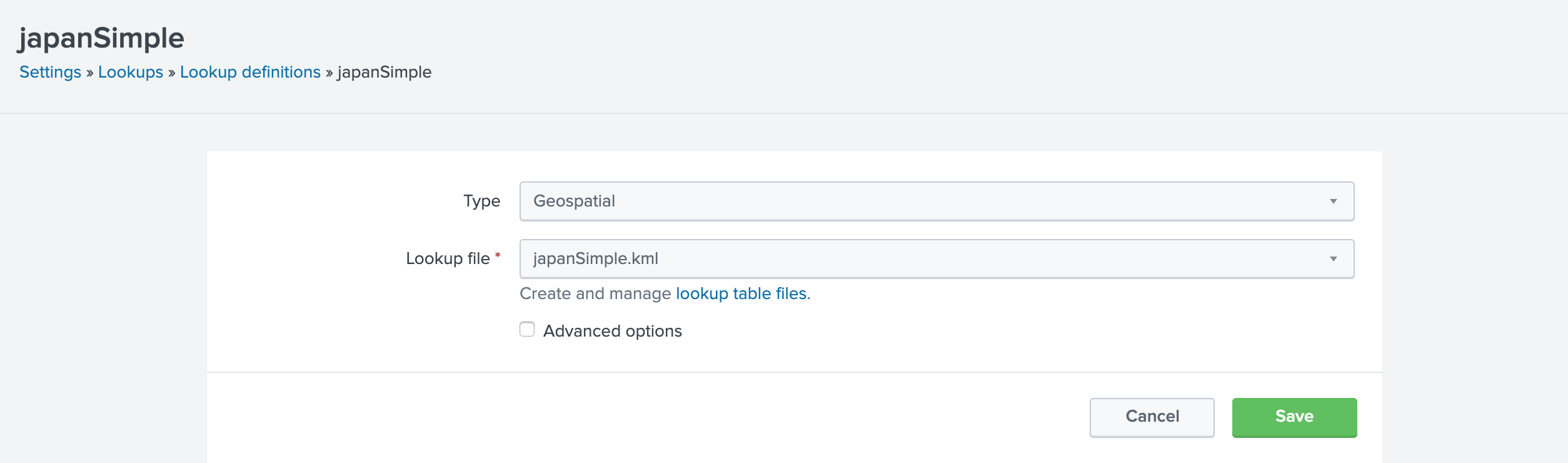
データの確認
|inputlookup japanSimple
データの入手
東洋経済Online 新型コロナウイルス国内感染の状況 から
https://github.com/kaz-ogiwara/covid19/
にあるデータが県別にまとまっているので、こちらを使用してみる
MITライセンスなので、使いやすい
ただし、4月6日現在確認したところ3月24日で更新が止まっている。
再開を期待します。
データはindividuals.csv
ダウンロード用スクリプトの作成
"newNo","oldNo","year","month","day","old","gender","pref","city"
# !/bin/zsh
url='https://raw.githubusercontent.com/kaz-ogiwara/covid19/master/data/individuals.csv'
cd ../lookups
curl -fsX GET $url -o individuals.csv
{cat header.txt; tail -n +2 individuals.csv} > japan.csv
Macosxなのでzsh. etc/apps/covid19_japan/bin配下に配置
やっていることは./lookups配下にCSVをダウンロードして
新しいヘッダーをつけているだけなので、powershellでもできると思います。
lookup
https://en.wikipedia.org/wiki/Prefectures_of_Japan
から県のデータを作成した。
prefecture.csv:
| Prefecture | Kanji | Capital | Region | Major_Island |
|---|---|---|---|---|
| Aichi | 愛知県 | Nagoya | Chubu | Honshu |
| Akita | 秋田県 | Akita | Tohoku | Honshu |
| Aomori | 青森県 | Aomori | Tohoku | Honshu |
| Chiba | 千葉県 | Chiba | Kanto | Honshu |
| Ehime | 愛媛県 | Matsuyama | Shikoku | Shikoku |
| Fukui | 福井県 | Fukui | Chubu | Honshu |
| Fukuoka | 福岡県 | Fukuoka | Kyushu | Kyushu |
| Fukushima | 福島県 | Fukushima | Tohoku | Honshu |
| Gifu | 岐阜県 | Gifu | Chubu | Honshu |
| Gunma | 群馬県 | Maebashi | Kanto | Honshu |
| Hiroshima | 広島県 | Hiroshima | Chugoku | Honshu |
| Hokkaido | 北海道 | Sapporo | Hokkaido | Hokkaido |
| Hyogo | 兵庫県 | Kobe | Kansai | Honshu |
| Ibaraki | 茨城県 | Mito | Kanto | Honshu |
| Ishikawa | 石川県 | Kanazawa | Chubu | Honshu |
| Iwate | 岩手県 | Morioka | Tohoku | Honshu |
| Kagawa | 香川県 | Takamatsu | Shikoku | Shikoku |
| Kagoshima | 鹿児島県 | Kagoshima | Kyushu | Kyushu |
| Kanagawa | 神奈川県 | Yokohama | Kanto | Honshu |
| Kochi | 高知県 | Kochi | Shikoku | Shikoku |
| Kumamoto | 熊本県 | Kumamoto | Kyushu | Kyushu |
| Kyoto | 京都府 | Kyoto | Kansai | Honshu |
| Mie | 三重県 | Tsu | Kansai | Honshu |
| Miyagi | 宮城県 | Sendai | Tohoku | Honshu |
| Miyazaki | 宮崎県 | Miyazaki | Kyushu | Kyushu |
| Nagano | 長野県 | Nagano | Chubu | Honshu |
| Nagasaki | 長崎県 | Nagasaki | Kyushu | Kyushu |
| Nara | 奈良県 | Nara | Kansai | Honshu |
| Niigata | 新潟県 | Niigata | Chubu | Honshu |
| Oita | 大分県 | Oita | Kyushu | Kyushu |
| Okayama | 岡山県 | Okayama | Chugoku | Honshu |
| Okinawa | 沖縄県 | Naha | Kyushu | Ryukyu Islands |
| Osaka | 大阪府 | Osaka | Kansai | Honshu |
| Saga | 佐賀県 | Saga | Kyushu | Kyushu |
| Saitama | 埼玉県 | Saitama | Kanto | Honshu |
| Shiga | 滋賀県 | Otsu | Kansai | Honshu |
| Shimane | 島根県 | Matsue | Chugoku | Honshu |
| Shizuoka | 静岡県 | Shizuoka | Chubu | Honshu |
| Tochigi | 栃木県 | Utsunomiya | Kanto | Honshu |
| Tokushima | 徳島県 | Tokushima | Shikoku | Shikoku |
| Tokyo | 東京都 | Shinjuku | Kanto | Honshu |
| Tottori | 鳥取県 | Tottori | Chugoku | Honshu |
| Toyama | 富山県 | Toyama | Chubu | Honshu |
| Wakayama | 和歌山県 | Wakayama | Kansai | Honshu |
| Yamagata | 山形県 | Yamagata | Tohoku | Honshu |
| Yamaguchi | 山口県 | Yamaguchi | Chugoku | Honshu |
| Yamanashi | 山梨県 | Kofu | Chubu | Honshu |
|
|
||||
| これもlookupsフォルダに入れておく |
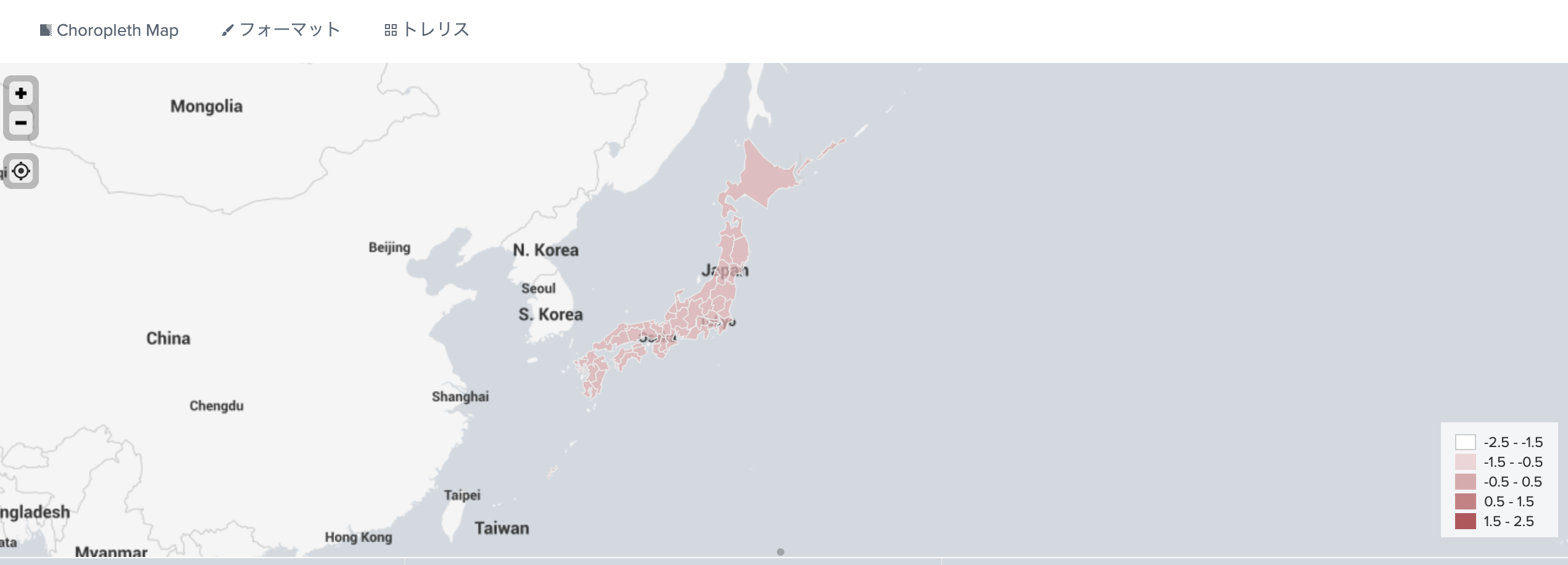
Choropleth Mapで表示
| inputlookup japan.csv
| stats count by pref
| lookup prefecture.csv Kanji as pref OUTPUT Prefecture as featureId
| fields - pref
| geom japansimple
| sort - count
データが3月24日までなので北海道が一番多い
予測
AppsをMLTKに切り替えてpredictで感染者数上位5県の推移をみてみる。
| inputlookup japan.csv
| eval _time=strptime(year." ".month." ".day,"%Y %m %d")
| timechart count as Counts by pref where sum in top5
| tail 60
| reverse
| predict 東京都 北海道 兵庫県 愛知県 大阪府 OTHER future_timespan=30
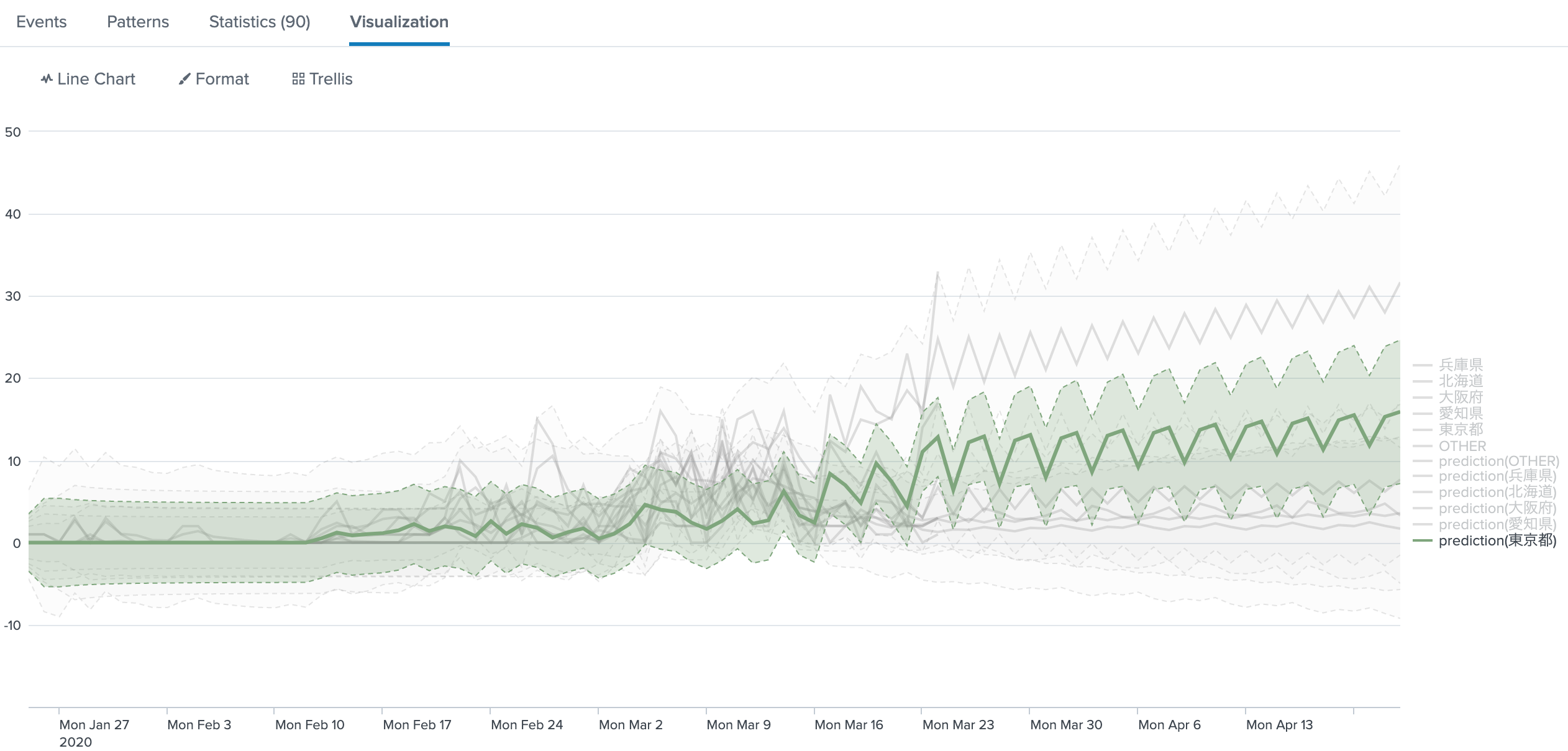
4月に入ってからこの図をみるとなかなか感慨深い
NHKのデータを利用する
都道府県別の感染者数(累計・NHKまとめ)のデータが都道府県別で集計されているので使用してみる。
データの取得
import requests
import json
headers = {'accept': 'application/json', 'content-type': 'application/json'}
url = 'https://www3.nhk.or.jp/news/special/coronavirus/data/47patients-data.json'
response=requests.get(url,headers=headers)
json_obj = response.json()
f = open("output.json","w")
json.dump(json_obj, f)
cd ../lookups
python ../bin/dl_json2.py
![]() 一回でできるpythonの技能がないためシエルスクリプトに頼ってしまう。
一回でできるpythonの技能がないためシエルスクリプトに頼ってしまう。
sedが便利すぎて離れられない。
なお、Python 3.7.6
indexに読み込み
[covid19normal_json]
DATETIME_CONFIG = CURRENT
INDEXED_EXTRACTIONS = json
## KV_MODE = none
## LINE_BREAKER = }(.)|(.){\"data|(.) \"category
## NO_BINARY_CHECK = true
## category = Structured
## description = json
## disabled = false
## pulldown_type = true
## SHOULD_LINEMERGE = false
TRUNCATE = 0
## SEDCMD-trim = s/\],\"unit.*$//
## SEDCMD-category = s/(.category.*?\]).*/{\1}/
## TRANSFORMS-null = json_null
[japansimple]
case_sensitive_match = 1
external_type = geo
filename = japansimple.kml
## [json_null]
## REGEX = title|unit|caution
## DEST_KEY = queue
## FORMAT = nullQueue
Choropleth Map用のkmlの設定も入っている。
今回はnullQueueを使用して、余計なエベントを削除してみた。
LINE_BREAKERは切りたいところ(文字)を(.)で記述している。
設定をすぐ忘れるのでここに書いておく。
(直接取り込みに変更)
累計値をグラフにする
source="output.json" sourcetype="covid19normal_json"
| spath output=category category{}
| spath output=data47 data47{}
| eval category=mvjoin(category," ")
| stats values(category) as category by data47
| spath input=data47
| makemv delim=" " category
| eval tmp=mvzip(category,'data{}')
| streamstats count as session
| stats values(name) as pref by session tmp
| eval _time=strptime(replace(tmp,"(.*),.*","2020/\1"),"%Y/%m/%d"), data=mvindex(split(tmp,","),1)
| fields _time pref data
| xyseries _time pref data
| addcoltotals labelfield=_time label=total
| transpose 0 header_field=_time
| sort 10 - total
| transpose 0 header_field=column column_name=_time
| where _time!="total"
ファイル取り込み時間を_timeとしているので、検索期間はそれに合わせて検索してください。
(100日以上の期間対応のため4/10修正)
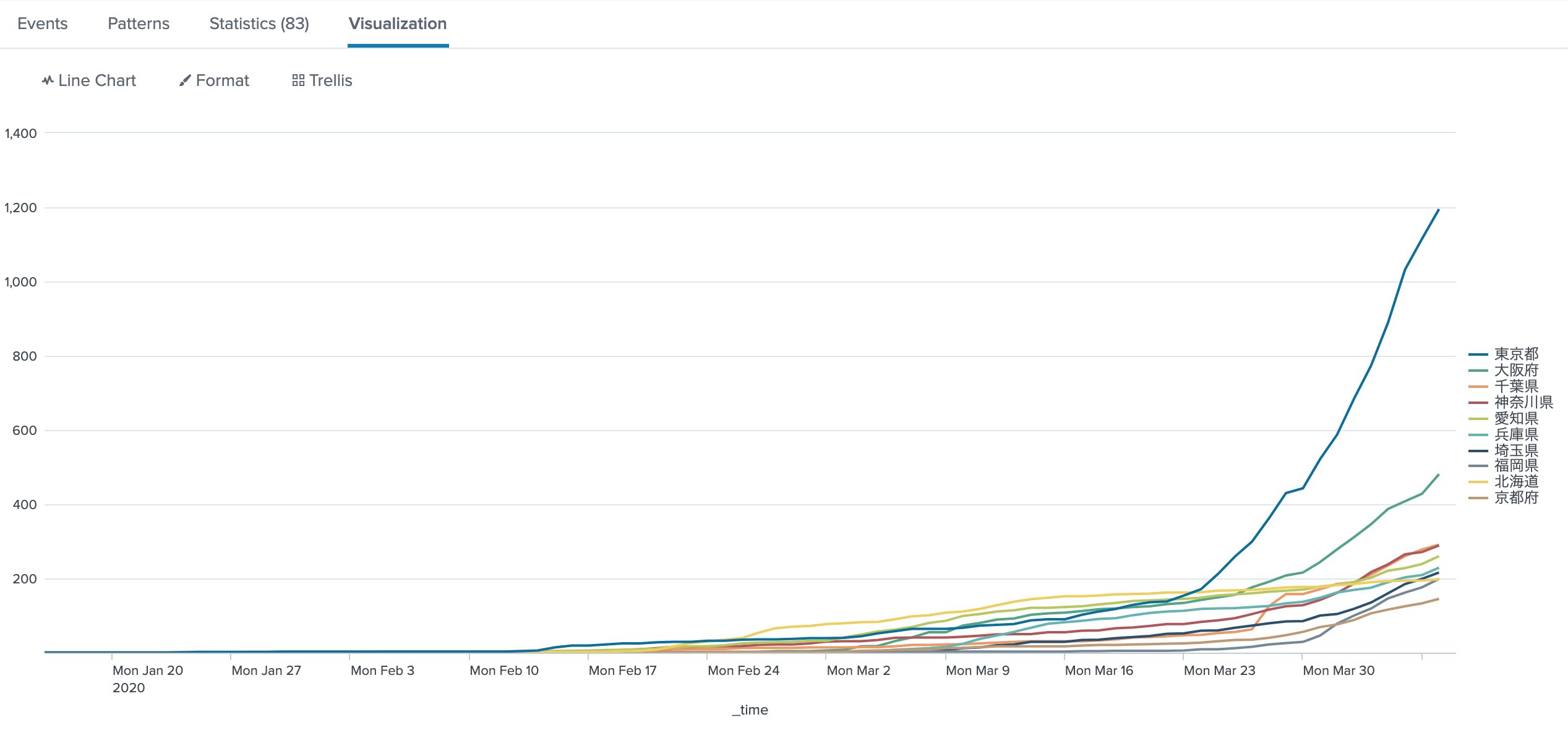
緊急事態宣言が出た今、この累計数の上位と宣言がちょっと違うのがわかる。
一日単位でグラフ化する
source="output.json" sourcetype="covid19normal_json"
| spath output=category category{}
| spath output=data47 data47{}
| eval category=mvjoin(category," ")
| stats values(category) as category by data47
| spath input=data47
| makemv delim=" " category
| eval tmp=mvzip(category,'data{}')
| streamstats count as session
| stats values(name) as pref by session tmp
| eval _time=strptime(replace(tmp,"(.*),.*","2020/\1"),"%Y/%m/%d"), data=mvindex(split(tmp,","),1)
| timechart useother=f span=1d sum(data) by pref where sum in top10
| untable _time pref count
| streamstats current=f max(count) as count_p by pref
| eval day_count = count - count_p
| table _time pref day_count
| xyseries _time pref day_count
| addcoltotals labelfield=_time label=total
| transpose 0 header_field=_time
| sort - total
| transpose 0 header_field=column column_name=_time
| where _time!="total"
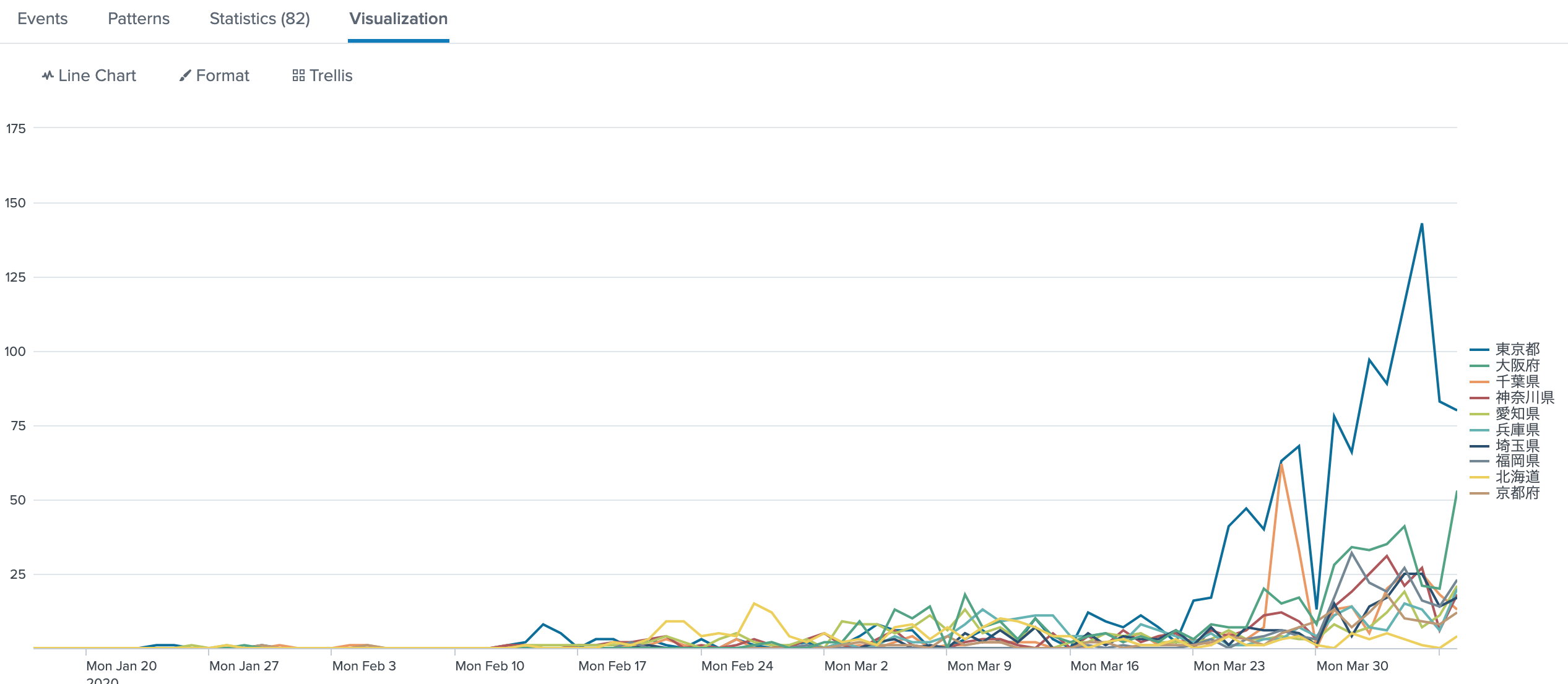
1日単位のデータで予測する
ここでAppsを先ほどと同様にMLTKに切り替える
source="output.json" sourcetype="covid19normal_json"
| spath output=category category{}
| spath output=data47 data47{}
| eval category=mvjoin(category," ")
| stats values(category) as category by data47
| spath input=data47
| makemv delim=" " category
| eval tmp=mvzip(category,'data{}')
| streamstats count as session
| stats values(name) as pref by session tmp
| eval _time=strptime(replace(tmp,"(.*),.*","2020/\1"),"%Y/%m/%d"), data=mvindex(split(tmp,","),1)
| timechart useother=f span=1d sum(data) by pref where sum in top10
| untable _time pref count
| streamstats current=f max(count) as count_p by pref
| eval day_count = count - count_p
| timechart span=1d max(day_count) by pref
| predict 東京都 大阪府 千葉県 神奈川県 兵庫県 埼玉県 福岡県 future_timespan=30
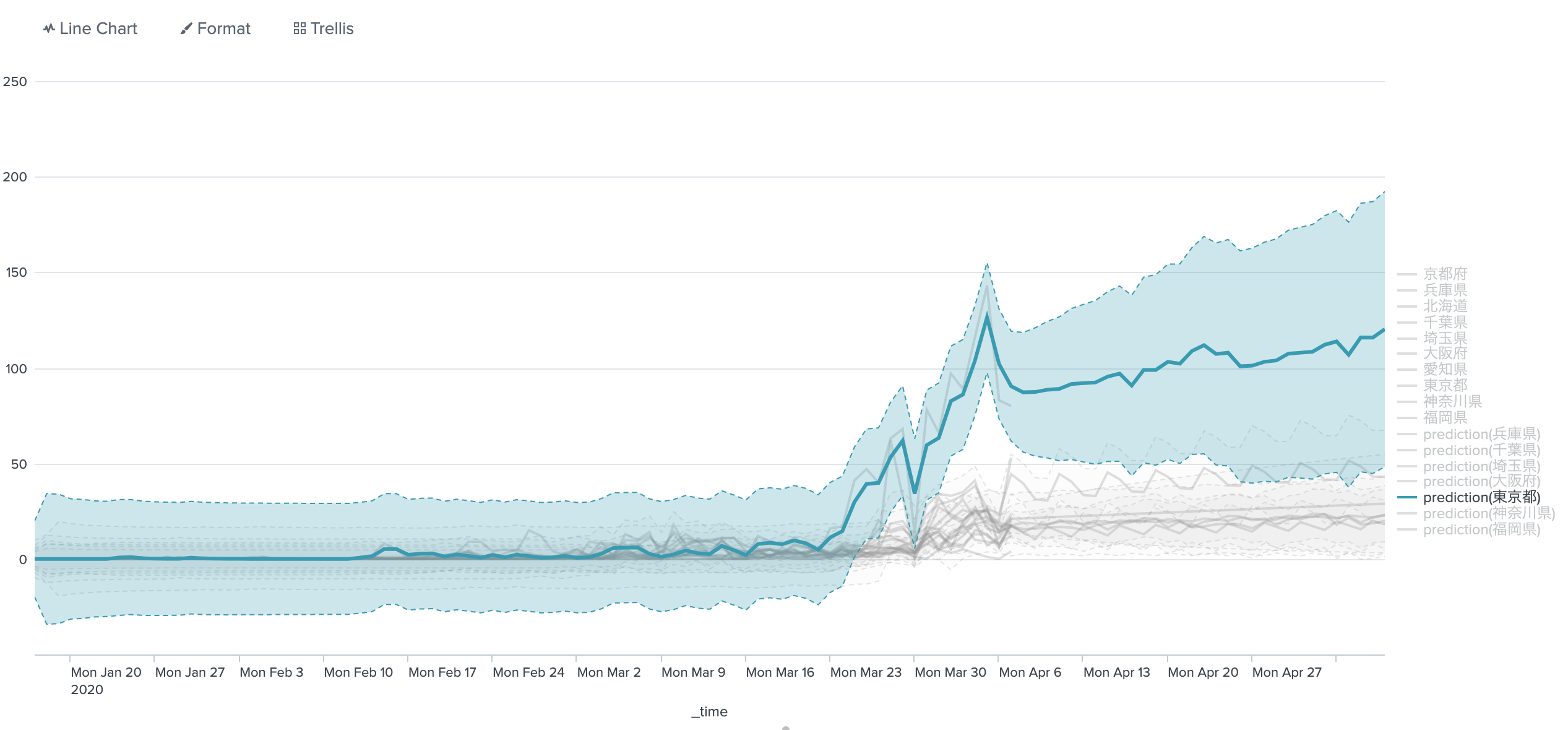
やはり東京は予断を許さない。
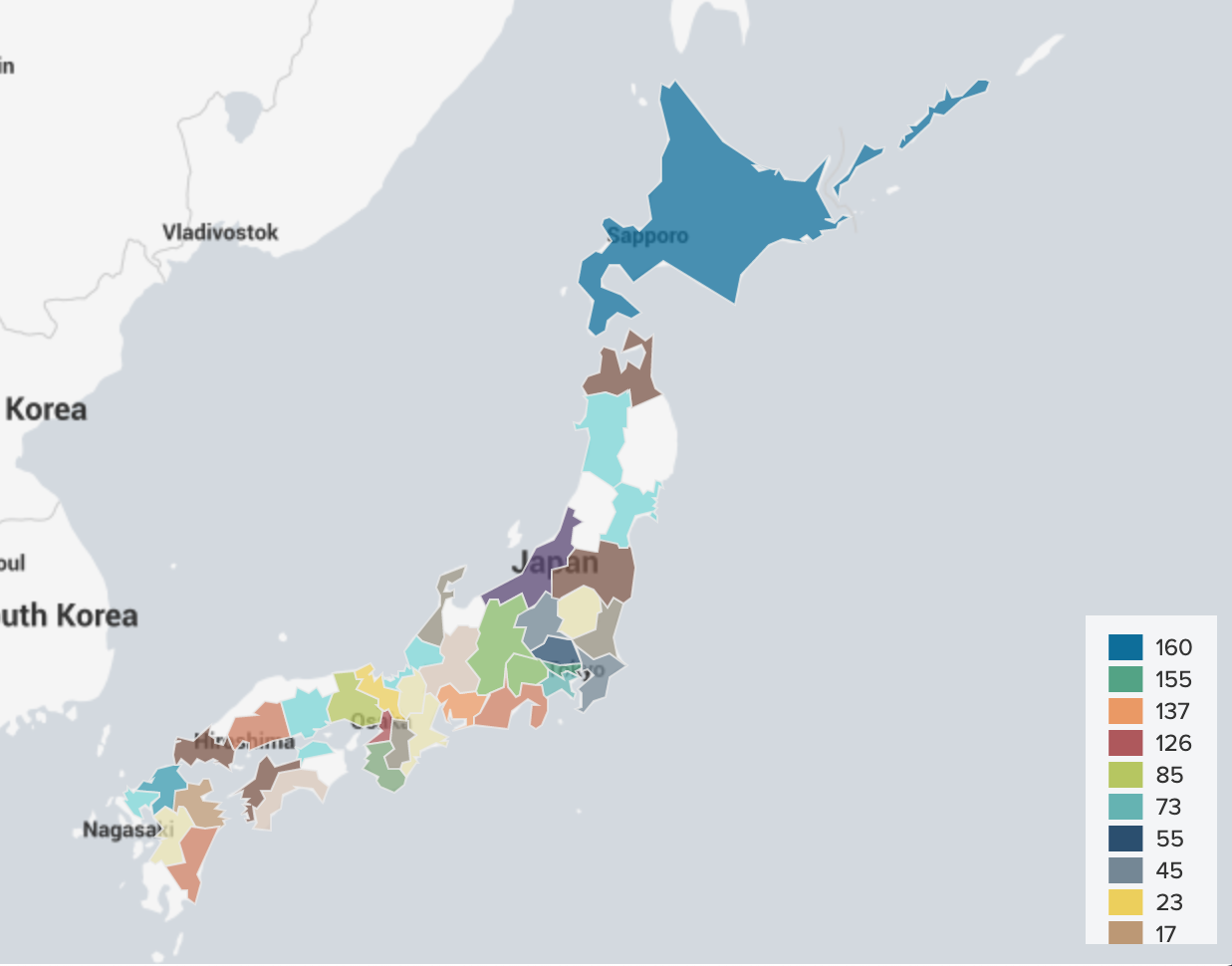
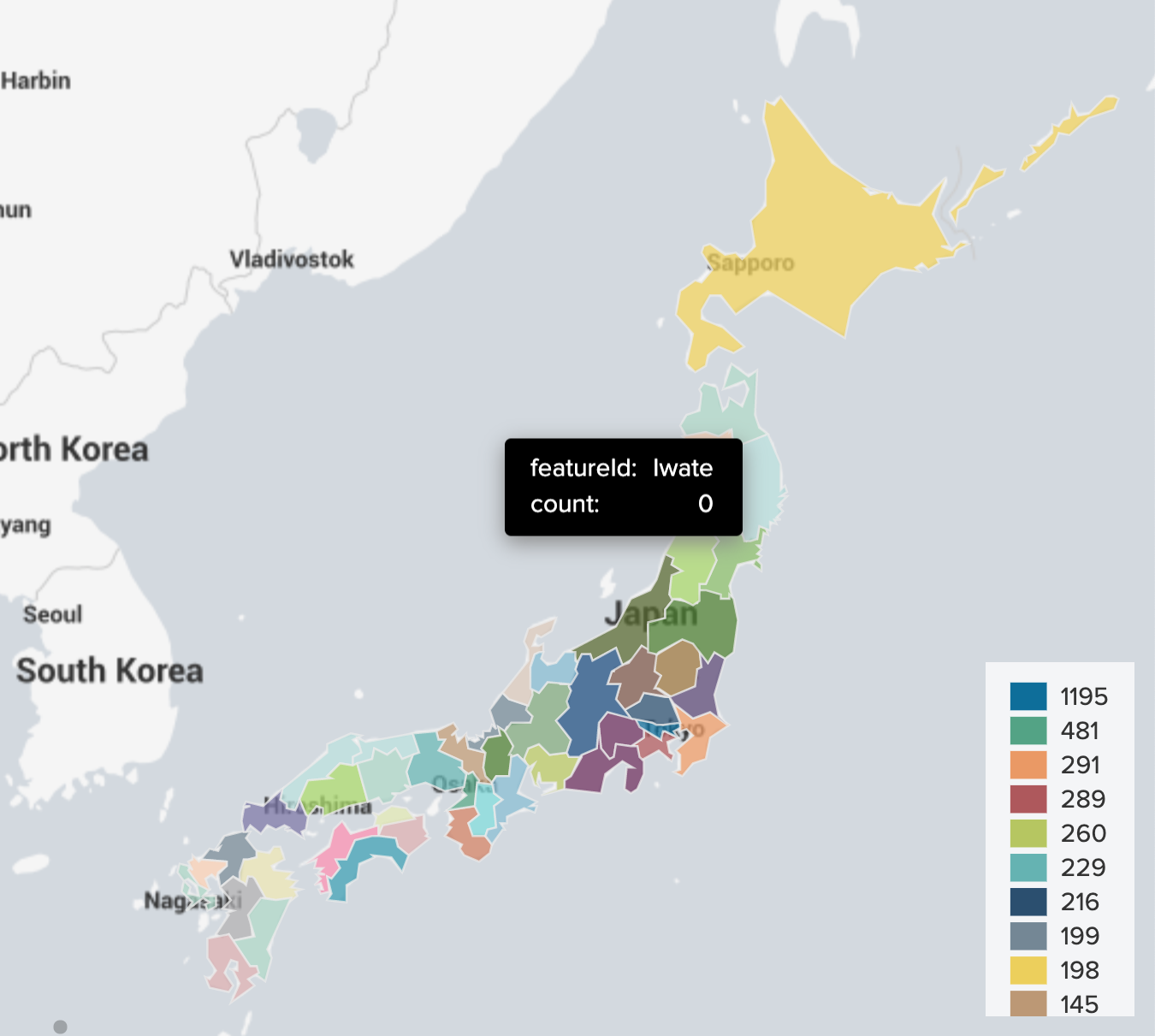
ChoroplethMap
Appsを戻して検索する
source="output.json" sourcetype="covid19normal_json"
| spath output=category category{}
| spath output=data47 data47{}
| eval category=mvjoin(category," ")
| stats values(category) as category by data47
| spath input=data47
| makemv delim=" " category
| eval tmp=mvzip(category,'data{}')
| streamstats count as session
| stats values(name) as pref by session tmp
| eval _time=strptime(replace(tmp,"(.*),.*","2020/\1"),"%Y/%m/%d"), data=mvindex(split(tmp,","),1)
| sort 0 - _time data
| dedup pref
| lookup prefecture.csv Kanji as pref OUTPUT Prefecture as featureId
| geom japansimple
| fields - _time session pref tmp
まとめ
データを自分自身で確認すると、今の状況や今後どうなりそうなのかそれなりに納得できるのがいいと思います。
今回、 Splunkを使用したのは自分が一番使いやすかったからなので、pythonとかRでできる人はそのままやってもらった方が早いと思います。
3月の時に一回調べた時は、4月になってこんなことになっているとは思いませんでした。
今から始めたことは、2週間後にならないとわからないので、頑張っていきたいと思います。