でデータが提供されているので、matplotlibでグラフにしてみた。
データ
JSON形式だけど、listの中に入っているので、いったん取り出さないとdictにならない。
データのダウンロードからグラフ化
data_dl_and_graph.ipynb
%matplotlib inline
import pandas as pd
import requests
import matplotlib.pyplot as plt
from matplotlib import rcParams
!pip install -q japanize-matplotlib
import japanize_matplotlib
# 「IPA」フォントをインストール
!apt-get -y install fonts-ipafont-gothic -qq
# matplotlibのキャッシュをクリア
# !rm /root/.cache/matplotlib/fontlist-v310.json
# データをダウンロード
url = 'https://data.corona.go.jp/converted-json/covid19japan-all.json'
response = requests.get(url)
covid19japan_json = response.json()
# データの加工
covid19japan_data = pd.DataFrame(covid19japan_json[0]['area'])
df = covid19japan_data.assign(lastUpdate=covid19japan_json[0]['lastUpdate'])
df = df.sort_values('npatients')
df = df.tail(10)
# グラフの描画
rcParams['font.family'] = "IPAGothic"
plt.figure(figsize=(8, 8),dpi=100)
plt.barh(df['name_jp'],df['npatients'])
plt.title('コロナウィルス感染者数 '+df['lastUpdate'][0])
plt.xlabel('感染者数')
plt.ylabel('都道府県')
fig=[plt.text(1000,df.at[i,'name_jp'], df.at[i,'npatients'], va='center', color='w', fontsize='x-large') for i in df.index]
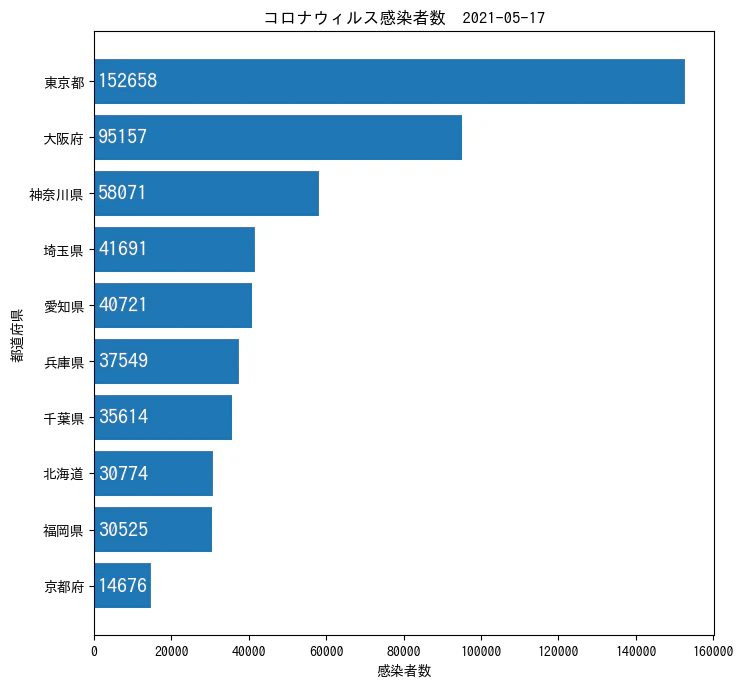
解説
- 日本語環境にするために、IPAフォントをダウンロードしている。
- データの加工については、
barh()は降順で表示するので、sort_values()したのちtail(10)で上位10個を抽出 -
figは数値を棒の中に表示したかったので、内包で展開している。-
plt.text(x軸,y軸,値)が基本 - 今回はx軸を固定して、y軸を都道府県の値にするために
[index, 'name_jp']で都道府県名を取り出している。 - colabは直接実行していけば、表示されるので、変数に入れているのは余計な表示をなくすため
-
全ての都道府県を表示する。
all_pref.ipynb
# データのダウンロードについては、上を参照
#
# データの加工
covid19japan_data = pd.DataFrame(covid19japan_json[0]['area'])
df = covid19japan_data.assign(n_diff=max(covid19japan_data['npatients']) - covid19japan_data['npatients'], lastUpdate=covid19japan_json[0]['lastUpdate'])
df.sort_values('npatients', ascending=False, inplace=True)
df.reset_index(drop=True,inplace=True)
# グラフの描画
rcParams['font.family'] = "IPAGothic"
plt.figure(figsize=(10, 12),dpi=100)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
cols = 1
position = 1
for i in df.index:
if position > 47:
cols += 1
position = cols
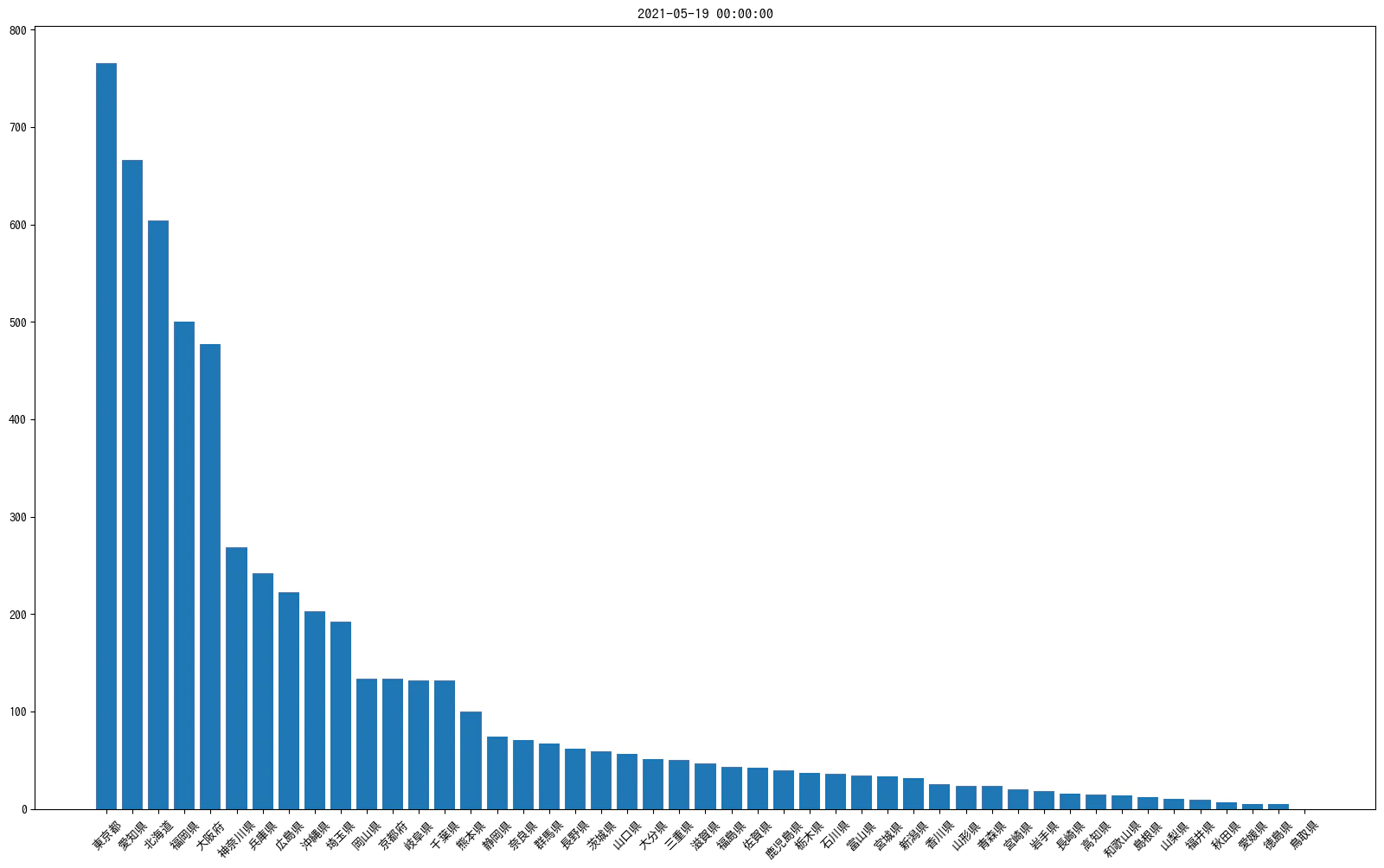
plt.subplot(10,5, position).set_xlim([0,max(df['npatients'])])
plt.tick_params(labelleft=False,labelbottom=False,bottom=False)
plt.title(df['name_jp'][i])
plt.barh(df['name_jp'][i],df['npatients'][i],color='Green', alpha=0.8)
plt.barh(df['name_jp'][i], df['n_diff'][i], left=df[i:i+1]['npatients'], color='b', alpha=0.1)
plt.text(df['npatients'][0]//3,df['name_jp'][i], df['npatients'][i], va='center', color='Black', fontsize='x-large')
position += 5

解説
- 今回は東京都に合わせてグラフを書きたいので、
n_diffのデータを作成 - indexを振り直すことで、あとの描画時のループカウンターとする。
-
plt.subplot(行,列,表示箇所)なので、ループで都道府県別に表示している。- ただし、表示箇所は横に増加していくため、_10 ✖️ 5_の表示箇所を5づつ増加させている。
- 東京都だけ表示がずれたので
set_xlim()でx軸の表示枠を固定長にしている。
-
plt.tick_params()で軸の表示を消している。 -
plt.title()でx軸の表示をタイトルとしている。
オブジェクト指向スタイルで作り直した
object_graph.ipynb
fig=plt.figure(figsize=(10,12), dpi=100, facecolor='plum')
fig.subplots_adjust(wspace=0.4, hspace=0.8)
cols = 1
position = 1
ax = []
for i in df.index:
if position > 47:
cols += 1
position = cols
ax.append(fig.add_subplot(10,5, position))
ax[i].set_xlim([0,max(df['npatients'])])
ax[i].tick_params(labelleft=False,labelbottom=False,bottom=False)
ax[i].spines["right"].set_color("none") # 右消し
ax[i].spines["left"].set_color("none") # 左消し
ax[i].spines["top"].set_color("none") # 上消し
ax[i].spines["bottom"].set_color("none") # 下消し
ax[i].set_title(df['name_jp'][i], fontdict={'fontsize': 12})
ax[i].barh(df['name_jp'][i],df['npatients'][i],color='Green', alpha=0.8)
ax[i].barh(df['name_jp'][i], df['n_diff'][i], left=df['npatients'][i], color='b', alpha=0.1)
ax[i].text(1000,df['name_jp'][i], df['npatients'][i], va='center', color='Black', fontdict={'fontsize': 12})
position += 5

解説
- きちんと
figure()とaxisを意識して作ってみた。 - 基本的な設計は以前のものと一緒
- 複数の_ax_のオブジェクトはlistで管理
-
axisの枠とかを消すのにspines[].set_color()で頑張った。 -
axisで作っているので、set_title()になっていたり、細かいところが変わっている。 - 色使いが変なのは仕方がない

ヒートマップっぽいことに挑戦
daily_by_pref.ipynb
%matplotlib inline
import pandas as pd
import requests
import matplotlib.pyplot as plt
import matplotlib
!pip install -q japanize-matplotlib
import japanize_matplotlib
# 「IPA」フォントをインストール
!apt-get -y install fonts-ipafont-gothic -qq
matplotlib.font_manager._rebuild()
# matplotlibのキャッシュをクリア
# !rm /root/.cache/matplotlib/fontlist-v310.json
matplotlib.rcParams['font.family'] = "IPAGothic"
nhk_url="https://www3.nhk.or.jp/n-data/opendata/coronavirus/nhk_news_covid19_prefectures_daily_data.csv"
# 日付,都道府県コード,都道府県名,各地の感染者数_1日ごとの発表数,各地の感染者数_累計,各地の死者数_1日ごとの発表数,各地の死者数_累計
rr=requests.get(nhk_url)
import io
df_nhk=pd.read_csv(io.StringIO(rr.content.decode('utf-8')), skiprows=1,header=None, names=['date',"pref_code","pref_name","num","accum","death_num","death_accum"],index_col='date',parse_dates=True)
# df_nhk
# 最新の日付の情報を抽出
df_g1=df_nhk.loc[max(df_nhk.index),['pref_name','num']].set_index('pref_name').sort_values('num',ascending=False)
# 棒グラフ
fig = plt.figure(figsize=(20, 12),dpi=100)
ax= fig.add_subplot(111)
ax.set_title(df_nhk.tail(1).index[0])
fig=plt.xticks(rotation=45)
x=df_g1.index
y=df_g1.num
ax.bar(x,y,label='感染者数')
# 都道府県別人口の一覧を入手
url_pref='https://www.homemate.co.jp/research/population/all/'
pref_mass=pd.read_html(url_pref)[0].loc[:,['都道府県','人口']]
pref_mass.set_index('都道府県', inplace=True)
# 先ほどのデータと結合
df=pd.concat([df_g1,pref_mass],axis=1)
df = df.assign(
mass=lambda x: x['人口'].str.replace(',','').str.replace('人','').astype(int),
perm=lambda x: round(x.num / x.mass * 100000,2),
n_diff=max(df['num']) - df['num'],
colors=lambda x: (x.perm / 5)
)
df.drop(columns=['人口'], inplace=True)
# 描画
fig=plt.figure(figsize=(10,12), dpi=100, facecolor='khaki')
fig.subplots_adjust(wspace=0.4, hspace=0.8)
category_colors = plt.get_cmap('Reds',16)
cols = 1
position = 1
ax = []
for i,v in enumerate(df.index):
if position > 47:
cols += 1
position = cols
ax.append(fig.add_subplot(10,5, position))
ax[i].set_xlim([0,max(df['num'])])
ax[i].set_xscale('symlog')
ax[i].tick_params(labelleft=False,labelbottom=False,bottom=False, labelright=False)
ax[i].set_title(df.index[i], fontdict={'fontsize': 12, 'color': 'black'})
ax[i].barh(df.index[i],df['num'][i],color=category_colors(df['colors'][i]), alpha=0.8)
ax[i].barh(df.index[i], df['n_diff'][i], left=df['num'][i], color='b', alpha=0.5)
ax[i].text(0,df.index[i], df['num'][i], va='center', color='w', fontdict={'fontsize': 12}) if df.colors[i] > 1. \
else ax[i].text(0,df.index[i], df['num'][i], va='center', color='black', fontdict={'fontsize': 12})
position += 5
ax=[axs.spines[sp].set_visible(False) for sp in ['top','bottom','right','left'] for axs in ax]

色の濃いところは、人口比で1日の感染者数が多いところ。
解説
- NHKのデータは
read_csv()で直接はうまくいかなかったのでrequests()とio.StringIO()で取り込んだ - 都道府県別人口一覧はホームメイトのHPから。統計局のデータはexcelで使いもんにならなかった・・・
-
NHKのHPでも10万人あたりの数字を出している。今回はこの数字の大小で色を変えてみた。
- 0〜3の数字にしたかったので、適当に割っている。
- colormapsをみながらどれがいいかなといろいろと試してこれにしてみた。
-
get_cmap()で範囲を指定して、barh()の_color_で色を指定
FacetGrid風
pref_data1.ipynb
%matplotlib inline
import pandas as pd
import requests
import matplotlib.pyplot as plt
import matplotlib
!pip install -q japanize-matplotlib
import japanize_matplotlib
# 「IPA」フォントをインストール
!apt-get -y install fonts-ipafont-gothic -qq
matplotlib.font_manager._rebuild()
# matplotlibのキャッシュをクリア
!rm /root/.cache/matplotlib/fontlist-v310.json
matplotlib.rcParams['font.family'] = "IPAGothic"
nhk_url="https://www3.nhk.or.jp/n-data/opendata/coronavirus/nhk_news_covid19_prefectures_daily_data.csv"
# 日付,都道府県コード,都道府県名,各地の感染者数_1日ごとの発表数,各地の感染者数_累計,各地の死者数_1日ごとの発表数,各地の死者数_累計
rr=requests.get(nhk_url)
import io
df_nhk=pd.read_csv(io.StringIO(rr.content.decode('utf-8')), skiprows=1,header=None
, names=['date',"pref_code","pref_name","num","accum","death_num","death_accum"],index_col='date',parse_dates=True)
# 7日分のデータに限定
import datetime
m=max(df_nhk.index)-datetime.timedelta(days=7)
df=df_nhk[df_nhk.index >= m]
# 都道府県別で7日分の感染者数の平均を導出
facet_df=df.assign(
avg=df.groupby('pref_name').num.transform(lambda y: y.mean()),
timedate=df.index.date
)[['pref_name','num','avg','timedate']].reset_index()
# 感染者数の上位の県のリストを作成
orderlist=list(facet_df.query("date=='{}'".format(max(facet_df['date']))).sort_values('num',ascending=False)['pref_name'])
# 作図
fig=plt.figure(figsize=(20,20))
fig.subplots_adjust(hspace=0.8)
ax=[]
for i, pref in enumerate(orderlist):
ax.append(fig.add_subplot(10,5, i + 1))
data=facet_df.query("pref_name==@pref")
data=data.assign(
color_bool=lambda x: x.num > x.avg,
color=lambda x: x.color_bool.apply(
lambda y: 'red' if y else 'blue')
)
ax[i]=plt.bar(data.date,data.num,color=data.color)
ax[i]=plt.xticks(data.date, [i.day for i in data.date])
ax[i]=plt.axhline(data['avg'].max(), ls='--', c='green')
ax[i]=plt.title(pref)
fig.suptitle('感染者数 {}〜{}'.format(
min(facet_df['timedate']),max(facet_df['timedate'])
)
, size=18, weight=2)

解説
- _figure_をグラフの数だけ作って、作図していくこれまでの方法の応用
-
transforms()のところはgroupby()で集約されたフィールドに対して集計している。 - 作図の
assign()のところはまずは_boolean_の列を作って、その次に条件判定をしてあげている。-
lambdaの中でのif elseがあんまりうまくいかなくて、こんな感じになった。
-
- 全部
pltで書いている。 -
suptitle()でformat()で変数の結果を与えているのが頑張ったところ
FacetGrid風その2
データは上と一緒なので、作図のところから
pref_data2.ipynb
fig, axes = plt.subplots(10, 5, figsize=(20,20),
sharex='col', sharey=False,
subplot_kw=dict(facecolor='white'))
fig.subplots_adjust(hspace=0.2)
fig.suptitle('感染者数 {}〜{}'.format(
min(facet_df['timedate']),max(facet_df['timedate'])
)
, size=18, weight=2)
axeslist=[j for i in axes for j in i]
pointer = 0
for i, pref in enumerate(orderlist):
data=facet_df.query("pref_name==@pref")
data=data.assign(
color_bool=lambda x: x.num > x.avg,
color=lambda x: x.color_bool.apply(
lambda y: 'red' if y else 'blue')
)
axeslist[i].bar(data.date,data.num,color=data.color)
axeslist[i].set_xticklabels([i.day for i in data.date])
axeslist[i].axhline(data['avg'].max(), ls='--', c='green')
axeslist[i].set_title(pref)
pointer = i
a=[ax.axis('off') for ax in axeslist[pointer+1:]]
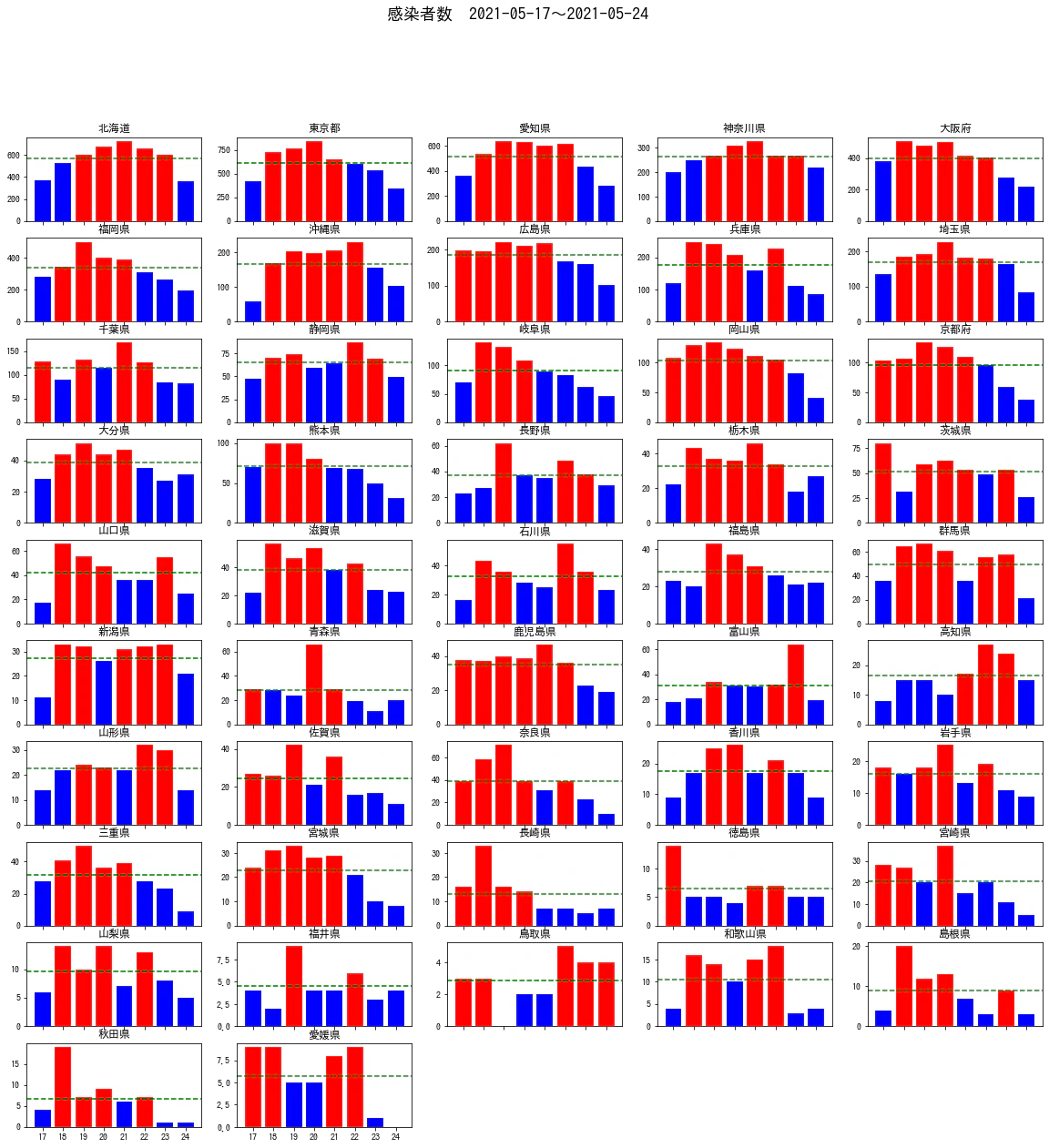
解説
- 上のが_figure_に描いているのに対して、_axes_に記述している。
-
 _axes_にアクセスするまでが本当に大変だった。
_axes_にアクセスするまでが本当に大変だった。 -
ax[i,j]でアクセスできなくて、同じ_axes_に描画されてしまっていた。 -
plt.subplots()で作成した_axes_は、今回であれば二次元配列の中に描画エリアが格納されている - いったん順番に取り出し_axeslist_(AxesSubplot)を配列としている。
-
- あとは、_axes_へのアクセス用のメソッドで同じことをしている。
- 最後は余った_axes_を見えなくしている。
Axesについて
figure_がキャンバス全体だとしたら、そのなかの細かい領域が_axes
今回みたいな数多くの描画に対しての上手い例文がなくて、また_searborn_のFacetGridだと
中途半端な数のグラフだとcol_wrapで、xticklabelsがずれてしまったので諦めたり、かなり悩みました。
まとめ
今回は値を棒の中に表示するところを頑張ってみました。日本語表示も結構大変でした。 ![]()
HPの表示は値によってヒートマップにしていたり、最大値をx軸の最大にして都道府県で表示しているので、こんどはそちらを目指していきたい。
→ これもなんとかできました。データそのもので条件判定しなくても、描画する時で切り替えればうまくいきますね。
データの加工はなんとかなってきましたが、描画はまだまだですね。