はじめに
みなさんはGemini APIのコストを自前で計算したことはあるだろうか。
自分は業務でGemini APIを使い始めて、レスポンスの usage_metadata からトークン数を取り出してコスト計算していた。
使い始めて2週間。料金を確認したところ、自身でトークン数から算出したログでのコストと実際のコストが大きく乖離していた...。
今回はここの謎に迫っていく。
usage_metadata のフィールド一覧
Gemini APIではresponseの中に使用されたトークン数が含まれている。
このトークン数がAPI利用額を左右するらしい...。
※Gemini APIの利用料金:Gemini API 料金
meta = response.usage_metadata
meta.prompt_token_count # 入力トークン
meta.candidates_token_count # 出力トークン
meta.thoughts_token_count # 思考トークン
meta.total_token_count # 合計
自分がやっていた計算
Gemini APIの料金を見ていて、微妙な表現が1つあった。
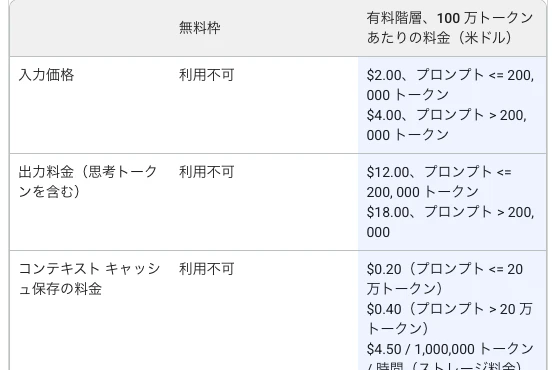
出力料金(思考トークンを含む)
自分は最初にこれを見た時に、
candidates_token_count(出力トークン)にthoughts_token_count(思考トークン)が含まれるんや!
と思った。思ってしまっていた。つまり計算式的にはこうだ。
prompt_token_count × 入力単価 + candidates_token_count × 出力単価
思考トークンは candidates に含まれてると思ってたから除外していた。
実際のことは後述する。
実際に叩いて確かめた
検証用コードは以下の通り。モデルは最新のgemini-3.1-pro-previewで検証した。
※このコードは思考トークンを考慮していない当時のバージョン。正しい計算コードは後述する。
import json
import os
from datetime import datetime, timezone
from pathlib import Path
from dotenv import load_dotenv
from google import genai
load_dotenv()
# ==========================================
# 料金設定(2026年5月時点)
# https://ai.google.dev/gemini-api/docs/pricing
# ==========================================
MODEL = "gemini-3.1-pro-preview"
# 1Mトークンあたりのドル単価
PRICE = {
"input": {
"standard": 2.00, # ≤200kトークン
"large": 4.00, # >200kトークン
},
"output": {
"standard": 12.00,
"large": 18.00,
},
}
THRESHOLD = 200_000 # トークン数の閾値
def calc_cost(prompt_tokens: int, output_tokens: int) -> dict:
"""入力・出力トークン数からドルコストを計算する。"""
tier = "large" if prompt_tokens > THRESHOLD else "standard"
input_cost = prompt_tokens / 1_000_000 * PRICE["input"][tier]
output_cost = output_tokens / 1_000_000 * PRICE["output"][tier]
total_cost = input_cost + output_cost
return {
"tier": tier,
"prompt_tokens": prompt_tokens,
"output_tokens": output_tokens,
"input_cost_usd": input_cost,
"output_cost_usd": output_cost,
"total_cost_usd": total_cost,
}
def save_log(data: dict) -> Path:
log_dir = Path(__file__).parent / "logs"
log_dir.mkdir(exist_ok=True)
timestamp = datetime.now(timezone.utc).strftime("%Y%m%d_%H%M%S")
log_path = log_dir / f"{timestamp}.json"
log_path.write_text(json.dumps(data, ensure_ascii=False, indent=2))
return log_path
def call_and_measure(prompt: str) -> None:
client = genai.Client()
response = client.models.generate_content(
model=MODEL,
contents=prompt,
)
meta = response.usage_metadata
prompt_tokens = meta.prompt_token_count
candidates_tokens = meta.candidates_token_count
thoughts_tokens = meta.thoughts_token_count or 0
total_tokens = meta.total_token_count
result = calc_cost(prompt_tokens, candidates_tokens)
log_data = {
"timestamp": datetime.now(timezone.utc).isoformat(),
"model": MODEL,
"prompt": prompt,
"response": response.text,
"usage_metadata": {
"prompt_token_count": prompt_tokens,
"candidates_token_count": candidates_tokens,
"thoughts_token_count": thoughts_tokens,
"total_token_count": total_tokens,
},
"cost": result,
}
log_path = save_log(log_data)
print("=" * 50)
print(f"[usage_metadata]")
print(f" prompt_token_count : {prompt_tokens}")
print(f" candidates_token_count : {candidates_tokens}")
print(f" thoughts_token_count : {thoughts_tokens}")
print(f" total_token_count : {total_tokens}")
print()
print(f"[検証] candidates に thoughts は含まれているか?")
print(f" candidates - thoughts = {candidates_tokens - thoughts_tokens}")
print(f" ※ 純粋な出力トークンはこの値になるはず")
print()
print(f"[コスト計算] tier={result['tier']}")
print(f" 入力コスト : ${result['input_cost_usd']:.6f}")
print(f" 出力コスト : ${result['output_cost_usd']:.6f}")
print(f" 合計 : ${result['total_cost_usd']:.6f}")
print("=" * 50)
print()
print("[レスポンス]")
print(response.text)
print()
print(f"ログ保存: {log_path}")
if __name__ == "__main__":
call_and_measure("日本の首都はどこですか?一言で答えてください。")
試したプロンプトとそのレスポンス
(プロンプト)
日本の首都はどこですか?一言で答えてください。
(レスポンス)
東京です。
printの内容は以下の通り。
==================================================
[usage_metadata]
prompt_token_count : 14
candidates_token_count : 3
thoughts_token_count : 77
total_token_count : 94
[検証] candidates に thoughts は含まれているか?
candidates - thoughts = -74
※ 純粋な出力トークンはこの値になるはず
[コスト計算] tier=standard
入力コスト : $0.000028
出力コスト : $0.000036
合計 : $0.000064
==================================================
14 + 3 + 77 = 94 になっている。つまり candidates と thoughts は別カウント。
(心の声:「ドキュメントには『Gemini APIではcandidatesに含まれる』って書いてあったのに...。」)
思考トークンは別途課金される
思考トークンは出力トークンと同じ単価で課金される。なので正しい出力コストの計算式は↓
出力コスト = (candidates_token_count + thoughts_token_count) × 出力単価
自分がやっていた計算は思考トークン分が抜けていた...。
実際の利用額
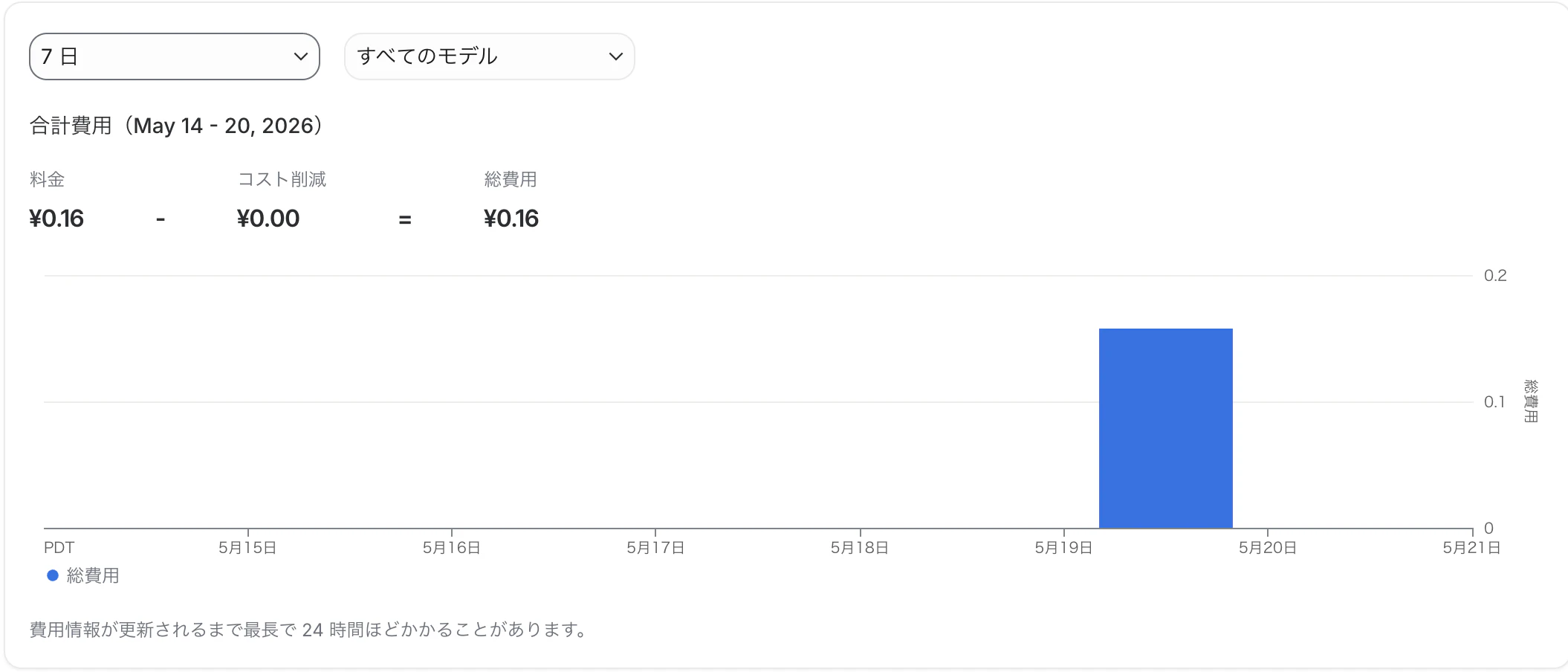
思考コストが料金に含まれるとすると、合計の利用額は先ほどの例だと
合計利用額 = (prompt_token_count/1000000 * 2 ) + ((candidates_token_count + thoughts_token_count)/1000000 * 12)
= 0.000988(ドル)
2026/5の為替は1ドルあたり159.03円。
よって
0.000988 * 159.03 = 0.157(円)
切り上げて0.16円となり、これで計算は合ってそう!
200kトークンの閾値について
gemini-3.1-pro-previewには200kトークンを境に単価が変わる仕組みがある。
| ≤200kトークン | >200kトークン | |
|---|---|---|
| 入力 | $2.00/1Mトークン | $4.00/1Mトークン |
| 出力 | $12.00/1Mトークン | $18.00/1Mトークン |
ここで注意が必要なのが、この閾値は月間累計ではなく1リクエストごとの判定という点。
ただ、自分は200kトークンを超えるリクエストを実際に試していない。
調べた限りでは「超えた分だけではなくリクエスト全体に高い単価が適用される」という情報もあるが、公式ドキュメントには明示されていない。さらに疑問も残っている。
- 200kを超えたとき「超えた分だけ」高い単価になるのか「全体に」高い単価が適用されるのか
- 出力トークン数も独立して200kで判定されるのか、入力トークン数だけで両方のティアが決まるのか
個人レベルで検証するにはコストが高いため、ここは潔くぶん投げる(ごめんなさい)。
正しいコスト計算コード
ここまでを踏まえた正しい計算式をまとめるとこうなる。
PRICE = {
"input": {"standard": 2.00, "large": 4.00}, # $/1Mトークン
"output": {"standard": 12.00, "large": 18.00},
}
THRESHOLD = 200_000
def calc_cost(prompt_tokens: int, candidates_tokens: int, thoughts_tokens: int) -> dict:
tier = "large" if prompt_tokens > THRESHOLD else "standard"
output_tokens = candidates_tokens + thoughts_tokens # 思考トークンは出力として課金
input_cost = prompt_tokens / 1_000_000 * PRICE["input"][tier]
output_cost = output_tokens / 1_000_000 * PRICE["output"][tier]
return {
"tier": tier,
"prompt_tokens": prompt_tokens,
"output_tokens": output_tokens,
"thoughts_tokens": thoughts_tokens,
"input_cost_usd": input_cost,
"output_cost_usd": output_cost,
"total_cost_usd": input_cost + output_cost,
}
ポイントは2つ。
-
candidates_token_count + thoughts_token_countを出力トークンとして計算する - 200k閾値の判定は
prompt_token_count(入力トークン数)で行い、超えていたらリクエスト全体に高い単価を適用する
おわりに
今回の検証でわかったことをまとめるとこうなる。
-
candidates_token_countに思考トークンは含まれない。thoughts_token_countは別カウント - 思考トークンは出力トークンと同じ単価で課金される
- 自分がやっていた計算は思考トークン分が丸ごと抜けていた...。
ドキュメントに「出力料金(思考トークンを含む)」と書いてあったのを「candidatesに含まれる」と読み違えていた。実際に叩いて確かめるまで気づかなかった。
200kトークンを超えるリクエストの挙動については、お金がかかりすぎて自分では検証できなかった...。誰か試してみてくれ...。